











जटिल वितरित प्रणालियों को डिज़ाइन करने के लिए केवल कोड लिखने से अधिक चाहिए; इसमें एक स्पष्ट दृश्य भाषा की आवश्यकता होती है जिसे हितधारक समझ सकें। 🏗️ डेटा फ्लो डायग्राम (DFD) इस भाषा के रूप में कार्य करते हैं, जो जानकारी के विभिन्न नोड्स, सेवाओं और स्टोरेज इकाइयों के बीच गति को नक्शा बनाते हैं। वितरित वातावरण में लागू करने पर, DFDs कार्यान्वयन शुरू होने से पहले बॉटलनेक, सुरक्षा जोखिम और सुसंगतता की चुनौतियों को पहचानने के लिए महत्वपूर्ण उपकरण बन जाते हैं।
यह मार्गदर्शिका प्रभावी वितरित प्रणाली मॉडल बनाने की विधि का अध्ययन करती है। हम मुख्य घटकों, विघटन प्रक्रिया और डेटा नेटवर्क सीमाओं को पार करते समय आवश्यक विशिष्ट विचारों का अध्ययन करेंगे। स्थापित मॉडलिंग विधियों का पालन करके टीमें यह सुनिश्चित कर सकती हैं कि उनकी वास्तुकला स्केलेबिलिटी और विश्वसनीयता का समर्थन करे।
🌐 वितरित प्रणालियों के संदर्भ को समझना
वितरित प्रणालियाँ बहुत सारे स्वतंत्र कंप्यूटरों से मिलकर बनती हैं जो उपयोगकर्ताओं के लिए एकल सुसंगत प्रणाली के रूप में दिखती हैं। मोनोलिथिक आर्किटेक्चर के विपरीत, इन वातावरणों में संचार, राज्य प्रबंधन और विफलता के तरीकों के संबंध में जटिलता आती है। 🚀 इन प्रणालियों के मॉडलिंग के लिए आंतरिक प्रक्रिया तर्क से बाहरी संचार मार्गों की ओर दृष्टिकोण में परिवर्तन की आवश्यकता होती है।
- नेटवर्क सीमाएँ: डेटा अक्सर भौतिक या तार्किक नेटवर्कों को पार करता है, जिससे लेटेंसी और संभावित विफलता के बिंदु आते हैं।
- सेवा विभाजनता: प्रणालियों को छोटी सेवाओं में बांटा जाता है, जिनमें से प्रत्येक विशिष्ट जिम्मेदारियों का निर्वहन करता है।
- राज्यहीनता बनाम राज्ययुक्तता: कुछ घटक इतिहास को बनाए रखे बिना अनुरोधों को प्रक्रिया करते हैं, जबकि अन्य स्थायी डेटा का प्रबंधन करते हैं।
- असमान संचार: बहुत से वितरित अंतरक्रियाएँ सीधे समकालीन कॉल के बजाय संदेश भंडार पर निर्भर करती हैं।
स्पष्ट नक्शे के बिना, टीमें एक ‘स्पैगेटी आर्किटेक्चर’ बनाने के जोखिम में हैं जहाँ डेटा के प्रवाह स्पष्ट नहीं होते। एक अच्छी तरह से संरचित DFD इन अंतरक्रियाओं को स्पष्ट करता है, यह सुनिश्चित करते हुए कि प्रत्येक डेटा बिंदु का परिभाषित उत्पत्ति और गंतव्य हो।
🔍 प्रणाली डिज़ाइन में डेटा फ्लो डायग्राम की भूमिका
