











टिकाऊ सिस्टम मॉडल बनाने के लिए जानकारी को कैप्चर, हस्तांतरण और बनाए रखने के तरीके के बारे में अनुशासित दृष्टिकोण की आवश्यकता होती है। डेटा फ्लो डायग्राम (DFD) के संदर्भ में, डेटा स्टोर सिस्टम स्थायित्व की रीढ़ है। डेटा कहाँ रहता है, इसके स्पष्ट डिज़ाइन के बिना, जानकारी का प्रवाह सामान्य और अनावश्यक रहता है। यह मार्गदर्शिका DFD में डेटा स्टोर के डिज़ाइन के मूल सिद्धांतों का अध्ययन करती है, जिससे स्पष्टता, सटीकता और सिस्टम आर्किटेक्चर के साथ संरेखण सुनिश्चित होता है।
प्रभावी मॉडलिंग आकृतियों के बीच रेखाएँ खींचने से आगे बढ़ती है। इसमें सिस्टम के भीतर डेटा अखंडता, पहुँच पैटर्न और जानकारी के जीवनचक्र के बारे में गहन समझ की आवश्यकता होती है। स्थापित डिज़ाइन सिद्धांतों का पालन करके, विश्लेषक ऐसे डायग्राम बना सकते हैं जो विकास टीमों के लिए विश्वसनीय नक्शे के रूप में कार्य करते हैं।
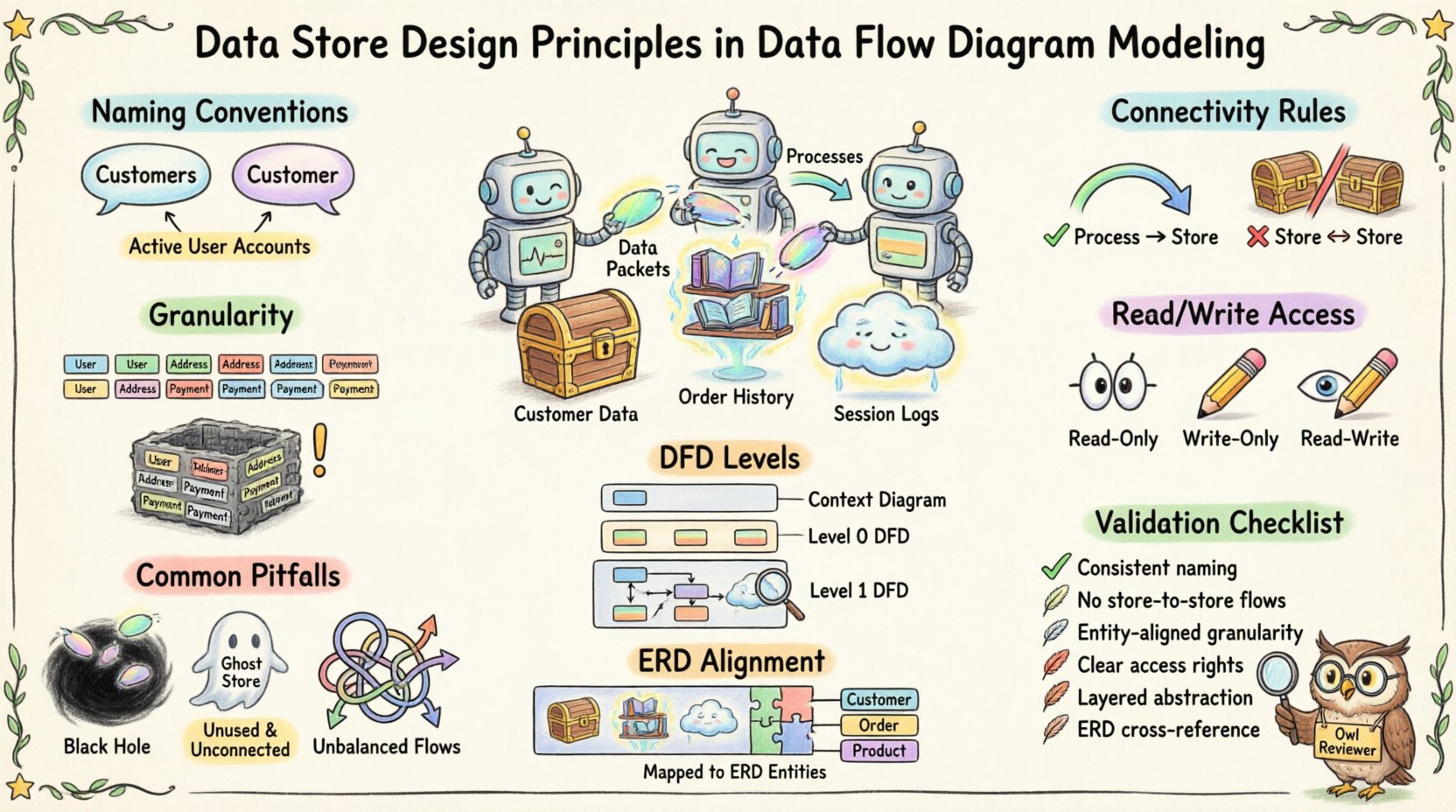
🏷️ डेटा स्टोर को परिभाषित करना 🏷️
एक डेटा स्टोर डेटा फ्लो डायग्राम में एक सक्रिय तत्व है। प्रक्रियाओं के विपरीत जो डेटा को बदलते हैं, डेटा स्टोर डेटा को विश्राम में रखते हैं। वे फाइलों, डेटाबेस, कागजी रिकॉर्ड या किसी भी भंडारण स्थान का प्रतिनिधित्व करते हैं जहाँ जानकारी बाद में प्राप्त करने के लिए सहेजी जाती है।
- सक्रिय प्रकृति: एक प्रक्रिया द्वारा स्पष्ट रूप से अनुरोध किए बिना डेटा स्टोर से बाहर नहीं बहता है।
