











システムアーキテクチャおよびセキュリティ工学の分野において、データの移動を可視化することは単なる設計作業ではなく、根本的なセキュリティ実践である。データフローダイアグラム(DFD)は、システム内を移動する情報のマップとして機能する。リスク分析に適切に活用された場合、このマップは本番環境に問題が発生する前に脆弱性を特定するための重要なツールとなる。本ガイドでは、リスク特定および軽減戦略をDFD作成プロセスに直接統合するための手法を詳述する。
セキュリティは追加機能ではなく、設計そのものに内在する性質である。外部エンティティ、プロセス、データストア間をデータがどのように移動するかを検証することで、信頼境界が越えられている場所、機密情報が露出している場所、制御が欠落している場所を特定できる。以下のセクションでは、このアプローチのメカニズムを、基礎概念から実践的応用まで探求する。
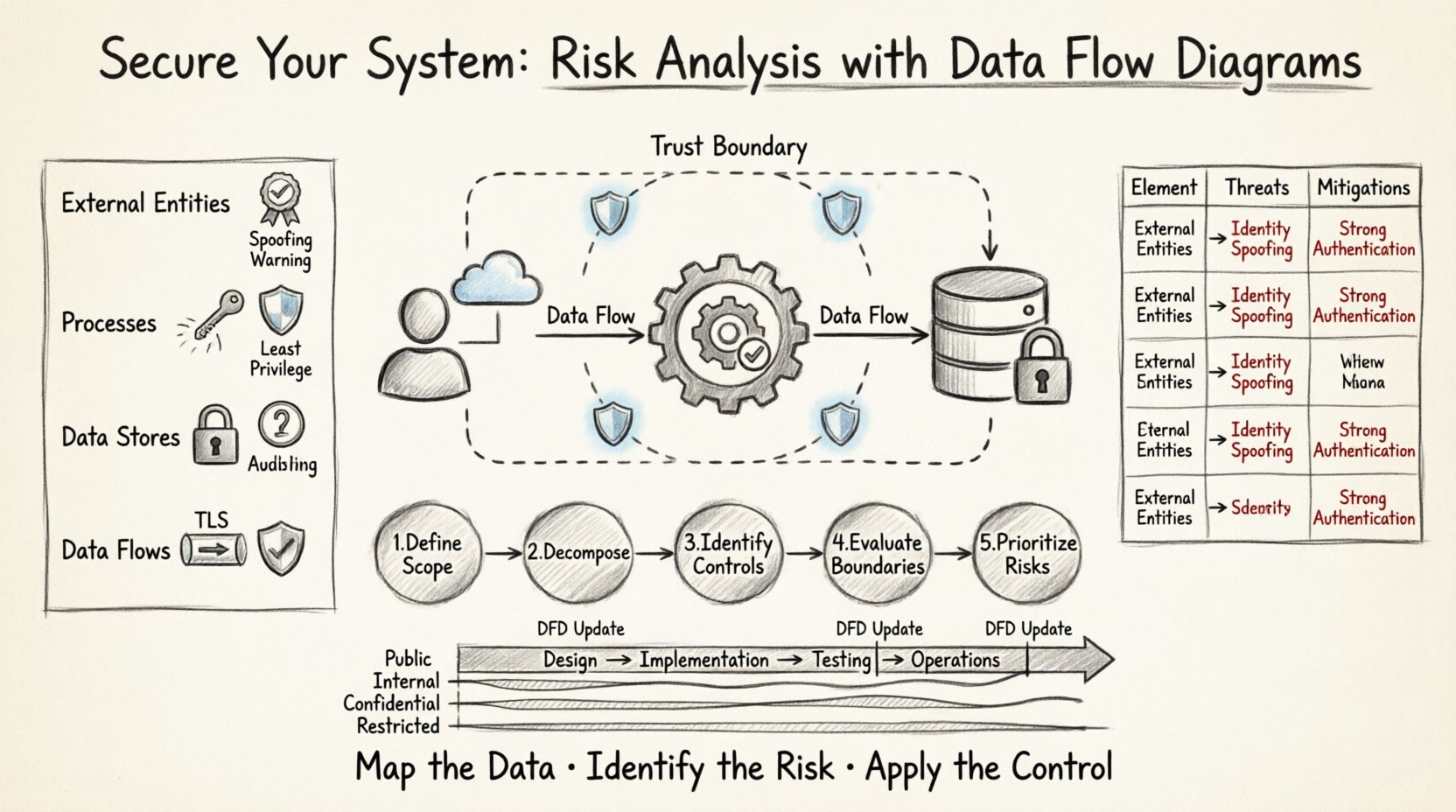
🧩 データフローダイアグラムの核心要素の理解
リスクを分析する前に、分析対象となる構成要素を理解する必要がある。DFDは4つの主要な要素で構成される。各要素には、レビュー過程で評価しなければならない特定のセキュリティ上の意味合いが伴う。
- 外部エンティティ: これらはシステム境界外のデータの発信元または受信先を表す。ユーザー、他のシステム、第三者サービスなどが例である。 セキュリティ上の影響: エンティティはしばしばなりすまし攻撃や不正アクセス試行の発信源となる。内部プロセスとやり取りする前に、すべてのエンティティは認証および承認が必要である。
- プロセス: これらはデータに対して機能または変換を行うものである。入力データを出力データに変換する。 セキュリティ上の影響: プロセスは論理エラーが発生する場所である。プロセスが入力を検証しなければ、インジェクション攻撃や論理バイパスが発生する可能性がある。各プロセスの実行コンテキストに最小権限の原則が適用されていることを確認することは不可欠である。
- データストア: これらはデータが静止状態で保持される場所を表す。データベース、ファイル、メモリバッファなどが含まれる。 セキュリティ上の影響: データストアは情報漏洩の主な標的となる。アクセス制御、静止状態での暗号化、整合性チェックはここでは必須である。
- データフロー: これらは他の3つの要素間をデータが移動する経路を表す。 セキュリティ上の影響: フローはネットワークまたはプロセス間通信チャネルを表す。送信中のデータは必ず暗号化されなければならない。攻撃者が横方向に移動するのを検出するためには、不正なフローの監視が不可欠である。
🔍 DFDと脅威モデリングの交差点
リスク分析をDFDに統合するには、構造的なアプローチが必要である。これはしばしば「データフローダイアグラムを用いた脅威モデリング」と呼ばれる。目的は、各要素およびフローに関連する潜在的な脅威を特定し、適切な緩和策を決定することである。
この分析を実施する際、焦点は「システムはどのように動作するか?」から「システムはどのように攻撃されるか?」へと移行する。この視点の変化により、チームは穴を後から補う反応的対応ではなく、事前に制御を設計する能動的なアプローチを取ることができる。
