











En la arquitectura compleja de los sistemas distribuidos modernos, el tiempo no es simplemente una métrica que se debe medir; es una restricción fundamental que determina el comportamiento del sistema. La confiabilidad del software no consiste únicamente en evitar fallos o manejar excepciones; se trata de garantizar que los componentes interactúen correctamente dentro de límites temporales específicos. Cuando múltiples hilos, servicios o dispositivos de hardware intentan acceder a recursos compartidos, la secuencia y la duración de estas interacciones se vuelven críticas. Es aquí donde los diagramas de tiempo se vuelven indispensables.
Los diagramas de tiempo proporcionan una representación visual de cómo las señales o mensajes cambian de estado con el paso del tiempo. Permiten a los ingenieros modelar las relaciones temporales entre eventos antes de que se ejecute una sola línea de código. Al visualizar el flujo del tiempo, los equipos pueden identificar cuellos de botella potenciales, condiciones de carrera y errores de sincronización que a menudo permanecen invisibles en diagramas de flujo estáticos o diagramas de secuencia. Esta guía explora la mecánica del uso de diagramas de tiempo para mejorar la confiabilidad del software, ofreciendo una profundización en la concurrencia, el análisis de latencia y la validación del sistema.
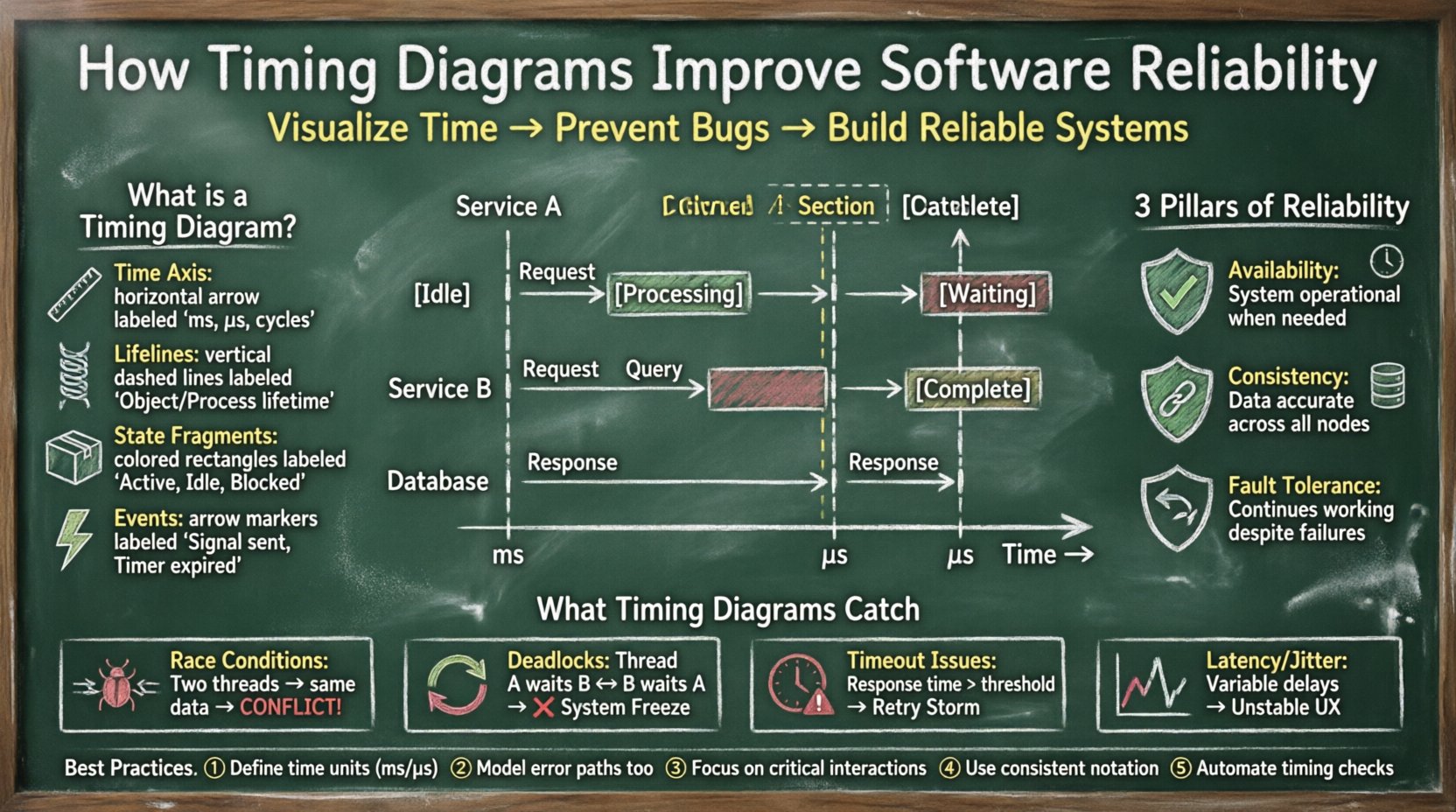
🔍 Definición de diagramas de tiempo en ingeniería
Un diagrama de tiempo es un tipo de diagrama de comportamiento en modelado de sistemas que describe el comportamiento de los objetos con el paso del tiempo. A diferencia de un diagrama de secuencia, que se centra principalmente en el orden de los mensajes, un diagrama de tiempo enfatiza las relaciones temporales entre eventos. Muestra los estados de los objetos y las transiciones entre ellos a lo largo de un eje horizontal del tiempo.
- Eje del tiempo:Normalmente se extiende horizontalmente de izquierda a derecha, representando la progresión del tiempo en milisegundos, microsegundos o ciclos de reloj.
- Líneas de vida:Barras verticales que representan la existencia de un objeto o proceso con el paso del tiempo.
- Fragmentos de estado:Áreas rectangulares en la línea de vida que indican el estado del objeto (por ejemplo, Activo, Inactivo, Bloqueado, Procesando).
- Eventos:Flechas o marcadores que indican cuándo ocurre una acción específica, como el envío de una señal o la expiración de un temporizador.