- स्टोरेज पहचान: यह खुद एक प्रक्रिया नहीं है; यह डेटा को नहीं बदलता है, बल्कि इसे रखता है।
- दृश्य प्रतिनिधित्व: आमतौर पर एक खुले छोर वाले आयत या डबल ऊर्ध्वाधर रेखाओं के रूप में दिखाया जाता है, जो उपयोग किए जाने वाले नोटेशन मानक पर निर्भर करता है।
जब इन तत्वों को डिज़ाइन करते समय, ध्यान भौतिक कार्यान्वयन के बजाय तार्किक आवश्यकता पर रहना चाहिए। DFD बताता है किक्या डेटा की आवश्यकता है, नहीं किकैसे इसे भौतिक रूप से हार्ड ड्राइव पर इंडेक्स या स्टोर किया जाता है।
📝 स्पष्टता के लिए नामकरण प्रणाली 📝
नामकरण भ्रम के खिलाफ पहली रक्षा रेखा है। अस्पष्ट लेबल डिज़ाइन चरण में गलत व्याख्या के कारण बनते हैं। एक अच्छे नाम वाले डेटा स्टोर को उसमें संग्रहीत जानकारी के बारे में तुरंत संदर्भ प्रदान करता है।
1. एकवचन बनाम बहुवचन
संगतता महत्वपूर्ण है। कुछ टीमें एकवचन संज्ञा को प्राथमिकता देती हैं (उदाहरण के लिए, ग्राहक) जबकि अन्य बहुवचन का उपयोग करते हैं (उदाहरण के लिए, ग्राहक)। महत्वपूर्ण बात यह है कि पूरे मॉडल में एक ही प्रणाली का उपयोग किया जाता है।
- सिफारिश: डेटा के सेट के लिए बहुवचन संज्ञा का उपयोग करें (उदाहरण के लिए, आदेश, उत्पाद) एक संग्रह को इंगित करने के लिए।
- अपवाद:एकल नाम केवल तभी काम करते हैं जब स्टोर केवल एक ही प्रकार के रिकॉर्ड को रखता है (उदाहरण के लिए, कॉन्फ़िगरेशन).
