











आधुनिक सॉफ्टवेयर आर्किटेक्चर में, जानकारी के आवागमन को समझना उसके भंडारण को समझने के बराबर महत्वपूर्ण है। डेटा फ्लो डायग्राम (DFD) इस आवागमन के लिए ब्लूप्रिंट के रूप में कार्य करता है, जो डेटा के इनपुट से आउटपुट तक के यात्रा को मैप करता है। विस्तार को संभालने के लिए डिज़ाइन किए गए सिस्टम के लिए, इन डायग्राम्स को सरल खाकों से जटिल मानचित्रों में विकसित किया जाता है, जो प्रदर्शन, विश्वसनीयता और रखरखाव को निर्धारित करते हैं। यह मार्गदर्शिका स्केलेबल वातावरणों में डेटा फ्लो के मॉडलिंग के लिए उपयोग किए जाने वाले मूल पैटर्न का अध्ययन करती है।
स्केलेबिलिटी केवल अधिक सर्वर जोड़ने के बारे में नहीं है; यह डेटा के सिस्टम में यात्रा करने के तरीके को पुनर्गठित करने के बारे में है ताकि बॉटलनेक बने। विशिष्ट DFD पैटर्न के अनुप्रयोग से, आर्किटेक्ट उत्पादन में समस्याओं के रूप में आने से पहले क्षमता सीमाओं को देख सकते हैं। इस दृष्टिकोण से यह सुनिश्चित होता है कि जानकारी का तार्किक प्रवाह वर्तमान आवश्यकताओं और भविष्य के विस्तार का समर्थन करता है।
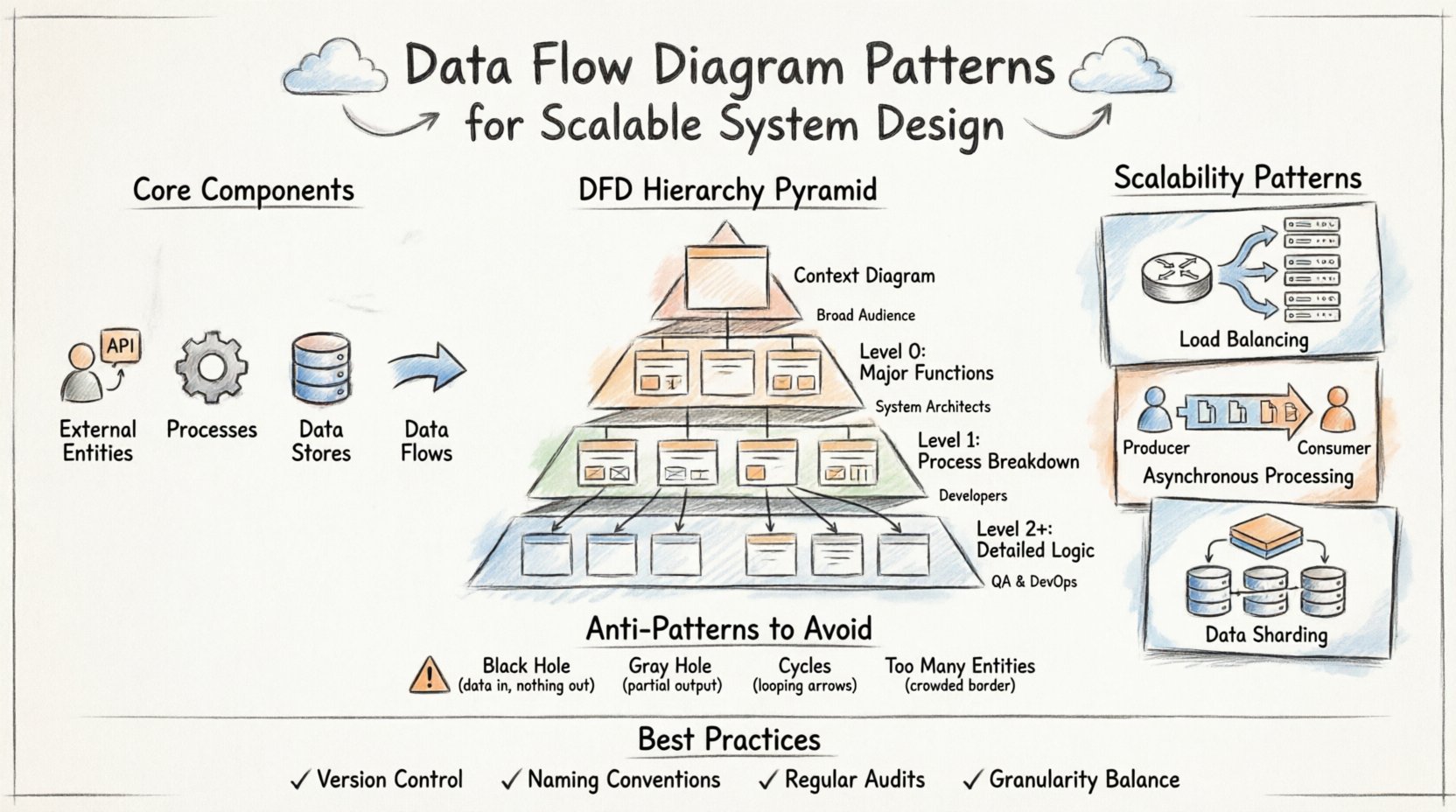
🧩 डेटा फ्लो डायग्राम के मुख्य घटक
पैटर्न में डुबकी लगाने से पहले, एक को निर्माण ब्लॉक्स को समझना चाहिए। प्रत्येक DFD चार मूल तत्वों पर निर्भर करता है। इन्हें गलती से मिलाने से अस्पष्ट मॉडल बनते हैं जो विकास को प्रभावी ढंग से मार्गदर्शन नहीं कर पाते।
- बाहरी एजेंसियाँ: सिस्टम सीमा के बाहर के स्रोत या गंतव्य का प्रतिनिधित्व करते हैं। इनमें उपयोगकर्ता, तृतीय-पक्ष API या हार्डवेयर उपकरण शामिल हैं।
- प्रक्रियाएँ: डेटा के एक रूप से दूसरे रूप में बदलना। ये सिस्टम के भीतर सक्रिय गणना या व्यवसाय तर्क बिंदु हैं।
- डेटा स्टोर्स: वे स्थान जहाँ डेटा विश्राम में रहता है। इनमें डेटाबेस, फाइल प्रणाली या मेमोरी कैश शामिल हो सकते हैं।
- डेटा प्रवाह: एजेंसियों, प्रक्रियाओं और स्टोर्स के बीच डेटा के लिए ली गई राहें। तीर दिशा और सामग्री को इंगित करते हैं।
प्रत्येक घटक को स्पष्ट रूप से परिभाषित किया जाना चाहिए ताकि अस्पष्टता न हो। उदाहरण के लिए, एक प्रक्रिया को कभी भी दूसरी प्रक्रिया की ओर तीर नहीं दिखाना चाहिए बिना डेटा के संगत प्रवाह के। प्रत्येक तीर को सिस्टम में गतिशील वास्तविक जानकारी का प्रतिनिधित्व करना चाहिए।
