











現代のビジネス分析の分野において、明確さは単なる贅沢ではなく、必須である。組織は複数の部門にまたがるワークフロー、レガシーシステム、人的なやり取りを抱えている。複雑さが増すと、誤解のリスクも高まる。このような状況で、構造化モデリング技法が不可欠となる。特に、データフローダイアグラム(DFD)は、情報がシステム内でどのように移動するかを可視化する強力な手法を提供する。複雑なビジネスプロセスを分解することで、分析者は膨大なタスクを管理可能で論理的な構成要素に分割できる。このガイドでは、DFDのメカニズム、原則、およびプロセス分解における戦略的応用について探求する。
データフローダイアグラムの基盤を理解する 🧩
データフローダイアグラムとは、情報システム内を流れているデータの流れを図式化したものである。フローチャートとは異なり、制御論理や手順的なステップを描くことが多いが、DFDはデータにのみ焦点を当てる。データがどこから来ているか、どこに保存されているか、どのように変換されるか、そして最終的にどこへ出るかを示す。この違いは、単に出来事の順序ではなく、業務の本質を理解する必要があるビジネスアナリストにとって極めて重要である。
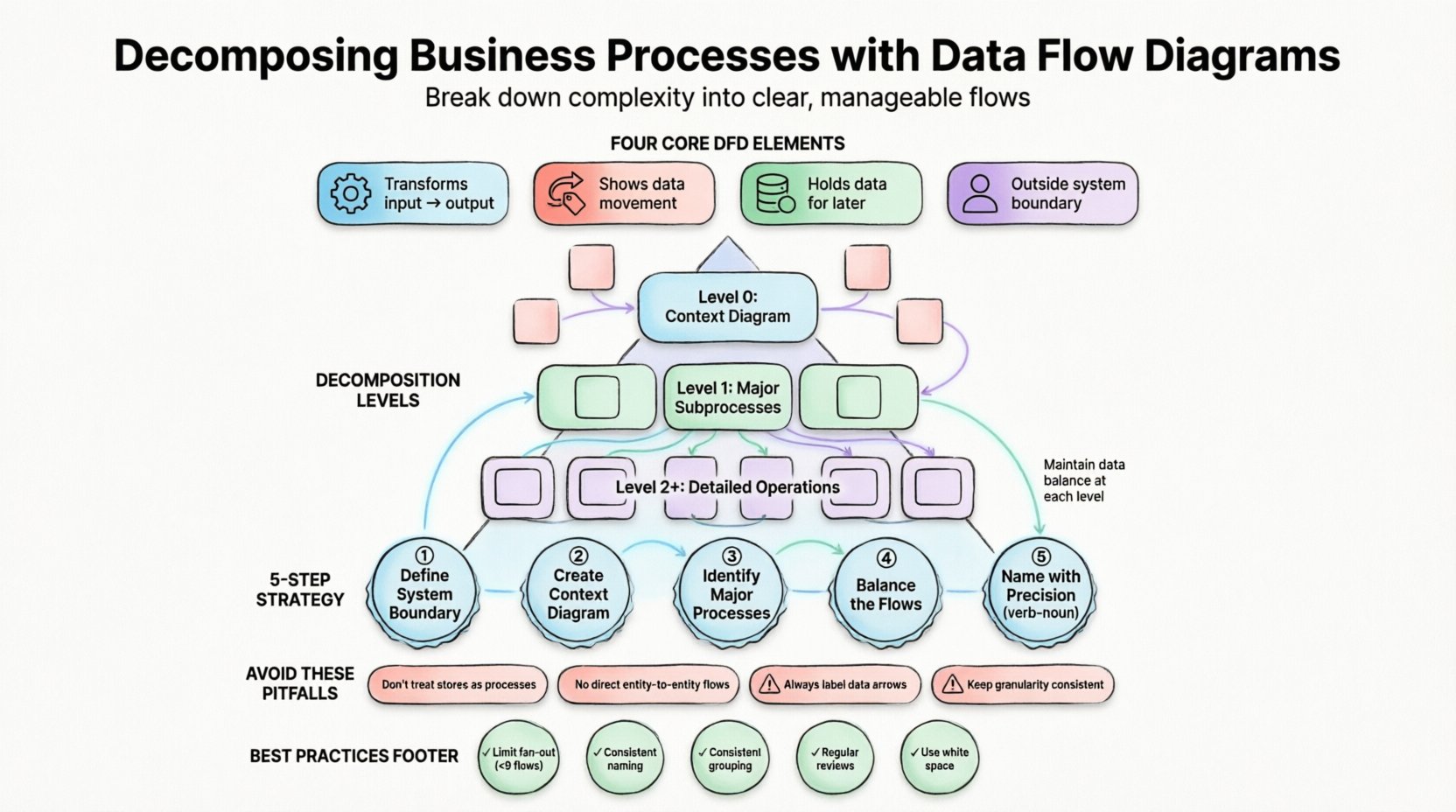
構造化されたDFDは、文書全体にわたって一貫性を保つために特定の記法に依存している。この図は、4つの主要な要素に基づいて構築される。
- プロセス:入力データを出力データに変換するアクション。これらは通常、丸みを帯びた長方形または円で表される。それらはデータに何が起こるかを説明する。何がデータに起こる内容を。
- データフロー:プロセス、ストア、エンティティの間を移動するデータ。これらは矢印で示され、移動中のコンテンツを明確に示すためにラベルを付ける必要がある。
- データストア:後で使用するためにデータを保持する場所。これらは開かれた長方形または平行線で表される。データベース、ファイル、または物理的なアーカイブを表す。
- 外部エンティティ:システム境界外のデータの発信元または受信先。これらは四角形または長方形で、ユーザー、他のシステム、または組織を表す。
標準化されたアプローチがなければ、これらの図は混乱してしまう。構造化されたDFDは、すべてのデータフローに発信元と受信先が存在し、すべてのプロセスが論理的にデータを変換することを保証する規律を課す。
分解の必然性 🔨
複雑なビジネスプロセスは、ほとんどが1ページに収まらない。企業全体の運用を1つのビューでマッピングしようとすると、ステークホルダーにとって理解不能な図になってしまう。分解は、高レベルのプロセスを低レベルの詳細に分割するための技法である。この階層的なアプローチにより、分析者は認知負荷を管理し、正確性を保つことができる。
分解は、いくつかの重要な機能を果たす:
- 粒度制御:チームが特定の関心領域に注目しながらも、広い文脈を失わないようにする。
- ステークホルダーの整合:異なるステークホルダーは、異なる詳細レベルを必要とする。経営陣は上位レベルの図を参照する一方、開発者は詳細なサブプロセスを必要とする。
- エラー検出:複雑な相互作用は、孤立させることでより容易に発見できる。データの不整合や欠落したフローは、低レベルでより明確に見える。
- モジュール性:離散的な関数の観点での思考を促進し、現代のソフトウェアアーキテクチャやマイクロサービスとよく整合する。