2. वर्णनात्मक सटीकता
सामान्य शब्दों जैसे डेटा या जानकारी. इन लेबलों में सामग्री के बारे में कोई जानकारी नहीं होती है।
- बुरा उदाहरण: सिस्टम डेटा
- अच्छा उदाहरण: सक्रिय उपयोगकर्ता खाते
विशिष्ट नामकरण स्टेकहोल्डर्स को स्टोर के दायरे को तुरंत पहचानने में मदद करता है। आरेख को समझने के लिए आवश्यक मानसिक भार को कम करता है।
3. काल और अवस्था
नाम डेटा की अवस्था को दर्शाना चाहिए। यदि स्टोर ऐतिहासिक रिकॉर्ड रखता है, तो नाम में इसका उल्लेख होना चाहिए।
- लेनदेन लॉग पिछली घटनाओं के रिकॉर्ड को इंगित करता है।
- रुके हुए आदेश कार्रवाई का इंतजार कर रहे डेटा को इंगित करता है।
🔗 जुड़ाव नियम 🔗
स्टोर में डेटा के आने और बाहर जाने को सख्त तार्किक नियमों द्वारा नियंत्रित किया जाता है। इन नियमों के उल्लंघन से DFD की अखंडता नष्ट हो जाती है।
1. प्रक्रिया जुड़ाव आवश्यकता
एक डेटा स्टोर को हमेशा कम से कम एक प्रक्रिया से जुड़ा होना चाहिए। यह अकेले अस्तित्व में नहीं आ सकता।
- इनपुट: एक प्रक्रिया को स्टोर में डेटा लिखना चाहिए (उदाहरण के लिए, एक नया रिकॉर्ड सहेजना)।
- आउटपुट: एक प्रक्रिया को स्टोर से डेटा पढ़ना चाहिए (उदाहरण के लिए, एक रिकॉर्ड प्राप्त करना)।
यदि कोई स्टोर किसी चीज से जुड़ा नहीं है, तो यह एक भूत तत्व है जिसका कोई कार्य नहीं है। यदि यह एक से अधिक प्रक्रियाओं से जुड़ा है, तो प्रत्येक जुड़ाव के लिए डेटा के प्रवाह को स्पष्ट रूप से परिभाषित किया जाना चाहिए।
2. सीधे स्टोर से स्टोर फ्लो नहीं
किसी प्रक्रिया के बीच बिना डेटा एक डेटा स्टोर से दूसरे डेटा स्टोर में सीधे नहीं जा सकता है। इस नियम ने डेटा संग्रहण से पहले डेटा परिवर्तन या प्रमाणीकरण होने के सिद्धांत को बल देने का काम करता है।
- गलत: लाइन जो जोड़ती है स्टोर A सीधे स्टोर B.
- सही: प्रक्रिया X से पढ़ता है स्टोर A, डेटा को बदलता है, और लिखता है स्टोर B.
इस अलगाव से यह सुनिश्चित होता है कि डेटा के स्थायी होने से पहले व्यावसायिक तर्क, प्रमाणीकरण या प्रारूपण लागू किया जाता है। यह मॉडल को यह सुझाव देने से रोकता है कि डेटा बिना निगरानी के सिर्फ कॉपी कर दिया गया है।
3. डेटा फ्लो लेबलिंग
प्रक्रिया और डेटा स्टोर को जोड़ने वाली प्रत्येक लाइन को लेबल करना आवश्यक है। लेबल उस विशिष्ट डेटा का वर्णन करता है जो उस सीमा के पार जा रहा है।
- उदाहरण: एक लाइन आर्डर प्रक्रिया से आर्डर स्टोर को लेबल किया जा सकता है आर्डर विवरण.
- उदाहरण: एक लाइन आर्डर स्टोर से रिपोर्ट प्रक्रिया को लेबल किया जा सकता है आदेश इतिहास.
