











सिस्टम डिजाइन और आवश्यकता इंजीनियरिंग के क्षेत्र में स्पष्टता अत्यंत महत्वपूर्ण है। जब स्टेकहोल्डर्स को सिस्टम के माध्यम से जानकारी के आवागमन को देखने में कठिनाई होती है, तो परियोजनाएं अक्सर रुक जाती हैं। इसी स्थिति में डेटा प्रवाह आरेख (DFD) व्यवसाय विश्लेषकों के लिए एक आवश्यक उपकरण बन जाता है। स्थिर चार्ट या जटिल कोड के विपरीत, एक DFD डेटा के प्रवेश से निकास तक के यात्रा को नक्शा बनाता है, जिसमें परिवर्तन और भंडारण बिंदुओं को उजागर किया जाता है। यह मार्गदर्शिका DFD के यांत्रिकी, उनके संरचनात्मक घटकों और सफल व्यवसाय विश्लेषण में उनके महत्वपूर्ण भूमिका का अध्ययन करती है।
चाहे आप पुराने सिस्टम का नक्शा बना रहे हों या एक नए डिजिटल प्लेटफॉर्म का डिजाइन कर रहे हों, जानकारी के प्रवाह को समझना प्रभावी मॉडलिंग की आधारशिला है। हम मुख्य प्रतीकों, आरेखों के पदानुक्रम और उचित सटीकता सुनिश्चित करने वाले विशिष्ट नियमों को कवर करेंगे। कोई भी भड़काऊ बात नहीं, सिर्फ विश्वसनीय सिस्टम दस्तावेजीकरण के लिए आवश्यक संरचनात्मक अखंडता।
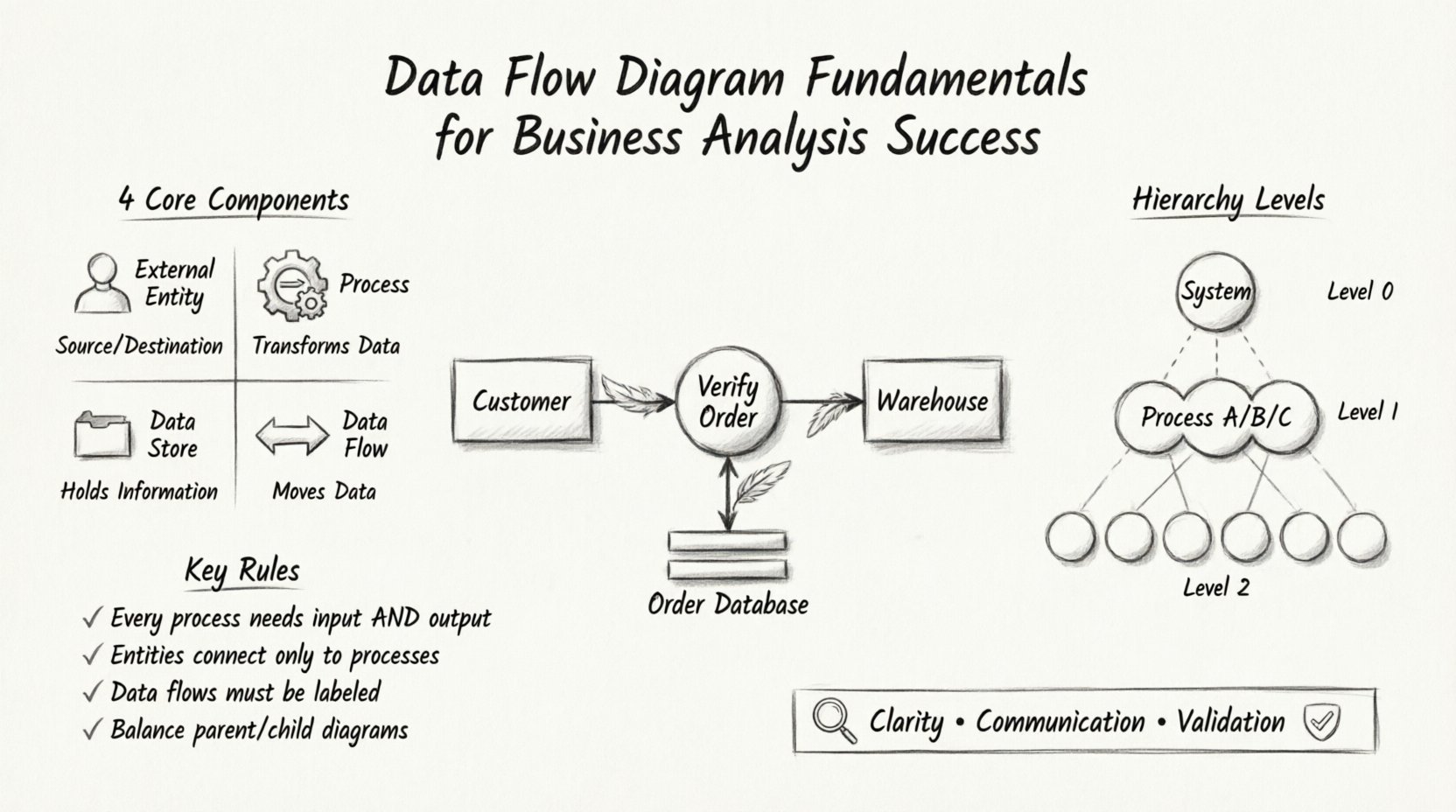
डेटा प्रवाह आरेख क्या है? 🤔
एक डेटा प्रवाह आरेख एक सूचना प्रणाली के माध्यम से डेटा के प्रवाह का एक आलेखीय प्रतिनिधित्व है। यह डेटा के इनपुट और आउटपुट दिखाकर यह दिखाता है कि डेटा को सिस्टम द्वारा कैसे प्रसंस्कृत किया जाता है। एक फ्लोचार्ट के विपरीत जो किसी प्रक्रिया के तर्क और निर्णय लेने के क्रम पर ध्यान केंद्रित करता है, एक DFD डेटा के स्वयं पर ध्यान केंद्रित करता है।
मुख्य विशेषताएं शामिल हैं:
- डेटा पर ध्यान केंद्रित:यह डेटा वस्तुओं का अनुसरण करता है, नियंत्रण तर्क का नहीं।
- प्रक्रिया-केंद्रित:यह दिखाता है कि डेटा सिस्टम के माध्यम से गति करते समय कैसे बदलता है।
- सारांश:यह आंतरिक कार्यान्वयन विवरणों को छिपाता है, “क्या” पर ध्यान केंद्रित करता है, न कि “कैसे” पर।
- स्वतंत्रता:यह सिस्टम की आवश्यकताओं का वर्णन करता है, बिना उन्हें विशिष्ट तकनीक से जोड़े।
एक व्यवसाय विश्लेषक के लिए, DFD एक संचार सेतु के रूप में कार्य करता है। यह तकनीकी आवश्यकताओं को एक दृश्य रूप में बदलता है जिसे तकनीकी रूप से अनजान स्टेकहोल्डर्स समीक्षा और मान्यता दे सकते हैं। इससे अस्पष्टता कम होती है और यह सुनिश्चित करता है कि सभी लोग सिस्टम द्वारा जानकारी के प्रबंधन के तरीके पर सहमति रखते हैं।
