











現代のソフトウェア開発およびシステムアーキテクチャにおいて、チーム間の断絶はしばしば静かに生産性を奪う要因となる。エンジニアリング、プロダクトマネジメント、品質保証、セキュリティ運用は頻繁に孤立して作業しており、断片的な文書や口頭での引き継ぎに依存するため、誤解が生じやすい。共有されたデータフローダイアグラム(DFD)は、これらのギャップを埋めるための普遍的な視覚的言語として機能する。共通の参照ポイントを確立することで、組織はすべての関係者がデータがシステム内でどのように移動し、どこに保存され、どのように変換されるかを理解していることを保証できる。
このガイドでは、共有されたDFDの実装メカニズムを検討し、整合性を促進する。単なる図面作成を越えて、これらの成果物を意思決定を支える動的な文書とするために必要な文化的・プロセス的な変化についても議論する。DFDの構造的要素、抽象化の階層、そして時間の経過とともにその関連性を維持するために必要なガバナンスモデルについて検討する。
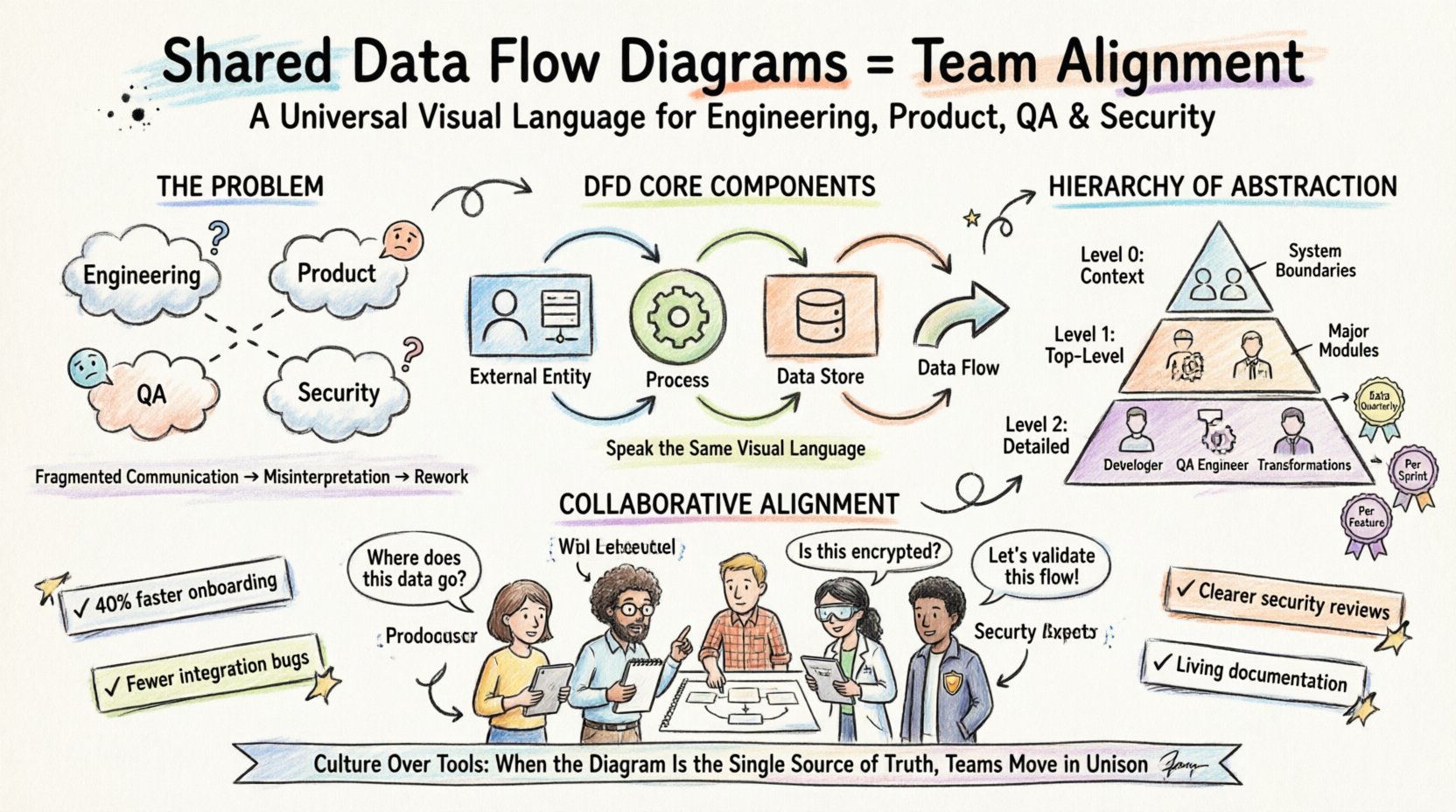
データフローダイアグラムとは何か? 🔍
データフローダイアグラムとは、情報システム内を流れているデータの流れを視覚的に表現したものです。フローチャートが論理の順序や制御フローに注目するのに対し、DFDはデータそのものに注目します。データの発生源、処理方法、保存場所、システムからの出力先を明示します。
DFDの主な価値は、複雑さを抽象化できる点にある。ステークホルダーは、コードレベルの実装細節に巻き込まれることなく、「全体像」を把握できる。チームがこれらの図を共有することで、1行のコードが書かれる前からアーキテクチャについて合意形成が可能になる。
DFDの核心的な構成要素 🧩
真の整合性を達成するためには、すべてのチームメンバーが同じ視覚的言語を話す必要がある。DFDの標準表記には、4つの基本要素が含まれる:
- 外部エンティティ(ソース/シンク):システムの境界外にある人、システム、または組織で、データを送信または受信するもの。通常、長方形で表現される。
- プロセス:データに対して行われる変換またはアクションを表す。入力データが出力データに変換される場所である。プロセスは通常、丸みを帯びた長方形または円で示される。
- データストア:後で使用するためにデータを保持するリポジトリを表す。データベース、ファイルシステム、一時的なキャッシュなどが含まれる。データストアは通常、開口部のある長方形で表現される。
- データフロー:エンティティ、プロセス、ストアの間を移動するデータの流れを表す。矢印で表現され、移動中の情報の内容を示すラベルが付く。
