











सटीक परियोजना अनुमान लाभकारी सॉफ्टवेयर विकास की आधारशिला है। एक प्रणाली की योजना बनाते समय, डेटा के नीचे के आंदोलनों को समझना संसाधन आवश्यकताओं के अनुमान के लिए एक ठोस आधार प्रदान करता है। डेटा फ्लो डायग्राम (DFD) इन आंदोलनों को मैप करने के लिए एक शक्तिशाली दृश्य उपकरण के रूप में कार्य करता है। DFD की संरचनात्मक जटिलता के विश्लेषण से, टीमें केवल कार्यात्मक आवश्यकताओं पर निर्भर रहने की तुलना में अधिक विश्वसनीय प्रयास अनुमान प्राप्त कर सकती हैं।
यह मार्गदर्शिका यह समझने के लिए अध्ययन करती है कि DFD जटिलता मापदंडों का उपयोग कैसे किया जाए ताकि प्रयास अनुमान को बेहतर बनाया जा सके। हम जटिलता को बढ़ाने वाले घटकों, इन तत्वों को मापने के तरीकों और आरेखीय विश्लेषण को परियोजना अवधि में बदलने की प्रक्रिया का अध्ययन करेंगे।
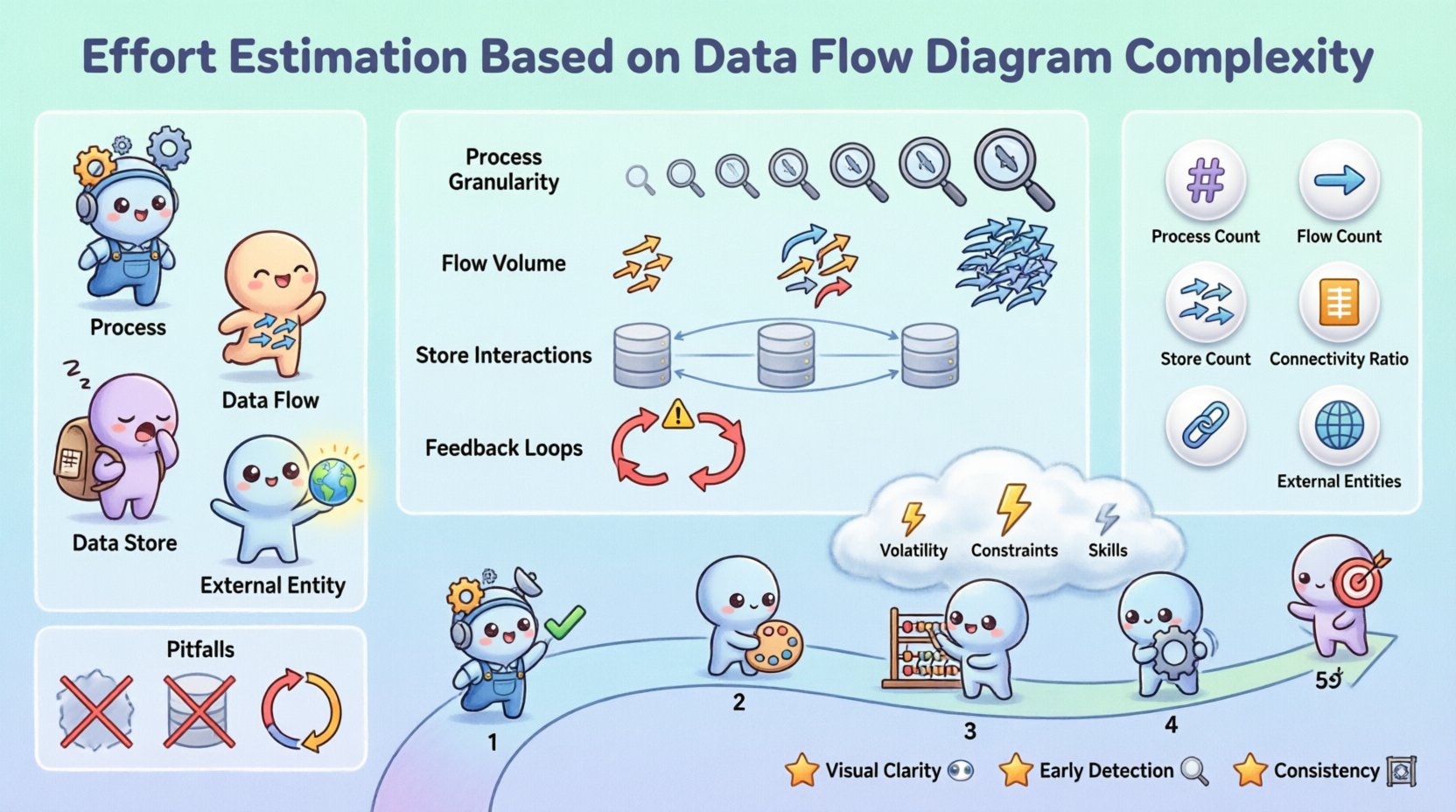
🔍 योजना निर्माण में डेटा फ्लो डायग्राम को समझना
एक डेटा फ्लो डायग्राम एक सूचना प्रणाली में डेटा के प्रवाह का आलेखीय प्रतिनिधित्व है। नियंत्रण तर्क पर ध्यान केंद्रित करने वाले फ्लोचार्ट्स के विपरीत, DFDs डेटा रूपांतरण पर ध्यान केंद्रित करते हैं। अनुमान के संदर्भ में, एक DFD शामिल कार्यों के लिए एक नक्शा के रूप में कार्य करता है।
- प्रक्रियाएँ: डेटा के रूपांतरण का प्रतिनिधित्व करते हैं। प्रत्येक प्रक्रिया आमतौर पर कोड में एक विशिष्ट कार्य या मॉड्यूल के साथ मैप होती है।
- डेटा प्रवाह: प्रक्रियाओं, भंडारण और एकाधिकारों के बीच डेटा के आंदोलन को दिखाते हैं। इनका अर्थ इंटरफेस और एकीकरण बिंदुओं का प्रतिनिधित्व करता है।
- डेटा भंडारण: यह बताते हैं कि डेटा कहाँ विश्राम के रूप में रखा जाता है। इनका संबंध डेटाबेस तालिकाओं या फाइल प्रणालियों से होता है।
- बाहरी एकाधिकार: प्रणाली के बाहर के डेटा के स्रोत या गंतव्य। इनका अर्थ एकीकरण आवश्यकताओं को परिभाषित करना है।
प्रयास के अनुमान के समय, इन तत्वों के दृश्य घनत्व और जुड़ाव उस मानसिक भार के बारे में संकेत देते हैं जो प्रणाली के कार्यान्वयन के लिए आवश्यक है। एक दुर्लभ आरेख जिसमें रेखीय प्रवाह हों, कम जटिलता का संकेत देता है, जबकि एक घना बारीकी से जुड़े बातचीत का जाल बड़े स्तर की एकीकरण चुनौतियों का संकेत देता है।
🏗️ जटिलता के कारकों की पहचान करना
सभी डेटा प्रवाह समान नहीं होते हैं। कुछ सरल फील्ड स्थानांतरण का प्रतिनिधित्व करते हैं, जबकि अन्य जटिल व्यावसायिक तर्क, सत्यापन या सुरक्षा प्रोटोकॉल को शामिल करते हैं। सटीक अनुमान लगाने के लिए, आपको आरेख में जटिलता को बढ़ाने वाले विशिष्ट कारकों की पहचान करनी होगी।
