











Dans le paysage de l’architecture système et de l’ingénierie de la sécurité, visualiser le déplacement des données n’est pas simplement un exercice de conception ; c’est une pratique fondamentale de sécurité. Un diagramme de flux de données (DFD) sert de carte pour l’information qui traverse un système. Lorsqu’il est correctement utilisé pour l’analyse des risques, cette carte devient un outil essentiel pour identifier les vulnérabilités avant qu’elles ne se manifestent dans les environnements de production. Ce guide détaille la méthodologie pour intégrer directement les stratégies d’identification et d’atténuation des risques dans le processus de création du DFD.
La sécurité n’est pas une fonctionnalité additionnelle ; c’est une propriété intrinsèque de la conception. En examinant comment les données circulent entre les entités externes, les processus et les magasins de données, les architectes peuvent identifier précisément où les frontières de confiance sont franchies, où des informations sensibles sont exposées et où des contrôles manquent. Les sections suivantes explorent les mécanismes de cette approche, en passant des concepts fondamentaux à son application concrète.
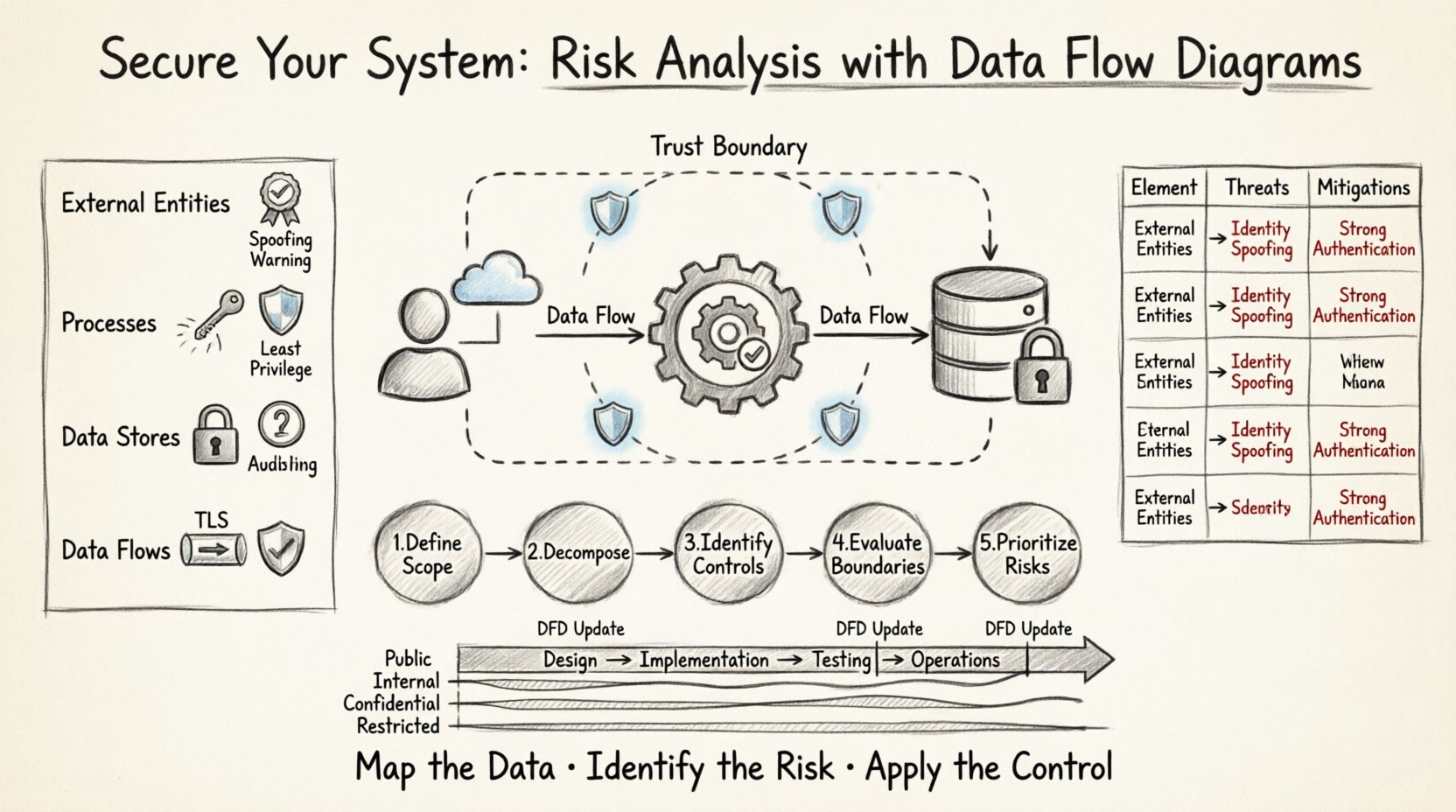
🧩 Comprendre les éléments fondamentaux d’un diagramme de flux de données
Avant d’analyser les risques, il faut comprendre les composants qui sont analysés. Un DFD se compose de quatre éléments principaux. Chaque élément comporte des implications de sécurité spécifiques qui doivent être évaluées lors du processus de revue.