एक डेटा फ्लो डायग्राम एक सूचना प्रणाली के माध्यम से डेटा के प्रवाह का आलेखीय प्रतिनिधित्व है। इसमें समय या नियंत्रण तर्क को नहीं दिखाया जाता है, बल्कि डेटा के प्रणाली में प्रवेश, परिवर्तन, गति और बाहर निकलने के तरीके पर ही ध्यान केंद्रित किया जाता है। 🧭
वितरित संदर्भ में, DFD मदद करता है:
- जहाँ डेटा का उत्पत्ति होती है (बाहरी एकाइयाँ)।
- कैसे इसका प्रक्रिया की जाती है (प्रक्रियाएँ)।
- जहाँ इसे अस्थायी या स्थायी रूप से संग्रहीत किया जाता है (डेटा भंडार)।
- कैसे यह घटकों के बीच यात्रा करता है (डेटा प्रवाह)।
DFD का उपयोग करने से वास्तुकार अपनी प्रस्तावित आर्किटेक्चर के खिलाफ आवश्यकताओं की पुष्टि कर सकते हैं। यह सुनिश्चित करता है कि कोई भी डेटा वैध कारण के बिना न तो बनाया जाए और न ही नष्ट किया जाए, जिससे जीवनचक्र के दौरान अखंडता बनी रहे।
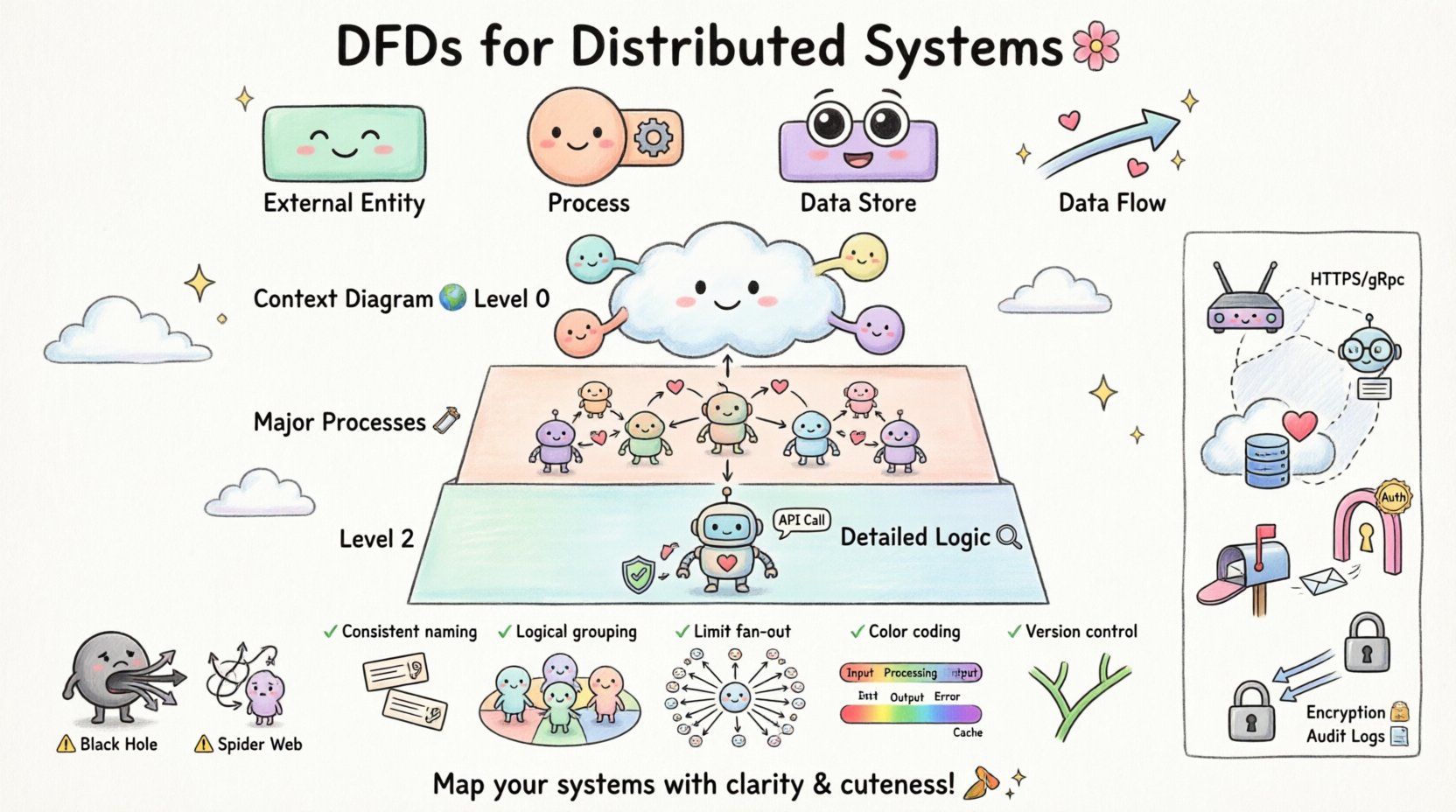
DFD के मुख्य घटक
एक वैध मॉडल बनाने के लिए, आपको मानक नोटेशन में उपयोग किए जाने वाले चार प्राथमिक प्रतीकों को समझना होगा। प्रत्येक आलेखी प्रतिनिधित्व में एक अलग उद्देश्य के लिए कार्य करता है।
| घटक | कार्य | दृश्य प्रतिनिधित्व |
|---|---|---|
| बाहरी एकाइयाँ | प्रणाली सीमा के बाहर डेटा का स्रोत या गंतव्य। | आयत |
| प्रक्रिया | इनपुट से आउटपुट तक डेटा का परिवर्तन। | वृत्त या गोल कोने वाला आयत |
| डेटा भंडार | वह स्थान जहां डेटा बाद में उपयोग के लिए रखा जाता है। | खुला आयत या समानांतर रेखाएं |
| डेटा प्रवाह | घटकों के बीच डेटा के गतिशीलता। | तीर |
जब वितरित प्रणालियों के मॉडलिंग करते हैं, तो हर तीर को एक संज्ञा वाक्यांश से लेबल करना महत्वपूर्ण है जो डेटा की सामग्री का वर्णन करे, कोई क्रिया नहीं। उदाहरण के लिए, “उपयोगकर्ता प्रमाणपत्र” का उपयोग करें, “प्रमाणपत्र भेजना” के बजाय।
📉 डीएफडी अपघटन के स्तर
जटिल प्रणालियों को एक ही दृश्य में प्रदर्शित नहीं किया जा सकता है। अपघटन आपको उच्च स्तर के सारांश से विस्तृत विवरण में गहराई से जाने की अनुमति देता है। इस दृष्टिकोण से पाठक को ज्ञानात्मक अत्यधिक भार नहीं लगता है।
स्तर 0: संदर्भ आरेख
संदर्भ आरेख उच्चतम स्तर के सारांश प्रदान करता है। यह पूरी प्रणाली को एकल प्रक्रिया के रूप में दिखाता है और उन सभी बाहरी एकाधिकारों की पहचान करता है जो इससे बातचीत करते हैं। 🌍
- परिधि:प्रणाली की सीमा को परिभाषित करता है।
- बातचीत:बाहरी दुनिया से सभी इनपुट और आउटपुट दिखाता है।
- स्पष्टता:स्टेकहोल्डर्स को प्रणाली के उद्देश्य को तकनीकी विवरण के बिना समझने में मदद करता है।
स्तर 1: मुख्य प्रक्रियाएं
