











現代の組織では、ビジネス目標と技術的実行の間にある乖離が、しばしば遅延や予算超過、目的から外れた機能を招きます。この摩擦の主な原因は、言語の壁です。ビジネス関係者は価値、成果、顧客のニーズといった言葉で話す一方、技術チームはアーキテクチャ、データ構造、プロトコルについて議論します。これを解決するためには、視覚的モデリングが不可欠です。データフローダイアグラム(DFD)は、情報がシステム内でどのように移動するかを明確で標準化された視点で提供する、普遍的な翻訳者として機能します。この視覚的言語を採用することで、コードを1行も書く前に、チーム間で理解を一致させることができます。
このガイドでは、DFDを効果的に活用して協働を促進し、正確性を確保し、開発ライフサイクルをスムーズにする方法を探ります。基本的な構成要素、抽象度の異なるレベル、およびステークホルダーとエンジニアの両方の要件を満たす図の作成におけるベストプラクティスについて説明します。
コミュニケーションギャップを理解する 🗣️
ビジネス要件が開発チームに引き渡される際、しばしば解釈が加えられます。ステークホルダーが「ユーザープロフィールの更新機能」を要請しても、技術チームはそのデータがどのように検証され、保存され、保護されるかを決定しなければなりません。共有される視覚的参照がなければ、仮定が入り込みます。一方のチームはデータをリアルタイムで保存すると仮定する一方、もう一方のチームはバッチ処理を計画しているかもしれません。
DFDは、制御の論理ではなく、データの移動に焦点を当てるため、このリスクを軽減します。この違いは重要です。なぜなら、ビジネスアナリストが実装の詳細に巻き込まれることなく、情報の流れを検証できるからです。一方、開発者は同じ図を使って統合ポイントやデータベースの要件を特定できます。
- ビジネス視点: 入力、出力、価値の交換に注目する。
- 技術視点: ストレージ、処理、伝送に注目する。
- DFD視点: 両者の間でのデータの移動と変換に注目する。
これらの流れを視覚化することで、チームは設計段階の初期に欠落しているデータポイント、重複するプロセス、またはボトルネックを特定できます。この予防的なアプローチにより、プロジェクトライフサイクルの後半での変更コストを削減できます。
データフローダイアグラムとは何か? 📝
データフローダイアグラムとは、情報システム内を流れるデータの流れを図式化したものである。フローチャートとは異なり、制御論理や決定ポイントに注目するのではなく、データそのものに注目する。データがどこから来ているか、どのように処理されるか、どこに保存されるか、最終的にどこに到達するかを示す。
DFDは階層的です。高レベルの概要から始め、複雑なプロセスを小さな、管理しやすいサブプロセスに分解します。このモジュール性により、チームは特定の領域に注目しながらも、全体のシステムアーキテクチャを失うことはありません。
DFDの使用による主な利点
- 明確性:視覚的表現は、テキストが多めの文書よりも迅速に処理される。
- 一貫性:標準的な記号により、誰もが図を同じように解釈できる。
- 完全性:チームがすべての入力と出力について検討するよう強制する。
- コミュニケーション:会議やレビューの際に共通の参照ポイントとして機能する。
主要な構成要素と記号 🔑
意味のあるDFDを作成するには、標準的な表記を使用する必要があります。Yourdon/DeMarcoやGane/Sarsonなどのメソドロジー間にはわずかな違いがありますが、核心的な概念は一貫しています。これらの記号を使用することで、アナリストやエンジニアが図を普遍的に理解できるようになります。