1. प्रक्रिया विस्तार
प्रक्रिया में विस्तार का स्तर महत्वपूर्ण है। एक उच्च स्तर की प्रक्रिया जैसे “ऑर्डर प्रोसेस” में दर्जनों उप-चरण छिपे हो सकते हैं। यदि DFD उच्च स्तर पर है, तो अनुमान में उस प्रक्रिया के विघटन को शामिल करना होगा। विपरीत रूप से, एक विस्तृत स्तर 2 या 3 DFD वास्तविक कार्य इकाइयों को उजागर करता है।
- कच्चे दाने वाली प्रक्रियाएँ: विघटन के लिए अधिक विश्लेषण समय की आवश्यकता होती है।
- पतली दाने वाली प्रक्रियाएँ: अधिक सीधे अनुमान लगाने की अनुमति देती हैं, लेकिन एकीकरण अतिरिक्त लागत को छोड़ सकती हैं।
2. डेटा प्रवाह का आयतन
तत्वों को जोड़ने वाले तीरों की संख्या डेटा संभालने के आयतन को दर्शाती है। प्रत्येक तीर एक डेटा संरचना का प्रतिनिधित्व करता है जिसका मूल्यांकन, रूपांतरण, भंडारण या स्थानांतरण करना होता है।
- अधिक प्रवाह अक्सर अधिक API बिंदु या डेटाबेस प्रश्नों का अर्थ होता है।
- जटिल प्रवाह में त्रुटि संभाल और पुनर्प्रयास तर्क की आवश्यकता हो सकती है।
3. डेटा भंडारण अंतरक्रियाएँ
डेटा भंडारण के साथ प्रत्येक अंतरक्रिया लेटेंसी के मामलों, समानांतरता की समस्याओं और स्कीमा प्रबंधन को जोड़ती है। एक प्रक्रिया जो एक साथ कई भंडारणों में पढ़ती और लिखती है, एकल भंडारण के साथ अंतरक्रिया करने वाली प्रक्रिया की तुलना में अधिक जटिल होती है।
4. प्रतिपुष्टि लूप
आरेख में लूप आवर्ती प्रसंस्करण या राज्य परिवर्तन को दर्शाते हैं। ये आमतौर पर विकास के सबसे अधिक त्रुटि-प्रवण क्षेत्र होते हैं। लूप के लिए अनुमान लगाने के लिए उन परीक्षण परिदृश्यों को ध्यान में रखना होता है जहां राज्य कई चक्रों के बीच बनाए रखा जाता है।
📏 अनुमान के लिए मात्रात्मक मापदंड
गुणात्मक अवलोकनों से मात्रात्मक अनुमानों तक जाने के लिए, DFD से निकाले गए विशिष्ट मापदंडों का उपयोग किया जा सकता है। इन मापदंडों में विभिन्न परियोजनाओं में अनुमान प्रक्रिया को मानकीकृत करने में सहायता मिलती है।
| मापदंड | विवरण | प्रयास पर प्रभाव |
|---|---|---|
| प्रक्रिया गिनती | रूपांतरण नोड्स की कुल संख्या। | कार्य बिंदुओं से सीधा संबंध। |
| प्रवाह गिनती | डेटा गति तीरों की कुल संख्या। | एकीकरण और इंटरफेस की जटिलता को दर्शाता है। |
| स्टोर गिनती | डेटा भंडारण की कुल संख्या। | डेटाबेस डिजाइन और माइग्रेशन प्रयास पर प्रभाव डालता है। |
| कनेक्टिविटी अनुपात | प्रवाहों और प्रक्रियाओं का अनुपात। | उच्च अनुपात तंतु बंधे प्रणालियों को दर्शाते हैं। |