स्तर 1 संदर्भ आरेख से एकल प्रक्रिया को मुख्य उप-प्रक्रियाओं में विस्तारित करता है। इस स्तर पर प्रणाली को कार्य के आधार पर तार्किक खंडों में बांटा जाता है। 🛠️
- अपघटन:प्रणाली को 5 से 9 तक मुख्य प्रक्रियाओं में विभाजित करता है।
- प्रवाह:ये मुख्य प्रक्रियाओं के बीच डेटा के गतिशीलता को दिखाता है।
- भंडार:इन प्रक्रियाओं के समर्थन करने वाले डेटा भंडार का परिचय देता है।
स्तर 2 और आगे: विस्तृत तर्क
स्तर 2 पर अधिक अपघटन होता है, जहां विशिष्ट उप-प्रक्रियाओं को विभाजित किया जाता है। यह अक्सर वह स्थान होता है जहां कार्यान्वयन विवरण उभरने लगते हैं, जैसे विशिष्ट सत्यापन नियम या API कॉल। 🔍
वितरित मॉडलिंग में, स्तर 2 आरेख विशेष रूप से सेवा सीमाओं को परिभाषित करने में उपयोगी होते हैं। वे यह पहचानने में मदद करते हैं कि कौन सी प्रक्रिया किस सेवा नोड में स्थित होनी चाहिए।
⚡ वितरित वातावरणों का मॉडलिंग
मानक DFDs अक्सर एकल एकल परिवेश के बारे में मानते हैं। जब उन्हें वितरित प्रणालियों के लिए अनुकूलित किया जाता है, तो नेटवर्क की वास्तविकताओं को दर्शाने के लिए विशिष्ट चिह्नों और विचारों को लागू करना होता है। 🌐
यहाँ मानक बनाम वितरित मॉडलिंग तत्वों की तुलना है:
| तत्व | मानक मॉडलिंग | वितरित मॉडलिंग |
|---|---|---|
| डेटा प्रवाह | सीधा तार्किक प्रवाह। | नेटवर्क स्थानांतरण, देरी, प्रोटोकॉल। |
| प्रक्रिया | एकल गणना इकाई। | माइक्रोसर्विस, कंटेनर, या सर्वरलेस फ़ंक्शन। |
| डेटा भंडार | स्थानीय डेटाबेस। | बादल भंडारण, वितरित कैश, या शेडेड डीबी। |
| सीमा | प्रणाली सीमा। | नेटवर्क सीमा, विश्वास क्षेत्र, या API गेटवे। |
जब विभिन्न नोड्स में प्रक्रियाओं के बीच डेटा प्रवाह बनाते हैं, तो प्रवाह को परिवहन तंत्र (जैसे HTTPS, gRPC, संदेश भंडार) के साथ टिप्पणी करना उपयोगी होता है। इससे प्रदर्शन और सुरक्षा की आवश्यकताओं के संदर्भ में स्पष्टता आती है।
🛡️ समानांतरता और अवस्था का प्रबंधन
वितरित प्रणालियाँ अक्सर समानांतर अनुरोधों का प्रबंधन करती हैं। एक स्थिर DFD समय को स्पष्ट रूप से नहीं दिखा सकता है, लेकिन इन बातचीत के दौरान अवस्था का प्रबंधन कैसे किया जाता है, इसका इंगित करना चाहिए। ⏳
- राज्यहीन प्रक्रियाएँ: यदि कोई प्रक्रिया अवस्था को स्टोर नहीं करती है, तो DFD को डेटा के बहाव को दिखाना चाहिए और उसे उस विशिष्ट लेनदेन के लिए स्टोर में वापस नहीं लौटने देना चाहिए।
