











En la arquitectura de software moderna, comprender cómo se mueve la información es tan crítico como entender cómo se almacena. Un diagrama de flujo de datos (DFD) sirve como plano maestro para este movimiento, representando el recorrido de los datos desde la entrada hasta la salida. Al diseñar sistemas pensados para manejar el crecimiento, estos diagramas evolucionan de simples bocetos a mapas complejos que determinan el rendimiento, la confiabilidad y la mantenibilidad. Esta guía explora los patrones esenciales utilizados para modelar flujos de datos en entornos escalables.
La escalabilidad no consiste únicamente en agregar más servidores; se trata de reestructurar cómo los datos recorren el sistema para evitar cuellos de botella. Al aplicar patrones específicos de DFD, los arquitectos pueden visualizar los límites de capacidad antes de que se conviertan en problemas de producción. Este enfoque garantiza que el flujo lógico de la información respalde tanto los requisitos actuales como la expansión futura.
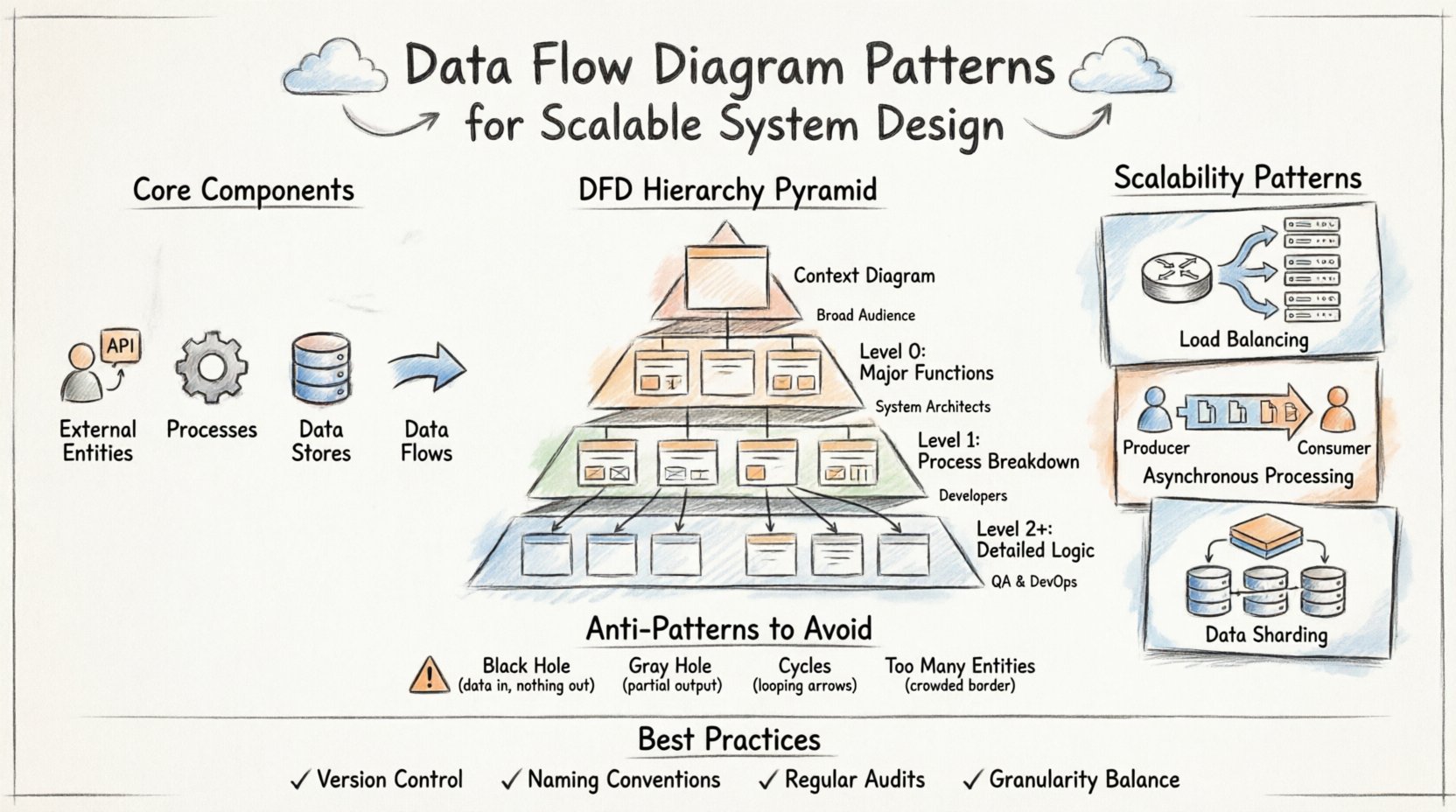
🧩 Componentes principales de un diagrama de flujo de datos
Antes de adentrarse en los patrones, uno debe dominar los bloques de construcción. Cada DFD depende de cuatro elementos fundamentales. Confundirlos conduce a modelos ambiguos que no guían eficazmente el desarrollo.
