











🏗️ ऑब्जेक्ट-ओरिएंटेड एनालिसिस की नींव
ऑब्जेक्ट-ओरिएंटेड एनालिसिस और डिज़ाइन (OOA&D) के क्षेत्र में, सिस्टम मॉडल की सटीकता प्रारंभिक चरणों में पहचाने गए एंटिटीज की गुणवत्ता पर निर्भर करती है। वास्तविक दुनिया की एंटिटीज सॉफ्टवेयर समाधान के मुख्य निर्माण तत्वों का प्रतिनिधित्व करती हैं। वे वस्तुएँ हैं जो क्षेत्र में राज्य, व्यवहार और संबंधों को ले जाती हैं। जब इन एंटिटीज को सही तरीके से परिभाषित किया जाता है, तो परिणामस्वरूप आर्किटेक्चर टिकाऊ, रखरखाव योग्य और व्यापार संचालन के साथ संरेखित होता है। विपरीत रूप से, एंटिटीज को गलत तरीके से पहचानने से जटिल कपलिंग, अतिरिक्त डेटा संरचनाएँ और एक सिस्टम बन सकता है जो बदलती हुई आवश्यकताओं के अनुकूल होने में कठिनाई महसूस करता है।
प्रभावी मॉडलिंग के लिए डेटा को अलग-अलग टेबल या चर के रूप में देखने के बजाय व्यापार प्रक्रिया में सक्रिय भागीदार के रूप में देखने की आवश्यकता होती है। लक्ष्य अनावश्यक जटिलता के बिना क्षेत्र की आत्मा को पकड़ना है। इस प्रक्रिया में आवश्यकताओं का विस्तृत विश्लेषण करना, विषय विशेषज्ञों से जुड़ना और गुणवत्तापूर्ण विश्लेषणात्मक तकनीकों का उपयोग करना शामिल है ताकि महत्वपूर्ण एंटिटीज, मूल्य वस्तुओं और अस्थायी लक्षणों के बीच अंतर किया जा सके।
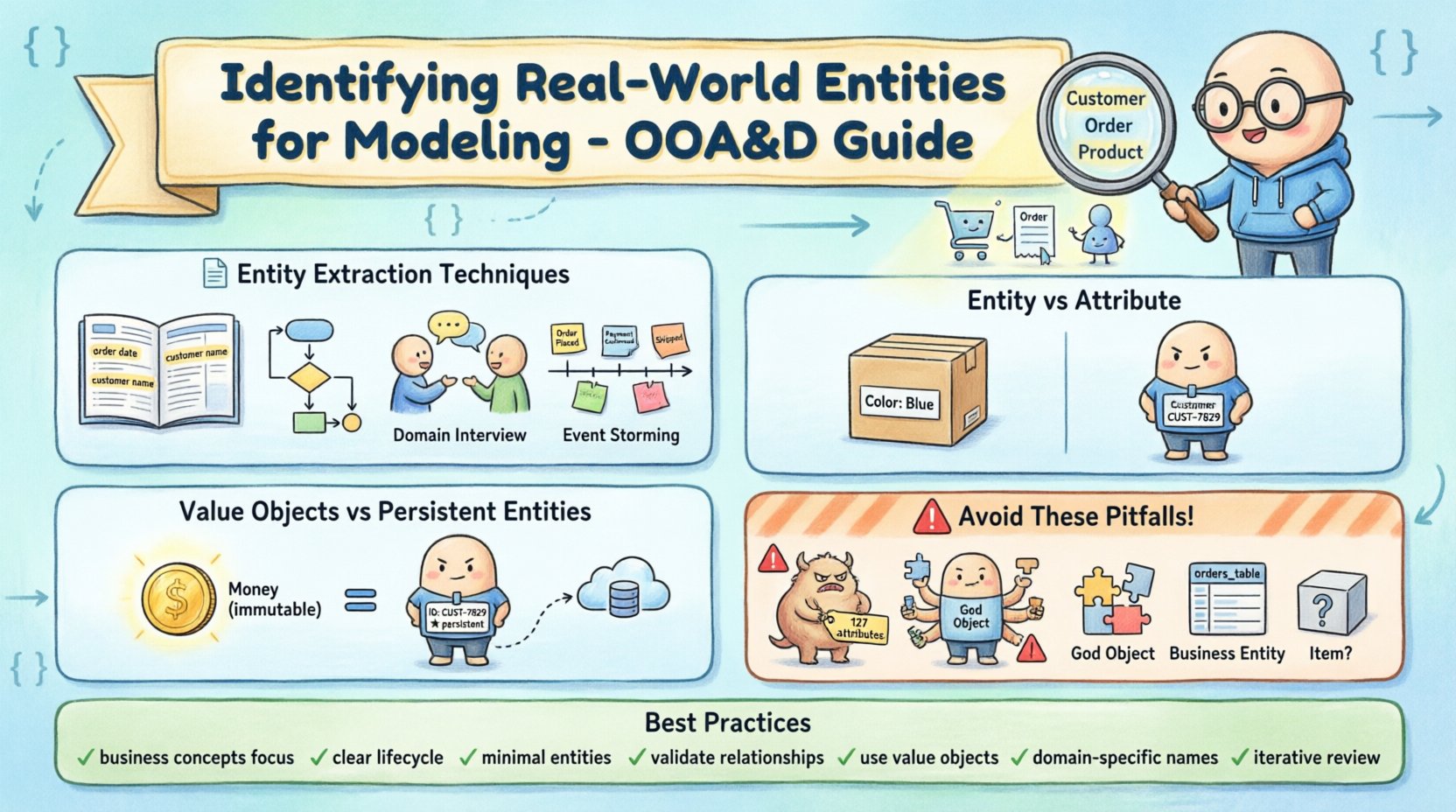
📝 एंटिटी निकास के तरीके
कच्ची जानकारी से संभावित एंटिटीज को निकालने के लिए कई सिद्ध तरीके मौजूद हैं। इन तकनीकों में अस्पष्ट व्यापार आवश्यकताओं को ठोस मॉडलिंग उम्मीदवारों में बदलने में मदद मिलती है।
- संज्ञा वाक्यांश विश्लेषण: सबसे आम दृष्टिकोण में आवश्यकता दस्तावेजों और उपयोगकर्ता कहानियों को पढ़ना शामिल होता है। विश्लेषक उन संज्ञाओं और संज्ञा वाक्यांशों को उजागर करते हैं जो अक्सर दिखाई देते हैं। उदाहरण के लिए, लॉजिस्टिक्स सिस्टम में, “पैकेज,” “ड्राइवर,” और “वेयरहाउस” प्राकृतिक रूप से उभरते हैं। हालांकि, हर संज्ञा एक एंटिटी नहीं होती है। शब्द जैसे “हैंडलिंग” या “शिपिंग” अक्सर क्रियाओं या संबंधों का वर्णन करते हैं, बल्कि स्वतंत्र वस्तुओं का नहीं।
