











精確的專案估算是成功軟體開發的基石。在規劃系統時,理解背後的資料流動能為預測資源需求提供具體基礎。資料流程圖(DFD)是一種強大的視覺化工具,可用來描繪這些資料流動。透過分析DFD的結構複雜度,團隊能得出比僅依賴功能需求更可靠的工時估算。
本指南探討如何利用DFD複雜度指標來優化工時估算。我們將檢視推動複雜度的元件、量化這些要素的方法,以及如何將圖示分析轉化為專案時程的過程。
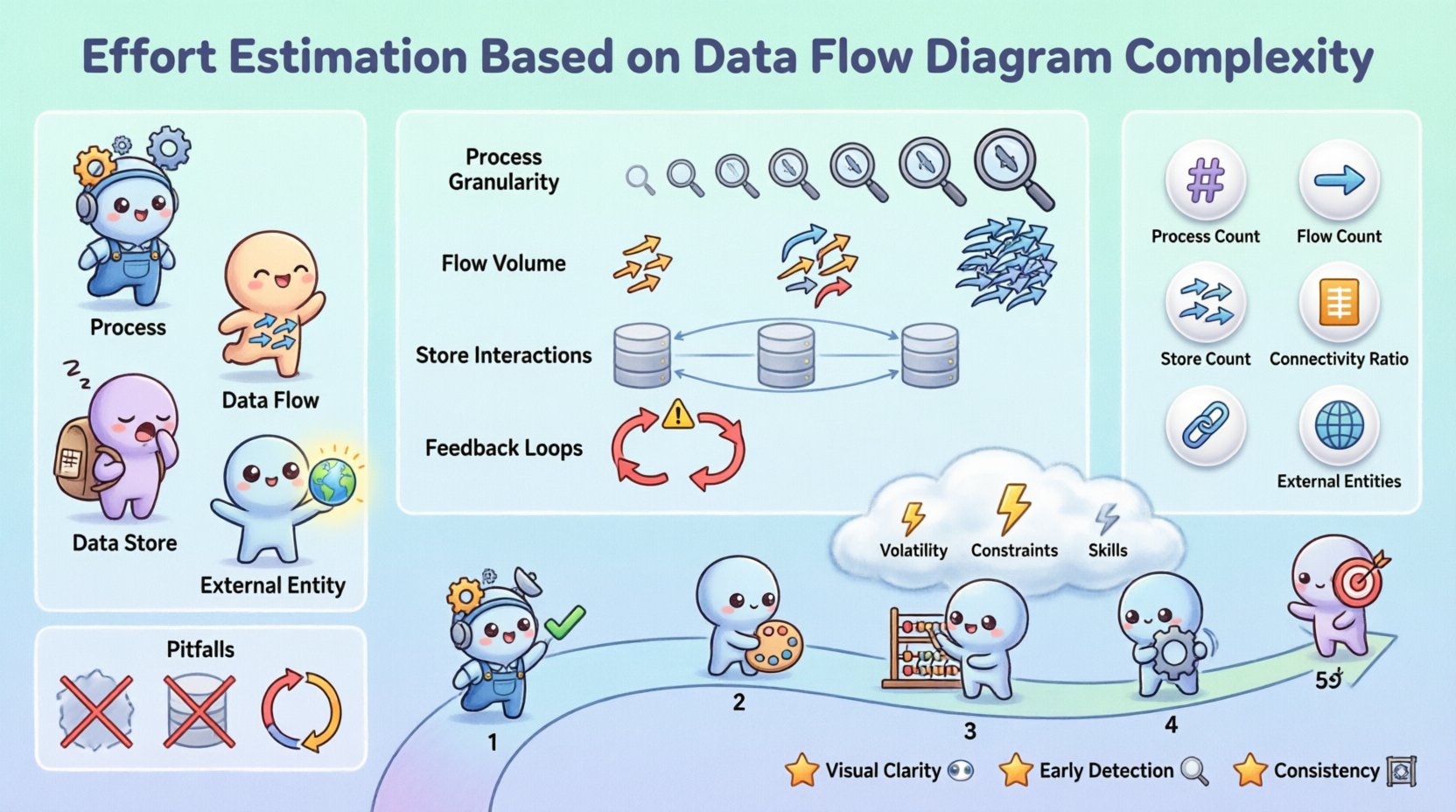
🔍 規劃中的資料流程圖理解
資料流程圖是一種以圖形方式呈現資料在資訊系統中流動的工具。與專注於控制邏輯的流程圖不同,DFD專注於資料轉換。在估算的脈絡下,DFD可作為相關工作的藍圖。
- 處理程序:代表資料的轉換。每個處理程序通常對應程式碼中的特定功能或模組。
- 資料流:顯示資料在處理程序、儲存體與實體之間的移動。這些代表介面與整合點。
- 資料儲存體:標示資料靜止存放的位置。這些對應資料庫表格或檔案系統。
- 外部實體:系統外部的資料來源或目的地。這些定義了整合需求。
在估算工時時,這些元件的視覺密度與連接性可提供執行系統所需認知負荷的線索。結構稀疏且流程線性的圖表暗示較低的複雜度,而密集的互動網絡則暗示顯著的整合挑戰。
🏗️ 識別複雜度驅動因素
並非所有資料流都相同。有些僅代表簡單的欄位傳輸,而有些則涉及複雜的商業邏輯、驗證或安全協定。為能精確估算,必須識別圖表中增加複雜度的特定驅動因素。
1. 處理程序的細緻程度
處理程序的細節層級至關重要。像「處理訂單」這樣的高階程序可能隱藏數十個子步驟。若DFD處於高階層級,估算時必須考慮該程序的分解。反之,詳細的第二或第三層DFD則能揭示實際的工作單元。
- 粗粒度的處理程序:需要更多分析時間來分解。
- 細粒度的處理程序:可進行更直接的估算,但可能忽略整合的額外負荷。
2. 資料流數量
連接元件的箭頭數量代表資料處理的數量。每個箭頭代表一個必須經過驗證、轉換,並儲存或傳輸的資料結構。
- 更多的資料流通常意味著更多的API端點或資料庫查詢。
- 複雜的資料流可能需要錯誤處理與重試邏輯。
3. 資料儲存體互動
每次與資料儲存體的互動都會帶來延遲考量、並發問題與結構管理。同時讀取與寫入多個儲存體的處理程序,比僅與單一儲存體互動的程序更為複雜。
4. 反饋迴圈
圖表中的迴圈表示反覆處理或狀態變更。這些通常是開發中最容易出錯的區域。估算迴圈時,必須考慮狀態在多個週期中持續維持的測試情境。
📏 評估的量化指標
從定性觀察轉向定量估算,可以應用從資料流程圖(DFD)推導出的特定指標。這些指標有助於在不同專案之間標準化估算流程。