DFDリスク分析の主な目的
- 資産の特定: どのデータ要素が機密性が高いかを特定する。すべてのデータが同じレベルの保護を必要とするわけではない。
- 信頼境界の定義: システム境界が終了し、外部環境が始まる場所を明確にマークする。これらの境界を越えると信頼レベルが変化する。
- 脅威の列挙: 図面の要素に適用可能な具体的な脅威をリストアップする。
- コントロールマッピング: 識別された脅威を軽減するために、セキュリティコントロールを特定の図面要素に割り当てる。
📉 DFDレベル別リスク分析
データフローダイアグラムは通常、高レベルのコンテキストから詳細なプロセス論理へと段階的に作成される。各レベルは、リスクに関する異なる粒度の洞察を提供する。
コンテキスト図(レベル0)
これは最も高いレベルの視点である。システムを外部エンティティと相互作用する単一のプロセスとして示している。
- リスクの焦点:ネットワーク境界のセキュリティと高レベルのアクセス制御。
- 分析:すべての外部接続を特定する。直接のインターネット接続があるか?新しい設計とインターフェースするレガシーシステムは存在するか?このレベルでの高レベルのリスクには、主な通信チャネルにおけるミドルマン攻撃が含まれる。
レベル1 DFD
主要プロセスがサブプロセスに分解される。データストアとデータフローが可視化される。
- リスクの焦点:内部データ処理とプロセスの隔離。
- 分析:セキュリティチェックを回避するフローを検索する。たとえば、信頼できないエンティティから、検証プロセスを経ずに機密データストアへデータが直接流れているか?このレベルでは、認証フローにおける論理的な穴がよく明らかになる。
レベル2 DFD(およびそれ以上)
サブプロセスがさらに詳細化される。このレベルは、特定のモジュール分析にしばしば使用される。
- リスクの焦点:データ検証、暗号化の実装、エラー処理。
- 分析:特定のアルゴリズムやデータ変換を検証する。暗号化操作が明示的に示されているか?エラーメッセージが情報漏洩を引き起こすような方法でログ記録されているか?このレベルは、コードレベルのセキュリティレビューにおいて極めて重要である。
📋 リスクマトリクス:要素と脅威のマッピング
以下の表は、特定のDFD要素に関連する一般的なリスクを要約したものである。このマトリクスは、設計レビュー段階でのチェックリストとして機能する。
| DFD要素 | 一般的な脅威 | 緩和戦略 |
|---|---|---|
| 外部エンティティ |
|
|
| プロセス |
|
|
| データストア |
|
|
| データフロー |
|
|
🛠️ リスク分析のためのステップバイステッププロセス
この分析を実施するには、厳密なワークフローが必要です。以下のステップは、DFDを用いた包括的なリスクレビューの手順を示しています。
ステップ1:範囲と境界の定義
まず、コンテキスト図を描き始めましょう。システムの内部と外部を明確に定義してください。この境界が信頼の境界です。この線を越えるすべてのデータは、検証が必要です。各外部エンティティに割り当てられた信頼レベルを記録してください。エンティティは完全に信頼できるか、部分的に信頼できるか、信頼できないかはどのようになりますか?