| बाहरी एजेंसी गिनती | शामिल बाहरी प्रणालियों की संख्या। | संचार और निर्भरता जोखिम बढ़ाता है। |
इन मानों को जोड़कर आप एक जटिलता अंक प्राप्त कर सकते हैं। उदाहरण के लिए, एक सरल प्रणाली में 5 प्रक्रियाएं और 10 प्रवाह हो सकते हैं, जबकि एक जटिल प्रणाली में 50 प्रक्रियाएं और 150 प्रवाह हो सकते हैं। इस अंक को ऐतिहासिक डेटा द्वारा निर्धारित आधार प्रयास गुणांक से गुणा किया जा सकता है।
🛠️ अनुमान प्रक्रिया
DFD को प्रयास अनुमान में बदलने के लिए एक संरचित दृष्टिकोण की आवश्यकता होती है। योजना में सुसंगतता और सटीकता सुनिश्चित करने के लिए इन चरणों का पालन करें।
चरण 1: आरेख की पूर्णता की पुष्टि करें
अनुमान करने से पहले सुनिश्चित करें कि DFD आवश्यकताओं का सही ढंग से प्रतिनिधित्व करता है। गायब प्रवाह या एजेंसियां अनुमान को कम कर देंगी। जांचें कि प्रत्येक डेटा आवश्यकता के लिए एक संबंधित प्रवाह है और प्रत्येक प्रक्रिया के परिभाषित इनपुट और आउटपुट हैं।
चरण 2: प्रक्रिया जटिलता को वर्गीकृत करें
सभी प्रक्रियाओं को समान मात्रा में प्रयास की आवश्यकता नहीं होती है। उनकी तर्क पर आधारित प्रत्येक प्रक्रिया के लिए एक जटिलता भार निर्धारित करें।
- सरल:सीधे डेटा मैपिंग या प्राप्ति। (भार: 1)
- मध्यम: मान्यता, गणना, या प्रारूपण शामिल है। (भार: 2)
- जटिल: एकाधिक डेटा स्टोर, बाहरी API, या जटिल एल्गोरिदम को शामिल करता है। (भार: 3)
चरण 3: आधार दक्षता की गणना करें
प्रत्येक श्रेणी में प्रक्रियाओं की संख्या को उनके संबंधित भारों से गुणा करें। इन मानों को जोड़कर आधार जटिलता अंक (BCS) प्राप्त करें।
सूत्र: BCS = (सरल गिनती × 1) + (मध्यम गिनती × 2) + (जटिल गिनती × 3)
चरण 4: प्रवाह जटिलता के लिए समायोजन करें
डेटा प्रवाह की उच्च मात्रा इंटरफेस विकास के लिए आवश्यक प्रयास को बढ़ाती है। प्रक्रिया गिनती के सापेक्ष कुल प्रवाह गिनती के आधार पर एक प्रवाह गुणक लागू करें।
- निम्न अनुपात (प्रति प्रक्रिया ≤ 2 प्रवाह): गुणक 1.0
- मध्यम अनुपात (प्रति प्रक्रिया 3-5 प्रवाह): गुणक 1.2
- उच्च अनुपात (प्रति प्रक्रिया > 5 प्रवाह): गुणक 1.5
चरण 5: बाहरी निर्भरता को ध्यान में रखें
बाहरी एकाधिक जोखिम लाते हैं। प्रत्येक बाहरी प्रणाली के लिए एकीकरण परीक्षण, सुरक्षा सेटिंग, और संभावित विक्रेता समन्वय की आवश्यकता होती है। प्रत्येक बाहरी एकाधिक के लिए एक निश्चित समय बफर जोड़ें।
⚠️ जोखिम और अनिश्चितता के लिए समायोजन करें