Al mapear estos elementos, los desarrolladores crean una línea de tiempo de las operaciones del sistema. Este contexto visual es crucial para comprender cuánto tiempo tarda un proceso en completarse y cómo espera a otros procesos. Transforma la lógica abstracta en una línea de tiempo tangible que puede analizarse para detectar errores.
🏗️ Las columnas fundamentales de la confiabilidad del software
La confiabilidad en la ingeniería de software se refiere a la probabilidad de que un sistema realice sus funciones requeridas bajo condiciones especificadas durante un período determinado. Para lograr esto, se deben abordar tres pilares principales:
- Disponibilidad:El sistema debe estar operativo cuando sea necesario. Los diagramas de tiempo ayudan a verificar que los procesos de recuperación se completen dentro de ventanas aceptables.
- Consistencia:Los datos deben mantenerse precisos entre nodos distribuidos. Visualizar las operaciones de escritura y lectura ayuda a garantizar que la integridad de los datos no se vea comprometida por la latencia.
- Resistencia a fallos:El sistema debe continuar operando a pesar de los fallos. Los diagramas de tiempo ilustran cuánto tiempo tarda un mecanismo de respaldo en activarse, asegurando que no se perciba ninguna interrupción del servicio por parte del usuario.
Sin una comprensión clara de las restricciones temporales, un sistema podría ser lógicamente correcto pero prácticamente poco confiable. Por ejemplo, una consulta a una base de datos podría devolver los datos correctos, pero si tarda 10 segundos en procesarse, viola el requisito de confiabilidad de una interfaz de usuario receptiva. Los diagramas de tiempo exponen estas violaciones temporales.
🐞 Detección de condiciones de carrera mediante análisis visual
Una condición de carrera ocurre cuando dos o más procesos acceden a datos compartidos de forma concurrente, y el resultado final depende del tiempo relativo de su ejecución. Estas son notoriamente difíciles de depurar porque son no deterministas y a menudo desaparecen cuando se adjuntan depuradores.
Los diagramas de tiempo reducen este riesgo al imponer un orden visual estricto de los eventos. Al modelar una condición de carrera potencial, un ingeniero puede dibujar las líneas de vida de los hilos que compiten. Si el diagrama muestra que ambos hilos intentan escribir en la misma ubicación de memoria simultáneamente sin una barrera de sincronización, el error se vuelve inmediatamente visible.
