











ソフトウェアエンジニアリングの複雑な環境において、明確さが価値となる。アーキテクトや技術文書作成者は、ステークホルダーをコードや設定ファイルの海に溺れさせることなく、データがシステム内でどのように移動するかを伝えるという課題に直面することが多い。ここにデータフローダイアグラム(DFD)の重要性が現れる。DFDをアーキテクチャドキュメントに統合することで、抽象的な論理と具体的な実装の間のギャップを埋め、開発者、プロダクトマネージャー、監査担当者がすべて理解できる視覚的言語を提供する。
このガイドでは、データフローダイアグラムをアーキテクチャ記録に埋め込むメカニズムについて解説する。基礎的な概念、統合プロセス、保守戦略、およびドキュメントが信頼できる真実の源として機能し続けるためのベストプラクティスを網羅する。これらの方法に従うことで、システムの進化を支援する動的なドキュメントを作成でき、静的なレリックスに終わらせることを防げる。
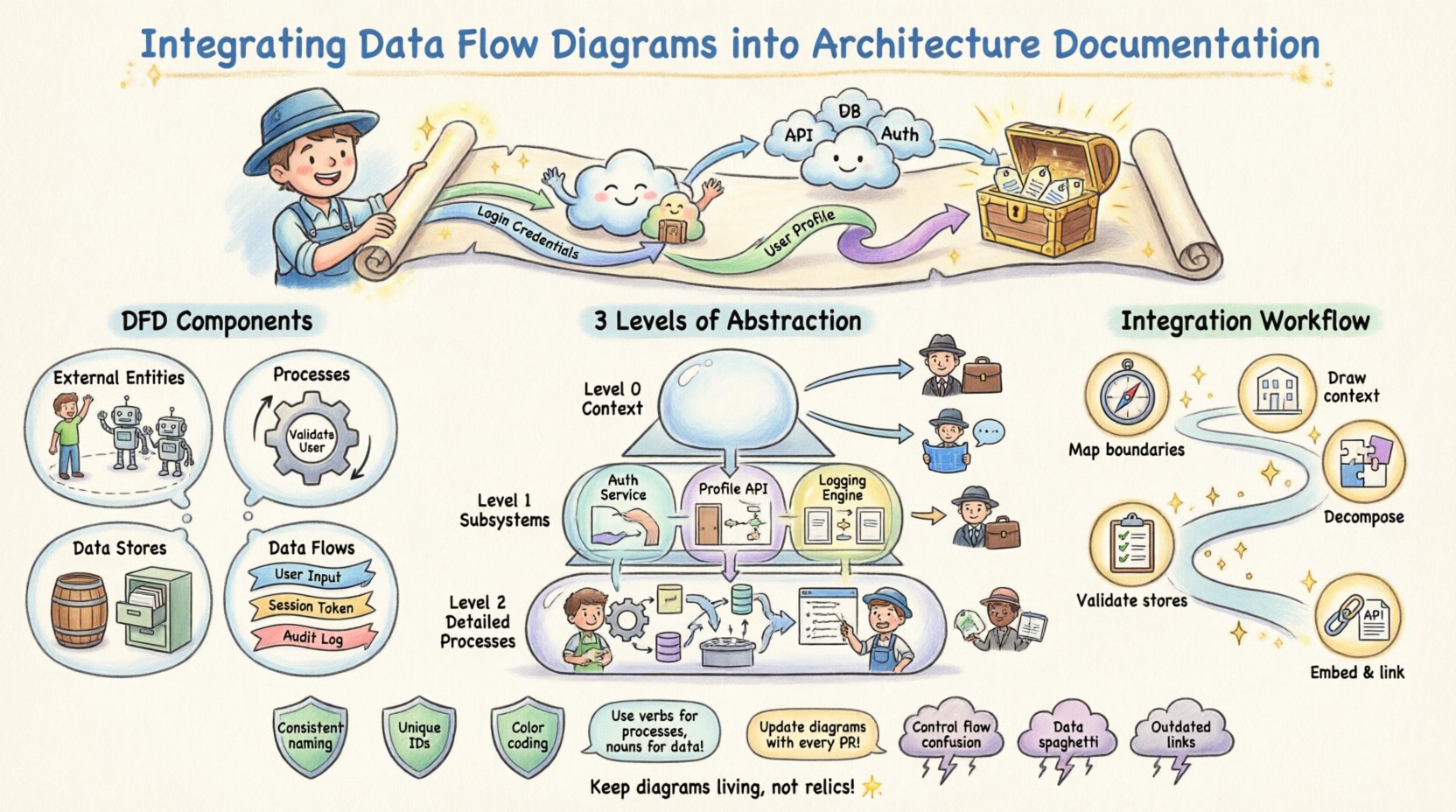
🤔 システム設計におけるデータフローダイアグラムの理解
データフローダイアグラムは、システム内を流れている情報の流れを表す。フローチャートとは異なり、フローチャートは制御フローと決定論理に注目するが、DFDはデータの移動にのみ焦点を当てる。データがどこから来ているか、どのように変換されるか、どこに保存されるか、そして最終的にどこから出るかを示す。この違いは、アーキテクチャドキュメントにおいて極めて重要であり、アプリケーションの情報的基盤を、それを実行する手続き的論理から分離するからである。
アーキテクチャパッケージにDFDを含めることで、システムの認知的負荷の地図を提供していることになる。ステークホルダーは、下層のコード論理を理解しなくても、データの取り込みから保存、取得までを追跡できる。この抽象化は、上位レベルの意思決定やコンプライアンス監査において不可欠である。
- 外部エンティティ:システムとやり取りするが、システムの境界外に存在するユーザー、システム、または組織を表す。
- プロセス:データに対して行われる変換や計算。これらはコード関数ではなく、論理的な操作である。
- データストア:データが一時的に保管されるリポジトリ。データベース、ファイルシステム、ログなどが含まれる。
- データフロー:エンティティ、プロセス、ストアの間を移動するデータの流れ。通常、転送されるデータの名前でラベル付けされる。
これらのコンポーネントを明確に定義することで、一貫した語彙を確立できる。これにより、エンジニアがシステムの振る舞いについて議論する際の曖昧さが減少し、「ユーザーのプロフィールデータ」という表現が、バックエンド、フロントエンド、ドキュメントのすべてで同じエンティティを指すことを保証する。
📈 DFDがアーキテクチャドキュメントにおいて重要な理由
DFDを統合することは、単に絵を描くことではない。ドキュメントそのものの有用性を高めることにある。適切に構成されたDFDは、アーキテクチャドキュメントにおいていくつかの重要な領域に具体的な価値をもたらす。
🔍 情報伝達の向上
視覚モデルは、システム間の相互作用を理解するために必要な認知的負荷を軽減する。テキストによる記述は、データ交換の双方向性をうまく捉えられないことが多い。図では方向性が即座にわかる。新しい開発者がプロジェクトに参加した際、リポジトリに飛び込む前にDFDを見て、高レベルのデータトポロジーを理解できる。
