











システム設計および要件工学の分野において、明確さは極めて重要です。ステークホルダーが情報がシステム内でどのように移動するかを把握できない場合、プロジェクトはしばしば停滞します。このような状況で、データフロー図(DFD)はビジネスアナリストにとって不可欠なツールとなります。静的な図や複雑なコードとは異なり、DFDはデータの入力から出力までの流れを可視化し、変換や保存ポイントを強調します。このガイドでは、DFDの仕組み、構造的要素、そして成功したビジネスアナリシスにおける重要な役割について解説します。
レガシーシステムのマッピングであれ、新しいデジタルプラットフォームの設計であれ、情報の流れを理解することは、効果的なモデリングの基盤です。主要な記号、図の階層構造、正確性を保証するための具体的なルールについて説明します。誇張は一切なく、堅固なシステム文書作成に必要な構造的整合性のみを提供します。
データフロー図とは何ですか? 🤔
データフロー図は、情報システム内を流れているデータの流れを図式化したものです。入力と出力を示すことで、システムがデータをどのように処理するかをモデル化します。フローチャートはプロセスの論理や意思決定の順序に注目するのに対し、DFDはデータそのものに注目します。
主な特徴には以下が含まれます:
- データに注目する: データオブジェクトを追跡するものであり、制御論理ではない。
- プロセス指向: データがシステム内を移動する際にどのように変化するかを示す。
- 抽象化: 内部の実装詳細を隠蔽し、「どうするか」ではなく「何をするか」に注目する。
- 独立性: 特定の技術に束縛されず、システム要件を記述する。
ビジネスアナリストにとって、DFDはコミュニケーションの橋渡しの役割を果たします。技術的な要件を、非技術的なステークホルダーが確認・検証できる視覚的な形式に変換するのです。これにより曖昧さが減少し、システムが情報をどのように扱うかについて、全員が合意できるようになります。
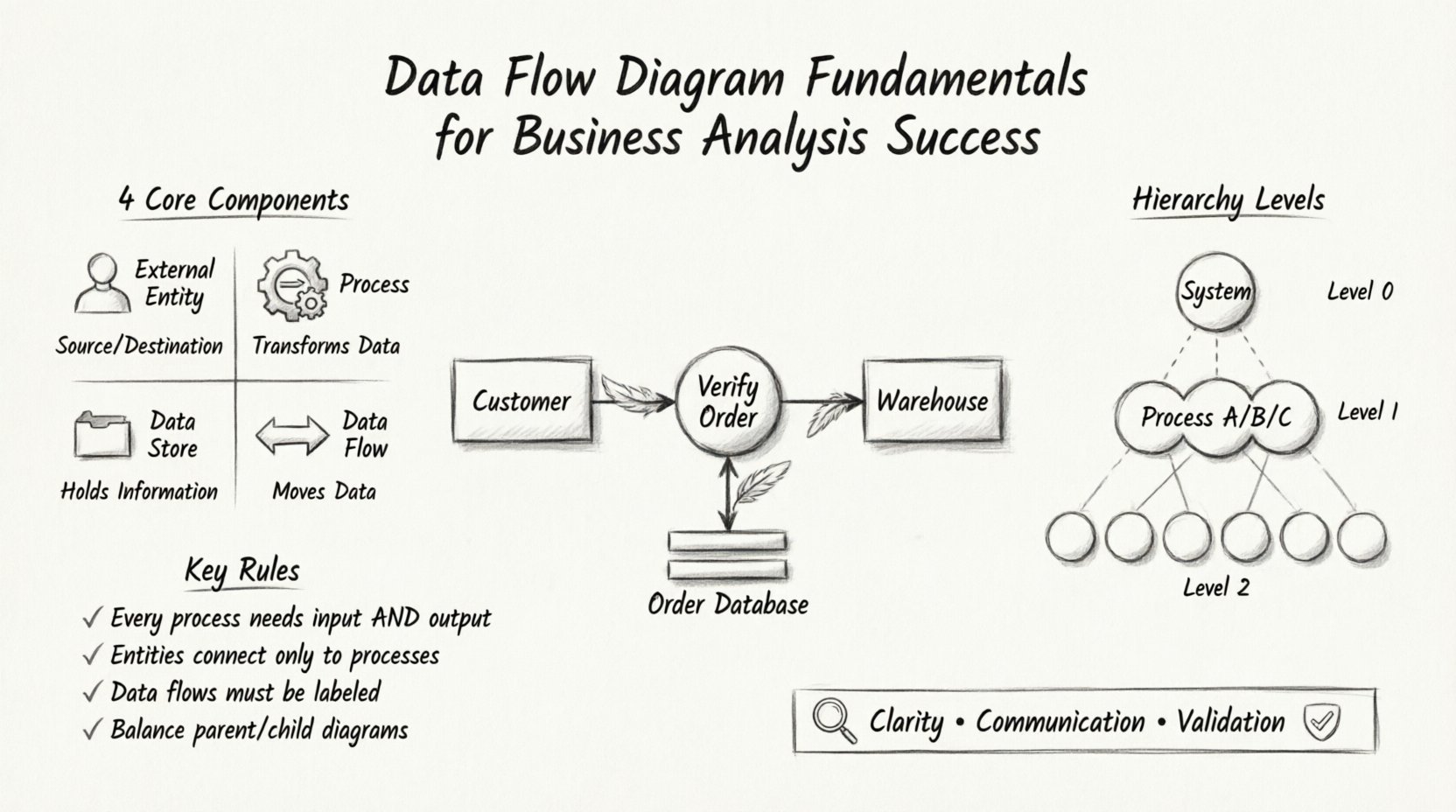
DFDの核心的な構成要素 🧩
有効なデータフロー図は、4つの基本要素で構成されています。正確な図を描くためには、これらの要素を理解することが前提です。これらの記号は、使用する方法やツールに関係なく一貫して保持されます。
1. 外部エンティティ(情報源および目的地) 👤
外部エンティティは、モデル化対象のシステムとやり取りする人、組織、または他のシステムを表します。データフローの出発点(ソース)または終着点(デスティネーション)として機能します。これらはシステムの境界外に存在します。
- 例: 顧客、銀行、政府機関、またはサードパーティのAPI。
- 表記法: 通常、長方形または人物を表すアイコンで表現される。
- ルール: すべてのデータフローはプロセスに接続しなければならない。別のエンティティに直接接続することはできない。
2. プロセス(変換) ⚙️
プロセスは、入力データを出力データに変換します。データに対して実行される関数、活動、または計算を記述します。システム内の「作業」が行われる場所です。
- 例: 「合計を計算する」、「ユーザーを検証する」、「レポートを生成する」。
- 表記法: 通常は円または角が丸い長方形です。
- ルール: すべてのプロセスには少なくとも1つの入力と1つの出力が必要です。入力を受けるが出力を生成しないプロセスは不可能です。
3. データストア(リポジトリ) 📁
データストアは、後で使用するために情報を保存する場所を表します。データベース、ファイル、紙のファイル、または物理的な倉庫が該当します。データを処理するのではなく、保持するだけです。