これらの構成要素が組織全体で標準化されれば、新人開発者がシニアアーキテクトが作成した図を見ても、その意図を即座に理解できる。これにより、コードレビューおよびスプリント計画における認知的負荷が軽減される。
共有された文脈がなければ、整合性が失敗する理由 🚧
中央集権的な視覚的表現がなければ、チームはしばしばテキストベースの要件や口頭での説明に頼る。テキストは線形であり、曖昧さを含みやすい。データ検証ルールを説明する文が、バックエンドチームとフロントエンドチームで異なるように解釈されることがある。これにより、「あなたはそれだと考えていたの?」という状況が生じ、再作業やリリースの遅延を招く。
整合性の欠如によるコスト 💸
データフローが明確に定義されていないと、いくつかの運用上の問題が生じる:
- 統合失敗:API契約が想定されるデータ構造と一致しないことがある。
- セキュリティの穴:フローが明示的にマークされていなければ、機密データが暗号化されていないプロセスを通過する可能性がある。
- パフォーマンスのボトルネック:特定のデータフローが重い処理を伴うことにチームが気づかず、本番環境で遅延問題が発生する。
- オンボーディングの摩擦:新入社員が、アーキテクチャを学ぶ代わりに、システムを逆引きして理解しようと数週間を費やす。
共有されたDFDは、データの移動を明確にすることで、これらのリスクを軽減する。実装を開始する前に、チームが「このデータは次にどこへ行くのか?」という問いに答えることを強いる。
DFD階層の標準化 📊
混乱を防ぐために、図示に階層的なアプローチを採用することが不可欠です。これにより、異なるチームが各自の役割に応じた詳細度で関与できます。プロダクトマネージャーは上位のフローを把握する必要があり、エンジニアは特定のデータ変換を確認する必要があります。
抽象度のレベル
- レベル0(コンテキスト図): これは最も高いレベルです。システム全体を1つのプロセスとして示し、外部エンティティとの相互作用を表します。システムの境界を定義します。
- レベル1(トップレベルの分解): 主なプロセスが主要なサブプロセスに分解されます。これにより、システムの機能的な概要が得られます。
- レベル2(詳細な分解): サブプロセスがさらに具体的なアクションに分解されます。ここに詳細な論理が存在します。
以下の表は、各レベルにおける適切な対象者と目的を概説しています。
| 図のレベル | 主な対象者 | 注目領域 | 更新頻度 |
|---|---|---|---|