DFD के मुख्य घटक 🧩
प्रत्येक वैध डेटा प्रवाह आरेख में चार मूल तत्व होते हैं। सही आरेख बनाने के लिए इनकी समझ आवश्यक है। इन प्रतीकों की स्थिरता विधि या उपकरण के बदलाव के बावजूद बनी रहती है।
1. बाहरी एकाधिकार (स्रोत और गंतव्य) 👤
बाहरी एकाधिकार लोगों, संगठनों या अन्य प्रणालियों का प्रतिनिधित्व करते हैं जो मॉडल की जा रही प्रणाली के साथ बातचीत करते हैं। वे डेटा प्रवाह के लिए प्रारंभ बिंदु (स्रोत) या अंतिम बिंदु (गंतव्य) के रूप में कार्य करते हैं। वे प्रणाली की सीमा के बाहर स्थित होते हैं।
- उदाहरण: एक ग्राहक, एक बैंक, एक सरकारी एजेंसी या एक तीसरे पक्ष का API।
- प्रतीक चिह्न: आमतौर पर एक आयत या एक व्यक्ति का प्रतिनिधित्व करने वाले आइकन के रूप में दर्शाया जाता है।
- नियम: प्रत्येक डेटा प्रवाह को एक प्रक्रिया से जुड़ना चाहिए; यह दूसरे एकाधिकार से सीधे जुड़ नहीं सकता।
2. प्रक्रियाएं (रूपांतरण) ⚙️
एक प्रक्रिया आने वाले डेटा को बाहर निकलने वाले डेटा में बदलती है। यह डेटा पर किए जाने वाले कार्य, गतिविधि या गणना का वर्णन करती है। यहीं सिस्टम के भीतर “काम” होता है।
- उदाहरण: “कुल गणना करें,” “उपयोगकर्ता की पुष्टि करें,” “रिपोर्ट उत्पन्न करें।”
- प्रतीक चिह्न: आमतौर पर एक वृत्त या गोल कोने वाला आयत।
- नियम: प्रत्येक प्रक्रिया के कम से कम एक इनपुट और एक आउटपुट होने चाहिए। एक प्रक्रिया जो इनपुट लेती है लेकिन कोई आउटपुट नहीं बनाती है, असंभव है।
3. डेटा स्टोर (भंडारण स्थल) 📁
डेटा स्टोर वह स्थान दर्शाते हैं जहां जानकारी बाद में उपयोग के लिए संग्रहीत की जाती है। यह एक डेटाबेस, फाइल, कागजी फाइल या भौतिक गोदाम हो सकता है। यह डेटा को प्रसंस्कृत नहीं करता है; यह उसे रखता है।
- उदाहरण: ग्राहक डेटाबेस, इन्वेंटरी फाइल, ऑर्डर लॉग।
- प्रतीक: अक्सर एक खुला आयत या समानांतर रेखाएं।
- नियम: डेटा प्रवाह को प्रक्रियाओं को डेटा स्टोर से जोड़ना चाहिए। एक डेटा स्टोर सीधे बाहरी एकाधिकार से जुड़ नहीं सकता है।
4. डेटा प्रवाह (गति) 🔄
डेटा प्रवाह एकाधिकारों, प्रक्रियाओं और स्टोर के बीच डेटा के गति को दर्शाते हैं। ये स्थानांतरित किए जा रहे वास्तविक डेटा पैकेट्स का प्रतिनिधित्व करते हैं।
- उदाहरण: “बिल,” “भुगतान विवरण,” “खोज प्रश्न।”
- प्रतीक: डेटा की गति की दिशा में इशारा करने वाली तीर।
