











Crear modelos de sistemas robustos requiere un enfoque disciplinado sobre cómo se captura, mueve y retiene la información. En el contexto de los diagramas de flujo de datos (DFD), el almacén de datos representa la columna vertebral de la persistencia del sistema. Sin un diseño claro sobre dónde reside la data, el flujo de información permanece abstracto e inimplementable. Esta guía explora los principios fundamentales para diseñar almacenes de datos dentro de los DFD, asegurando claridad, precisión y alineación con la arquitectura del sistema.
Una modelización efectiva va más allá de dibujar líneas entre formas. Exige una comprensión profunda de la integridad de los datos, los patrones de acceso y el ciclo de vida de la información dentro del sistema. Al adherirse a principios de diseño establecidos, los analistas pueden producir diagramas que sirvan como planos confiables para los equipos de desarrollo.
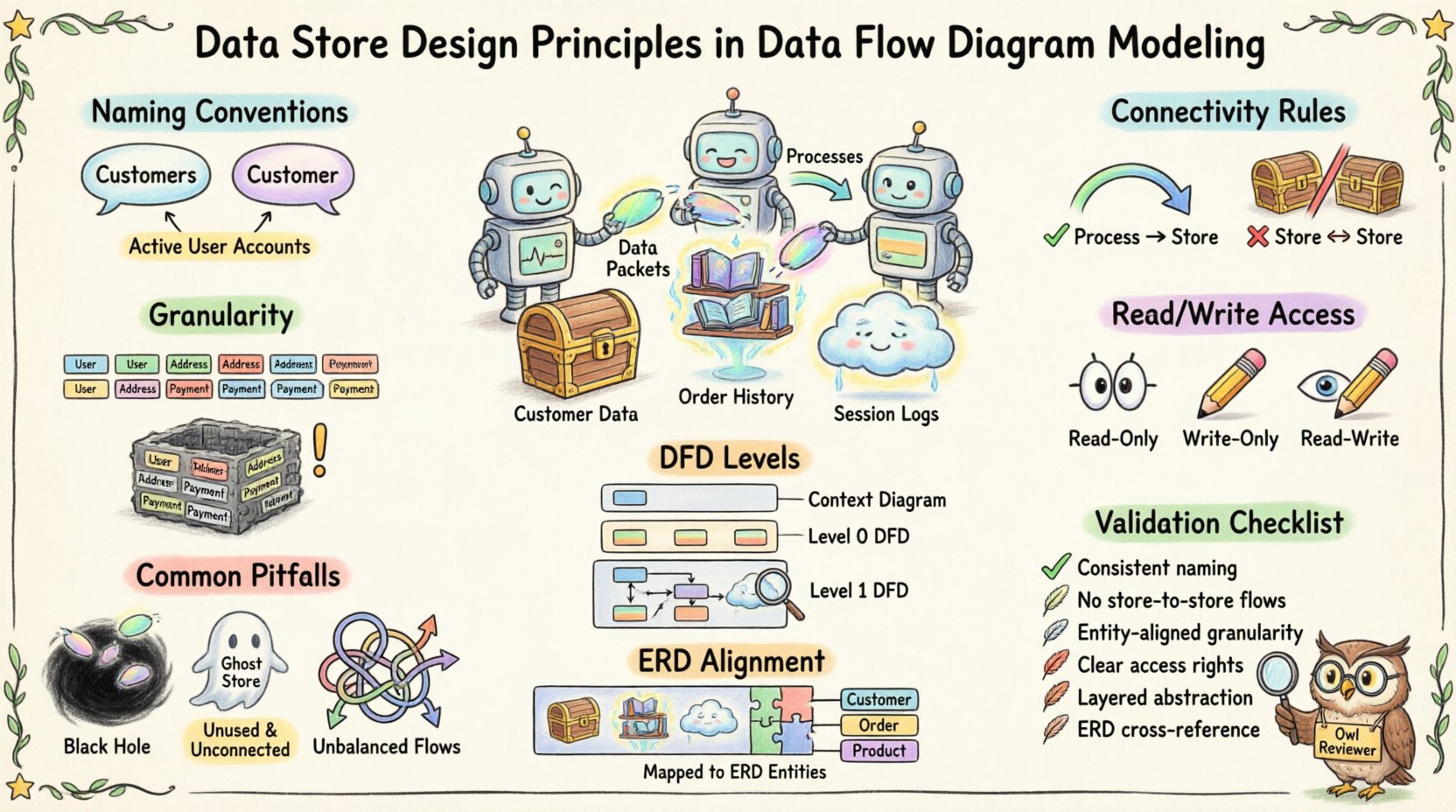
🏷️ Definición del almacén de datos 🏷️
Un almacén de datos es un elemento pasivo en un diagrama de flujo de datos. A diferencia de los procesos, que transforman datos, los almacenes de datos almacenan datos en reposo. Representan archivos, bases de datos, registros en papel o cualquier repositorio donde se guarda la información para su recuperación posterior.