📉 DFD स्तरों की श्रेणी
स्केलेबल सिस्टम को विभिन्न स्तरों के अमूर्तीकरण की आवश्यकता होती है। एक ही डायग्राम अक्सर पूरी जटिलता को नहीं ध्यान में रखता है। इसके बजाय, एक श्रेणी का उपयोग उच्च-स्तरीय संदर्भ से विस्तृत कार्यान्वयन तर्क तक गहराई से जाने के लिए किया जाता है। इस संरचना के कारण टीमें बड़ी छवि को समीक्षा कर सकती हैं बिना जंगल में खो जाने के।
| स्तर | फोकस | जटिलता | प्राथमिक दर्शक |
|---|---|---|---|
| संदर्भ डायग्राम | सिस्टम सीमा और बाहरी अंतरक्रियाएँ | कम | हितधारक, प्रबंधन |
| स्तर 0 (DFD 0) | मुख्य सिस्टम कार्य और डेटा स्टोर्स | मध्यम | सिस्टम आर्किटेक्ट्स |
| स्तर 1 | स्तर 0 प्रक्रियाओं का विश्लेषण | उच्च | विकासकर्ता, � ingineers |
| स्तर 2+ | विशिष्ट एल्गोरिदमिक या उप-प्रक्रिया तर्क | बहुत उच्च | विशेषज्ञ इंजीनियर |
इन स्तरों के बीच संगति बनाए रखना आवश्यक है। स्तर 0 में पहचाना गया डेटा स्टोर को स्तर 1 में सही तरीके से संदर्भित किया जाना चाहिए। यदि स्तर 1 में किसी प्रक्रिया को विभाजित किया जाता है, तो इनपुट और आउटपुट फ्लो को स्तर 0 में मूल प्रक्रिया के साथ मेल खाना चाहिए। इस संतुलन से यह सुनिश्चित होता है कि मॉडल पूरे जीवनचक्र में एक विश्वसनीय संदर्भ बना रहे।
🚀 सिस्टम आर्किटेक्चर में स्केलेबिलिटी पैटर्न
स्केल के लिए डिज़ाइन करने के लिए विशिष्ट मॉडलिंग चयनों की आवश्यकता होती है। मानक आरेख अक्सर लोड हैंडलिंग तंत्र को छिपा देते हैं। स्केलेबिलिटी को संबोधित करने के लिए, आर्किटेक्ट्स को कार्य वितरण या संसाधन प्रबंधन के पैटर्न को स्पष्ट रूप से प्रस्तुत करना चाहिए।
1. लोड बैलेंसिंग और वितरण
उच्च ट्रैफिक वाले सिस्टम में, एक ही प्रक्रिया सभी आने वाले अनुरोधों को हैंडल नहीं कर सकती है। DFD में वितरण तंत्र को दर्शाना आवश्यक है।
- राउटर पैटर्न: एक प्रक्रिया नोड का परिचय दें जो ट्रैफिक को कई सेवा नोड्स की ओर निर्देशित करता है।
- प्रतिलिपि बनाना: कई समान प्रक्रियाओं को दिखाएं जो समान डेटा प्रवाह को समानांतर प्रोसेसिंग के लिए प्राप्त करती हैं।
