











現代のソフトウェアアーキテクチャにおいて、情報がどのように移動するかを理解することは、情報がどのように保存されるかを理解することと同じくらい重要です。データフローダイアグラム(DFD)は、この移動のための設計図であり、データが入力から出力へと移動するプロセスを可視化します。成長を想定したシステムを設計する際、これらの図は単なるスケッチから、パフォーマンス、信頼性、保守性を決定する複雑なマップへと進化します。本ガイドでは、スケーラブルな環境におけるデータフローをモデル化するために使用される基本的なパターンについて解説します。
スケーラビリティとは単にサーバーを追加することだけではなく、ボトルネックを回避するためにデータがシステム内をどのように移動するかを再構築することです。特定のDFDパターンを適用することで、アーキテクトは生産環境での問題になる前に、容量の限界を可視化できます。このアプローチにより、情報の論理的な流れが現在の要件と将来の拡張を両方サポートすることを保証します。
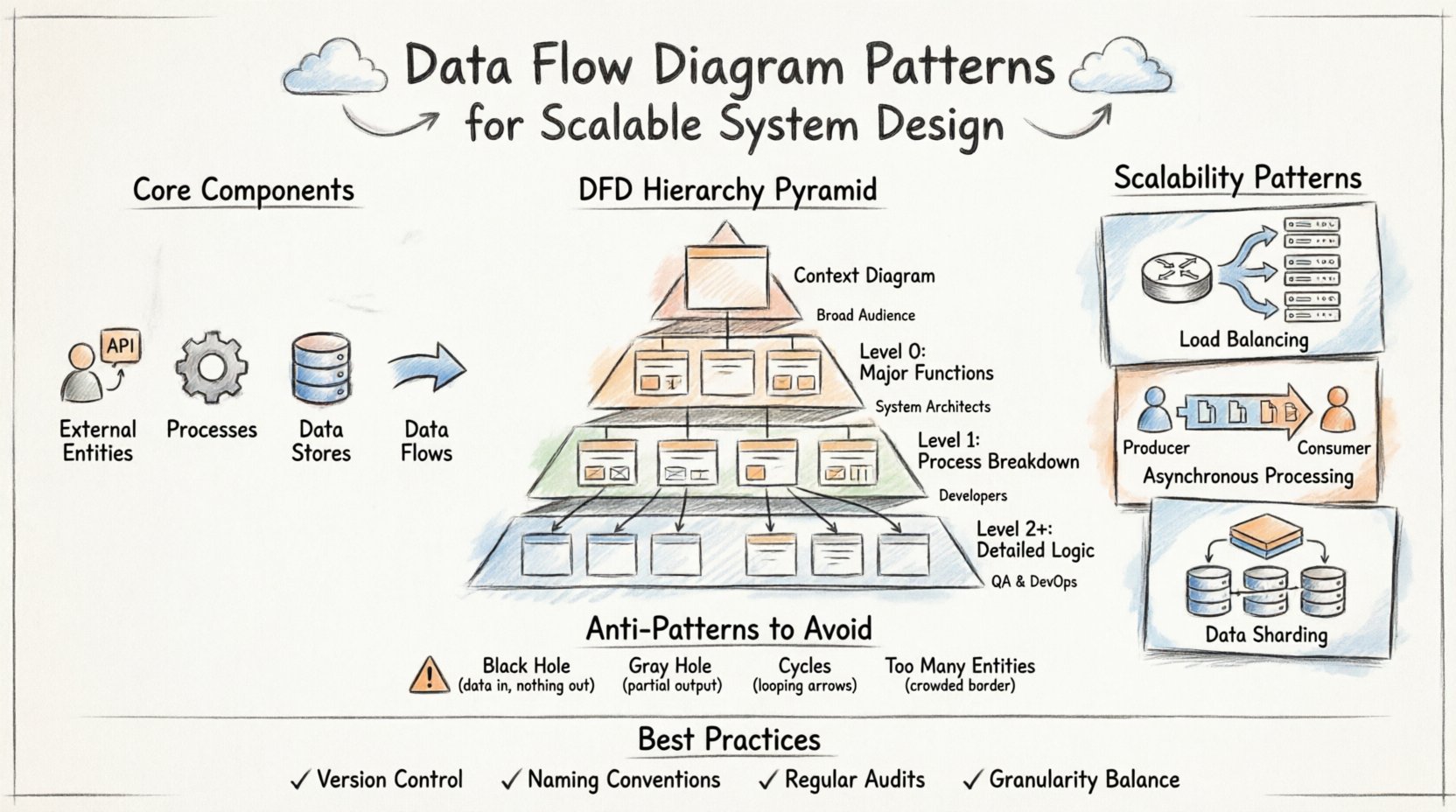
🧩 データフローダイアグラムのコアコンポーネント
パターンの詳細に入る前に、基本構成要素を習得する必要があります。すべてのDFDは4つの基本要素に依存しています。これらの要素を混同すると、開発を効果的に導くことができない曖昧なモデルが生まれます。
- 外部エンティティ:システム境界外の情報源または宛先を表します。ユーザー、サードパーティAPI、ハードウェアデバイスなどが含まれます。
- プロセス:データを一つの形式から別の形式に変換します。これらはシステム内のアクティブな計算処理やビジネスロジックのポイントです。
- データストア:データが静止している場所です。データベース、ファイルシステム、メモリキャッシュなどが含まれます。
- データフロー:エンティティ、プロセス、ストアの間をデータが通る経路です。矢印は方向と内容を示します。
各コンポーネントは曖昧さを防ぐために明確に定義されるべきです。たとえば、対応するデータフローが存在しない限り、プロセスが他のプロセスに矢印を向けることは決してありません。すべての矢印は、システム内を実際に移動している情報に対応しなければなりません。
📉 DFDのレベル構造
スケーラブルなシステムには、異なる抽象度のレベルが必要です。単一の図ではほとんど全体の複雑さを捉えることはできません。代わりに、高レベルのコンテキストから詳細な実装論理へと段階的に掘り下げる階層構造が用いられます。この構造により、チームは細部に迷うことなく全体像を把握できます。
| レベル | 注目点 | 複雑さ | 主な対象者 |
|---|---|---|---|
| コンテキスト図 | システム境界と外部との相互作用 | 低 | ステークホルダー、経営陣 |
| レベル0(DFD 0) | 主要なシステム機能とデータストア | 中 | システムアーキテクト |
| レベル1 | レベル0プロセスの分解 | 高 | 開発者、エンジニア |
| レベル2以上 | 特定のアルゴリズム的またはサブプロセス論理 | 非常に高い | 専門エンジニア |
これらのレベル間で一貫性を保つことは非常に重要です。レベル0で特定されたデータストアは、レベル1でも正しく参照されなければなりません。レベル1でプロセスが分割された場合、入力および出力のフローはレベル0の親プロセスと一致している必要があります。このバランスが、モデルがライフサイクル全体を通じて信頼できる参照源のままになることを保証します。
🚀 システムアーキテクチャにおけるスケーラビリティパターン