- Entités externes : Elles représentent les sources ou destinations des données situées en dehors des limites du système. Des exemples incluent les utilisateurs, d’autres systèmes ou des services tiers. Implication de sécurité : Les entités sont souvent à l’origine d’attaques par usurpation d’identité ou de tentatives d’accès non autorisées. Chaque entité doit être authentifiée et autorisée avant d’interagir avec les processus internes.
- Processus : Ce sont les fonctions ou les transformations qui agissent sur les données. Elles transforment les données d’entrée en données de sortie. Implication de sécurité : Les processus sont là où se produisent les erreurs de logique. Si un processus ne valide pas correctement les entrées, cela peut entraîner des attaques par injection ou des contournements de logique. Il est essentiel de s’assurer que le principe du moindre privilège s’applique au contexte d’exécution de chaque processus.
- Magasins de données : Elles représentent les lieux où les données sont stockées au repos. Elles peuvent être des bases de données, des fichiers ou des tampons mémoire. Implication de sécurité : Les magasins de données sont la cible principale des exfiltrations. Les contrôles d’accès, le chiffrement au repos et les vérifications d’intégrité sont obligatoires ici.
- Flux de données : Ce sont les chemins suivis par les données entre les trois autres éléments. Implication de sécurité : Les flux représentent les canaux réseau ou de communication entre processus. Les données en transit doivent être chiffrées. La surveillance des flux non autorisés est essentielle pour détecter le déplacement latéral des attaquants.
🔍 L’intersection des DFD et de la modélisation des menaces
Intégrer l’analyse des risques aux DFD exige une approche structurée. Cela est souvent appelé modélisation des menaces à l’aide de diagrammes de flux de données. L’objectif est d’identifier les menaces potentielles associées à chaque élément et flux, puis de déterminer les mesures d’atténuation appropriées.
Lors de cette analyse, l’attention se déplace de « comment fonctionne le système ? » à « comment le système peut-il être attaqué ? ». Ce changement de perspective permet aux équipes de concevoir des contrôles de manière proactive plutôt que de réparer des failles de manière réactive.
Objectifs clés de l’analyse des risques DFD
- Identification des actifs : Déterminer quels éléments de données sont sensibles. Toutes les données n’ont pas besoin du même niveau de protection.
- Définition des frontières de confiance : Marquer clairement où se termine la frontière du système et où commence l’environnement externe. Les niveaux de confiance changent à travers ces frontières.
- Énumération des menaces : Liste les menaces spécifiques applicables aux éléments du diagramme.
- Cartographie des contrôles :Attribuez des contrôles de sécurité aux éléments spécifiques du diagramme afin de réduire les menaces identifiées.
📉 Analyse des risques par niveau de DFD
Les diagrammes de flux de données sont généralement créés par niveaux, passant d’un contexte de haut niveau à une logique de processus détaillée. Chaque niveau offre un niveau de granularité différent d’analyse des risques.
Diagramme de contexte (Niveau 0)
Il s’agit de la vue de niveau le plus élevé. Il montre le système comme un seul processus interagissant avec des entités externes.
- Focus sur les risques :Sécurité de la périphérie du réseau et contrôle d’accès de haut niveau.
- Analyse :Identifiez toutes les connexions externes. Y a-t-il une connexion directe à Internet ? Y a-t-il des systèmes hérités qui interagissent avec la nouvelle conception ? Les risques de haut niveau incluent les attaques d’interception sur les canaux de communication principaux.
Diagramme de flux de données de niveau 1
Le processus principal est décomposé en sous-processus. Les magasins de données et les flux deviennent visibles.
- Focus sur les risques :Gestion interne des données et isolation des processus.
- Analyse :Recherchez les flux qui contournent les contrôles de sécurité. Par exemple, les données circulent-elles directement d’une entité non fiable vers un magasin de données sensible sans passer par un processus de validation ? Ce niveau révèle souvent des lacunes logiques dans les flux d’authentification.
Diagramme de flux de données de niveau 2 (et au-delà)
Les sous-processus sont davantage détaillés. Ce niveau est souvent utilisé pour une analyse spécifique des modules.
- Focus sur les risques :Validation des données, mise en œuvre du chiffrement et gestion des erreurs.
- Analyse :Examinez des algorithmes spécifiques ou des transformations de données. Les opérations cryptographiques sont-elles explicitement indiquées ? Les messages d’erreur sont-ils enregistrés de manière à révéler des informations ? Ce niveau est crucial pour les revues de sécurité au niveau du code.