- कतारबद्ध करना: एक डेटा स्टोर का प्रतिनिधित्व करें जो प्रोसेसिंग शुरू होने से पहले बफर के रूप में कार्य करता है, शिखरों को चिकना करता है।
जब एक राउटर बनाते हैं, तो सुनिश्चित करें कि फ्लो तार्किक रूप से विभाजित हो। यदि सिस्टम राउंड-रॉबिन रणनीति का उपयोग करता है, तो आरेख में यह दर्शाना चाहिए कि निर्णय लोड पर आधारित है, डेटा कंटेंट पर नहीं। इस अंतर का बैकएंड लॉजिक के अनुप्रयोग पर प्रभाव पड़ता है।
2. असिंक्रोनस प्रोसेसिंग
यदि एक चरण दूसरे का इंतजार करता है, तो सिंक्रोनस फ्लो बॉटलनेक बना सकते हैं। असिंक्रोनस पैटर्न प्रक्रियाओं को अलग करते हैं, जिससे सिस्टम स्वतंत्र रूप से स्केल हो सकता है।
- संदेश कतारें: एक डेटा स्टोर का उपयोग कतार का प्रतिनिधित्व करने के लिए करें। उत्पादक स्टोर में लिखता है, और उपभोक्ता बाद में इसे पढ़ता है।
- घटना प्रवाह: एक प्रक्रिया को दिखाएं जो एक घटना उत्सर्जित करती है जो ब्लॉकिंग किए बिना बहुत से डाउनस्ट्रीम उपभोक्ताओं को ट्रिगर करती है।
- बैकग्राउंड कार्य: उन्हें एक निर्दिष्ट प्रक्रिया समूह में रूट करके लंबे समय तक चलने वाले कार्यों को उपयोगकर्ता-मुख्य अनुरोधों से अलग करें।
इस अलगाव से उपयोगकर्ता-मुख्य प्रक्रियाओं को हल्का रखा जा सकता है, जबकि भारी काम पृष्ठभूमि में होता है। DFD इस अलगाव को दृश्यमान बनाता है, जिससे विकासकर्ताओं को तुरंत प्रतिक्रिया समय की अपेक्षा करने से रोका जाता है।
3. डेटा शार्डिंग और विभाजन
जैसे-जैसे डेटा का आयतन बढ़ता है, एकल स्टोरेज इकाइयाँ प्रदर्शन के बाधाएं बन जाती हैं। DFD में शार्डिंग पैटर्न डेटा को कई स्टोर्स के बीच कैसे विभाजित किया जाता है, इसे दृश्यमान करने में मदद करते हैं।
- क्षैतिज विभाजन: एक प्रक्रिया को दिखाएं जो एक ID या कुंजी के आधार पर विशिष्ट डेटा सबसेट को विभिन्न डेटा स्टोर में रूट करती है।
- पठन प्रतिकृतियाँ: प्रतिकृतियों से डेटा पढ़ने के लिए अलग-अलग फ्लो को इंगित करें जबकि लेखन प्राथमिक स्टोर में जाते हैं।
- कैशिंग लेयर्स: लेटेंसी को कम करने के लिए प्रक्रिया और मुख्य डेटाबेस के बीच एक कैश डेटा स्टोर डालें।
| पैटर्न | स्केलेबिलिटी लाभ | ट्रेड-ऑफ |
|---|---|---|
| लोड बैलेंसिंग | थ्रूपुट बढ़ता है | राज्य प्रबंधन में बढ़ी हुई जटिलता |