विस्तृत DFD के साथ भी अनिश्चितता बनी रहती है। बदलते आवश्यकताओं या तकनीकी देनदारी जैसे कारकों के कारण आवश्यक प्रयास में परिवर्तन हो सकता है। इन जोखिमों को ध्यान में रखते हुए अपने अनुमानों को समायोजित करें।
1. आवश्यकता अस्थिरता
यदि व्यावसायिक आवश्यकताएं विकास के दौरान बदलने की संभावना है, तो DFD को महत्वपूर्ण संशोधन की आवश्यकता हो सकती है। ऐसे मामलों में कुल प्रयास में 15-20% का आपातकालीन बफर जोड़ें।
2. तकनीकी सीमाएं
पुरानी प्रणालियां या विशिष्ट बुनियादी ढांचे की आवश्यकताएं डेटा प्रवाह को जटिल बना सकती हैं। यदि DFD डेटा के एक पुराने मेनफ्रेम में जाने को दिखाता है, तो उस कनेक्शन को संभालने के लिए प्रयास मानक API कॉल्स की तुलना में अधिक हो सकता है।
3. टीम का कौशल स्तर
अनुमान एक आधारभूत क्षमता के अनुमान पर आधारित है। यदि टीम क्षेत्र या तकनीकी स्टैक के नए है, तो DFD प्रक्रियाओं की जटिलता अधिक सीखने के समय में बदल सकती है। प्रति प्रक्रिया इकाई के समय को उचित रूप से समायोजित करें।
🚫 DFD विश्लेषण में सामान्य त्रुटियां
आम गलतियों से बचना अनुमान की ईमानदारी बनाए रखने के लिए महत्वपूर्ण है। कई जाल बड़ी गलत गणनाओं की ओर ले जा सकते हैं।
- डेटा मान्यता को नजरअंदाज करना: एक DFD डेटा के गतिशील होने को दिखाता है, लेकिन उस पर लागू नियमों को नहीं दिखाता है। मान्यता तर्क अक्सर प्रक्रिया प्रयास का 20-30% होता है।
- त्रुटि संभाल को नजरअंदाज करना: हैप्पी पाथ्स को मैप करना आसान है। त्रुटि पाथ्स, पुनर्प्रयास और लॉगिंग हर फ्लो में छिपी जटिलता जोड़ते हैं।
- रैखिक वृद्धि मानकर: जटिलता अक्सर रैखिक रूप से नहीं बढ़ती है। एक और डेटा स्टोर जोड़ने से लेनदेन सुसंगतता की आवश्यकता के कारण संबंध जटिलता एक्सपोनेंशियल रूप से बढ़ सकती है।
- सुरक्षा के बारे में ध्यान न देना: एन्क्रिप्शन, प्रमाणीकरण और अधिकार परतें अक्सर DFD में अप्रत्यक्ष रूप से होती हैं। अनुमान में इनकी स्पष्ट गणना करें।
- केवल प्रक्रियाओं पर ध्यान केंद्रित करना: डेटा स्टोर और फ्लो को सेटअप और परीक्षण करने में प्रक्रियाओं की तुलना में अक्सर अधिक समय लगता है।
📅 अनुमानों को प्रोजेक्ट शेड्यूल में शामिल करना
जब भार की गणना कर ली जाती है, तो इसे शेड्यूल से जोड़ना होता है। इसमें संसाधन आवंटन और मील के पत्थर निर्धारण शामिल होते हैं।
- चरणबद्ध डिलीवरी: डेटा फ्लो निर्भरता के आधार पर प्रक्रियाओं का समूह बनाएं। जोखिम को कम करने के लिए उच्च प्राथमिकता वाले फ्लो को पहले डिलीवर करें।
- समानांतर कार्य प्रवाह: यदि प्रक्रियाएं स्वतंत्र हैं, तो उन्हें समानांतर रूप से विकसित किया जा सकता है। DFD का उपयोग करके स्वतंत्र समूहों की पहचान करें।