ステップ2:システムの分解
レベル1およびレベル2の図を作成してください。メインプロセスを分解する際には、すべてのデータフローが転送中のデータの種類でラベル付けされていることを確認してください。たとえば、「支払いデータ」ではなく「クレジットカード番号」とラベルを付けるようにしてください。具体的なラベル付けにより、リスクの分類がより正確になります。
ステップ3:セキュリティコントロールの特定
リスクマトリクスに基づいて、図の各要素を確認してください。各コンポーネントに対して以下の質問をします:
- このコンポーネントは機密データを扱いますか?
- 認証メカニズムが導入されていますか?
- データは転送中に暗号化されていますか?
- 監査目的でログが生成されていますか?
ステップ4:信頼境界の評価
図上にすべての信頼境界をマークしてください。信頼境界とは、信頼のレベルが変化する場所です。たとえば、パブリックなWebサーバーと内部データベースの間に境界が存在します。この境界を越えることは、最もリスクの高いポイントです。すべての境界越えポイントに、ファイアウォールルール、APIゲートウェイ、または暗号化トンネルなどの特定のセキュリティコントロールが設けられていることを確認してください。
ステップ5:リスクの文書化と優先順位付け
特定されたリスクをすべてリストアップしてください。深刻度評価システム(例:低、中、高、深刻)を使用してください。リスクの優先順位は、攻撃の可能性と、リスクが実現した場合のビジネスへの影響の2つの要因に基づいて決定してください。高影響度のリスクは、デプロイ前に対処する必要があります。
🚧 DFDセキュリティ分析における一般的な落とし穴
経験豊富なアーキテクトですら、重要な詳細を見落とすことがあります。一般的なミスに気づいておくことで、堅固なセキュリティ体制を確保できます。
- ゴーストフロー:すべてのデータフローに明確な送信元と受信先があることを確認してください。どこからも来ず、どこにも行かないフローは、論理の欠落や孤立したデータ処理を示していることが多いです。このようなギャップは攻撃者によって悪用される可能性があります。
- 静止中のデータを無視する:転送中のデータにのみ注目する。多くの侵害事例は、データベースに保存されたデータが暗号化されていない、または過度に許容的なクエリによってアクセス可能であることが原因です。
- 認証を無視する:フローが存在するからといって、それが安全であると仮定する。データフローが存在するからといって、セキュリティが保証されるわけではありません。明示的な認証および承認プロセスは、プロセスまたはコントロールとしてモデル化する必要があります。
- バージョン管理の欠如:DFDはシステムの変更に伴って進化します。図が現在の実装と一致しない場合、リスク分析は無効になります。図のバージョン管理をコードのバージョンと併せて行うようにしてください。
- 一般的なラベル:データタイプを明示せずに「ユーザー情報」のような曖昧なラベルを使用する。特定のデータタイプは、特定の規制およびセキュリティ要件(例:PII、PHI、PCI-DSS)を引き起こします。
🔄 開発ライフサイクルへの統合
DFD分析が効果的であるためには、一度限りのイベントにしてはなりません。ソフトウェア開発ライフサイクル(SDLC)に統合される必要があります。
設計フェーズ
初期設計段階で、コンテキスト図およびレベル1図を作成してください。高レベルのリスク評価を実施します。これにより、基本的なセキュリティ上の欠陥がアーキテクチャに組み込まれるのを防げます。
実装フェーズ
開発者が機能を構築する際には、レベル2図を更新する必要があります。これにより、セキュリティモデルが最新の状態を保ちます。開発者は、図を使って、自身が記述しているデータフローに対して必要なコントロールが正しく実装されているかを確認できます。
テストフェーズ