- नियम: तीरों को लेबल करना आवश्यक है। बिना लेबल के प्रवाह अर्थहीन हैं।
नीचे दी गई तालिका इन घटकों के बीच संबंधों का सारांश प्रदान करती है जिससे त्वरित संदर्भ के लिए सहायता मिले।
| घटक | कार्य | जुड़ाव नियम |
|---|---|---|
| बाहरी एकाधिकार | स्रोत या गंतव्य | केवल एक प्रक्रिया से जुड़ता है |
| प्रक्रिया | डेटा को परिवर्तित करता है | एकाधिकारों, स्टोर और अन्य प्रक्रियाओं से जुड़ता है |
| डेटा स्टोर | डेटा स्टोर करता है | केवल एक प्रक्रिया से जुड़ता है |
| डेटा प्रवाह | डेटा को परिवहन करता है | लेबल किया जाना चाहिए; एंटिटी को एंटिटी सीधे नहीं जोड़ा जा सकता है |
DFD विघटन के स्तर 📉
एक एकल आरेख अक्सर पूरी जटिलता को नहीं दर्शाता है। विवरण को प्रबंधित करने के लिए DFD को अलग-अलग स्तरों में विभाजित किया जाता है। इस पदानुक्रम की अनुमति विश्लेषकों को सिस्टम दृश्य में जूम इन और जूम आउट करने के लिए देता है।
संदर्भ आरेख (स्तर 0) 🌍
संदर्भ आरेख उच्चतम स्तर के सारांश का प्रतिनिधित्व करता है। यह प्रणाली को एकल प्रक्रिया के रूप में दिखाता है और उन बाहरी एंटिटी की पहचान करता है जो इससे बातचीत करती हैं। यह प्रणाली की सीमाओं को परिभाषित करता है।
- परिधि: पूरी प्रणाली का प्रतिनिधित्व करने वाली एक केंद्रीय प्रक्रिया।
- विवरण: केवल मुख्य डेटा इनपुट और आउटपुट दिखाए जाते हैं।
- उपयोग: प्रणाली की परिधि पर प्रारंभिक हितधारक सहमति के लिए उपयोग किया जाता है।
स्तर 1 आरेख 🏗️
स्तर 1 आरेख संदर्भ आरेख से एकल प्रक्रिया को उप-प्रक्रियाओं में विस्तारित करता है। यह प्रणाली के मुख्य कार्यों को तोड़ता है।
- परिधि: प्रणाली की आंतरिक प्रक्रियाएं दिखाई देती हैं।
- विवरण: आंतरिक कार्यों के बीच डेटा कैसे आगे बढ़ता है, इसका प्रदर्शन करता है।
- उपयोग: विस्तृत कार्यात्मक आवश्यकताओं के लिए उपयोग किया जाता है।
स्तर 2 और उससे आगे 🧱
यदि स्तर 1 में कोई प्रक्रिया अभी भी बहुत जटिल है, तो आगे का विघटन होता है। स्तर 2 आरेख एक विशिष्ट स्तर 1 प्रक्रिया को बेहतर चरणों में तोड़ता है।
- परिधि: एक विशिष्ट कार्य के भीतर विस्तृत तर्क।
- विवरण: विशिष्ट डेटा परिवर्तन और स्थानीय स्टोर।
- उपयोग: विकास टीमों के लिए उपयोग किया जाता है जो विशिष्ट मॉड्यूल कार्यान्वित कर रही हैं।
संतुलन का सिद्धांत ⚖️