- Naturaleza pasiva:Los datos no fluyen fuera de un almacén a menos que un proceso lo solicite explícitamente.
- Identidad del almacenamiento:No es un proceso en sí mismo; no modifica los datos, solo los almacena.
- Representación visual:Normalmente se representa como un rectángulo sin cerrar o como líneas verticales dobles, dependiendo del estándar de notación utilizado.
Al diseñar estos elementos, el enfoque debe centrarse en el requisito lógico y no en la implementación física. El DFD describequédatos se necesitan, nocómose indexan físicamente o se almacenan en un disco duro.
📝 Convenciones de nomenclatura para claridad 📝
La nomenclatura es la primera línea de defensa contra la confusión. Las etiquetas ambiguas conducen a malentendidos durante la fase de diseño. Un almacén de datos bien nombrado proporciona contexto inmediato sobre la información que contiene.
1. Singular vs. Plural
La consistencia es clave. Algunas equipos prefieren sustantivos en singular (por ejemplo, Cliente) mientras que otros usan plural (por ejemplo, Clientes). El factor crítico es que todo el modelo utilice la misma convención.
- Recomendación:Utilice sustantivos en plural para conjuntos de datos (por ejemplo, Pedidos, Productos) para indicar una colección.
- Excepción:Los nombres singulares funcionan para instancias específicas si el almacén contiene solo un tipo de registro (por ejemplo, Configuración).
2. Precisión descriptiva
Evite términos genéricos como Datos o Info. Estas etiquetas no proporcionan ninguna información sobre el contenido.
- Mal ejemplo: Datos del sistema
- Buen ejemplo: Cuentas de usuarios activos
Una nomenclatura específica ayuda a los interesados a identificar de inmediato el alcance del almacén. Reduce la carga cognitiva necesaria para comprender el diagrama.
3. Tiempo y estado
Los nombres deben reflejar el estado de los datos. Si el almacén contiene registros históricos, el nombre debe reflejarlo.
- Registros de transacciones implica un registro de eventos pasados.
- Pedidos pendientes implica datos esperando una acción.
🔗 Reglas de conectividad 🔗
El movimiento de datos hacia adentro y hacia afuera de un almacén está regido por reglas lógicas estrictas. Violar estas reglas rompe la integridad del DFD.
1. Requisito de conexión con proceso
Un almacén de datos debe estar siempre conectado a al menos un proceso. No puede existir de forma aislada.
- Entrada: Un proceso debe escribir datos en el almacén (por ejemplo, guardando un nuevo registro).
- Salida: Un proceso debe leer datos desde el almacén (por ejemplo, recuperando un registro).
Si un almacén no está conectado a nada, es un elemento fantasma sin función. Si está conectado a múltiples procesos, el flujo de datos debe estar claramente definido para cada conexión.
2. No flujo directo de almacén a almacén
Los datos no pueden moverse directamente de un almacén de datos a otro sin un proceso intermedio. Esta regla refuerza el principio de que la transformación o validación de datos ocurre antes del almacenamiento.
- Incorrecto: Línea que conecta Almacén A directamente a Almacén B.
- Correcto: Proceso X lee desde Almacén A, transforma los datos y escribe en Almacén B.
Esta separación garantiza que la lógica de negocio, la validación o el formato se apliquen antes de que los datos se persistan. Evita que el modelo sugiera que los datos se copian simplemente sin supervisión.
3. Etiquetado del flujo de datos
Cada línea que conecta un proceso con un almacén de datos debe estar etiquetada. La etiqueta describe los datos específicos que se mueven a través de esa frontera.
- Ejemplo: Una línea desde Proceso de Pedido a Almacén de Pedidos podría estar etiquetada como Detalles del Pedido.
- Ejemplo: Una línea desde Almacén de Pedidos a Proceso de informe podría estar etiquetado comoHistorial de pedidos.
Las etiquetas proporcionan contexto sobre el volumen y el tipo de datos que se transfieren. Ayudan a los desarrolladores a comprender los requisitos de esquema más adelante.