| 記号名 | 視覚的表現 | 意味 | 例 |
|---|---|---|---|
| 外部エンティティ | 長方形または正方形 | システム境界外のデータの発信元または受信先。 | 顧客、仕入先、決済ゲートウェイ |
| プロセス | 角丸長方形または円 | 入力データを出力データに変換する変換処理。 | 税額計算、ログイン検証、レポート生成 |
| データストア | 開かれた長方形または平行線 | 将来の使用のためにデータを保存する場所。 | データベース、ファイルシステム、ログファイル |
| データフロー | 矢印 | エンティティ、プロセス、ストア間でのデータの移動。 | 注文詳細、ログイン資格情報、領収書 |
すべての矢印に、データを説明する名詞句をラベル付けすることが重要です。動詞ではなく、たとえば「ユーザーのプロフィール」を「ユーザーのプロフィールを送信する」という表現ではなく使用してください。これにより、転送される情報に注目することができるようになります。
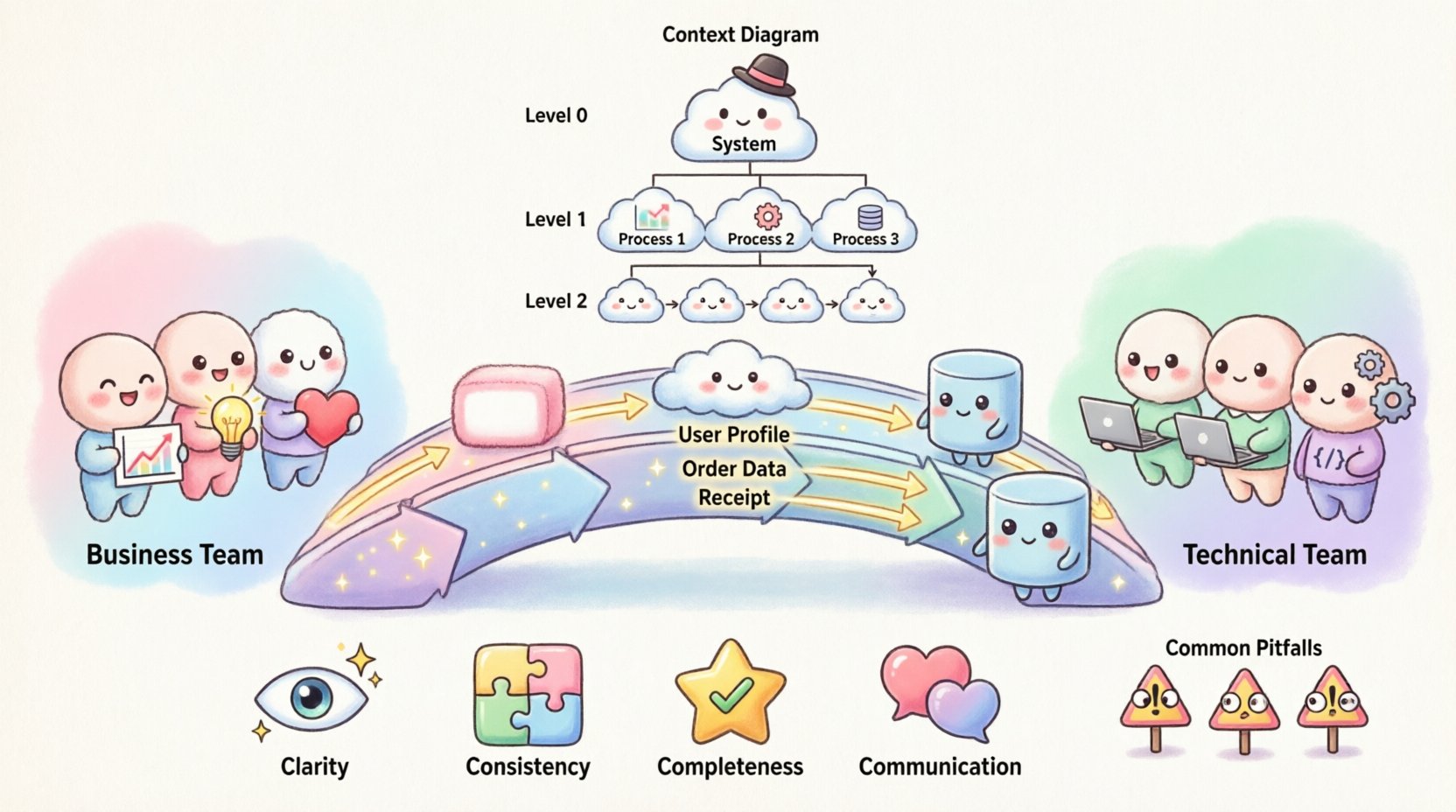
DFDにおける抽象度のレベル 📉
複雑なシステムは1つのビューでは説明できません。複雑さを管理するために、DFDは異なる詳細度で作成されます。この階層的なアプローチにより、チームは広い文脈から始めて、詳細な部分にまで掘り下げることができます。
1. コンテキスト図(レベル0)
コンテキスト図は最も高レベルの視点です。システム全体を1つのプロセスとして表します。システムが外部エンティティとどのようにやり取りするかを示しますが、内部プロセスやデータストアは表示しません。
- 目的:システムの境界を定義する。
- 焦点:高レベルの入力と出力。
- 対象:経営陣および上位ステークホルダー。
2. レベル1図
この図では、コンテキスト図の単一プロセスを主要なサブプロセスに分割します。主なデータストアとそれらの間の主要なフローを導入します。
- 目的:主な機能領域を概説する。
- 焦点:主要なデータ移動および保存。
- 対象者:ビジネスアナリストおよびリード開発者。
3. レベル2以下
レベル2の図は、レベル1の特定のプロセスをより詳細な要素に分解する。プロセスが直接実装可能な原子レベルになるまでこれを繰り返す。
- 目的:開発用の詳細仕様。
- 焦点:特定の論理およびデータ検証。
- 対象者:ソフトウェアエンジニアおよびテスト担当者。
効果的なDFDを作成するためのステップバイステップガイド 🛠️
信頼性の高い図を作成するには構造的なアプローチが必要である。このプロセスを急ぐと、再作業を要するエラーが生じることが多い。正確性と整合性を確保するために、この順序に従ってください。
ステップ1:範囲を特定する
描画する前に、システムの内部と外部を明確に定義する。これにより境界が設定される。システムの外部から相互作用するものはすべて外部エンティティである。内部にあるものはプロセスまたはデータストアである。
- 尋ねる:「どの誰がシステムにデータを提供するか?」
- 尋ねる:「どの誰がシステムからデータを受け取るか?」
- 尋ねる:「データはどこに保存されるか?」
ステップ2:外部エンティティをマッピングする
すべての外部アクターをキャンバス上に配置する。これらは接点である。その役割を明確に理解していることを確認する。たとえば、「ユーザー」と「管理者」は、必要なデータ権限によって異なる場合がある。
ステップ3:主要プロセスを定義する