DFD मॉडलिंग में सबसे महत्वपूर्ण नियमों में से एक संतुलन है। संतुलन एक मातृ आरेख और उसके बच्चे आरेख के बीच सामंजस्य सुनिश्चित करता है। जब किसी प्रक्रिया को निम्न स्तर के आरेख में विस्तारित किया जाता है, तो इनपुट और आउटपुट एक ही रहने चाहिए।
यदि लेवल 0 प्रक्रिया को “आदेश डेटा” प्राप्त होता है और “रसीद डेटा” भेजता है, तो उस प्रक्रिया का प्रतिनिधित्व करने वाला लेवल 1 आरेख को भी “आदेश डेटा” के रूप में इनपुट प्राप्त करना चाहिए और “रसीद डेटा” को आउटपुट के रूप में भेजना चाहिए। आंतरिक जटिलता बदल जाती है, लेकिन बाहरी दुनिया के साथ इंटरफेस स्थिर रहता है। इससे यह सुनिश्चित होता है कि विघटन प्रक्रिया के दौरान कोई डेटा न तो बनता है और न ही नष्ट होता है।
चरण-दर-चरण निर्माण प्रक्रिया 🛠️
एक विश्वसनीय DFD बनाने के लिए एक संरचित दृष्टिकोण की आवश्यकता होती है। जल्दबाजी करने से त्रुटियाँ और भ्रम होता है। एक विश्वसनीय मॉडल बनाने के लिए इन चरणों का पालन करें।
1. प्रणाली सीमा की पहचान करें
यह परिभाषित करें कि प्रणाली के अंदर क्या है और बाहर क्या है। इससे यह निर्धारित होता है कि कौन से संस्थान बाहरी हैं और कौन सी प्रक्रियाएँ आंतरिक हैं। इस सीमा के बाहर कुछ भी एक बाहरी संस्थान है।
2. बाहरी संस्थानों को नक्शा बनाएं
उन सभी लोगों, विभागों या प्रणालियों की सूची बनाएं जो समाधान के साथ बातचीत करते हैं। उन्हें आपके आरेख के किनारे पर रखें। आंतरिक उपयोगकर्ताओं को शामिल न करें, जब तक कि वे डेटा के बाहरी स्रोत के रूप में न बर्ताएं।
3. प्रमुख प्रक्रियाओं को परिभाषित करें
डेटा को संभालने के लिए आवश्यक उच्च स्तरीय कार्यों की पहचान करें। नामों के लिए क्रिया विशेषज्ञों का उपयोग करें (उदाहरण के लिए, “भुगतान प्रक्रिया” के बजाय “भुगतान”)। सुनिश्चित करें कि एक तार्किक क्रम है।
4. डेटा प्रवाह बनाएं
संस्थानों को प्रक्रियाओं से और प्रक्रियाओं को डेटा भंडार से जोड़ें। सुनिश्चित करें कि प्रत्येक प्रवाह को एक लेबल हो जो उसमें गतिमान डेटा का वर्णन करे। पठनीयता बनाए रखने के लिए संभव हो तो लाइनों को एक दूसरे को काटने से बचें।
5. समीक्षा और मान्यता
संतुलन नियम के विरुद्ध जांच करें। सुनिश्चित करें कि प्रत्येक प्रक्रिया के इनपुट और आउटपुट हैं। सुनिश्चित करें कि कोई डेटा भंडार बिना प्रक्रिया के बीच एक्सेस नहीं किया जाता है। फीडबैक के लिए ड्राफ्ट को स्टेकहोल्डर्स के सामने प्रस्तुत करें।
स्पष्टता के लिए नामकरण प्रथाएं 🏷️