- राज्य वाली प्रक्रियाएँ: यदि कोई प्रक्रिया अवस्था को बनाए रखती है, तो इस जानकारी को स्थायी रूप से रखने वाले डेटा भंडार तक स्पष्ट डेटा प्रवाह होना चाहिए।
- सांस्कृतिकता: अद्यतन का प्रतिनिधित्व करने वाले डेटा प्रवाहों को यह दर्शाना चाहिए कि नोड्स के बीच सांस्कृतिकता कैसे बनाए रखी जाती है।
उदाहरण के लिए, जब एक खरीदारी गाड़ी का मॉडलिंग करते हैं, तो DFD को उपयोगकर्ता एकाइटी से कार्ट सेवा तक और फिर डेटाबेस भंडार तक जाने वाले “कार्ट डेटा” को दिखाना चाहिए। यदि कार्ट सेवा वितरित है, तो प्रवाह यह दिखाना चाहिए कि कौन सा नोड डेटा की अधिकृत प्रति रखता है।
🚫 वितरित मॉडलिंग में आम त्रुटियाँ
सही डिज़ाइन करने वाले वास्तुकार भी वितरित डेटा प्रवाह के दृश्यीकरण के समय गलतियाँ कर सकते हैं। इन सामान्य त्रुटियों के बारे में जागरूक होने से मॉडल की गुणवत्ता में सुधार होता है। 🚧
| गड्ढा | प्रभाव | सुधार |
|---|---|---|
| काला छेद प्रक्रिया | डेटा एक प्रक्रिया में आता है लेकिन कभी बाहर नहीं जाता। | सुनिश्चित करें कि प्रत्येक इनपुट का संबंधित आउटपुट या स्टोरेज हो। |
| ग्रे होल प्रक्रिया | आउटपुट मौजूद हैं, लेकिन कोई इन्हें समझाने वाला इनपुट नहीं है। | प्रत्येक आउटपुट प्रवाह के लिए सभी डेटा स्रोतों की पुष्टि करें। |
| मकड़ी का जाल | बहुत सारी लाइनें एक दूसरे को काटती हैं जिससे भ्रम होता है। | संबंधित प्रवाहों को समूहित करने के लिए उप-प्रक्रियाओं का उपयोग करें। |
| नेटवर्क की उपेक्षा | लेटेंसी या विफलता बिंदुओं की उपेक्षा करना। | प्रवाहों को प्रोटोकॉल और विश्वसनीयता के नोट्स के साथ टिप्पणी करें। |
डेटा स्टोर के बीच प्रक्रिया के बिना सीधे कनेक्शन बनाने से बचें। डेटा स्टोर केवल उन प्रक्रियाओं के माध्यम से ही बातचीत करनी चाहिए जो डेटा की पुष्टि और परिवर्तन करती हैं। इससे अनधिकृत सीधे पहुंच को रोका जाता है और व्यापार तर्क को लागू किया जाता है।
📝 स्पष्टता के लिए सर्वोत्तम व्यवहार
एक आकृति बनाना जो दोनों सटीक और पठनीय हो, विशिष्ट डिज़ाइन सिद्धांतों का पालन करने की आवश्यकता होती है। 🎨
- संगत नामकरण:सभी आरेखों में एक ही डेटा के लिए एक ही शब्दावली का उपयोग करें। यदि स्तर 0 में “उपयोगकर्ता ID” का उपयोग किया गया है, तो स्तर 1 में इसे “ग्राहक कुंजी” नाम न दें।
- तार्किक समूहन:दृश्य रूप से संबंधित प्रक्रियाओं को एक साथ समूहित करें। इससे सेवा सीमाओं की पहचान करने में मदद मिलती है।
- फैन-आउट की सीमा निर्धारित करें:एक ही प्रक्रिया को दस से अधिक डेटा प्रवाहों से जोड़ने से बचें। यदि ऐसा होता है, तो प्रक्रिया को विभाजित करें।