📋 Matrice des risques : Cartographie des éléments sur les menaces
Le tableau ci-dessous résume les risques courants associés à des éléments spécifiques du DFD. Cette matrice sert de liste de contrôle pendant la phase de revue du design.
| Élément DFD | Menaces courantes | Stratégies de mitigation |
|---|---|---|
| Entité externe |
|
|
| Processus |
|
|
| Stockage de données |
|
|
| Flux de données |
|
|
🛠️ Procédé étape par étape pour l’analyse des risques
Mettre en œuvre cette analyse nécessite un flux de travail rigoureux. Les étapes suivantes décrivent la procédure pour effectuer une revue des risques approfondie à l’aide des diagrammes de flux de données (DFD).
Étape 1 : Définir le périmètre et les limites
Commencez par tracer le diagramme de contexte. Définissez clairement ce qui se trouve à l’intérieur du système et ce qui se trouve à l’extérieur. Cette frontière constitue le périmètre de confiance. Toute donnée qui traverse cette ligne doit être examinée attentivement. Documentez le niveau de confiance attribué à chaque entité externe. L’entité est-elle entièrement fiable, partiellement fiable ou non fiable ?
Étape 2 : Décomposer le système
Créez les diagrammes de niveau 1 et de niveau 2. En décomposant le processus principal, assurez-vous que chaque flux de données est étiqueté avec le type de données transférées. Par exemple, étiquetez un flux « Numéro de carte de crédit » plutôt que simplement « Données de paiement ». La précision permet une catégorisation des risques plus précise.
Étape 3 : Identifier les contrôles de sécurité
Examinez chaque élément du diagramme par rapport à la matrice des risques. Posez les questions suivantes pour chaque composant :
- Ce composant traite-t-il des données sensibles ?
- Un mécanisme d’authentification est-il en place ?
- Les données sont-elles chiffrées pendant le transfert ?
- Des journaux sont-ils générés à des fins d’audit ?
Étape 4 : Évaluer les frontières de confiance
Marquez chaque frontière de confiance sur le diagramme. Une frontière de confiance est un endroit où le niveau de confiance change. Par exemple, une frontière existe entre un serveur web public et une base de données interne. Le franchissement de cette frontière représente le point de risque le plus élevé. Assurez-vous que chaque point de franchissement dispose d’un contrôle de sécurité spécifique, tel qu’une règle de pare-feu, une passerelle API ou un tunnel de chiffrement.
Étape 5 : Documenter et prioriser les risques
Listez chaque risque identifié. Utilisez un système de notation de gravité (par exemple, Faible, Moyen, Élevé, Critique). Priorisez les risques en fonction de deux facteurs : la probabilité d’exploitation et l’impact sur l’activité si le risque se concrétise. Les risques à fort impact doivent être traités avant le déploiement.
🚧 Pièges courants dans l’analyse de sécurité des diagrammes de flux de données
Même les architectes expérimentés peuvent négliger des détails critiques. Être conscient des erreurs courantes aide à assurer une posture de sécurité solide.
- Flux fantômes :Assurez-vous que chaque flux de données a une source et une destination définies. Les flux qui commencent ou se terminent nulle part indiquent souvent une logique manquante ou des processus de données orphelins. Ces lacunes peuvent être exploitées par les attaquants.
- Ignorer les données au repos :Se concentrer uniquement sur les données en transit. De nombreuses violations se produisent parce que les données stockées dans les bases de données ne sont pas chiffrées ou sont accessibles via des requêtes trop permissives.
- Omettre l’authentification :Supposer qu’un flux existe, donc il est sécurisé. Les flux de données n’impliquent pas automatiquement une sécurité. Des étapes explicites d’authentification et d’autorisation doivent être modélisées comme des processus ou des contrôles.
- Manque de contrôle de version :Les diagrammes de flux de données évoluent avec les modifications du système. Si le diagramme ne correspond pas à l’implémentation actuelle, l’analyse des risques est invalide. Maintenez la version des diagrammes en parallèle avec les versions du code.
- Étiquettes génériques :Utiliser des étiquettes vagues comme « Données utilisateur » sans préciser le type de données. Les types de données spécifiques déclenchent des exigences réglementaires et de sécurité spécifiques (par exemple, PII, PHI, PCI-DSS).
🔄 Intégration dans le cycle de vie du développement
Pour que l’analyse des diagrammes de flux de données soit efficace, elle ne peut pas être une simple action ponctuelle. Elle doit être intégrée dans le cycle de vie du développement logiciel (SDLC).
Phase de conception
Pendant la conception initiale, créez les diagrammes de contexte et de niveau 1. Effectuez l’évaluation des risques de haut niveau. Cela garantit que des failles de sécurité fondamentales ne sont pas intégrées dans l’architecture.