スケーラビリティを考慮した設計には、特定のモデリング選択が必要です。標準的な図はしばしば負荷処理メカニズムを隠蔽しています。スケーラビリティを対処するため、アーキテクトは作業を分散するかリソースを管理するパターンを明示的に表現しなければなりません。
1. ロードバランシングと配分
高トラフィックシステムでは、単一のプロセスではすべての受信要求を処理できません。DFDは配分メカニズムを反映しなければなりません。
- ルーターパターン: 複数のサービスノードにトラフィックを配信するプロセスノードを導入する。
- レプリケーション: 同じデータフローを受信する複数の同一プロセスを表示し、並列処理を行う。
- キューイング: 処理開始前にバッファとして機能するデータストアを表現し、ピークをなめらかにする。
ルーターを描画する際は、フローが論理的に分割されていることを確認してください。システムがラウンドロビン戦略を使用している場合、図は判断がデータコンテンツではなく負荷に基づいていることを示す必要があります。この違いは、バックエンドロジックの実装方法に影響を与えます。
2. 非同期処理
同期的なフローでは、1つのステップが別のステップを待つ場合、ボトルネックが生じる可能性があります。非同期パターンはプロセスを分離することで、システムが独立してスケーリングできるようにします。
- メッセージキュー: データストアをキューを表すために使用する。プロデューサーはストアに書き込み、コンシューマーは後に読み込む。
- イベントストリーム: 送信者をブロッキングせずに複数の下流コンシューマーをトリガーするイベントを発信するプロセスを表示する。
- バックグラウンドジョブ: 長時間実行するタスクをユーザー向けリクエストから分離し、専用のプロセスプールにルーティングする。
この分離により、ユーザー向けプロセスは軽量のままに保たれ、重い処理はバックグラウンドで行われます。DFDによりこの分離が可視化され、開発者が即時応答を想定するのを防ぎます。
3. データシャーディングとパーティショニング
データ量が増加するにつれて、単一のストレージユニットがパフォーマンスの障壁になります。DFDにおけるシャーディングパターンは、データが複数のストアにどのように分割されているかを可視化するのに役立ちます。
- 水平分割: ID やキーに基づいて、特定のデータサブセットを異なるデータストアにルーティングするプロセスを表示する。
- 読み取りレプリカ:書き込みがプライマリストアに送られる一方で、レプリカからデータを読み取るための別々のフローを示す。
- キャッシュレイヤー:プロセスとメインデータベースの間にキャッシュデータストアを挿入して遅延を低減する。
| パターン | スケーラビリティの利点 | トレードオフ |
|---|---|---|
| ロードバランシング | スループットを向上させる | 状態管理の複雑さが増す |
| 非同期キュー | 依存関係を分離する | 最終整合性 |
| シャーディング | ストレージ容量を拡張する | シャード間をまたぐ複雑なクエリ |
| キャッシュ | 遅延を低減する | データの古さのリスク |
⚠️ 避けるべき一般的なアンチパターン
良い意図を持っていても、DFDにはシステム障害を引き起こす構造上の欠陥が含まれることがある。これらのアンチパターンを早期に認識することで、後々の高コストな再設計を防ぐことができる。
1. ブラックホール
ブラックホールとは、プロセスがデータを受け取るが、出力を行わない状態を指す。これは、プロセスがデータを削除するものと仮定したり、静かに処理するものと想定している場合によく発生する。