分解のプロセスは任意ではない。親プロセスが子プロセスに展開され、それらが親プロセスに入出するすべてのデータを総合的に説明するという論理的な経路に従う。
構造化DFDにおける分解のレベル 📈
構造を維持するために、DFDは通常、レベルに分類される。この階層構造により、詳細が追加されても抽象化のレベルが一貫性を保つ。以下の表は、標準的な分解レベルを概説している。
| レベル | 一般的な名前 | 説明 |
|---|---|---|
| 0 | コンテキスト図 | システム全体を外部エントリと相互作用する単一のプロセスとして示す。 |
| 1 | レベル0図 | 主プロセスを主要なサブプロセスに分割する(通常3~9個)。 |
| 2 | レベル1図 | 特定のレベル0プロセスをさらに詳細な操作に分解する。 |
| 3+ | 子図 | 実装の詳細を目的とした複雑な論理への深掘り。 |
各レベルは以下の原則に従わなければならない。データのバランスつまり、親プロセスの入力と出力は、その子プロセスの入力と出力の合計と正確に一致しなければならない。たとえば、レベル0プロセスに「注文データ」の入力がある場合、レベル1のサブプロセスは collectively その「注文データ」を受け入れなければならない。正当な理由がない限り、新たな外部入力を追加してはならない。
段階的分解戦略 🚀
分解を実行するには体系的なアプローチが必要である。矢印を急いで描き始めると構造的な誤りが生じる。以下のワークフローにより、堅牢な図構造を保証できる。
1. システム境界を定義する
何を描くかの前に、システムの内部と外部を明確に定義する。この境界がプロジェクトの範囲を定義する。外部エントリはこの境界の外に存在する。境界内ですべての出来事はプロセスまたはストアである。この定義により、分析段階での範囲の拡大(スコープクリープ)を防ぐことができる。
2. コンテキスト図を作成する
トップレベルの視点から始める。システムを中央に単一のバブルとして配置する。システムと相互作用する主要な外部エントリを特定する。それらの間の主要なデータフローを描く。この図はステークホルダーが範囲を確認できる「ヘリコプター視点」を提供する。
3. 主要プロセスを特定する
システムに入り出るデータフローを確認する。それぞれの明確な変換は、主要なプロセスを示唆する。たとえば、「顧客データ」が入力され、「請求書データ」が出力される場合、変換はおそらく「請求書の生成」である。これらを論理的なクラスタにグループ化する。
4. フローのバランスを取る
プロセスを分解する際には、入力と出力を確認する。データが消える(ブラックホール)ことや、どこからともなくデータが出現すること(奇跡)を避ける。サブプロセスに入力するすべての矢印は、そのプロセスから出力されるデータによって説明されなければならない。
5. 精確に名前を付ける
ラベル付けはしばしば見過ごされがちだが、読みやすさにとって極めて重要である。プロセス名は「注文の検証」や「税額の計算」のように、動詞+名詞の表現を用いるべきである。「データを処理する」のような曖昧なラベルは避ける。ラベルは実際に起こっている特定の変換を明確に示す必要がある。
プロセスモデリングにおける一般的な落とし穴 ⚠️
経験豊富なアナリストですら、データフローをモデリングする際に問題に直面することがあります。これらのパターンを早期に認識することで、大幅な再作業を回避できます。以下の項目は、分解の過程でよく見られる誤りです。
データストアをプロセスとして扱う