लेबल डेटा के आयतन और प्रकार के संदर्भ को प्रदान करते हैं जो स्थानांतरित किया जा रहा है। वे विकासकर्मियों को बाद में स्कीमा आवश्यकताओं को समझने में मदद करते हैं।
🎯 विस्तार और दायरा 🎯
डेटा को स्टोर में कैसे विभाजित करना है, यह एक महत्वपूर्ण डिजाइन निर्णय है। बहुत अधिक स्टोर मॉडल को टुकड़ों में बांट देते हैं, जबकि बहुत कम स्टोर जानकारी के एक एकल ब्लॉक के रूप में बनाते हैं।
1. एंटिटी-आधारित समूहन
डेटा को तार्किक एंटिटी के आधार पर समूहित करें। यदि प्रणाली ग्राहकों, उत्पादों और बिलों को ट्रैक करती है, तो इन्हें आमतौर पर अलग-अलग स्टोर में रखा जाना चाहिए।
- लाभ: रखरखाव को सरल बनाता है। ग्राहक डेटा में परिवर्तन बिल स्टोरेज तर्क को प्रभावित नहीं करते हैं।
- लाभ: अपडेट के दौरान अनजाने डेटा क्षति के जोखिम को कम करता है।
2. पढ़ने-लिखने का अलगाव
यह विचार करें कि क्या एक स्टोर मुख्य रूप से पढ़ने के लिए है या लिखने के लिए। उच्च आयतन वाले लेनदेन लॉग को आमतौर पर संदर्भ डेटा की तुलना में अलग स्टोरेज हैंडलिंग की आवश्यकता होती है।
- संदर्भ डेटा: जैसे स्टोरदेश कोड पढ़ने पर अधिक निर्भर हैं और बहुत कम बदलते हैं।
- लेनदेन डेटा: जैसे स्टोरबिक्री लॉग लिखने पर अधिक निर्भर हैं और समय के साथ बढ़ते हैं।
इन प्रकारों को अलग करने में क्षमता और पहुंच पैटर्न की योजना बनाने में मदद मिलती है, भले ही DFD एक तार्किक मॉडल बना रहता है।
3. अस्थायी बनाम स्थायी
सभी डेटा स्टोर स्थायी रखरखाव का प्रतिनिधित्व नहीं करते हैं। कुछ अस्थायी बफर हैं।
- सेशन डेटा: लॉगिन प्रक्रिया के दौरान अस्थायी उपयोगकर्ता सेशन के लिए उपयोग किए जाने वाले स्टोर।
- कैश स्टोर: अक्सर पहुंचे जाने वाले डेटा के लिए अस्थायी धारण क्षेत्र।
अस्थायी स्टोर को स्पष्ट रूप से चिह्नित करने से डेटा रखरखाव नीतियों के संबंध में भ्रम से बचा जा सकता है। प्रक्रिया पूरी होने के बाद अस्थायी स्टोर को खाली कर देना चाहिए।
🔄 डेटा प्रवाह और प्रक्रिया बातचीत 🔄
एक प्रक्रिया और डेटा स्टोर के बीच संबंध बहुत स्थितियों में द्विदिशात्मक होता है, लेकिन हमेशा नहीं। सही मॉडलिंग के लिए दिशात्मकता को समझना आवश्यक है।
1. केवल पढ़ने की अनुमति
कुछ स्टोर केवल पढ़ने के लिए एक्सेस किए जाते हैं। एक प्रक्रिया डेटा को बदले बिना जानकारी प्रदर्शित करने के लिए स्टोर को प्रश्न कर सकती है।
- उदाहरण: एक प्रोफाइल प्रदर्शित करें प्रक्रिया से पढ़नाउपयोगकर्ता प्रोफाइल स्टोर.
- प्रतिबंध: किसी लेन-देन के लिए स्टोर से प्रक्रिया की ओर और वापस डेटा प्रवाह तीर नहीं होना चाहिए, जब तक कि यह लेखन क्रिया को निरूपित न करे।
2. केवल लेखन की अनुमति
कुछ प्रक्रियाएं डेटा लेने के बिना डेटा लिखती हैं।
- उदाहरण: एक घटना लॉग प्रक्रिया लिखनासिस्टम ऑडिट स्टोर.
- प्रतिबंध: सुनिश्चित करें कि प्रक्रिया के बाहरी इनपुट के बिना डेटा को सही तरीके से लिखने के लिए आवश्यक संदर्भ हो।
3. पढ़ने-लिखने की अनुमति
अधिकांश व्यावसायिक प्रक्रियाएं डेटा को प्राप्त करने, संशोधित करने और सहेजने में शामिल होती हैं।
- उदाहरण: इन्वेंटरी अपडेट करें वर्तमान स्टॉक पढ़ता है, नया राशि की गणना करता है और इसे सहेजता है।