🎯 Granularidad y alcance 🎯
Decidir cómo dividir los datos en almacenes es una decisión de diseño crítica. Demasiados almacenes fragmentan el modelo, mientras que demasiados pocos crean un bloque monolítico de información.
1. Agrupación basada en entidades
Agrupa los datos por entidad lógica. Si el sistema rastrea clientes, productos e facturas, estos generalmente deben residir en almacenes separados.
- Beneficio:Simplifica la mantenibilidad. Los cambios en los datos del cliente no afectan la lógica de almacenamiento de facturas.
- Beneficio:Reduce el riesgo de corrupción accidental de datos durante las actualizaciones.
2. Separación de lectura y escritura
Considera si un almacén es principalmente para lectura o escritura. Los registros de transacciones de alto volumen a menudo requieren un manejo de almacenamiento diferente que los datos de referencia.
- Datos de referencia: Almacenes comoCódigos de país son de alta lectura y rara vez cambian.
- Datos de transacción: Almacenes comoRegistros de ventas son de alta escritura y crecen con el tiempo.
Distinguir estos tipos ayuda en la planificación de la capacidad y los patrones de acceso, aunque el DFD siga siendo un modelo lógico.
3. Temporal frente a permanente
No todos los almacenes de datos representan una retención permanente. Algunos son búferes temporales.
- Datos de sesión: Almacenes utilizados para sesiones de usuario temporales durante un proceso de inicio de sesión.
- Almacenes de caché: Áreas temporales de almacenamiento para datos frecuentemente accedidos.
Marcar claramente los almacenes temporales evita la confusión respecto a las políticas de retención de datos. Un almacén temporal debe vaciarse o limpiarse una vez que el proceso finalice.
🔄 Flujo de datos e interacción de procesos 🔄
La relación entre un proceso y un almacén de datos es bidireccional en muchos casos, pero no siempre. Comprender la direccionalidad es esencial para un modelado preciso.
1. Acceso de solo lectura
Algunos almacenes se acceden únicamente para leer. Un proceso podría consultar un almacén para mostrar información sin modificarla.
- Ejemplo: Un Mostrar perfil proceso leyendo desde Almacén de perfiles de usuario.
- Restricción:No debe haber ninguna flecha de flujo de datos que vaya desde el almacén hacia el proceso Y de vuelta para la misma transacción, a menos que implique una operación de escritura.
2. Acceso de solo escritura
Algunos procesos escriben datos sin necesidad de recuperarlos primero.
- Ejemplo: Un Registro de eventos proceso escribiendo en Almacén de auditoría del sistema.
- Restricción:Asegúrese de que el proceso cuente con el contexto necesario para escribir los datos correctamente sin entrada externa.
3. Acceso de lectura y escritura
La mayoría de los procesos empresariales implican recuperar, modificar y guardar datos.
- Ejemplo: Actualizar inventariolee el stock actual, calcula la nueva cantidad y la guarda.
- Modelado:Utilice flujos separados para lectura y escritura para aclarar la secuencia de operaciones.
Esta distinción ayuda a los desarrolladores a entender si una transacción de base de datos requiere un bloqueo o un commit de inmediato.
📊 Niveles de DFD y visibilidad de almacenes 📊
Los DFD a menudo se descomponen en niveles, desde diagramas de contexto (nivel 0) hasta desgloses detallados (nivel 2, nivel 3). Los almacenes de datos aparecen de manera diferente en cada nivel.
1. Nivel de contexto (nivel 0)
En el nivel más alto, los almacenes de datos a menudo se omiten para mantener la simplicidad. El enfoque está en las entidades externas y la frontera principal del sistema.
- Razón:Demasiados detalles oscurecen el intercambio de datos de alto nivel.
- Excepción:Las bases de datos externas importantes podrían mostrarse si son críticas para la frontera del sistema.
2. Descomposición de nivel 1
A medida que el sistema se descompone en procesos principales, los almacenes de datos se vuelven visibles. Aquí se define la arquitectura principal de almacenamiento.
- Enfoque:Identifique los almacenes centrales necesarios para cada función principal.
- Detalles:Asegúrese de que cada proceso tenga un destino para sus datos de salida.
3. Nivel 2 y más allá
Una descomposición adicional puede dividir grandes almacenes de datos en otros más pequeños y específicos.
- Ejemplo: Almacén de clientes en el nivel 1 podría dividirse en Almacén de información de contacto y Almacén de facturación en el nivel 2.
- Consistencia:Asegúrese de que los datos en niveles inferiores coincidan con los datos en niveles superiores. No introduzca nuevos tipos de datos que no estuvieran presentes en el diagrama padre.