システムが実行するコア機能を特定する。各プロセスには動詞と目的語を用いて名前を付ける(例:「支払い処理」)。「システム」や「やること」のような曖昧な名前は避ける。各プロセスには少なくとも1つの入力と出力が必要である。
ステップ4:データフローを描画する
エンティティ、プロセス、ストアを矢印でつなぐ。すべての矢印にラベルを付けることを確認する。データが1点から別の点へ論理的に流れているか確認する。データの所有権の連鎖においてステップを飛ばしてはならない。
ステップ5:ステークホルダーと検証する
ビジネス担当者と技術担当者双方とドラフトをレビューする。ビジネス側に、フローが期待通りかどうか尋ねる。技術側に、ストレージおよび処理ポイントが実現可能かどうか尋ねる。
ステップ6:精査と分解
上位のフローが合意されたら、複雑なプロセスを分解し始めましょう。次のレベルの図を描きます。親図と子図の入力と出力が一致していることを確認してください(データの保存則)。
データフローモデリングにおける一般的な落とし穴 ⚠️
経験豊富なモデラーでさえミスを犯します。一般的な誤りに気づくことで、図の整合性を保つことができます。以下の問題は設計段階で頻繁に発生します。
1. ブラックホール
入力はあるが出力がないプロセス。これはデータが消費されるが何の出力も生成されない論理エラーを示しています。実際のシステムでは、データが失われるか、エラーが静かに無視されることを意味します。
2. マジックプロセス
出力はあるが入力がないプロセス。これはデータがどこからともなく出現していることを示唆しています。すべてのデータには必ずソースが必要です。
3. バランスの取れていないフロー
プロセスを分解する際、子図の入力と出力は親図と一致している必要があります。親プロセスが「注文データ」を子に送る場合、理由を示さずにそれを「請求書データ」に変更することはできません。データはレベル間で一貫性を保たなければなりません。
4. コントロールフローとデータフロー
DFDは「もしXならY」といった制御論理を示しません。データの流れを示すものです。意思決定ポイントは、フローチャートで使われる菱形ではなく、データの流れが変化することによって表現すべきです。情報の移動に注目してください。
5. 過度な複雑化
上位の図にあまりにも多くの詳細を追加すると、読者が混乱します。特定の検証ルールやエラー処理は、低レベルの図や別途の文書に残すようにしましょう。
協働のためのベストプラクティス 🤝
図の質は、それを取り巻く会話の質に左右されます。DFDは文書化のためだけではなく、議論のツールとして活用しましょう。
- ワークショップ:両チームがリアルタイムで参加できるライブモデリングセッションを実施しましょう。これにより共有の責任感が育ちます。
- バージョン管理:図をコードのように扱いましょう。リポジトリに保存し、変更履歴をタイムラインで追跡してください。
- 命名規則:エンティティやプロセスの命名について標準を合意しましょう。一貫性があることで混乱を防げます。
- ツールの選定:エクスポートとインポートに対応する汎用的なモデリングツールを使用しましょう。特定のベンダーのエコシステムに縛られるフォーマットは避けましょう。
- 定期的なレビュー:要件が変更されたら図を更新しましょう。古くなった図は、何も無い状態よりも悪いです。
DFDをアジャイルおよびDevOpsワークフローに統合する 🔄
現代の開発手法はスピードと反復を重視しています。DFDも、軽量で最新の状態を保てれば、ここでも役立ちます。
1. スプリント計画