- Entidades externas: Representan fuentes o destinos fuera de los límites del sistema. Incluyen usuarios, APIs de terceros o dispositivos de hardware.
- Procesos: Transforman los datos de una forma a otra. Son los puntos de cálculo activos o lógica de negocio dentro del sistema.
- Almacenes de datos: Lugares donde los datos permanecen almacenados. Pueden ser bases de datos, sistemas de archivos o cachés de memoria.
- Flujos de datos: Los caminos que siguen los datos entre entidades, procesos y almacenes. Las flechas indican dirección y contenido.
Cada componente debe definirse claramente para evitar ambigüedades. Por ejemplo, un proceso nunca debe tener una flecha que apunte a otro proceso sin un flujo de datos correspondiente. Cada flecha debe representar información real que se mueve a través del sistema.
📉 La jerarquía de los niveles de DFD
Los sistemas escalables requieren diferentes niveles de abstracción. Un solo diagrama rara vez capta toda la complejidad. En su lugar, se utiliza una jerarquía para descender desde un contexto de alto nivel hasta la lógica de implementación detallada. Esta estructura permite a los equipos revisar la visión general sin perderse en los detalles.
| Nivel | Enfoque | Complejidad | Público principal |
|---|---|---|---|
| Diagrama de contexto | Límite del sistema y las interacciones externas | Baja | Partes interesadas, Gestión |
| Nivel 0 (DFD 0) | Funciones principales del sistema y almacenes de datos | Media | Arquitectos del sistema |
| Nivel 1 | Desglose de los procesos del Nivel 0 | Alto | Desarrolladores, Ingenieros |
| Nivel 2+ | Lógica algorítmica o de subproceso específica | Muy alto | Ingenieros especializados |
Mantener la consistencia entre estos niveles es fundamental. Una base de datos identificada en el Nivel 0 debe referenciarse correctamente en el Nivel 1. Si un proceso se divide en el Nivel 1, los flujos de entrada y salida deben coincidir con el proceso padre en el Nivel 0. Este equilibrio garantiza que el modelo siga siendo una referencia confiable durante todo el ciclo de vida.
🚀 Patrones de escalabilidad en la arquitectura de sistemas
Diseñar para escalar requiere elecciones específicas de modelado. Los diagramas estándar a menudo ocultan los mecanismos de manejo de carga. Para abordar la escalabilidad, los arquitectos deben representar explícitamente patrones que distribuyan el trabajo o gestionen los recursos.
1. Equilibrio de carga y distribución
En sistemas de alto tráfico, un solo proceso no puede manejar todas las solicitudes entrantes. El DFD debe reflejar el mecanismo de distribución.
- Patrón de enrutador: Introduce un nodo de proceso que dirige el tráfico a múltiples nodos de servicio.
- Replicación: Muestra múltiples procesos idénticos que reciben el mismo flujo de datos para un procesamiento paralelo.
- Colas: Representa una base de datos que actúa como búfer antes de que comience el procesamiento, suavizando los picos.
Al dibujar un enrutador, asegúrate de que el flujo se divida lógicamente. Si el sistema utiliza una estrategia de round-robin, el diagrama debe indicar que la decisión se basa en la carga y no en el contenido de los datos. Esta distinción afecta la forma en que se implementa la lógica del backend.
2. Procesamiento asíncrono
Los flujos síncronos pueden crear cuellos de botella si una etapa espera a otra. Los patrones asíncronos desacoplan los procesos, permitiendo que el sistema se escale de forma independiente.
- Colas de mensajes: Usa una base de datos para representar una cola. El productor escribe en la base de datos, y el consumidor la lee más tarde.
- Flujos de eventos: Muestra un proceso que emite un evento que activa múltiples consumidores posteriores sin bloquear al emisor.
- Trabajos en segundo plano: Separa las tareas de larga duración de las solicitudes dirigidas al usuario redirigiéndolas a un grupo de procesos dedicado.
Esta separación permite que los procesos dirigidos al usuario permanezcan ligeros mientras se realiza el trabajo pesado en segundo plano. El DFD hace visible esta separación, evitando que los desarrolladores asuman tiempos de respuesta inmediatos.
3. Fragmentación y partición de datos
A medida que crece el volumen de datos, las unidades de almacenamiento individuales se convierten en barreras de rendimiento. Los patrones de fragmentación en los DFD ayudan a visualizar cómo se divide el dato entre múltiples almacenes.
- Divisiones horizontales: Muestra un proceso que enruta subconjuntos de datos específicos a diferentes almacenes de datos según una ID o clave.
- Réplicas de lectura: Indique flujos separados para leer datos de réplicas mientras las escrituras van al almacén principal.