- Visualización de secciones críticas:Resalta la duración durante la cual un recurso está bloqueado. Si otro proceso intenta acceder durante esta ventana, el diagrama muestra un conflicto.
- Identificación de fallos:En las interfaces entre hardware y software, pueden ocurrir fallos de señal si no se cumplen los tiempos de preparación y retención. Los diagramas de tiempo muestran explícitamente estas ventanas.
- Dependencias de ordenación: Asegúrese de que la inicialización A finalice antes de que comience la inicialización B. El diagrama impone una verificación temporal sobre esta dependencia.
Al resolver estos problemas durante la fase de diseño, la probabilidad de fallos en producción disminuye significativamente. Esto traslada la detección de errores de concurrencia desde los registros en tiempo de ejecución hasta las revisiones de diseño.
🧵 Gestión de concurrencia y sincronización de hilos
Las aplicaciones modernas dependen en gran medida del procesamiento asíncrono para manejar cargas elevadas. Los hilos, las corutinas y los grupos de trabajadores permiten que múltiples tareas se ejecuten en paralelo. Sin embargo, los primitivos de sincronización como los mutex, semáforos y bloques introducen sus propias complejidades temporales.
Los diagramas de temporización ayudan a modelar estos puntos de sincronización. Ayudan a responder preguntas como:
- ¿Cuánto tiempo espera un hilo por un bloqueo antes de expirar?
- ¿Varía el tiempo de adquisición del bloqueo según la carga del sistema?
- ¿Existen interbloqueos en los que dos hilos esperan indefinidamente el uno al otro?
Al diseñar una aplicación multihilo, los ingenieros pueden bosquejar el estado de cada hilo. Si el hilo A posee el recurso 1 y espera el recurso 2, mientras que el hilo B posee el recurso 2 y espera el recurso 1, un diagrama de temporización puede revelar la condición de espera circular. Esta prueba visual permite reestructurar la lógica de adquisición de recursos antes de que comience la implementación.
Además, los diagramas de temporización aclaran el comportamiento de la inversión de prioridad. En sistemas en tiempo real, una tarea de alta prioridad podría quedar bloqueada por una tarea de baja prioridad que posee un bloqueo. Un diagrama de temporización hace evidente esta inversión de prioridad, permitiendo a los arquitectos implementar protocolos de herencia de prioridad.
🌐 Protocolos de red y verificación de intercambio de mensajes
En los sistemas distribuidos, la latencia de red es una variable que no puede ignorarse. Los protocolos como TCP/IP, HTTP/2 y gRPC dependen de intercambios de mensajes para establecer conexiones. Los diagramas de temporización son esenciales para validar estas interacciones.
Considere un intercambio de mensajes estándar de tres vías (SYN, SYN-ACK, ACK). Un diagrama de temporización permite a los ingenieros establecer una duración máxima permitida para este proceso. Si el diagrama muestra que el ACK tarda más que el umbral de tiempo de espera configurado, es probable que la conexión falle bajo carga.
- Configuración de tiempo de espera: Defina la duración exacta en milisegundos para una solicitud antes de que se active un nuevo intento.
- Lógica de retransmisión:Visualice el intervalo entre un paquete fallido y su retransmisión para asegurarse de que no sobrecargue la red.
- Intervalos de mantenimiento de conexión: Asegúrese de que el intervalo entre los mensajes de mantenimiento de conexión sea más corto que el tiempo de espera de inactividad de la red para evitar desconexiones prematuras.
Al modelar estas interacciones de red, los equipos pueden asegurarse de que su software maneje con elegancia las variaciones de red. Esto evita fallos en cadena en los que una respuesta lenta de un microservicio provoque que todo el frontend se bloquee.
⚙️ Temporización de la interfaz hardware-software
La fiabilidad del software depende a menudo de la calidad de su interacción con el hardware. Los sistemas embebidos, dispositivos IoT y plataformas de trading de alta frecuencia requieren un temporizado preciso. Un retraso de unos pocos microsegundos puede provocar corrupción de datos o pérdidas financieras.