गड़बड़ लेबल वाला आरेख उसके उद्देश्य को नष्ट कर देता है। स्पष्ट नामकरण प्रथाएं पाठक के लिए संज्ञानात्मक भार को कम करती हैं।
प्रक्रिया नाम
- क्रिया के बाद एक संज्ञा का उपयोग करें (उदाहरण के लिए, “ग्राहक प्रोफाइल अद्यतन करें”)।
- नाम छोटे रखें लेकिन वर्णनात्मक रखें।
- “प्रक्रिया 1” या “कुछ करें” जैसे सामान्य शब्दों से बचें।
डेटा प्रवाह नाम
- क्रिया के बजाय डेटा का नाम रखें (उदाहरण के लिए, “इन्वॉइस विवरण” के बजाय “इन्वॉइस भेजें”)।
- आरेख के भीतर एकवचन या बहुवचन का निरंतर उपयोग करें।
- सुनिश्चित करें कि नाम डेटा शब्दकोश या आवश्यकता दस्तावेज के अनुरूप हो।
डेटा भंडार नाम
- एक संज्ञा वाक्यांश का उपयोग करें जो भंडारित चीज को इंगित करे (उदाहरण के लिए, “आदेश फ़ाइल” या “ग्राहक सूची”)।
- क्रिया वाक्यांशों का उपयोग न करें।
आम त्रुटियाँ और उनसे बचने के तरीके ⚠️
अनुभवी विश्लेषक भी गलतियाँ करते हैं। सामान्य त्रुटियों को जल्दी पहचानने से बाद में बड़े पैमाने पर पुनर्कार्य करने की बचत होती है।
1. लटकते हुए डेटा प्रवाह
एक ऐसा प्रवाह जो कहीं से शुरू होता है या कहीं खत्म होता है। प्रत्येक तीर को दो वैध घटकों को जोड़ना चाहिए।
- सुधार:हर रेखा का अनुसरण करें। यदि यह खाली स्थान पर समाप्त होती है, तो इसे किसी प्रक्रिया या एकता से जोड़ें।
2. काले छेद
एक प्रक्रिया जिसमें इनपुट है लेकिन आउटपुट नहीं है। इसका अर्थ है कि डेटा का उपयोग या संग्रहण नहीं किया जाता है।
- सुधार:सुनिश्चित करें कि प्रत्येक प्रक्रिया किसी भी रूप में आउटपुट उत्पन्न करे, चाहे वह एक स्टोर, एक एकता या दूसरी प्रक्रिया में हो।
3. चमत्कारिक प्रक्रियाएँ
एक प्रक्रिया जिसमें आउटपुट है लेकिन इनपुट नहीं है। इसका अर्थ है कि डेटा बिना कारण उपस्थित होता है।
- सुधार:डेटा के स्रोत को पहचानें। इसे एक एकता या डेटा स्टोर से जोड़ें।
4. सीधे एकता से एकता तक प्रवाह
डेटा एक बाहरी एकता से दूसरी बाहरी एकता में बिना प्रणाली (प्रक्रिया) से गुजरे नहीं जा सकता है।
- सुधार:सभी बाहरी प्रवाहों को कम से कम एक आंतरिक प्रक्रिया के माध्यम से मार्गित करें।
5. बहुत अधिक विवरण बहुत जल्दी
संदर्भ या स्तर 1 दृश्य को स्थापित किए बिना स्तर 2 आरेख से शुरुआत करना।
- सुधार:व्यापक शुरुआत करें। सबसे पहले प्रणाली की सीमा को परिभाषित करें। उच्च स्तर के दृश्य के अनुमोदन के बाद ही विभाजन करें।