🛡️ セキュリティおよびコンプライアンス監査
規制対象業界では、データのルートを追跡することが必須である。DFDは、機密データがどこに保存されているか、プロセス間をどのように流れているかを明示的に示す。これにより、暗号化されていないデータ転送や、データストアへの不正アクセスポイントといった潜在的なセキュリティ脆弱性を特定しやすくなる。
🔄 システムへの導入
視覚的補助資料が利用可能になると、オンボーディング時間が短縮される。数百ページにわたるAPI仕様書を読む代わりに、新規メンバーは1時間程度でシステムのフローを把握できる。これにより、エンジニアリソースの生産性向上までの時間が早まる。
📂 抽象度のレベル:コンテキスト、レベル0、レベル1
効果的なアーキテクチャドキュメントは、単一の図に依存しない。代わりに、異なる対象者に適切な詳細レベルを提供するために、DFDの階層構造を用いる。この階層的なアプローチにより、情報過多を防ぎつつ、必要な粒度を維持できる。
| 図のレベル | 注目点 | 対象読者 | 使用ケース |
|---|---|---|---|
| コンテキスト図(レベル0) | 外部エントリと相互作用する単一のプロセスとしてのシステム。 | 経営関係者、プロダクトマネージャー | 高レベルの範囲定義と境界の特定。 |
| レベル1図 | 主要なサブシステムと主要なデータストア。 | システムアーキテクト、リード開発者 | 主要な機能ブロックおよびデータ保存の理解。 |
| レベル2図 | 特定の複雑なプロセスへの詳細な調査。 | バックエンドエンジニア、QAスペシャリスト | 実装の詳細および特定のデータ変換。 |
これらの図を文書化に統合する際は、各レベルが明確にラベル付けされていることを確認してください。高レベルの概要に詳細な情報を混在させないでください。コンテキスト図は内部プロセスを一切表示してはいけません。システム境界のみを示す必要があります。この規律により、抽象化の整合性が保たれます。
🔄 ステップバイステップの統合ワークフロー
DFDの統合は一度きりのイベントではありません。開発ライフサイクルと並行して実行されるワークフローです。以下に、これらの図を効果的に埋め込むための構造化されたアプローチを示します。
1. データ境界の特定
描画する前に、範囲を定義してください。システムに含まれるのは何ですか?外部のものは何ですか?すべての外部エントリ(ユーザー、サードパーティAPI)と内部データストアをリストアップしてください。このリストが図のインベントリになります。
2. 高レベルのフローのマッピング
まずコンテキスト図を作成してください。システムを中央の円またはボックスとして描画します。すべての外部エントリを矢印でこの中心に接続します。各矢印に、交換されている具体的なデータペイロード(例:「ログイン資格情報」、「請求書データ」、「ユーザー情報更新」)をラベル付けしてください。
3. プロセスの分解
コンテキスト図の中心プロセスを取り出し、サブプロセスに分解します。これによりレベル1図が作成されます。上位レベルからのすべてのデータフローが下位レベルで対応されていることを確認してください。以前に省略されていた場合を除き、この段階で新しい外部エントリを導入しないでください。