- 例:顧客データベース、在庫ファイル、注文ログ。
- 表記法:通常は開かれた長方形または平行線です。
- ルール:データフローはプロセスとデータストアを接続しなければなりません。データストアは外部エンティティに直接接続することはできません。
4. データフロー(移動) 🔄
データフローはエンティティ、プロセス、ストア間でのデータの移動を示します。実際に送信されているデータパケットを表します。
- 例: 「請求書」、「支払い詳細」、「検索クエリ」。
- 表記法:データの移動方向を示す矢印。
- ルール:矢印はラベルを付ける必要があります。ラベルのないフローは意味がありません。
以下の表は、これらのコンポーネント間の関係を要約し、すばやく参照できるようにします。
| コンポーネント | 機能 | 接続ルール |
|---|---|---|
| 外部エンティティ | 発信元または宛先 | プロセスにのみ接続可能 |
| プロセス | データを変換する | エンティティ、ストア、および他のプロセスに接続可能 |
| データストア | データを保存する | プロセスにのみ接続する |
| データフロー | データを輸送する | ラベルを付ける必要がある;エンティティ同士を直接接続できない |
DFDの分解レベル 📉
単一の図では、システム全体の複雑さをほとんど捉えることはない。詳細を管理するために、DFDは異なるレベルに分解される。この階層構造により、分析者はシステムの視点を拡大・縮小できる。
コンテキスト図(レベル0) 🌍
コンテキスト図は、最も高い抽象度のレベルである。システムを単一のプロセスとして示し、それとやり取りする外部エンティティを特定する。システムの境界を定義する。
- 範囲:システム全体を表す中心プロセス一つ。
- 詳細:主要なデータ入力と出力のみが表示される。
- 用途:システムの範囲について、初期のステークホルダー間の合意を得るために使用される。
レベル1図 🏗️
レベル1図は、コンテキスト図の単一プロセスをサブプロセスに展開する。システムの主要機能を分解する。
- 範囲:システムの内部プロセスが可視化される。
- 詳細:内部機能間でのデータの移動を示す。
- 用途:詳細な機能要件の定義に使用される。
レベル2以降 🧱
レベル1のプロセスがまだ複雑な場合、さらに分解が行われる。レベル2図は、特定のレベル1プロセスをより細かいステップに分解する。
- 範囲:特定の機能内の詳細な論理。
- 詳細:特定のデータ変換とローカルストア。
- 用途: 特定のモジュールを実装する開発チーム向けに使用されます。
バランスの原則 ⚖️
DFDモデリングにおける最も重要なルールの一つがバランスです。バランスは親図と子図の間に一貫性を保証します。プロセスが低レベルの図に展開される際、入力と出力は同じままである必要があります。
レベル0のプロセスが「注文データ」を受け取り、「領収書データ」を送信する場合、そのプロセスを表すレベル1の図も、入力として「注文データ」を受け取り、出力として「領収書データ」を送信しなければなりません。内部の複雑さは変化しますが、外部世界とのインターフェースは一定のままです。これにより、分解プロセス中にデータが生成されたり破壊されたりすることを防ぎます。
ステップバイステップの作成プロセス 🛠️
信頼性の高いDFDを作成するには、構造的なアプローチが必要です。急ぐと誤りや混乱を招きます。信頼できるモデルを構築するには、以下のステップに従ってください。
1. システム境界を特定する
システムの内部と外部を明確に定義します。これにより、外部のエンティティと内部のプロセスを判断できます。この境界の外側にあるすべてのものは、外部エンティティです。
2. 外部エンティティをマッピングする