- उपयोग केस परिदृश्य: उपयोग केस का विश्लेषण डेटा के उपयोग के तरीके के संदर्भ को प्रदान करता है। यदि उपयोगकर्ता किसी विशिष्ट वस्तु के साथ बहुत सारे परिदृश्यों में बातचीत करता है, तो वह एक मजबूत एंटिटी उम्मीदवार है। उदाहरण के लिए, यदि उपयोगकर्ता लॉग इन करता है, डैशबोर्ड देखता है और प्रोफाइल संपादित करता है, तो “उपयोगकर्ता” वस्तु सिस्टम के केंद्र में है।
- क्षेत्र ज्ञान के साक्षात्कार: स्टेकहोल्डर्स से बातचीत करने से उनके दैनिक रूप से उपयोग किए जाने वाले शब्दावली का पता चलता है। इससे एंटिटीज की पहचान करने में मदद मिलती है जो तकनीकी विवरणों में स्पष्ट रूप से नहीं लिखी गई हों, लेकिन व्यापार तर्क के लिए महत्वपूर्ण हों। स्टेकहोल्डर्स अक्सर तकनीकी पहचानकर्ता के बजाय वस्तुओं के कार्यात्मक नामों से संदर्भित करते हैं।
- इवेंट स्टॉर्मिंग: यह सहयोगात्मक तकनीक एक समय रेखा पर व्यापार घटनाओं को नक्शा बनाने में शामिल होती है। प्रत्येक घटना अक्सर एक एंटिटी के अस्तित्व को संकेत करती है जिसने उसे उत्पन्न किया या जिसे उसका प्रभाव पड़ा। इस दृश्यात्मक दृष्टिकोण से ऐसे संबंधों को उजागर करने में मदद मिलती है जो पाठ-आधारित विश्लेषण द्वारा छूट सकते हैं।
🔍 एंटिटीज और लक्षणों में अंतर करना
मॉडलिंग में एक सामान्य चुनौती यह निर्धारित करना है कि किसी अवधारणा को स्वतंत्र एंटिटी के रूप में या किसी अन्य एंटिटी के एक लक्षण के रूप में लिया जाना चाहिए। यह निर्णय मॉडल की विस्तृतता और प्रश्नों की जटिलता को प्रभावित करता है।
एक लक्षण किसी एंटिटी के गुण का वर्णन करता है। इसका अक्सर अपना कोई पहचान नहीं होता है। उदाहरण के लिए, एक “रंग” लक्षण एक “उत्पाद” एकतत्व उत्पाद के दिखावट का वर्णन करता है। यह उत्पाद के बाहर स्वतंत्र रूप से अस्तित्व में नहीं होता है।
हालांकि, एक एकतत्व का अपना पहचान और जीवनचक्र होता है। कुछ संदर्भों में, यह किसी विशिष्ट मातृ उदाहरण से जुड़े बिना भी अस्तित्व में रह सकता है, और यह अक्सर अपने स्वयं के संबंधों के साथ होता है। निम्नलिखित के बीच अंतर पर विचार करें:“पता” और “शहर”। कुछ मॉडलों में, “पता” एक जटिल गुण है जिसमें शामिल है “सड़क”, “शहर”, और “पिन कोड”। दूसरों में, “शहर” एक अलग एकतत्व है जिसमें गुण हैं जैसे “जनसंख्या” और “क्षेत्र”, बहुत से “पता” रिकॉर्ड से जुड़ा हुआ है।
| मापदंड | गुण | एकतत्व |
|---|---|---|
| पहचान | कोई अद्वितीय पहचानकर्ता नहीं | अद्वितीय पहचानकर्ता है |