- रंग कोडिंग:आ interनल प्रक्रियाओं, बाहरी एजेंसियों और डेटा स्टोर के बीच अंतर करने के लिए रंगों का उपयोग करें। इससे तेजी से स्कैन करने में मदद मिलती है।
- संस्करण नियंत्रण:आरेखों को कोड की तरह लें। उन्हें संस्करण नियंत्रण में स्टोर करें ताकि समय के साथ बदलावों को ट्रैक किया जा सके।
वितरित प्रणालियों के लिए मॉडलिंग करते समय, अलग-अलग विश्वास क्षेत्रों या नेटवर्क सेगमेंट का प्रतिनिधित्व करने के लिए स्विमलेन का उपयोग करने के बारे में सोचें। इससे तुरंत स्पष्ट हो जाता है कि कौन से घटक सार्वजनिक अनुमति वाले हैं और कौन से आंतरिक हैं।
🔒 सुरक्षा पर विचार करना
सुरक्षा को बाद में ध्यान में लाना नहीं है; इसे कार्यक्षमता के साथ मॉडल किया जाना चाहिए। 🔐 डेटा प्रवाह आरेख डिज़ाइन चरण के शुरुआती बिंदु पर सुरक्षा जोखिमों की पहचान करने का एक अद्वितीय अवसर प्रदान करते हैं।
- प्रमाणीकरण बिंदु:वह स्थान चिह्नित करें जहां उपयोगकर्ता प्रमाणपत्रों की पुष्टि की जाती है। आमतौर पर यह एक बाहरी एकाधिकार और प्रथम प्रक्रिया के सीमा के बीच होता है।
- डेटा एन्क्रिप्शन:वह स्थान चिह्नित करें जहां संवेदनशील डेटा प्रवाह को एन्क्रिप्ट किया जाता है। तीर पर “एन्क्रिप्टेड चैनल” जैसे लेबल का उपयोग करें।
- पहुंच नियंत्रण:दिखाएं कि कौन सी प्रक्रियाओं को विशिष्ट डेटा स्टोर को एक्सेस करने की अनुमति है।
- लॉगिंग:विशेष लॉग स्टोर में ऑडिट लॉग भेजने वाले प्रवाहों को शामिल करें। इससे ट्रेसेबिलिटी सुनिश्चित होती है।
इन सुरक्षा प्रवाहों को स्पष्ट रूप से मॉडल करके टीमें यह सुनिश्चित कर सकती हैं कि इंप्लीमेंटेशन के दौरान एन्क्रिप्शन और प्रमाणीकरण को भूला नहीं जाता है। इससे डेटा गोपनीयता और सुसंगतता आवश्यकताओं के बारे में चर्चा करने के लिए मजबूर किया जाता है।
🔄 रखरखाव और विकास
प्रणालियां विकसित होती हैं। आवश्यकताएं बदलती हैं, और नए सेवाओं को जोड़ा जाता है। एक डीएफडी एक जीवंत दस्तावेज है जिसे उपयोगी बनाए रखने के लिए रखरखाव किया जाना चाहिए। 🔄
- नियमित समीक्षाएं:विकास टीम के साथ डीएफडी की नियमित समीक्षा की योजना बनाएं ताकि वे वर्तमान कोडबेस के अनुरूप हों।
- परिवर्तन प्रबंधन:जब कोई नया फीचर जोड़ा जाता है, तो तुरंत आरेख को अपडेट करें। अगले दस्तावेजीकरण स्प्रिंट तक इंतजार न करें।
- निर्भरता ट्रैकिंग:आरेख का उपयोग निर्भरताओं को ट्रैक करने के लिए करें। यदि एक डेटा स्टोर को हटा दिया जाता है, तो डीएफडी यह दिखाएगा कि कौन सी प्रक्रियाएं टूटेंगी।