4. データストアの検証
すべてのデータストアを確認してください。読み取り専用ですか?書き込み専用ですか?データは永続化されますか?これらの属性をアーキテクチャノートに図と一緒に記録してください。これにより、データの永続性に関する誤解を防ぎます。
5. 埋め込みとリンク
図を文書化リポジトリ内に配置してください。ハイパーリンクを使用して、図を関連するAPI仕様やデータベーススキーマに接続してください。プロセスが変更された場合は、図と関連する文書を同時に更新してください。
🛡️ 明確性と一貫性のためのベストプラクティス
DFDが長期間にわたり有用であることを保証するため、厳格な表記法および命名規則の遵守が求められます。不一致は混乱を招き、図の目的を無効にします。
- 一貫した命名規則:ラベルには標準的なフォーマットを使用してください。たとえば、プロセスには常に動詞を使用(例:「ユーザー検証」)、データフローには常に名詞を使用(例:「ユーザー入力」)してください。同じ図内で動詞と名詞のスタイルを混在させないでください。
- 一意なプロセス識別:プロセスを順次番号を付けてください。これにより、コードレビュー中に特定の変換を参照する際に役立ちます(例:「プロセス3.1をレビュー」)。
- 交差を最小限に抑える: 要素の配置を工夫して線の交差を最小限に抑えるようにしてください。線がどうしても交差する場合は、接続していないことを示すためにブリッジ記法を使用してください。これにより、可読性が大幅に向上します。
- 論理的なグループ化: 関連するプロセスを視覚的にまとめて配置してください。たとえば、3つのプロセスが支払いを処理している場合は、クラスタとして配置します。これにより、読者は機能領域を一目で理解できます。
- 色分け: 異なるデータタイプやセキュリティレベルを区別するために、繊細な色の違いを使用してください。たとえば、機密データの流れには赤い枠線、公開データには緑の枠線を使用します。
ドキュメントは読者が事前に知識を持っていることを前提にしてはいけません。すべての矢印、ボックス、ラベルは、自明であるか、ドキュメント内の用語集にリンクされている必要があります。
🧹 メンテナンスとバージョン管理戦略
コードと一致しない図は、まったく図がないよりも悪いです。誤った安心感を生み出し、エンジニアを誤導します。したがって、メンテナンスはDFD統合において最も重要な段階です。
📝 バージョン管理
すべての図のフッターにバージョン番号を含めてください。図のバージョンをソフトウェアのリリースバージョンと紐づけます。機能が非推奨になった場合は、古い図を削除するのではなくアーカイブしてください。これにより、将来のデバッグに備えてデータフローの変更履歴を保持できます。
🔄 変更管理
DFDの更新をプルリクエストワークフローに統合してください。開発者がデータストアを変更するか、新しいAPIエンドポイントを追加する際は、対応するDFDを更新しなければなりません。これにより、ドキュメントが「完了の定義」の一部になることを保証します。
📅 定期的な監査
アーキテクチャドキュメントを四半期ごとにレビューするスケジュールを設定してください。指定されたアーキテクトが、現在のコードベースと図を一緒に確認する必要があります。不一致が見つかった場合は、すぐにログに記録し、修正しなければなりません。