आधुनिक व्यापार विश्लेषण अभ्यासों में DFD को एकीकृत करना 🔄
डेटा प्रवाह आरेख अलग-अलग वस्तुएँ नहीं हैं। वे व्यापार विश्लेषण के विस्तृत कार्य प्रवाह में फिट होते हैं, विशेष रूप से एजाइल और आवर्धित परिदृश्यों में।
एजाइल संगतता
एजाइल परिदृश्यों में, भारी दस्तावेजीकरण को अक्सर निषेध किया जाता है। हालांकि, जटिल तर्क के लिए दृश्य मॉडल जैसे DFD अभी भी मूल्यवान रहते हैं। उन्हें विकास को मार्गदर्शन करने के लिए ‘बस उतना ही’ दस्तावेजीकरण के रूप में बनाया जा सकता है, जिससे बाधा न बने। जटिल डेटा परिवर्तनों वाली उपयोगकर्ता कहानियों को स्पष्ट करने के लिए उनका उपयोग करें।
आवश्यकता ट्रेसेबिलिटी
DFD में प्रत्येक प्रक्रिया को किसी कार्यात्मक आवश्यकता से मैप करना चाहिए। इससे एक ट्रेसेबिलिटी मैट्रिक्स बनती है जहां आप सत्यापित कर सकते हैं कि प्रत्येक आवश्यकता मॉडल में प्रतिनिधित्व की गई है। यदि कोई आवश्यकता है जिसके लिए कोई संबंधित प्रक्रिया नहीं है, तो प्रणाली डिजाइन अधूरा है।
हितधारक संचार
तकनीकी शब्दावली अक्सर व्यापार उपयोगकर्ताओं को दूर कर देती है। DFD एक सार्वभौमिक भाषा प्रदान करते हैं। एक व्यापार उपयोगकर्ता डेटा स्टोर की ओर इशारा कर सकता है और कह सकता है, ‘हम इस इतिहास कहाँ रखते हैं?’ तब विश्लेषक जांच कर सकता है कि क्या आरेख में एक स्टोर मौजूद है। इससे आवश्यकताओं के सहयोगी सुधार को सुविधा मिलती है।
सटीकता के लिए जांच तकनीक 📏
जब एक आरेख बन जाता है, तो उसका परीक्षण करना आवश्यक है। DFD की पुष्टि करने से यह सुनिश्चित होता है कि यह वास्तविक दुनिया के संचालन का सही प्रतिनिधित्व करता है।
वॉकथ्रू
विषय विशेषज्ञों के साथ एक वॉकथ्रू करें। आरेख में एक विशिष्ट लेनदेन का पता लगाएं। उदाहरण के लिए, एक “पर्चेज ऑर्डर” के जीवनचक्र का पता लगाएं, जिसमें इसके निर्माण से लेकर संग्रहीत करने तक का मार्ग शामिल हो। यदि मार्ग टूटा हुआ है या तर्कहीन है, तो आरेख को संशोधित करने की आवश्यकता होगी।
डेटा डिक्शनरी क्रॉस-रेफरेंस
अपने डेटा प्रवाह के लेबल की अपनी डेटा डिक्शनरी के साथ तुलना करें। सुनिश्चित करें कि डिक्शनरी में परिभाषित डेटा संरचना आरेख में ले जाए जा रहे डेटा के साथ मेल खाती हो। यदि डिक्शनरी में “ग्राहक आईडी” को एक स्ट्रिंग के रूप में परिभाषित किया गया है, लेकिन प्रवाह एक संख्या के बारे में संकेत देता है, तो एक अंतर है।