計画段階では、選択されたユーザーストーリーが定義されたデータ境界内に収まっているかを、レベル1の図を参照して確認しましょう。これにより、予期せぬバックエンド変更を要する機能がスコープの拡大につながるのを防げます。
2. 完了定義
完了の定義に図の更新を含める。機能がデプロイされた場合、関連するDFDは新しいデータフローを反映すべきである。これにより、ドキュメントがライブシステムと同期されたまま保たれる。
3. インシデント対応
プロダクションでの問題が発生した際、DFDはデータの経路を追跡するのに役立つ。エンジニアは、データフローが予想された経路からどこでずれたかを迅速に特定でき、根本原因分析を迅速化できる。
成功の測定 📈
あなたのDFD戦略が効果を発揮しているかどうかはどうやって知るか?改善された整合性と効率を示すこれらの兆候を探してみよう。
- 再作業の削減:開発が開始された後に求められる変更が減る。
- 迅速なオンボーディング:新しいチームメンバーがシステムアーキテクチャをより早く理解できる。
- 明確な要件:精査フェーズ中に曖昧な質問が減る。
- テストの向上:テストケースがデータ経路をより包括的にカバーする。
実装における技術的考慮事項 🛡️
DFDは概念的なものであるが、技術スタックに直接的な影響を持つ。これらの影響を理解することで、エンジニアはより良いシステムを設計できる。
データベース設計
図内のデータストアはしばしばテーブルやコレクションに直接対応する。プロセス間のフローは外部キー関係やAPI呼び出しを示す。
セキュリティ境界
機密データが移動する場所を特定する。セキュリティゾーン間(例:インターネットから内部ネットワーク)を横切るデータフローは、暗号化と認証チェックを必要とする。これらのフローは明確にマークする。
パフォーマンス
大量のデータフローは、キャッシュや非同期処理の必要性を示す可能性がある。プロセスが多すぎる同時リクエストを処理している場合、DFDはスケーリングの必要性を浮き彫りにする。
図の維持管理 🔄
今日作成された図は明日には陳腐化している可能性がある。システムは進化する。要件は変化する。価値を高め続けるためには、維持管理が鍵となる。
- 所有者を割り当てる:図の維持管理を担当する特定の役割を指定する。所有者がいない共有責任にしてはならない。
- 更新のトリガー:図の更新を特定の変更要求や機能チケットに関連付ける。
- バージョンのアーカイブ:過去の意思決定の理由を理解するのに役立つため、古いバージョンをアーカイブして保持する。
- 可能な限り自動化する: ツールが対応している場合、コードや設定ファイルから図を生成して、手動でのずれを減らしましょう。
モデリングの人的側面 👥
図は人間が作成し、人間のために作られるということを思い出してください。完璧な技術的成果物を作ることではなく、理解を促進することが目的です。
- 質問を促す:若手メンバーがフローについて質問しやすい環境を作りましょう。
- 視覚的な簡潔さ: 図がごちゃついているように見える場合は、簡潔にしましょう。余白はあなたの味方です。
- 文脈が重要です: CEO向けの図とデータベース管理者向けの図は異なります。詳細のレベルを対象 audience に合わせて調整しましょう。
データフローダイアグラムを静的な文書ではなく、動的なコミュニケーションツールとして扱うことで、組織はビジネスの意図と技術的現実の間のギャップを埋めることができます。明確で正確なモデルを作成するための努力は、誤りの削減、迅速な納品、より結束したチーム文化という恩恵をもたらします。