データがデータベースとやり取りするため、データベースをプロセスとして扱いたくなるのは自然です。しかし、データベースは受動的な保存装置にすぎません。データを変換するのではなく、保持するだけです。プロセスには必ず動作を表す動詞が関連付けられるべきです。ストアはプロセスによってアクセスされるものであり、プロセスそのものではありません。
エンティティを直接接続する
外部エンティティ間でデータがシステムを経由せずに直接流れることはできません。顧客がリクエストを送信し、応答を受け取る場合、データはプロセスに入力され、変換された後、出力される必要があります。2つのエンティティ間に直接の線が引かれていると、それらが同一のエンティティであるか、システムが無視されていることを示唆します。
ラベルのないデータフロー
ラベルのない矢印は意味がありません。何の情報が移動しているかを示しません。すべてのフローには「配送先住所」や「支払い状況」など、明確な名前を付ける必要があります。ここでの曖昧さは、後の実装段階で誤りを招きます。
粒度の不一致
あるプロセスが詳細に記述されている一方で、隣接するプロセスは曖昧なままになっていることがあります。このような不一致は読者を混乱させます。あるサブプロセスが3つのステップに分解されている場合、隣接するプロセスも同程度の詳細度にすべきです。ただし、それらが本質的に単純である場合は例外です。
DFDをビジネス要件と統合する 📝
図は、実際のビジネスニーズと対応している場合にのみ有用です。データフローダイアグラムは、空虚な存在であってはなりません。要件文書の視覚的基盤として機能すべきです。要件に「システムはクレジットカードの検証を行う必要がある」とある場合、DFDにはカードデータを受け取り、ステータスフラグを出力する検証プロセスが示されるべきです。
このトレーサビリティは監査およびコンプライアンスにとって不可欠です。規制業界では、データの出所を証明し、どのように保護されているかを示すことが義務付けられています。DFDはセキュリティレビューの地図を提供します。アナリストは、機密データがどこに流れているかを特定し、プロセスレベルで適切な制御が適用されていることを確認できます。
構造化モデリングのためのベストプラクティス ✅
図の高品質を維持するためには、以下のベストプラクティスに従ってください。これらのガイドラインは一貫性と保守のしやすさを促進します。
- ファンアウトを制限する:1つのプロセスが9本以上のデータフローに接続されないようにしてください。プロセスがこれほど複雑である場合、さらに分解する必要がある可能性が高いです。
- 一貫した命名:すべてのレベルでデータフローに同じ用語を使用してください。レベル0で「注文データ」という用語を使用している場合、レベル1では「顧客リクエスト」とは呼びません。
- 論理的グループ化:関連するプロセスをまとめて配置してください。特定のプロセス群が常に財務データを扱う場合、視覚的にクラスタ化することで理解を助けます。
- 定期的に見直す:ビジネスプロセスは変化します。DFDは動的な文書です。図が現在の運用を正確に反映していることを確認するために、定期的なレビューをスケジュールしてください。
- 余白を活用する:要素をぎゅうぎゅうに詰め込まないでください。適切な余白は認知負荷を軽減し、図の読みやすさを向上させます。
システム設計における分解の役割 🏗️