| असिंक्रोनस कतारें | निर्भरताओं को अलग करता है | अंततः सुसंगतता |
| शार्डिंग | स्टोरेज क्षमता बढ़ती है | शार्ड्स के बीच जटिल प्रश्न |
| कैशिंग | लेटेंसी कम करता है | डेटा अद्यतनता के जोखिम |
⚠️ बचने के लिए सामान्य एंटी-पैटर्न
अच्छे इरादों के साथ भी, डीएफडी में संरचनात्मक दोष हो सकते हैं जो सिस्टम विफलता के कारण होते हैं। इन एंटी-पैटर्न को जल्दी पहचानने से बाद में महंगे रीफैक्टरिंग से बचा जा सकता है।
1. ब्लैक होल
एक ब्लैक होल तब होता है जब एक प्रक्रिया डेटा प्राप्त करती है लेकिन कोई आउटपुट नहीं उत्पन्न करती है। यह तब होता है जब एक प्रक्रिया को डेटा को हटाने या चुपचाप प्रोसेस करने के रूप में माना जाता है।
- जोखिम:त्रुटि सूचना के बिना डेटा का नुकसान।
- सुधार: सुनिश्चित करें कि प्रत्येक इनपुट के लिए एक संबंधित आउटपुट फ्लो या स्पष्ट त्रुटि पथ हो।
- स्केलेबिलिटी प्रभाव:साइलेंट फेल्योर्स वितरित प्रणालियों में डीबग करने में कठिन होते हैं।
2. ग्रे होल
एक ग्रे होल ब्लैक होल के समान है, लेकिन इसमें आंशिक आउटपुट होता है। प्रक्रिया जितना डेटा उत्पन्न करती है, उससे अधिक डेटा का उपयोग करती है, लेकिन शेष डेटा कहाँ गया, इसकी व्याख्या नहीं करती है।
- जोखिम:अनसमझ डेटा उपभोग स्टोरेज लीक या लेनदेन त्रुटियों के कारण होता है।
- सुधार:सभी डेटा पथों को स्पष्ट रूप से मॉडल करें, त्रुटि लॉग या ऑडिट ट्रेल शामिल हों।
3. डेटा प्रवाह में चक्कर
कुछ फीडबैक लूप आवश्यक हैं (उदाहरण के लिए, पुनर्प्रयास तंत्र), लेकिन नियंत्रण बिना चक्कर अनंत प्रक्रिया लूप का कारण बन सकते हैं।
- जोखिम:सिस्टम हैंग होना या संसाधन खत्म होना।
- सुधार: आरेख में रिकर्शन की गहराई को सीमित करें और डिजाइन में टाइमआउट तंत्र को लागू करें।
4. अनंत बाहरी एकाधिकार
बहुत सारे बाहरी एकाधिकार जोड़ने से आरेख पढ़ने योग्य नहीं रहता और मूल तर्क को छिपा देता है।
- जोखिम:सिस्टम सीमाओं पर स्पष्टता का नुकसान।
- सुधार: उचित स्थिति में संबंधित एकाधिकारों को एकल “रिकॉर्ड का प्रणाली” या “उपयोगकर्ता इंटरफेस” एकाधिकार में समूहित करें।
🔄 रखरखाव और विकास के लिए सर्वोत्तम प्रथाएं