वास्तविकता को दर्शाने वाला दस्तावेज़ तकनीकी ऋण बनाता है। डीएफडी को अपडेट रखने से नए इंजीनियरों के ऑनबोर्डिंग समय में कमी आती है और आर्किटेक्चर ड्रिफ्ट को रोका जा सकता है।
🛠️ कार्यान्वयन रणनीति
एक जटिल प्रणाली के मॉडलिंग की वास्तविक शुरुआत कैसे करें? पूर्णता सुनिश्चित करने के लिए एक संरचित दृष्टिकोण का पालन करें। 📋
- एंटिटी की पहचान करें:सभी उपयोगकर्ताओं, बाहरी प्रणालियों और उपकरणों की सूची बनाएं जो प्रणाली के साथ बातचीत करते हैं।
- सीमाओं को परिभाषित करें:प्रणाली की सीमा रेखा स्पष्ट रूप से खींचें। अंदर का सब कुछ प्रणाली है; बाहर का सब कुछ बाहरी है।
- उच्च स्तरीय प्रवाहों को मैप करें:पहले संदर्भ आरेख बनाएं। सुनिश्चित करें कि सभी इनपुट और आउटपुट को ध्यान में रखा गया है।
- प्रक्रियाओं को विभाजित करें:मुख्य प्रक्रिया को उप-प्रक्रियाओं में विभाजित करें। उन्हें क्रियाओं के साथ लेबल करें।
- डेटा स्टोर जोड़ें:वह स्थान पहचानें जहां डेटा को स्थायी रूप से संग्रहित किया जाना चाहिए। उन्हें संबंधित प्रक्रियाओं से जोड़ें।
- सत्यापित करें:काले छेद और धूमिल छेद की जांच करें। सुनिश्चित करें कि प्रत्येक प्रवाह का एक स्रोत और एक गंतव्य है।
- सुधारें:वितरित परिस्थितियों के लिए प्रोटोकॉल, एन्क्रिप्शन और नेटवर्क सीमाओं के बारे में विवरण जोड़ें।
इस चरणबद्ध प्रक्रिया से यह सुनिश्चित होता है कि कोड लिखे जाने से पहले मॉडल मजबूत हो। यह तार्किक त्रुटियों को जल्दी पकड़कर समय बचाती है।
🚀 निष्कर्ष
डेटा प्रवाह आरेख वितरित प्रणालियों को डिज़ाइन करने के लिए एक मूल उपकरण हैं। वे जटिल नेटवर्कों में डेटा के आवागमन को समझने के लिए आवश्यक स्पष्टता प्रदान करते हैं। सर्वोत्तम प्रथाओं का पालन करने, सामान्य त्रुटियों से बचने और आरेखों को समय के साथ बनाए रखने से टीमें स्केलेबल, सुरक्षित और विश्वसनीय प्रणालियां बना सकती हैं। 🌟
मॉडलिंग में निवेश की गई मेहनत विकास और रखरखाव के दौरान लाभ देती है। स्पष्ट आरेख डेवलपर्स, स्टेकहोल्डर्स और ऑपरेशन्स टीमों के बीच बेहतर संचार को सुविधा प्रदान करते हैं। वे प्रणाली की वास्तुकला के लिए एकमात्र सत्य स्रोत के रूप में कार्य करते हैं।
आज ही अपनी वितरित प्रणालियों का मानचित्र बनाना शुरू करें। स्पष्टता, सुसंगतता और सटीकता पर ध्यान केंद्रित करें। जब वास्तुकला को स्केल करने की आवश्यकता हो या नए सदस्यों को टीम में शामिल करने की आवश्यकता हो, तो आपका भविष्य का आप आपको धन्यवाद देगा। 🏁