⚠️ 共通の落とし穴とその回避方法
経験豊富なアーキテクトですら、データフローのモデル化においてミスを犯すことがあります。これらの落とし穴を早期に認識することで、数週間分のリファクタリングと混乱を回避できます。
| 落とし穴 | 結果 | 緩和戦略 |
|---|---|---|
| 制御フローの混同 | 図が、データしかない場所に論理があるように示している。 | 矢印が実行パスではなくデータを表していることを確認してください。論理については、制御フローダイアグラムを使用してください。 |
| データスパゲッティ | 線が多すぎて、図が読めなくなる。 | 複雑さを解消するためにサブプロセスを使用する。関連するフローをグループ化する。 |
| データストアの欠落 | 明示的な保存がないにもかかわらず、データが永続化すると仮定している。 | すべてのデータストアを明確に定義してください。メモリ内のバッファが保存としてカウントされるとは仮定しないでください。 |
| 古くなった参照 | 存在しなくなったプロセスへのリンク。 | コードのマージ時に厳格なレビュー過程を導入する。 |
もう一つの一般的な誤りは過剰な分解である。単純なCRUD操作に対してレベル2の図を描くと、スペースを無駄に使う。複雑な論理を明確にする必要がある場合にのみプロセスを分解するべきである。プロセスが1行のコードで理解できるなら、高レベルのままにしておく。
🔗 DFDを他のアーキテクチャ資産と接続する
DFDは孤立して存在するものではない。他のドキュメント形式と相互作用して、包括的なアーキテクチャ像を形成する。それらを統合することで、一貫性のある物語が生まれる。
- エンティティ関係図(ERD): DFDはデータの移動方法を示す。ERDはデータの構造を示す。DFD内のデータストアを、ERD内の対応するテーブルにリンクする。
- API仕様書: APIエンドポイントをデータフローにマッピングする。フローが「注文を提出」とラベル付けされている場合、API仕様書にはその提出を担当するエンドポイントが含まれているべきである。
- デプロイメント図: データストアが物理サーバーかクラウドバケットかを示す。これによりインフラチームは、データフローによって示唆される負荷分散を理解できる。
- セキュリティポリシー: 敏感なデータフローを暗号化基準と照合する。フローがネットワーク境界を越える場合、必要な暗号化プロトコルを明記する。
これらの資産を統合することで、真実のネットワークが構築される。DFDを読んでいるエンジニアは、API仕様書、データベーススキーマ、最終的にデプロイ構成にリンクをクリックして移動できる。これにより開発中のコンテキストスイッチの摩擦が軽減される。
🚀 ドキュメントの整合性についての最終的な考察
DFDを統合する目的は、初日から完璧な図を描くことではない。プロジェクトライフサイクル全体を通して、データがどのように認識され、管理されるかの標準を確立することである。ドキュメントがコードと共に進化するとき、それは歴史的な資料ではなく、生きているツールとなる。
完璧さよりも一貫性に注力する。常に最新の、わずかに簡略化された図は、陳腐化したハイパーディテールな図よりも価値が高い。ここに示されたワークフローと基準に従うことで、アーキテクチャドキュメントがチームに効果的に貢献し、エラーを減らし、納品を加速させることを保証できる。