ソリューションとやり取りするすべての人、部門、またはシステムをリストアップします。それらを図の周辺に配置してください。内部ユーザーは、外部のデータソースとして機能する場合を除き、含めないでください。
3. 主要なプロセスを定義する
データを処理するために必要な高レベルの機能を特定します。名前には動詞を用いる(例:「支払い処理」など、「支払い」ではなく)。論理的な順序が保たれていることを確認してください。
4. データフローを描画する
エンティティをプロセスに、プロセスをデータストアに接続します。すべてのフローに、その中を移動するデータを説明するラベルを付けることを確認してください。可能な限り線が交差しないようにして、読みやすさを保ちます。
5. レビューと検証
バランスのルールに照らして確認します。すべてのプロセスに入力と出力があることを確認します。データストアがプロセスを介さずにアクセスされないことを保証します。ドラフトをステークホルダーに提示し、フィードバックを得ます。
明確さのための命名規則 🏷️
見づらいラベルが付いた図は、その目的を果たしません。明確な命名規則は、読者の認知負荷を軽減します。
プロセス名
- 動詞の後に名詞を用いる(例:「顧客プロフィールの更新」)。
- 名前は短くても、説明的であるようにする。
- 「プロセス1」や「何かを行う」のような一般的な用語を避ける。
データフロー名
- 行動ではなく、データそのものを名前付ける(例:「請求書の詳細」、「請求書を送信する」ではない)。
- 図全体で、単数または複数を一貫して使用する。
- 名前がデータ辞書または要件文書と一致していることを確認する。
データストア名
- 何が格納されているかを示す名詞句を使用する(例:「注文ファイル」または「顧客リスト」)。
- 動詞句を使用しない。
よくある落とし穴とその回避方法 ⚠️
経験豊富なアナリストでさえミスを犯します。一般的な誤りを早期に認識することで、後で大幅な再作業を避けることができます。
1. 途切れてしまったデータフロー
どこからも始まらず、どこにも終わらないフローです。すべての矢印は、2つの有効なコンポーネントを結ばなければなりません。
- 修正:すべての線を追跡してください。空の空間で終わっている場合は、プロセスまたはエンティティに接続してください。
2. ブラックホール
入力はあるが、出力がないプロセスです。これは、データが使用されたり保存されたりせずに消費されていることを意味します。
- 修正:すべてのプロセスが、ストア、エンティティ、または別のプロセスに何らかの出力を生成することを確認してください。
3. 奇跡的なプロセス
出力はあるが、入力がないプロセスです。これは、データが空から出現していることを意味します。
- 修正:データの元を特定してください。それをエンティティまたはデータストアに接続してください。
4. エンティティ間の直接的なデータフロー
データは、システム(プロセス)を経由せずに、1つの外部エンティティから別の外部エンティティへ移動することはできません。
- 修正:すべての外部フローを、少なくとも1つの内部プロセスを通すようにルーティングしてください。
5. 早すぎる詳細の多さ
コンテキストやレベル1のビューを確立せずに、レベル2の図から始めること。
- 修正:広い視点から始めましょう。まずシステムの境界を定義してください。高レベルのビューが承認された後、のみ分解してください。
DFDを現代のビジネスアナリシス実践に統合する 🔄
データフローダイアグラムは孤立した成果物ではありません。特にアジャイルや反復的な環境において、広い範囲のビジネスアナリシスワークフローに組み込まれます。
アジャイルとの互換性