- एकीकरण परीक्षण: डेटा फ्लो की अखंडता के परीक्षण के लिए समर्पित समय निर्धारित करें। अक्सर जटिल DFD में यहीं विफलता होती है।
आरेख में दिखाए गए संरचनात्मक निर्भरताओं के अनुरूप शेड्यूल को समायोजित करके, आप एक वास्तविक अवधि बनाते हैं जो प्रणाली के प्राकृतिक प्रवाह का सम्मान करती है।
🔄 समय के साथ सटीकता बनाए रखना
अनुमान स्थिर नहीं होते हैं। जैसे-जैसे प्रोजेक्ट आगे बढ़ता है और DFD विकसित होता है, अनुमानों को फिर से निर्धारित करना चाहिए।
- बेसलाइन अपडेट्स: जब DFD अंतिम रूप ले लेता है, तो वास्तविक जटिलता अंकों के साथ प्रारंभिक अनुमानों को अपडेट करें।
- प्रतिबिंबित विश्लेषण: एक चरण के बाद, अनुमानित जटिलता अंकों की तुलना वास्तविक लगाए गए प्रयास से करें। इससे भविष्य के प्रोजेक्ट्स के लिए भार गुणांकों को बेहतर बनाया जा सकता है।
- परिवर्तन प्रबंधन: DFD में किसी भी परिवर्तन के कारण पुनर्अनुमान शुरू होना चाहिए। नहीं मानें कि एक छोटे फ्लो को जोड़ने का नगण्य प्रभाव होता है।
🛡️ DFD-आधारित योजना के लिए अंतिम विचार
प्रयास अनुमान के लिए डेटा फ्लो आरेखों का उपयोग करने से प्रोजेक्ट के आकार का आकलन करने के लिए एक संरचित, वस्तुनिष्ठ तरीका मिलता है। इससे अनुमान लगाने की बात से दूर ले जाता है और प्रणाली की वास्तविक डेटा संरचना के विश्लेषण की ओर ले जाता है।
हालांकि कोई मॉडल आदर्श नहीं होता है, लेकिन DFD जटिलता दृष्टिकोण के काफी लाभ हैं:
- दृश्य स्पष्टता: हितधारक डेटा गतिशीलता को देख सकते हैं, जिससे प्रयास के तर्कसंगत बनाना स्पष्ट हो जाता है।
- प्रारंभिक पहचान: जटिल प्रवाहों को कोडिंग शुरू होने से पहले पहचाना जा सकता है, जिससे आर्किटेक्चरल समायोजन किए जा सकते हैं।
- सांस्कृतिकता: विभिन्न परियोजनाओं में एक ही मापदंडों को लागू करने से बेहतर पोर्टफोलियो प्रबंधन संभव होता है।
याद रखें कि लक्ष्य पूर्णता नहीं है, बल्कि सूचित योजना बनाना है। नियमित रूप से अपने जटिलता कारकों की समीक्षा करें और अपनी आधार रेखाओं को अद्यतन करें। जैसे-जैसे आपकी टीम किसी विशिष्ट प्रकार के प्रवाहों और प्रक्रियाओं के साथ अनुभव प्राप्त करती है, आपकी प्रयास के अनुमान लगाने की क्षमता स्वाभाविक रूप से सुधरेगी।
डीएफडी को प्राथमिक अनुमानक के रूप में लेने से आप अपनी योजना को उस प्रणाली की मूल प्रकृति के साथ समायोजित करते हैं जिसका निर्माण आप कर रहे हैं। इससे अधिक वास्तविक बजट, योजनाएं और अंततः सॉफ्टवेयर समाधानों के अधिक सफल डिलीवरी की संभावना होती है।