| जटिलता | सरल डेटा प्रकार (स्ट्रिंग, नंबर) | कई विशेषताओं और व्यवहारों को धारण कर सकता है |
| पुनर्उपयोगिता | केवल एक संदर्भ के भीतर उपयोग किया जाता है | कई संदर्भों के बीच साझा किया जा सकता है |
| जीवनचक्र | केवल तब तक अस्तित्व में रहता है जब तक मूल वस्तु अस्तित्व में है | स्वतंत्र जीवनचक्र है |
💎 मूल्य वस्तुएँ बनाम स्थायी संस्थान
सभी संस्थानों को डेटाबेस में स्थायित्व की आवश्यकता नहीं होती है। प्रदर्शन और संरचनात्मक अखंडता के लिए मूल्य वस्तुओं और स्थायी संस्थानों के बीच अंतर करना महत्वपूर्ण है।
मूल्य वस्तुएँ वे वस्तुएँ हैं जो विशेषताओं को परिभाषित करती हैं लेकिन एक अलग पहचान नहीं रखती हैं। उनकी विशेषताओं द्वारा परिभाषित किया जाता है। यदि आप एक विशेषता बदलते हैं, तो वस्तु को अलग माना जाता है। एक प्रामाणिक उदाहरण है “धन”। समान मूल्य और मुद्रा वाली दो धन वस्तुओं को समान माना जाता है। किसी विशिष्ट डॉलर राशि के लिए एक अद्वितीय ID की आवश्यकता नहीं होती है।
स्थायी संस्थान अन्य उदाहरणों से अलग करने के लिए एक अद्वितीय पहचानकर्ता की आवश्यकता होती है, भले ही उनकी विशेषताएँ समान हों। एक “ग्राहक” संस्थान, उदाहरण के लिए, को ग्राहक ID होना चाहिए। दो ग्राहकों का नाम और पता समान हो सकता है, लेकिन वे अलग-अलग लोग हैं।
मूल्य वस्तुओं का उपयोग अनावश्यक डेटाबेस ओवरहेड को हटाकर क्षेत्र मॉडल में जटिलता को कम करता है। यह मॉडल को केवल वहाँ पहचान पर ध्यान केंद्रित करने की अनुमति देता है जहाँ वास्तव में आवश्यकता हो।
⚠️ सामान्य मॉडलिंग त्रुटियाँ
यहाँ तक कि अनुभवी विश्लेषक भी पहचान चरण के दौरान जाल में फंस सकते हैं। इन त्रुटियों को पहचानने से मॉडल को बेहतर बनाने में मदद मिलती है।
- अतिमॉडलिंग: ऐसी अवधारणाओं के लिए संस्थान बनाना जो दुर्लभ रूप से उपयोग की जाती हैं या महत्वपूर्ण मूल्य नहीं जोड़ती हैं। इससे एक भारी मॉडल बनता है जिसे नेविगेट करना मुश्किल होता है।
- अपरिमाणित मॉडलिंग: बहुत सारी अवधारणाओं को एक ही संस्थान में समूहित करना। इससे अक्सर “देवता वस्तुएँ” बनती हैं जिन्हें बनाए रखना मुश्किल होता है और एकल उत्तरदायित्व सिद्धांत का उल्लंघन करती हैं।
- संबंधों को नजरअंदाज करना: केवल वस्तुओं पर ध्यान केंद्रित करना बिना इसके परिभाषित किए कि वे कैसे बातचीत करती हैं। संबंधों के बिना कोई संस्थान अलग होता है और आमतौर पर एक जुड़े हुए प्रणाली में बेकार होता है।