| 指標 | 描述 | 對工作量的影響 |
|---|---|---|
| 流程數量 | 轉換節點的總數。 | 與功能點直接相關。 |
| 資料流數量 | 資料移動箭頭的總數。 | 顯示整合與介面的複雜度。 |
| 儲存體數量 | 資料儲存庫的總數。 | 影響資料庫設計與遷移工作量。 |
| 連接度比率 | 資料流與流程的比率。 | 高比率表示系統之間緊密耦合。 |
| 外部實體數量 | 所涉及的外部系統數量。 | 增加溝通與依賴風險。 |
透過累加這些數值,可以建立一個複雜度指數。例如,一個簡單系統可能有 5 個流程和 10 個資料流,而一個複雜系統可能有 50 個流程和 150 個資料流。此指數可再乘以根據歷史資料所確定的基準工作量係數。
🛠️ 評估流程
將資料流程圖(DFD)轉換為工作量估算,需要採取結構化的方法。遵循以下步驟,以確保規劃的一致性與準確性。
步驟 1:驗證圖表完整性
在進行估算之前,請確保資料流程圖(DFD)準確反映需求。遺漏的資料流或實體將導致低估。請確認每個資料需求都有對應的資料流,且每個流程都有明確的輸入與輸出。
步驟 2:分類流程複雜度
並非所有流程都需要相同的工作量。根據流程的邏輯,為每個流程分配複雜度權重。
- 簡單:直接的資料對應或取得。(權重:1)
- 中等: 包含驗證、計算或格式化。(權重:2)
- 複雜: 涉及多個資料儲存、外部 API 或複雜演算法。(權重:3)
步驟 3:計算基礎努力值
將每個類別中的流程數量乘以其相應的權重,並將這些值相加,以獲得基礎複雜度分數(BCS)。
公式: BCS =(簡單數量 × 1)+(中等數量 × 2)+(複雜數量 × 3)
步驟 4:調整流程複雜度
大量資料流動會增加介面開發所需的 effort。根據總流程數與流程數的相對關係,套用流程乘數。
- 低比率(每流程 ≤ 2 個流程): 乘數 1.0
- 中等比率(每流程 3-5 個流程): 乘數 1.2
- 高比率(每流程 > 5 個流程): 乘數 1.5
步驟 5:納入外部依賴
外部實體會帶來風險。每個外部系統都需要整合測試、安全設定,以及可能的供應商協調。為每個外部實體增加固定的時間緩衝。
⚠️ 調整風險與不確定性
即使擁有詳細的 DFD,不確定性依然存在。變更的需求或技術負債等因素可能改變所需的 effort。應調整您的估計以反映這些風險。
1. 需求波動性
如果業務需求在開發期間可能變更,DFD 可能需要大幅修改。在此情況下,應在總 effort 中增加 15-20% 的應變緩衝。
2. 技術限制
舊系統或特定基礎設施需求可能使資料流更複雜。如果 DFD 显示資料移動至舊式主機,處理該連接的 effort 可能高於標準 API 呼叫。