- リスク:エラーメッセージの通知なしにデータが消失する。
- 修正:すべての入力に対して、対応する出力フロー、または明確なエラー経路を確保する。
- スケーラビリティへの影響:静黙的な障害は分散システムではデバッグが難しい。
2. グレイホール
グレイホールはブラックホールに似ているが、出力が部分的である。プロセスは生成するデータよりも多くのデータを消費するが、残りのデータがどこに行ったのかを説明しない。
- リスク:説明のつかないデータ消費は、ストレージの漏洩やトランザクションエラーを引き起こす。
- 修正:エラーログや監査トレースを含む、すべてのデータ経路を明示的にモデル化する。
3. データフローにおける循環
一部のフィードバックループ(例:リトライメカニズム)は必要だが、制御されていない循環は無限の処理ループを引き起こす可能性がある。
- リスク:システムの応答停止またはリソースの枯渇。
- 修正:図の再帰の深さを制限し、設計にタイムアウトメカニズムを実装する。
4. 無限の外部エンティティ
外部エンティティを多すぎると図が読みにくくなり、核心的な論理が見えにくくなる。
- リスク:システム境界の不明瞭化。
- 修正:適切な場面では、関連するエンティティを単一の「レコード管理システム」または「ユーザーインターフェース」エンティティにグループ化する。
🔄 メンテナンスと進化のためのベストプラクティス
DFDは一度限りの成果物ではない。システムが成長するにつれて進化しなければならない。モデルを正確に保つことで、新しく加入するメンバーがコードを逆構築せずにアーキテクチャを理解できる。
- バージョン管理:図をコードのように扱う。変更履歴を追跡できるようにリポジトリに保存する。
- 命名規則:プロセスとデータフローには一貫した命名を使用する。「Update User」は常に「Update User」とするべきであり、「Change User Details」とはしない。
- 定期的な監査:図が現在の実装と一致していることを確認するために、定期的なレビューをスケジュールする。
- 粒度のバランス:すべてのプロセスをサブプロセスにするべきではない。関連する論理をグループ化して、システムの見通しを維持する。
📝 最終的な考察
効果的なシステム設計は明確なコミュニケーションに依存する。データフローダイアグラムは、アーキテクト、開発者、ステークホルダーの間で共有される言語を提供する。既存のパターンに従い、一般的な落とし穴を避けることで、チームは滑らかに成長するシステムを構築できる。
図は現実そのものではなく、モデルであることを思い出してください。複雑さを単純化して理解しやすくするためのものです。しかし、その単純化は、データの整合性や流れに関する重要な詳細を削除してはいけません。DFDがデータの移動を正確に反映している場合、それはボトルネックの予測やパフォーマンスの最適化に役立つ強力なツールになります。
システムがより分散化するにつれて、厳密なモデル化の必要性が高まります。ここに記述されているパターンは、その厳密性の基盤を提供します。モノリシックなアプリケーションを設計する場合でも、マイクロサービスのエコシステムを設計する場合でも、データフローの原則は常に変わりません。情報の流れに注目すれば、構造は自然と導かれるでしょう。
コンテキスト図から始めましょう。境界を明確に定義してください。プロセスの詳細に掘り下がるのは、必要がある場合だけです。技術スタックではなく、データに注目し続けましょう。この徹底的な姿勢により、アーキテクチャは数年先まで柔軟性とスケーラビリティを保つことができます。