Phase d’implémentation
Au fur et à mesure que les développeurs mettent en œuvre les fonctionnalités, ils doivent mettre à jour les diagrammes de niveau 2. Cela maintient le modèle de sécurité à jour. Les développeurs peuvent utiliser le diagramme pour vérifier que leur code implémente les contrôles nécessaires pour les flux de données qu’ils écrivent.
Phase de test
Les testeurs de sécurité peuvent utiliser le DFD pour planifier les tests d’intrusion. Ils peuvent se concentrer sur les flux à haut risque et les frontières de confiance identifiées dans l’analyse. Cela rend les tests plus efficaces et ciblés.
Phase d’exploitation
Maintenez les diagrammes pendant l’exploitation. Si un nouveau service tiers est intégré, mettez à jour le diagramme. Revoyez l’analyse des risques pour vous assurer que l’intégration nouvelle n’introduit pas de nouveaux vecteurs d’attaque.
📈 Mesure de l’efficacité de l’analyse
Comment savoir si l’analyse des risques du DFD fonctionne ? Recherchez les indicateurs suivants d’une posture de sécurité mûre.
- Nombre de vulnérabilités réduit : Moins de constatations de sécurité lors des revues de code et des tests d’intrusion.
- Correction plus rapide : Lorsque des problèmes sont détectés, ils sont plus faciles à localiser car le flux de données est documenté.
- Alignement avec la conformité : Les diagrammes correspondent directement aux exigences de conformité (par exemple, RGPD, HIPAA) en montrant où les données sensibles sont traitées et stockées.
- Connaissance de l’équipe : Les développeurs et les parties prenantes comprennent les implications sécurité de leurs choix de conception car le diagramme visualise les risques.
🛑 Gestion des exceptions et des systèmes hérités
Tous les systèmes ne sont pas de type greenfield. De nombreuses organisations doivent analyser des systèmes hérités où la documentation est absente ou incomplète.
Ingénierie inverse du DFD
Si un diagramme n’existe pas, vous devez en créer un à partir du code ou des fichiers de configuration. Ce processus, appelé ingénierie inverse, vous permet de visualiser le flux de données réel plutôt que celui prévu. Les écarts entre le flux réel et la conception prévue sont souvent là où se cachent les risques.
Gestion de la dette technique
Les systèmes hérités peuvent manquer de fonctionnalités de sécurité modernes. Lors de l’analyse de ces systèmes, concentrez-vous sur les contrôles compensatoires. Si le chiffrement ne peut pas être mis en œuvre au niveau du code, peut-il l’être au niveau du réseau ? Si l’authentification est faible, peut-on ajouter une couche de sécurité via une passerelle API devant l’application héritée ?
🔗 Le rôle de la classification des données
L’identification des risques est étroitement liée à la classification des données. Vous ne pouvez pas protéger ce que vous ne comprenez pas. Les flux de données doivent être annotés avec des niveaux de classification.
- Public : Informations pouvant être partagées librement. Faible risque en cas de divulgation.
- Interne : Informations destinées uniquement à un usage interne. Risque moyen en cas de divulgation.
- Confidentiel : Informations sensibles relatives à l’activité ou personnelles. Risque élevé en cas de divulgation.
- Restreint : Données extrêmement sensibles nécessitant des contrôles d’accès stricts. Risque critique en cas de divulgation.
Lors de l’analyse d’un DFD, mettez en évidence les flux contenant des données confidentielles ou restreintes avec une couleur distincte. Ce repère visuel dirige immédiatement l’attention de l’équipe sécurité vers les chemins les plus critiques.
🧭 Conclusion sur la méthodologie
Utiliser les diagrammes de flux de données pour l’identification des risques transforme la sécurité d’une liste de contrôle réactive en un principe de conception proactif. En visualisant le déplacement des données, les équipes peuvent repérer les menaces invisibles qui guettent dans l’architecture. Ce processus exige de la discipline, des mises à jour régulières et une compréhension claire des composants du système. Lorsqu’il est correctement mis en œuvre, il fournit une feuille de route claire pour sécuriser le système contre les menaces connues et émergentes.
La valeur de cette approche réside dans la clarté. Elle oblige les architectes à affronter la réalité du déplacement des données et de leurs points de vulnérabilité. Elle élimine toute ambiguïté dans les discussions sur la sécurité. À mesure que les systèmes gagnent en complexité, le besoin d’une telle analyse structurée devient encore plus critique. Maintenir des diagrammes précis et appliquer rigoureusement l’analyse des risques garantit que la sécurité reste alignée sur les fonctionnalités métier tout au long du cycle de vie du logiciel.
Commencez par le diagramme. Cartographiez les données. Identifiez le risque. Appliquez le contrôle. Ce cycle permet de créer un système résilient capable de résister aux pressions du paysage des menaces modernes.