- तकनीकी पक्ष: व्यवसाय अवधारणाओं के बजाय डेटाबेस तालिका नामों या प्रोग्रामिंग सीमाओं के आधार पर संस्थानों के नामकरण। मॉडल को क्षेत्र का प्रतिबिंब दिखाना चाहिए, न कि बुनियादी ढांचे का।
- बहुत जल्दी सारांश बनाना: सामान्य एंटिटीज बनाना जैसे “आइटम” या “ऑब्जेक्ट” विशिष्ट आवश्यकताओं को समझने से पहले। विशिष्टता अक्सर आवश्यक विवरणों को उजागर करती है जो सामान्य मॉडल्स छिपाते हैं।
🔄 सत्यापन और सुधार प्रक्रिया
पहचान एकमात्र घटना नहीं है। यह एक आवर्ती प्रक्रिया है जिसमें व्यापार की वास्तविकता के खिलाफ निरंतर सत्यापन की आवश्यकता होती है।
1. स्टेकहोल्डर्स के साथ वॉकथ्रू
मूल मॉडल को डोमेन विशेषज्ञों को प्रस्तुत करें। उनसे पूछें कि क्या एंटिटीज उनकी वास्तविकता का प्रतिनिधित्व करती हैं। क्या वे संबंधों को पहचानते हैं? कोई महत्वपूर्ण ऑब्जेक्ट गायब है? इस फीडबैक लूप सुनिश्चित करता है कि मॉडल व्यापार की आवश्यकताओं में जड़ा हुआ रहे।
2. परिदृश्य परीक्षण
मॉडल के माध्यम से विशिष्ट व्यापार परिदृश्य चलाएं। यदि उपयोगकर्ता को कई एंटिटीज को शामिल करने वाली रिपोर्ट बनाने की आवश्यकता है, तो जांचें कि क्या संबंध इस प्रश्न को कुशलतापूर्वक समर्थन करते हैं। यदि मॉडल को जटिल जॉइन्स या कार्यवाही की आवश्यकता है, तो एंटिटी संरचना में समायोजन की आवश्यकता हो सकती है।
3. सुसंगतता जांच
सुनिश्चित करें कि नामकरण प्रणाली सुसंगत हो। यदि आप एक खंड में “उपयोगकर्ता” का उपयोग करते हैं और दूसरे खंड में “ग्राहक”एक ही अवधारणा के लिए, तो भ्रम पैदा होगा। पूरे डोमेन मॉडल में शब्दावली को मानकीकृत करें।
4. सीमा पहचान
प्रणाली की सीमाओं को परिभाषित करें। कुछ एंटिटीज सॉफ्टवेयर प्रणाली के बाहर होती हैं लेकिन इसके साथ बातचीत करती हैं। इन्हें बाहरी एंटिटीज कहा जाता है। आंतरिक और बाहरी एंटिटीज के बीच अंतर करना निर्भरताओं और एकीकरण बिंदुओं को प्रबंधित करने में मदद करता है।
📊 बेस्ट प्रैक्टिसेज का सारांश
उच्च गुणवत्ता वाले मॉडलिंग सुनिश्चित करने के लिए, पहचान चरण के दौरान निम्नलिखित चेकलिस्ट का पालन करें।
- ✅ तकनीकी कार्यान्वयन के बजाय व्यापार अवधारणाओं पर ध्यान केंद्रित करें।