セキュリティテスト担当者は、DFDを用いて侵入テストの計画を立てることができます。分析で特定された高リスクのデータフローおよび信頼境界に注目できます。これにより、テストがより効率的かつ的確になります。
運用フェーズ
運用中に図を維持してください。新しいサードパーティサービスが統合された場合は、図を更新してください。新しい統合が新たな攻撃ベクトルをもたらさないかを確認するために、リスク分析を再確認してください。
📈 分析の効果を測定する
DFDリスク分析が効果的に機能しているかどうかはどうやって知ることができますか?成熟したセキュリティ体制の兆候を以下に示します。
- 脆弱性数の削減:コードレビューおよび侵入テスト中に、セキュリティ上の問題が少なくなる。
- 迅速な是正: 問題が発見された場合、データフローが文書化されているため、問題の場所をより簡単に特定できる。
- コンプライアンスとの整合性: 図は、機密データが処理・保存される場所を示すことで、コンプライアンス要件(例:GDPR、HIPAA)と直接対応している。
- チームの意識: 開発者および関係者は、図がリスクを可視化しているため、設計選択のセキュリティ上の影響を理解している。
🛑 異常処理とレガシーシステムの対応
すべてのシステムがグリーンフィールドではない。多くの組織は、文書が欠落または不完全なレガシーシステムを分析しなければならない。
DFDのリバースエンジニアリング
図が存在しない場合は、コードまたは構成ファイルから図を作成しなければなりません。このプロセスはリバースエンジニアリングと呼ばれ、意図されたものではなく実際のデータフローを可視化できる。実際のフローと意図された設計との差異は、リスクが隠れる場所であることが多い。
技術的負債の管理
レガシーシステムには現代的なセキュリティ機能が欠けていることがある。これらのシステムを分析する際は、補償制御に注目する。コードレベルでの暗号化が不可能な場合、ネットワークレベルでの実装は可能か?認証が弱い場合、APIゲートウェイがレガシーアプリケーションの前にセキュリティ層を追加できるか?
🔗 データ分類の役割
リスクの特定はデータ分類と密接に結びついている。理解していないものを保護することはできない。データフローには分類レベルを明記しなければならない。
- 公開:オープンに共有できる情報。漏洩してもリスクは低い。
- 社内専用:社内でのみ使用する情報。漏洩した場合、中程度のリスク。
- 機密:機密性の高いビジネス情報または個人情報。漏洩した場合、高いリスク。
- 制限:厳格なアクセス制御を要する極めて機密性の高いデータ。漏洩した場合、重大なリスク。
DFDを分析する際には、機密または制限データを含むフローを明確な色で強調表示してください。この視覚的インジケーターにより、セキュリティチームは最も重要な経路に即座に注目できます。
🧭 メソドロジーに関する結論
リスク識別にデータフローダイアグラムを使用することで、セキュリティは反応型のチェックリストから予防的な設計原則へと変化します。データの流れを可視化することで、アーキテクチャ内に潜む見えない脅威をチームが把握できます。このプロセスには、自己管理、定期的な更新、システム構成要素に対する明確な理解が求められます。正しく実行されれば、既知および新興の脅威に対してシステムを保護するための明確なロードマップを提供します。
このアプローチの価値は明確さにあります。アーキテクトがデータの移動経路や脆弱な場所を現実に向き合うことを強制します。セキュリティに関する議論から曖昧さを排除します。システムの複雑性が増すにつれて、このような構造化された分析の必要性はさらに重要になります。正確な図面を維持し、リスク分析を厳密に適用することで、ソフトウェアのライフサイクル全体にわたりセキュリティがビジネス機能と整合した状態を保つことができます。
図面から始めましょう。データをマッピングします。リスクを特定します。対策を適用します。このサイクルにより、現代の脅威環境の圧力に耐えうるレジリエントなシステムが構築されます。