- मॉडलिंग: क्रियाओं के क्रम को स्पष्ट करने के लिए पढ़ने और लिखने के लिए अलग-अलग प्रवाह का उपयोग करें।
यह अंतर विकासकर्ताओं को समझने में मदद करता है कि क्या एक डेटाबेस लेनदेन को तुरंत लॉक या कॉमिट करने की आवश्यकता है।
📊 डीएफडी स्तर और स्टोर दृश्यता 📊
डीएफडी को अक्सर स्तरों में विभाजित किया जाता है, संदर्भ आरेख (स्तर 0) से विस्तृत विभाजन (स्तर 2, स्तर 3) तक। प्रत्येक स्तर पर डेटा स्टोर अलग-अलग तरीके से दिखाई देते हैं।
1. संदर्भ स्तर (स्तर 0)
उच्चतम स्तर पर, डेटा स्टोर को आमतौर पर छोड़ दिया जाता है ताकि सरलता बनी रहे। ध्यान बाहरी एकाधिकारों और मुख्य सिस्टम सीमा पर केंद्रित होता है।
- कारण:बहुत अधिक विवरण उच्च स्तर के डेटा आदान-प्रदान को धुंधला कर देता है।
- अपवाद:महत्वपूर्ण बाहरी डेटाबेस को दिखाया जा सकता है यदि वे सिस्टम सीमा के लिए महत्वपूर्ण हैं।
2. स्तर 1 विभाजन
जैसे ही सिस्टम प्रमुख प्रक्रियाओं में विभाजित किया जाता है, डेटा स्टोर दिखाई देने लगते हैं। यहीं मुख्य भंडारण संरचना को परिभाषित किया जाता है।
- फोकस:प्रत्येक प्रमुख कार्य के लिए आवश्यक मुख्य भंडारण स्थलों की पहचान करें।
- विवरण:यह सुनिश्चित करें कि प्रत्येक प्रक्रिया के आउटपुट डेटा के लिए एक गंतव्य हो।
3. स्तर 2 और उससे आगे
अधिक विभाजन बड़े डेटा स्टोर को छोटे, अधिक विशिष्ट स्टोर में विभाजित कर सकता है।
- उदाहरण: ग्राहक स्टोर स्तर 1 पर विभाजित हो सकता है संपर्क जानकारी स्टोर और बिलिंग स्टोर स्तर 2 पर।
- सांस्कृतिकता:यह सुनिश्चित करें कि निम्न स्तरों पर डेटा उच्च स्तरों पर डेटा के साथ मेल खाता हो। मूल आरेख में नहीं मौजूद नए डेटा प्रकारों को न जोड़ें।
⚠️ सामान्य त्रुटियाँ ⚠️
यहां तक कि अनुभवी विश्लेषक भी डेटा स्टोर डिजाइन करते समय गलतियां करते हैं। इन सामान्य त्रुटियों से बचने से आरेख की सटीकता बनी रहती है।
- काले छेद:एक प्रक्रिया जो डेटा लेती है लेकिन कहीं भी उसे लिखती नहीं है। इसका अर्थ है डेटा का नुकसान।
- आग के तूफान: एक प्रक्रिया जो डेटा को लेती है लेकिन किसी स्टोर के बिना डेटा बाहर निकालती है। इसका अर्थ है कि डेटा बिना किसी कारण के बनाई जाती है (चमत्कार)।
- भूतों के स्टोर: ऐसे डेटा स्टोर जिनके कोई जुड़ी प्रक्रियाएं नहीं हैं। ये मृत निकास हैं।
- असंतुलित प्रवाह: जब लेवल 1 से लेवल 2 में जाया जाता है, तो इनपुट और आउटपुट के मैच होने चाहिए। यदि लेवल 2 में कोई स्टोर जोड़ा जाता है, तो उसके लिए मातृ प्रक्रिया के इनपुट/आउटपुट के आधार पर तर्क देना होगा।
- अत्यधिक डिजाइनिंग: हर डेटाबेस टेबल को लेवल 1 डायग्राम में अलग-अलग स्टोर के रूप में मॉडल करने की कोशिश। भौतिक टेबल के बजाय तार्किक एंटिटी पर ध्यान केंद्रित करें।
📚 डेटा मॉडल्स के साथ संरेखण 📚
जबकि DFDs प्रवाह पर ध्यान केंद्रित करते हैं, उन्हें एंटिटी रिलेशनशिप डायग्राम (ERD) या तार्किक डेटा मॉडल के साथ संरेखित होना चाहिए। DFD में डेटा स्टोर को ERD में एंटिटी के साथ मेल बैठाना चाहिए।
- संगतता जांच: यदि DFD में है उत्पाद स्टोर, तो ERD में होना चाहिए उत्पाद एंटिटी।
- एट्रिब्यूट मैपिंग: प्रक्रिया द्वारा स्टोर के साथ बातचीत करने के लिए आवश्यक एट्रिब्यूट को डेटा मॉडल में मौजूद होना चाहिए।