文書化を超えて、DFDの分解はシステムの構築方法に影響を与えます。プロセスが明確に定義されていると、開発チームはモジュールを特定の開発者やチームに割り当てることができます。このモジュール化により、チーム間の依存関係が軽減されます。プロセスAとプロセスBが独立している場合、並行して開発が可能になります。
さらに、分解はパフォーマンスのボトルネックを特定するのに役立ちます。特定のサブプロセスが過剰なリソースを消費したり、大きな遅延を引き起こしたりする場合、それは最適化の対象になります。分解がなければ、ボトルネックはシステムのモノリシックな視点の中に隠れてしまいます。
また、テスト戦略の支援にもなります。テストケースはデータフローから直接導出できます。プロセスが「入力A」を「出力B」に変換する場合、テストケースはその特定の変換を検証する必要があります。設計とテストの整合性により、高品質な提供が保証されます。
並行プロセスおよびループの扱い 🔄
現実のビジネスプロセスは、しばしばループや並行処理を含む。標準的なDFDは論理を線形に表現するが、ビジネスルールは反復的であることがある。たとえば、注文が承認される前に複数の検証ステップを経る必要がある場合がある。図では、このようにデータフローが以前のプロセスに戻る形で表現される。
ループをモデル化する際、明確さが最も重要である。ループの条件は矢印の意味合いだけで示すのではなく、プロセスの説明に明記するようにする。プロセスに戻るフローは、再作業サイクルまたは検証の再試行を示す。この戻りの条件を明確に記述することで、開発チームの誤解を防ぐことができる。
並行処理は並行するフローで表現される。2つの処理が同時に発生する場合は、別々の分岐に描く。ただし、DFDはタイミングや同期ポイントを示さないことに注意する。そのような詳細は他のモデル化記法に属する。DFDはフローの存在に注目するものであり、タイミングには注目しない。
アナリストのための最終的な考慮事項 🤔
分解の技術を習得するには、練習と忍耐が必要である。アナリストがさまざまな種類のビジネスロジックに遭遇する中で、このスキルは時間とともに育つ。目標は、可能な限り詳細な図を描くことではなく、最も有用な図を描くことである。
図はコミュニケーションツールであることを忘れないでください。主な対象は、情報の流れを理解する必要がある非技術的なステークホルダーである。図がしすぎた技術的要素を含んでしまうと、目的を果たせない。抽象度を、対象となる audience の専門性に合わせて調整する。
ドキュメントは常に意思決定プロセスを支援すべきである。ビジネスリーダーが特定のデータポイントの発生源を尋ねたとき、DFDは迅速に答えを提供できるべきである。この信頼性が分析機能に対する信頼を築く。時間とともに、図の集積は組織にとって貴重な資産となり、将来のシステム変更の参照資料として機能する。
システムが進化するにつれて、図もそれに合わせて進化しなければならない。陳腐化した図は、何も描かれていないよりも悪い。なぜなら誤解を招くからである。データフロー・モデルの整合性を保つことを誓う。それらを、最終的にそれらを支援するために書かれるコードと同じように丁寧に扱うべきである。この規律により、ビジネスロジックが透明でアクセス可能であることが保証される。
結局のところ、価値は得られた明確さにある。複雑なものを理解可能な形に分解することで、アナリストは組織がより効率的に運営できるように支援する。データフロー図の構造的なアプローチが、この明確さの基盤を提供し、混沌を秩序に変える。