- Capas de caché: Inserte un almacén de datos de caché entre el proceso y la base de datos principal para reducir la latencia.
| Patrón | Beneficio de escalabilidad | Compromiso |
|---|---|---|
| Equilibrio de carga | Aumenta el rendimiento | Mayor complejidad en la gestión del estado |
| Colas asíncronas | Desacopla dependencias | Consistencia eventual |
| Fragmentación | Amplía la capacidad de almacenamiento | Consultas complejas entre fragmentos |
| Caché | Reduce la latencia | Riesgos de obsolescencia de datos |
⚠️ Patrones anti-comunes que deben evitarse
Incluso con buenas intenciones, los diagramas de flujo de datos pueden contener fallas estructurales que provocan fallos del sistema. Reconocer estos patrones anti-comunes temprano evita reingenierías costosas más adelante.
1. El agujero negro
Un agujero negro ocurre cuando un proceso recibe datos pero no produce ninguna salida. Esto suele ocurrir cuando se asume que un proceso elimina datos o los procesa en silencio.
- Riesgo:Pérdida de datos sin notificación de error.
- Solución: Asegúrese de que cada entrada tenga un flujo de salida correspondiente o una ruta de error clara.
- Impacto en la escalabilidad:Los fallos silenciosos son difíciles de depurar en sistemas distribuidos.
2. El Agujero Gris
Un agujero gris es similar a un agujero negro, pero con una salida parcial. El proceso consume más datos de los que produce, pero no explica adónde fueron los restantes.
- Riesgo:El consumo de datos no explicado conduce a fugas de almacenamiento o errores en transacciones.
- Solución:Modelar explícitamente todos los caminos de datos, incluidos los registros de errores o rastros de auditoría.
3. Ciclos en el Flujo de Datos
Aunque algunos bucles de retroalimentación son necesarios (por ejemplo, mecanismos de reintento), los ciclos no controlados pueden causar bucles de procesamiento infinitos.
- Riesgo:Cuelgues del sistema o agotamiento de recursos.
- Solución:Limitar la profundidad de recursión en el diagrama e implementar mecanismos de tiempo de espera en el diseño.
4. Entidades Externas Infinitas
Agregar demasiadas entidades externas hace que el diagrama sea ilegible y oculta la lógica principal.
- Riesgo:Pérdida de claridad sobre los límites del sistema.
- Solución:Agrupar entidades relacionadas en una única entidad de tipo «Sistema de Registro» o «Interfaz de Usuario», según corresponda.
🔄 Mejores Prácticas para el Mantenimiento y la Evolución
Un diagrama de flujo de datos no es un artefacto único. Debe evolucionar conforme crece el sistema. Mantener el modelo actualizado garantiza que los nuevos miembros del equipo entiendan la arquitectura sin tener que realizar ingeniería inversa del código.
- Control de Versiones:Tratar los diagramas como código. Almacenarlos en un repositorio para rastrear los cambios con el tiempo.
- Convenciones de Nombres:Utilizar nombres consistentes para procesos y flujos de datos. «Actualizar Usuario» siempre debe ser «Actualizar Usuario», no «Cambiar Detalles del Usuario».
- Revisiones Regulares:Programar revisiones periódicas para asegurar que el diagrama coincida con la implementación actual.
- Equilibrio de Granularidad:No convierta cada proceso en un subproceso. Agrupe la lógica relacionada para mantener una visión manejable del sistema.
📝 Consideraciones Finales
Un diseño de sistema efectivo depende de una comunicación clara. El Diagrama de Flujo de Datos proporciona un lenguaje compartido entre arquitectos, desarrolladores y partes interesadas. Al seguir patrones establecidos y evitar errores comunes, los equipos pueden construir sistemas que crezcan de manera adecuada.
Recuerda que los diagramas son modelos, no la realidad misma. Simplifican la complejidad para hacerla comprensible. Sin embargo, la simplificación no debe eliminar detalles críticos relacionados con la integridad y el flujo de datos. Cuando un diagrama de flujo de datos (DFD) refleja con precisión el movimiento de datos, se convierte en una herramienta poderosa para predecir cuellos de botella y optimizar el rendimiento.
A medida que los sistemas se vuelven más distribuidos, aumenta la necesidad de un modelado riguroso. Los patrones descritos aquí proporcionan una base para esa rigurosidad. Ya sea que estés diseñando una aplicación monolítica o un ecosistema de microservicios, los principios del flujo de datos permanecen constantes. Enfócate en el movimiento de la información, y la estructura seguirá.
Comienza con el diagrama de contexto. Define claramente los límites. Desciende a los procesos solo cuando sea necesario. Mantén el enfoque en los datos, no en la pila tecnológica. Esta disciplina garantiza que la arquitectura permanezca flexible y escalable durante muchos años.