Las rutinas de servicio de interrupciones (ISRs) son un ejemplo claro. Cuando ocurre una interrupción de hardware, la CPU debe pausar las tareas actuales para atenderla. Un diagrama de temporización muestra la latencia de interrupción (tiempo desde la solicitud de interrupción hasta la entrada en la ISR) y el tiempo de respuesta de la interrupción.
- Latencia de interrupción: El tiempo necesario para reconocer la interrupción.
- Sobrecarga del cambio de contexto: El tiempo que se guarda y se restaura durante la ISR.
- Preservación de registros: Asegurarse de que el estado se guarde antes de que la ISR lo modifique.
Si el diagrama de tiempos muestra que la ISR tarda demasiado, podría bloquear otras interrupciones críticas. Este análisis visual permite a los desarrolladores optimizar el código de la ISR o desviar el procesamiento a un hilo de fondo, asegurando que se cumplan los requisitos en tiempo real.
📉 Identificación de problemas de latencia y jitter
La latencia es el retraso antes de que comience la transferencia de datos tras una instrucción para su transferencia. El jitter es la variación de la latencia con el tiempo. Ambos son perjudiciales para la experiencia del usuario y la estabilidad del sistema. Los diagramas de tiempos son la herramienta principal para analizar estas métricas.
Al modelar un ciclo de solicitud-respuesta, los ingenieros pueden marcar los puntos exactos en los que ocurre el procesamiento. Por ejemplo:
- Tiempo de espera en la cola:¿Cuánto tiempo permanece una solicitud en el buffer antes de procesarse?
- Tiempo de procesamiento:¿Cuánto tiempo tarda realmente la lógica en ejecutarse?
- Tránsito de red:¿Cuánto tiempo tarda los datos en viajar a través del cable?
Al sumar estos segmentos, se calcula la latencia total. Si el jitter es alto, el diagrama de tiempos mostrará un espaciado inconsistente entre los eventos en múltiples iteraciones. Esta inconsistencia indica inestabilidad en la infraestructura subyacente, lo que impulsa una investigación adicional sobre contención de recursos o congestión de red.
📝 Documentación de interacciones del sistema
La documentación a menudo se pasa por alto en la búsqueda de funcionalidad, pero es vital para la fiabilidad a largo plazo. El código cambia con frecuencia, y nuevos miembros del equipo se incorporan regularmente. Los diagramas de tiempos sirven como una referencia duradera sobre cómo se comporta el sistema con el tiempo.
Un conjunto bien mantenido de diagramas de tiempos proporciona:
- Material de incorporación:Los nuevos desarrolladores pueden entender el flujo temporal sin tener que leer miles de líneas de código.
- Ayuda para depuración:Cuando ocurre un error, los ingenieros pueden comparar el comportamiento real con el diagrama de tiempos documentado para detectar desviaciones.
- Definición de contrato:Definen el comportamiento esperado entre servicios, actuando como un contrato para la integración.
Esta documentación reduce la carga cognitiva sobre los ingenieros durante la respuesta a incidentes. En lugar de adivinar el momento de los eventos, tienen una referencia visual a seguir.
⚠️ Violaciones de tiempo comunes
No todas las cuestiones de tiempo son iguales. Algunas son fallos críticos, mientras que otras son degradaciones del rendimiento. La tabla a continuación categoriza las violaciones comunes encontradas en el modelado de sistemas.
| Tipo de violación | Descripción | Impacto en la fiabilidad |
|---|---|---|
| Violación del tiempo de preparación | Los datos no están estables antes del borde del reloj. | Cambios de estado impredecibles, fallo de hardware. |
| Violación del tiempo de retención | Los datos cambian demasiado pronto después del borde del reloj. | Corrupción de datos, metastabilidad. |
| Caducidad del tiempo de espera | La operación tarda más de lo definido en el límite. | Indisponibilidad del servicio, tormentas de reintento. |
| Bloqueo | Dos procesos esperan indefinidamente el uno al otro. | Congelamiento del sistema, hambre de recursos. |
| Inversión de prioridad | Una tarea de alta prioridad espera a una tarea de baja prioridad. | Fallas en los plazos, fallo en tiempo real. |
| Desbordamiento de búfer | Los datos llegan más rápido de lo que pueden ser consumidos. | Pérdida de paquetes, agotamiento de memoria. |
Revisar estas categorías frente a los diagramas de temporización de su sistema ayuda a priorizar qué problemas requieren una corrección inmediata. Las violaciones de hardware a menudo requieren actualizaciones de firmware, mientras que los tiempos de espera de software podrían requerir una refactorización de lógica.