⚠️ Errores comunes ⚠️
Incluso analistas con experiencia cometen errores al diseñar almacenes de datos. Evitar estos errores comunes asegura que el diagrama permanezca preciso.
- Agujeros negros:Un proceso que recibe datos pero no los escribe en ningún lugar. Esto implica pérdida de datos.
- Tormentas de fuego: Un proceso que recibe datos pero genera datos sin almacenarlos. Esto implica que los datos surgen de la nada (milagro).
- Almacenes fantasma: Almacenes de datos sin procesos conectados. Estos son puntos muertos.
- Flujos desequilibrados: Al pasar del Nivel 1 al Nivel 2, las entradas y salidas deben coincidir. Si se añade un almacén en el Nivel 2, debe justificarse mediante las entradas/salidas del proceso padre.
- Sobrediseño: Intentar modelar cada tabla de base de datos como un almacén independiente en un diagrama del Nivel 1. Adhírese a entidades lógicas, no a tablas físicas.
📚 Alineación con modelos de datos 📚
Mientras que los DFD se centran en el flujo, deben alinearse con Diagramas de Relación de Entidades (ERD) o modelos de datos lógicos. Los almacenes de datos en el DFD deben corresponder a las entidades en el ERD.
- Verificación de consistencia: Si el DFD tiene un Almacén de Producto, el ERD debería tener una Producto entidad.
- Asignación de atributos: Los atributos requeridos por el proceso para interactuar con el almacén deben existir en el modelo de datos.
- Normalización: Aunque los DFD no imponen la normalización, el diseño debe evitar redundancias evidentes que sugieran un mal diseño de base de datos.
Esta alineación garantiza que el diseño lógico (DFD) pueda traducirse en una implementación física (esquema de base de datos) sin una reestructuración significativa.
🔍 Lista de verificación de validación de diseño 🔍
Antes de finalizar un diagrama de flujo de datos, utilice la siguiente lista de verificación para validar el diseño de almacenes de datos.
| Principio | Elemento de la lista de verificación | Estado |
|---|---|---|
| Nomenclatura | ¿Todos los nombres de almacén son descriptivos y coherentes? | ☐ |
| Conectividad | ¿Está cada almacén conectado a al menos un proceso? | ☐ |
| Dirección del flujo | ¿Las flechas apuntan correctamente entre procesos y almacenes? | ☐ |
| Etiquetado | ¿Los datos fluyen a través de líneas etiquetadas con nombres de contenido? | ☐ |
| Sin enlaces directos entre almacenes | ¿Hay alguna línea que conecte directamente un almacén con otro almacén? | ☐ |
| Consistencia | ¿Los almacenes de nivel inferior coinciden con el alcance del nivel padre? | ☐ |
| Integridad | ¿Se cumplen todos los requisitos de datos para los procesos con los almacenes disponibles? | ☐ |
🔄 Mantenimiento y evolución 🔄
Los requisitos del sistema cambian. Los almacenes de datos deben ser adaptables a estos cambios sin romper el modelo.
- Control de versiones: Mantenga un registro de los cambios en las definiciones de almacenes. Si un almacén se divide, documente la ruta de migración.
- Datos heredados: Planee cómo se manejarán los datos antiguos cuando cambie el esquema de un almacén. Esto a menudo requiere un almacén de archivo.
- Bucle de retroalimentación: Utilice la retroalimentación de los equipos de desarrollo para afinar la granularidad del almacén. Si los desarrolladores encuentran un almacén demasiado amplio, divídalo. Si lo encuentran demasiado fragmentado, márquelo.
Un modelo estático es una carga. El diseño del almacén de datos debe revisarse cada vez que cambien las reglas de negocio o se introduzcan nuevos requisitos de cumplimiento. Esto garantiza que el DFD siga siendo un documento vivo que refleje con precisión las necesidades de datos del sistema.
📝 Conclusión sobre la implementación
Diseñar almacenes de datos en diagramas de flujo de datos es una tarea fundamental para el análisis del sistema. Cierra la brecha entre procesos abstractos y la persistencia concreta de datos. Al seguir convenciones de nomenclatura estrictas, reglas de conectividad y principios de granularidad, los analistas crean modelos que son tanto legibles como accionables.
El objetivo no es replicar perfectamente el esquema de la base de datos, sino capturar la necesidad lógica del almacenamiento de datos. Cuando el DFD es preciso, la transición hacia el desarrollo es más fluida y el riesgo de pérdida de datos o desalineación se reduce significativamente. Enfóquese en la claridad, la consistencia y el flujo lógico de la información para producir diseños de sistemas de alta calidad.