| コンテキスト(レベル0) | ステークホルダー、プロダクト、経営陣 | システムの境界および入出力 | 四半期ごとまたはメジャーリリース時 |
| トップレベル(レベル1) | エンジニアリングリード、アーキテクト | 主要な機能モジュール | スプリントごとまたはマイルストーンごと |
| 詳細(レベル2) | 開発者、QA、セキュリティ担当 | 特定のデータ変換 | 機能変更ごと |
整合プロセスにおける役割 👥
DFDの作成と維持は技術チームの単独の責任ではありません。効果的な整合には、さまざまな分野からの意見が必要です。各役割が独自の視点を提供し、図が現実を反映することを保証します。
- プロダクトマネジメント: ビジネス価値と外部エンティティを定義します。図がユーザーのニーズとビジネスルールを反映していることを確認します。
- システムアーキテクト: 高レベル構造を定義する。データストアおよびプロセスがスケーラビリティや信頼性などの非機能要件と整合していることを保証する。
- バックエンドエンジニア: 処理論理を検証する。定義されたデータフローが現在のインフラ構成内で技術的に実現可能であることを確認する。
- QAエンジニア: 異常ケースを特定する。テストされていない状況につながる可能性のあるデータ経路の欠落がないか図面を検証する。
- セキュリティ専門家: データストアおよびデータフローに機密情報がないかを確認する。データ保護規制への準拠を保証する。
共同レビュー会議 🤝
ドキュメントを渡すのではなく、チームは図面をリアルタイムで描画または更新するワークショップを開催すべきである。この手法はしばしば「ホワイトボード作業」と呼ばれるが、即時フィードバックを促進する。セキュリティ専門家が暗号化されていない状態でシステムからデータが流出するフローに気づいた場合、コード監査中に発見するのではなく、直ちに指摘できる。
単一の真実の源を確立する 🏛️
図面はアクセス可能で最新である場合にのみ有用である。図面がローカルのハードディスク上にあるか、静的なPDFファイルにある場合、変更が加えられた瞬間に陳腐化してしまう。整合性を維持するため、DFDはすべての承認済み人員がアクセス可能な中央集積リポジトリに置かれるべきである。
図面のバージョン管理 📝
コードがバージョン管理されるのと同様に、図面もコードとして扱うべきである。つまり、差分比較ができないバイナリファイルに頼るのではなく、図面の定義をバージョン管理システムに保存するべきである。共同プラットフォームを使用する際、システムは以下の情報を追跡すべきである:
- 誰が変更を行ったか?
- いつ変更が行われたか?
- どの特定の要素が変更されたか?
- 変更の理由は何か?