संगति जांच
एक से अधिक आरेखों के बीच संगति की जांच करें। यदि कोई प्रक्रिया Level 1 आरेख में दिखाई देती है, तो उसमें प्रवेश करने वाले और निकलने वाले डेटा प्रवाह को Level 2 विभाजन में प्रवाह के साथ मेल खाना चाहिए। यहां असंगति तर्क की कमी को दर्शाती है।
विश्लेषण में डेटा स्टोर की भूमिका 🗃️
डेटा स्टोर को अक्सर नजरअंदाज किया जाता है, फिर भी वे प्रणाली की स्थिति का प्रतिनिधित्व करते हैं। उनकी समझ डेटा शासन और अखंडता के लिए आवश्यक है।
पढ़ना बनाम लिखना संचालन
डेटा स्टोर से सभी कनेक्शन एक जैसे नहीं होते हैं। कुछ प्रक्रियाएं केवल डेटा पढ़ती हैं (उदाहरण के लिए, “इतिहास प्रदर्शित करें”), जबकि अन्य डेटा लिखती या अद्यतन करती हैं (उदाहरण के लिए, “आर्डर सहेजें”)। जबकि पारंपरिक DFD में दोनों के लिए एक ही रेखा का उपयोग किया जाता है, इस अंतर को समझना बाद में डेटाबेस डिजाइन में मदद करता है। एक केवल पढ़ने वाला स्टोर उस विशिष्ट उपयोगकर्ता के लिए लेखन अनुमति की आवश्यकता नहीं रखता है।
अस्थायी बनाम स्थायी भंडारण
अस्थायी बफर और स्थायी आर्काइव के बीच अंतर करें। एक अस्थायी स्टोर बैच गणना के दौरान डेटा को रख सकता है, जबकि स्थायी स्टोर नियमानुसार डेटा को बनाए रखता है। इस अंतर का सुरक्षा आवश्यकताओं और रखरखाव नीतियों पर प्रभाव पड़ता है।
DFD उपयोगिता पर निष्कर्ष 🚀
डेटा प्रवाह आरेख व्यापार विश्लेषण के लिए एक सदियों पुराना उपकरण बना हुआ है। वे कार्यान्वयन विवरण के शोर को दूर करके जानकारी के मूल आंदोलन को उजागर करते हैं। घटकों, संतुलन और नामकरण के संबंध में सख्त नियमों का पालन करके विश्लेषक ऐसे मॉडल बना सकते हैं जो प्रणाली विकास के लिए भरोसेमंद नक्शे के रूप में कार्य करते हैं।
व्यापार विश्लेषण में सफलता स्पष्टता पर निर्भर करती है। एक अच्छी तरह से निर्मित DFD उस स्पष्टता को प्रदान करता है। यह स्टेकहोल्डरों को एक साथ लाता है, डेवलपर्स को मार्गदर्शन करता है, और यह सुनिश्चित करता है कि अंतिम प्रणाली इच्छित तरीके से व्यवहार करे। सही तरीके से उपयोग किया जाए, तो DFD केवल एक ड्राइंग नहीं है; यह व्यापार की आवश्यकताओं और तकनीकी समाधान के बीच एक संविदा है।
डेटा पर ध्यान केंद्रित करें। सीमाओं का सम्मान करें। प्रवाहों की पुष्टि करें। इस अनुशासित दृष्टिकोण से ऐसे आरेख प्राप्त होंगे जो समय और परिवर्तन की परीक्षा में खड़े होंगे।