アジャイル環境では、重い文書化はしばしば避けられます。しかし、DFDのような視覚モデルは、複雑な論理に対して依然として価値があります。開発をガイドするための「ちょうどよい」文書化として作成でき、ボトルネックにならずに済みます。複雑なデータ変換を含むユーザーストーリーを明確にするためにそれらを使用してください。
要件トレーサビリティ
DFD内の各プロセスは、機能要件に対応する必要があります。これにより、すべての要件がモデルに反映されているかを確認できるトレーサビリティマトリクスが作成されます。対応するプロセスのない要件が存在する場合、システム設計は不完全です。
ステークホルダーとのコミュニケーション
技術用語はしばしばビジネスユーザーを遠ざけます。DFDは普遍的な言語を提供します。ビジネスユーザーがデータストアを指差して、「この履歴はどこに保存していますか?」と尋ねることができます。アナリストは、図にそのストアが存在するかを確認できます。これにより、要件の共同での洗練が容易になります。
正確性を確認するための検証技術 📏
図が描かれた後は、必ず検証する必要があります。DFDの検証により、現実世界の業務を正確に反映しているかを確認できます。
ウォークスルー
専門家と共同でウォークスルーを行います。図を通じて特定の取引を追跡します。たとえば、「購入依頼」のライフサイクルを作成からアーカイブまで追跡します。パスが途切れたり論理的に整合性が取れなければ、図の見直しが必要です。
データ辞書の参照
データフローのラベルをデータ辞書と照合してください。辞書で定義されたデータ構造が、図で移動しているデータと一致していることを確認します。たとえば、辞書で「顧客ID」を文字列として定義しているのに、フローが数値を意味している場合は、不整合が生じています。
一貫性の確認
複数の図にわたって一貫性を確認します。プロセスがレベル1の図に存在する場合、そのプロセスに流入・流出するデータフローは、レベル2の分解図のフローと一致している必要があります。ここでの不一致は論理的な穴を示しています。
分析におけるデータストアの役割 🗃️
データストアはしばしば見過ごされがちですが、システムの状態を表しています。それらを理解することは、データガバナンスと整合性にとって不可欠です。
読み取りと書き込み操作
データストアへのすべての接続が同じではありません。一部のプロセスはデータを単に読み取るだけ(例:「履歴表示」)ですが、他のプロセスはデータを書き込みまたは更新します(例:「注文保存」)。従来のDFDでは両者に同じ線を使用しますが、この違いを理解しておくと、後のデータベース設計に役立ちます。読み取り専用のストアでは、特定のユーザーに書き込み権限は不要です。
一時的保存と永続的保存
一時的なバッファと永続的なアーカイブを区別します。一時的なストアはバッチ計算中にデータを保持する可能性がありますが、永続的なストアはコンプライアンスのためにデータを保持します。この違いはセキュリティ要件や保持ポリシーに影響を与えます。
DFDの有用性に関する結論 🚀
データフロー図は、ビジネス分析における永遠のツールです。実装の詳細によるノイズを排除し、情報の本質的な流れを明らかにします。コンポーネント、バランス、命名に関する厳格なルールに従うことで、分析者はシステム開発の信頼できる設計図となるモデルを作成できます。
ビジネス分析の成功は明確さにかかっています。適切に構築されたDFDがその明確さを提供します。ステークホルダーを一致させ、開発者を導き、最終的なシステムが意図した通りに動作することを保証します。正しく使用されるとき、DFDは単なる図ではなく、ビジネスニーズと技術的ソリューションの間の契約です。
データに注目する。境界を尊重する。フローを検証する。この厳格なアプローチにより、時間と変化に耐える図が得られます。