3. 團隊技能水平
估計假設具備基本能力。如果團隊對該領域或技術堆疊不熟悉,DFD 流程的複雜性可能轉化為更多學習時間。應相應調整每流程單位的時間。
🚫 DFD 分析中的常見陷阱
避免常見錯誤對於維持估計的完整性至關重要。多個陷阱可能導致嚴重的誤估。
- 忽略資料驗證: DFD 展示資料移動,但未顯示其應用的規則。驗證邏輯通常佔流程 effort 的 20-30%。
- 忽略錯誤處理: 正常流程很容易繪製。錯誤路徑、重試和記錄會為每個流程增加隱藏的複雜性。
- 假設線性增長: 複雜度通常以非線性方式增長。由於需要確保事務一致性,增加一個資料儲存庫可能會使連接複雜度呈指數級增加。
- 忽視安全性: 加密、驗證和授權層級在資料流程圖中通常隱含存在。估算時應明確考慮這些因素。
- 僅關注流程: 資料儲存和資料流通常比流程本身更耗時於設定與測試。
📅 將估算整合至專案時程
估算完成後,必須對應到時程上。這包括資源配置與里程碑定義。
- 分階段交付: 根據資料流依賴關係分組流程。優先交付高優先級的資料流以降低風險。
- 並行工作流: 若流程彼此獨立,則可並行開發。利用資料流程圖識別獨立的群組。
- 整合測試: 計畫專門時間用於測試資料流的完整性。這通常是複雜資料流程圖失敗的地方。
透過將時程與圖中顯示的結構依賴關係對齊,可建立符合實際的時間軸,尊重系統的自然運作流程。
🔄 長期維持準確性
估算並非一成不變。隨著專案推進與資料流程圖的演變,估算應重新校準。
- 基準更新: 當資料流程圖定稿後,以實際複雜度分數更新初始估算。
- 回顧分析: 每個階段結束後,將估算的複雜度分數與實際投入的工時進行比較。這能優化未來專案的權重因子。
- 變更管理: 資料流程圖的任何變更都應觸發重新估算。不要假設增加一個小資料流的影響可忽略不計。
🛡️ 基於資料流程圖規劃的最終考量
利用資料流程圖進行工時估算,提供了一種結構化且客觀的方法來評估專案規模。這使討論從猜測轉向對系統實際資料架構的分析。
雖然沒有模型是完美的,但資料流程圖複雜度方法具有顯著優勢:
- 視覺清晰度:利害關係人可以清楚看到資料的流動,使工時的合理性變得透明。
- 早期發現:複雜的流程可以在編碼開始之前被識別出來,從而允許進行架構調整。
- 一致性:在不同專案中應用相同的指標,可以實現更好的組合管理。
請記住,目標不是完美,而是有根據的規劃。定期審查您的複雜度因素並更新基準。隨著您的團隊對特定類型的流程和過程變得更加熟悉,您預測工作量的能力將自然提升。
通過將DFD視為主要估算工具,您能將規劃與您正在構建的系統的基本特性保持一致。這將帶來更現實的預算、時程,最終實現更成功的軟體解決方案交付。