🔄 Integración en el Ciclo de Vida del Desarrollo
Para utilizar eficazmente los diagramas de temporización para la fiabilidad, deben integrarse en el ciclo de vida del desarrollo de software (SDLC). No deben ser una consideración posterior añadida tras la implementación.
- Fase de diseño: Cree diagramas de temporización de alto nivel durante las revisiones de arquitectura del sistema. Identifique rutas críticas y restricciones de temporización.
- Fase de implementación:Utilice diagramas de temporización para guiar las pruebas unitarias. Asegúrese de que las pruebas unitarias cubran los límites de temporización, no solo la corrección lógica.
- Fase de integración:Realice un análisis de temporización sobre los componentes integrados. Verifique que el sistema combinado cumpla con los requisitos globales de temporización.
- Fase de prueba:Utilice herramientas de prueba de carga para generar datos de temporización. Compare los registros de temporización reales con los diagramas originales.
- Fase de mantenimiento:Actualice los diagramas cuando los cambios de código afecten la temporización. Asegúrese de que la documentación permanezca sincronizada con la base de código.
Esta integración garantiza que las consideraciones de temporización formen parte de la conversación en cada etapa, reduciendo el costo de corregir problemas de fiabilidad más adelante en la cadena.
📊 Medición de las Mejoras en la Fiabilidad
¿Cómo cuantifica usted el beneficio de utilizar diagramas de temporización? Aunque la fiabilidad a menudo se mide en porcentajes de tiempo de actividad, los diagramas de temporización contribuyen a métricas específicas:
- Tiempo medio entre fallos (MTBF): Al prevenir condiciones de carrera y bloqueos, la frecuencia de fallos disminuye.
- Tiempo medio para reparar (MTTR): Una mejor documentación y registros visuales reducen el tiempo necesario para diagnosticar problemas.
- Percentiles de latencia: La latencia P99 y P999 se vuelve más estable cuando se identifican temprano los cuellos de botella de tiempo.
- Utilización de recursos: Optimizar los tiempos de espera reduce el tiempo de inactividad de la CPU y mejora el rendimiento general.
Seguimiento de estas métricas con el tiempo permite a los equipos ver la correlación directa entre el modelado riguroso del tiempo y la estabilidad del sistema. Transforma la confiabilidad de un objetivo cualitativo a una realidad cuantitativa.
💡 Resumen de las mejores prácticas
Para maximizar el impacto de los diagramas de tiempo en la confiabilidad del software, adhiera a las siguientes prácticas:
- Defina unidades de tiempo claras: Siempre especifique la unidad de tiempo (ms, s, ciclos) para evitar ambigüedades.
- Incluya estados de error: Modele no solo el camino feliz, sino también los caminos de tiempo de espera y los caminos de manejo de errores.
- Enfóquese en los caminos críticos: No dibuje cada operación individual. Enfóquese en las interacciones que afectan la estabilidad del sistema.
- Use una notación consistente: Adopte una notación estándar para las líneas de vida y eventos para garantizar una comprensión general en el equipo.
- Automatice cuando sea posible: Integre herramientas de análisis de tiempo en la canalización CI/CD para detectar regresiones automáticamente.
La confiabilidad del software es un esfuerzo continuo. Requiere vigilancia, modelado preciso y una comprensión profunda de cómo el tiempo afecta el comportamiento del sistema. Los diagramas de tiempo proporcionan la claridad visual necesaria para navegar esta complejidad. Al adoptar estas prácticas, los equipos de ingeniería pueden construir sistemas que no solo funcionen, sino que también sean robustos, predecibles y resistentes a la naturaleza impredecible del tiempo.
Cuando visualiza el tiempo, gana control sobre él. Este control se traduce directamente en confiabilidad. A medida que los sistemas crecen en distribución y complejidad, la capacidad de modelar relaciones temporales se convierte en una ventaja competitiva. Separa los sistemas que simplemente funcionan de aquellos que funcionan de manera consistente bajo presión.