- नॉर्मलाइजेशन: जबकि DFDs नॉर्मलाइजेशन को बाध्य नहीं करते हैं, डिजाइन में स्पष्ट अतिरिक्तता से बचना चाहिए जो खराब डेटाबेस डिजाइन का संकेत करती है।
इस संरेखण से यह सुनिश्चित होता है कि तार्किक डिजाइन (DFD) को भौतिक कार्यान्वयन (डेटाबेस स्कीमा) में बिना बड़े पुनर्निर्माण के बदला जा सकता है।
🔍 डिजाइन सत्यापन चेकलिस्ट 🔍
डेटा फ्लो डायग्राम को अंतिम रूप देने से पहले, डेटा स्टोर डिजाइन की पुष्टि करने के लिए निम्नलिखित चेकलिस्ट का उपयोग करें।
| सिद्धांत | चेकलिस्ट आइटम | स्थिति |
|---|---|---|
| नामकरण | क्या सभी स्टोर नाम वर्णनात्मक और संगत हैं? | ☐ |
| कनेक्टिविटी | क्या प्रत्येक स्टोर कम से कम एक प्रक्रिया से जुड़ा है? | ☐ |
| प्रवाह दिशा | क्या तीर प्रक्रियाओं और स्टोर के बीच सही दिशा में इशारा कर रहे हैं? | ☐ |
| लेबलिंग | क्या डेटा सामग्री के नाम वाली लाइनों के माध्यम से प्रवाहित हो रहा है? | ☐ |
| कोई सीधे स्टोर लिंक नहीं | क्या कोई लाइन स्टोर को स्टोर से सीधे जोड़ती है? | ☐ |
| सांस्कृतिक एकरूपता | क्या निचले स्तर के स्टोर माता-पिता स्तर के दायरे के अनुरूप हैं? | ☐ |
| अखंडता | क्या उपलब्ध स्टोर द्वारा प्रक्रियाओं की सभी डेटा आवश्यकताओं को पूरा किया जाता है? | ☐ |
🔄 रखरखाव और विकास 🔄
सिस्टम आवश्यकताएं बदलती हैं। डेटा स्टोर को इन बदलावों के अनुकूल होना चाहिए बिना मॉडल को तोड़े।
- संस्करण नियंत्रण:स्टोर परिभाषाओं में बदलावों का अनुसरण करें। यदि कोई स्टोर विभाजित होता है, तो पुनर्स्थापना मार्ग का विवरण दर्ज करें।
- पुराने डेटा:यह योजना बनाएं कि स्टोर स्कीमा बदलने पर पुराने डेटा का क्या होगा। इसके लिए अक्सर एक आर्काइव स्टोर की आवश्यकता होती है।
- फीडबैक लूप:विकास टीमों से प्राप्त फीडबैक का उपयोग करके स्टोर के विस्तार को बेहतर बनाएं। यदि विकासकर्ता किसी स्टोर को बहुत व्यापक पाते हैं, तो उसे विभाजित करें। यदि वे इसे बहुत टुकड़ों में पाते हैं, तो इसे मिलाएं।
एक स्थिर मॉडल एक जोखिम है। जब भी व्यावसायिक नियम बदलते हैं या नए सुरक्षा आवश्यकताएं लागू होती हैं, तो डेटा स्टोर डिजाइन की समीक्षा की जानी चाहिए। इससे यह सुनिश्चित होता है कि DFD एक जीवित दस्तावेज बनी रहे जो सिस्टम की डेटा आवश्यकताओं को सही ढंग से प्रतिबिंबित करे।
📝 कार्यान्वयन पर निष्कर्ष
डेटा फ्लो डायग्राम में डेटा स्टोर का डिजाइन सिस्टम विश्लेषण के लिए एक मूलभूत कार्य है। यह अमूर्त प्रक्रियाओं और वास्तविक डेटा संरक्षण के बीच के अंतर को पार करता है। सख्त नामकरण प्रथाओं, जुड़ाव नियमों और विस्तार सिद्धांतों का पालन करके विश्लेषक ऐसे मॉडल बनाते हैं जो दोनों पठनीय और कार्यान्वयन योग्य होते हैं।
लक्ष्य डेटाबेस स्कीमा की बिल्कुल सटीक प्रतिलिपि बनाना नहीं है, बल्कि डेटा संग्रहण की तार्किक आवश्यकता को पकड़ना है। जब DFD सही होता है, तो विकास में संक्रमण आसान होता है, और डेटा हानि या असंगति का जोखिम महत्वपूर्ण रूप से कम हो जाता है। स्पष्टता, सांस्कृतिक एकरूपता और जानकारी के तार्किक प्रवाह पर ध्यान केंद्रित करके उच्च गुणवत्ता वाले सिस्टम डिजाइन बनाएं।