- ✅ सुनिश्चित करें कि प्रत्येक एंटिटी का स्पष्ट उद्देश्य और जीवनचक्र हो।
- ✅ जटिलता को कम करने के लिए एंटिटीज की संख्या को न्यूनतम करें।
- ✅ विशेषताओं को अंतिम रूप देने से पहले संबंधों की पुष्टि करें।
- ✅ पहचान रहित डेटा प्रकारों के लिए मूल्य वस्तुओं का उपयोग करें।
- ✅ नामों को वर्णनात्मक और डोमेन-विशिष्ट रखें।
- ✅ आवश्यकताओं के विकास के साथ मॉडल की आवर्ती समीक्षा करें।
🚀 सटीक मॉडलिंग का प्रभाव
वास्तविक दुनिया की एंटिटीज की सटीक पहचान में निवेश की गई मेहनत सॉफ्टवेयर जीवनचक्र के दौरान लाभ देती है। एक सटीक मॉडल बाद में रीफैक्टरिंग की आवश्यकता को कम करता है। यह डेवलपर्स और व्यापार स्टेकहोल्डर्स के बीच संचार को स्पष्ट करता है। यह डेटाबेस डिजाइन, API परिभाषा और उपयोगकर्ता इंटरफेस संरचना को मार्गदर्शन करने वाला ब्लूप्रिंट के रूप में कार्य करता है।
जब एंटिटीज को सही तरीके से मॉडल किया जाता है, तो सिस्टम अधिक लचीला बन जाता है। नए फीचर्स जोड़ने के लिए अक्सर मौजूदा एंटिटीज को बदलना आवश्यक होता है, पूरे फाउंडेशन को फिर से बनाने के बजाय। इस स्थिरता के कारण संगठन को तकनीकी देने के बिना बाजार में बदलावों के प्रति प्रतिक्रिया करने में सक्षम होता है।
अंततः, लक्ष्य व्यापार की सच्चाई को दर्शाने वाले एक जीवित मॉडल को बनाना है। इसके लिए धैर्य, गहन समझ और स्पष्टता के प्रति प्रतिबद्धता की आवश्यकता होती है। त्वरित रास्तों से बचकर और कठोर विश्लेषण तकनीकों का पालन करके, परिणामस्वरूप सिस्टम समय और बदलाव की परीक्षा में खड़ा रहेगा।
🔗 मॉडलिंग यात्रा में अगले चरण
जब एंटिटीज की पहचान कर ली जाती है, तो ध्यान उनके व्यवहार और संबंधों को परिभाषित करने की ओर बदल जाता है। इसमें राज्य आरेख, क्रम आरेख और क्लास आरेख बनाना शामिल होता है। यहाँ पहचानी गई एंटिटीज इन व्यापक आरेखों में नोड्स के रूप में कार्य करती हैं। आगे बढ़ने से पहले उन्हें मजबूत बनाने से डिज़ाइन चरण में जाने वाली गलतियों के श्रृंखलाबद्ध होने से बचा जा सकता है।
निरंतर सीखना और अनुकूलन आवश्यक है। जैसे-जैसे व्यापार क्षेत्र विकसित होता है, मॉडल को उसके साथ विकसित होना चाहिए। नियमित समीक्षाएँ पहचान प्रक्रिया को संबंधित और प्रभावी बनाए रखती हैं। इस गतिशील दृष्टिकोण से यह सुनिश्चित होता है कि सॉफ्टवेयर समाधान संगठन के लक्ष्यों के साथ समान रहे।