この監査トレースはトラブルシューティングに不可欠である。本番環境でバグが発生した場合、チームは図面の履歴を遡って、データフローが最近変更されたかどうかを確認できる。
命名規則 🏷️
命名の曖昧さは整合性を破壊する。名前が「データ更新」というプロセスは曖昧である。一方、「ユーザー・プロフィール住所の更新」という名前は明確である。すべてのプロセス、データストア、データフローに対して厳格な命名規則を設けることは、共有理解の前提条件である。
- プロセス名: 動詞+名詞(例:「支払い詳細の検証」)
- データストア: 複数形名詞(例:「ユーザー・アカウント」)
- データフロー: 名詞句(例:「注文確認メール」)
保守と進化 🔄
ドキュメント管理における最大の課題の一つは、常に最新の状態を保つことである。アジャイル環境では変更が頻繁に発生する。図面がコードと並行して更新されない場合、資産ではなく負債になってしまう。
変更管理プロトコル 📋
組織は、図の更新を開発ワークフローに統合すべきである。データフローの変更は、コードのマージの前提条件となるべきである。これは次のように強制できる。
- 完了の定義: 特性は、関連するDFDレベルが更新されるまで完了とは見なされない。
- 自動チェック: 図がデプロイされた構成と一致しているかを検証するスクリプト。
- 定期的な監査: チームが図を確認してずれを特定するためのスケジュールされたレビュー。
レガシーシステムの取り扱い 🏗️
既存のシステムを扱う際には、「現状」の図を作成した後で「将来」の図を作成する必要がある。現在のデータフローを逆設計することは、移行やリファクタリングプロジェクトの最初のステップであることが多い。これには、元の開発者へのインタビュー、またはデータベーススキーマの分析が必要であり、正確なフローを再構築するためである。
避けたい一般的な落とし穴 ⚠️
最高の意図を持っていても、チームはDFDの効果を低下させる罠にはまってしまうことがある。これらの一般的な誤りに気づくことで、整合プロセスの整合性を保つことができる。
落とし穴1:過度な複雑化 🧨
レベル0またはレベル1の図に、すべての変数やエラー条件を示そうとすると、ノイズが発生する。図の目的はフローを示すことであり、論理を示すことではない。詳細な論理はコードや別途の仕様書に記載すべきである。視覚的な表現は簡潔に保つこと。
落とし穴2:非機能要件を無視する 🛡️
標準的なDFDは機能的なデータに焦点を当てる傾向がある。しかし、セキュリティやパフォーマンスに関するデータもまたフローである。システムの挙動に影響を与える場合、メタデータ、ログ、認証トークン、監査トレースを含めるべきである。データフローに機密情報を含む場合は、視覚的に区別すべきである。
落とし穴3:「棚ぼた」図の作成 📚
会議やコードレビュー中に誰も図を見ない場合、それは「棚ぼた」である。これを防ぐためには、図を文書化の際に明確に参照する必要がある。たとえば、API仕様書を書く際には、そのエンドポイントを処理するDFD内の特定のプロセスにリンクする。
成功の測定 📈
共有されたDFDが実際に整合性を高めているかどうかはどうやって知るか? コラボレーションと効率性を反映する特定の指標を追跡する必要がある。
- オンボーディング時間: 新しいエンジニアが生産的になるまでにかかる時間を測定する。明確なDFDはこれを大幅に短縮すべきである。
- 欠陥密度: データ処理や統合に関連するバグの数を追跡する。バグが少ないほど、データフローに関する整合性が高まっていることを示す。
- レビュー周期時間: コードレビューにかかる時間をモニタリングする。レビュー者が図からデータフローを理解できていれば、説明を求める時間は短くなる。
- ドキュメントの新鮮さ: 最近のスプリントで更新された図の割合と、古くなった図の割合の比率を計算する。
結論:ツールより文化 🧱
データフローダイアグラムのメカニズムは技術的であるが、その成功は文化に依存する。整合性は特定のツールをチームに強制することで達成されるものではない。図が真実を表していると合意することで達成される。
チームが個人の出力よりも共有された理解を優先するとき、ソフトウェアの品質が向上する。DFDは製品のビジョンとエンジニアリングの実行との間の契約となる。構築されたシステムが設計されたシステムであり、設計されたシステムが必要なシステムであることを保証する。
階層、バージョン管理、レビューの基準に従うことで、組織は静的な図を共同作業のための動的なツールに変えることができます。その結果、より強靭なアーキテクチャと、一丸となって動くチームが生まれます。
まず現在の状態をマッピングしましょう。サイロを特定し、線を引きます。その後、一緒に協力して流れを明確にします。それが整合性を図る道です。