एक डीएफडी एक बार का उत्पाद नहीं है। यह सिस्टम बढ़ने के साथ विकसित होना चाहिए। मॉडल को सटीक रखने से यह सुनिश्चित होता है कि नए टीम सदस्य कोड के उलटे डिजाइन किए बिना आर्किटेक्चर को समझ सकें।
- संस्करण नियंत्रण:आरेखों को कोड की तरह लें। उन्हें एक रिपोजिटरी में स्टोर करें ताकि समय के साथ बदलावों को ट्रैक किया जा सके।
- नामकरण प्रथाएं: प्रक्रियाओं और डेटा प्रवाह के लिए स्थिर नामकरण का उपयोग करें। “उपयोगकर्ता को अपडेट करें” को हमेशा “उपयोगकर्ता को अपडेट करें” कहा जाना चाहिए, “उपयोगकर्ता विवरण बदलें” नहीं।
- नियमित ऑडिट: आरेख को वर्तमान कार्यान्वयन के अनुरूप रहने की गारंटी देने के लिए नियमित समीक्षा योजना बनाएं।
- विस्तार संतुलन: हर प्रक्रिया को उप-प्रक्रिया न बनाएं। संबंधित तर्क को समूहित करें ताकि सिस्टम के लिए प्रबंधन योग्य दृश्य बना रहे।
📝 अंतिम विचार
प्रभावी सिस्टम डिजाइन स्पष्ट संचार पर निर्भर करता है। डेटा प्रवाह आरेख वास्तुकारों, विकासकर्मियों और हितधारकों के बीच एक साझा भाषा प्रदान करता है। स्थापित पैटर्न का पालन करने और सामान्य त्रुटियों से बचने से टीमें ऐसे सिस्टम बना सकती हैं जो धीरे-धीरे विकसित हों।
याद रखें कि आरेख मॉडल होते हैं, वास्तविकता नहीं। वे जटिलता को सरल बनाते हैं ताकि इसे समझा जा सके। हालांकि, सरलीकरण को डेटा अखंडता और प्रवाह से संबंधित महत्वपूर्ण विवरणों को हटाने की अनुमति नहीं देनी चाहिए। जब एक DFD डेटा गति का सही प्रतिनिधित्व करता है, तो यह बॉटलनेक और प्रदर्शन को अनुकूलित करने के लिए भविष्यवाणी करने के लिए एक शक्तिशाली उपकरण बन जाता है।
जैसे-जैसे प्रणालियाँ अधिक वितरित होती हैं, सख्त मॉडलिंग की आवश्यकता बढ़ती है। यहाँ वर्णित पैटर्न उस सख्ती के लिए आधार प्रदान करते हैं। चाहे एक मोनोलिथिक एप्लिकेशन या माइक्रोसर्विस इकोसिस्टम का डिज़ाइन कर रहे हों, डेटा प्रवाह के सिद्धांत एक जैसे रहते हैं। जानकारी के आंदोलन पर ध्यान केंद्रित करें, और संरचना अपने आप अनुसरण करेगी।
संदर्भ आरेख से शुरू करें। सीमाओं को स्पष्ट रूप से परिभाषित करें। केवल तभी प्रक्रियाओं में गहराई से जाएँ जब आवश्यक हो। तकनीकी स्टैक के बजाय डेटा पर ध्यान केंद्रित रखें। इस अनुशासन से यह सुनिश्चित होता है कि वास्तुकला वर्षों तक लचीली और स्केलेबल रहेगी।