











堅牢なシステムモデルを作成するには、情報がどのように収集され、移動され、保持されるかについて、厳密なアプローチが必要です。データフローダイアグラム(DFD)の文脈において、データストアはシステムの永続性の基盤を表します。データがどこに存在するかを明確に設計しない限り、情報の流れは抽象的で実装不可能なままになります。このガイドでは、DFD内のデータストアを設計する際の基本原則を検討し、明確性、正確性、およびシステムアーキテクチャとの整合性を確保します。
効果的なモデリングは、図形の間に線を引くこと以上のことです。データの整合性、アクセスパターン、システム内の情報のライフサイクルについて深い理解が求められます。確立された設計原則に従うことで、アナリストは開発チームにとって信頼できる設計図となる図を生成できます。
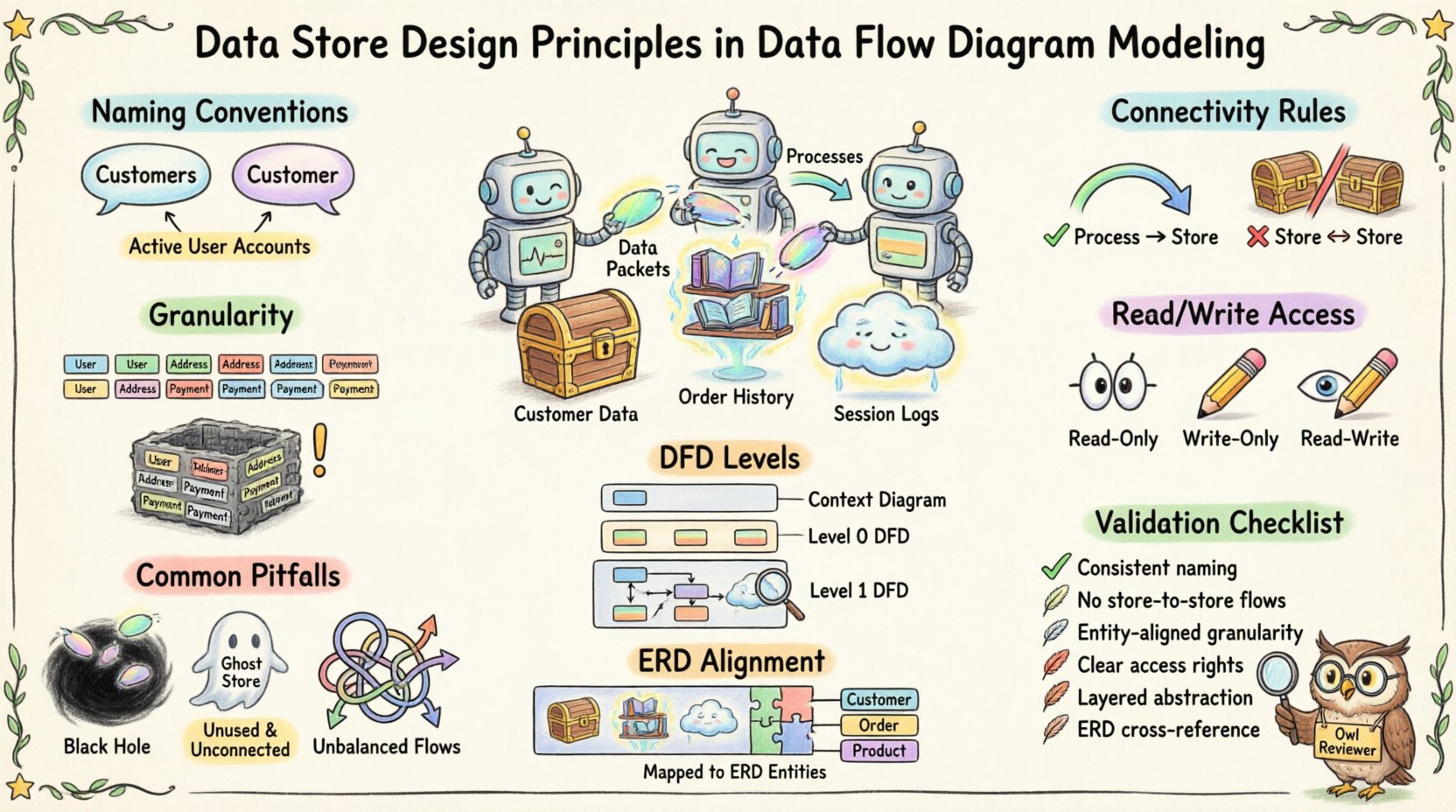
🏷️ データストアの定義 🏷️
データストアは、データフローダイアグラムにおける受動的な要素です。データを変換するプロセスとは異なり、データストアは静止したデータを保持します。ファイル、データベース、紙の記録、または情報が後で取得できるように保存されるあらゆるリポジトリを表します。
- 受動的性質:プロセスが明示的に要求しない限り、データはストアから流れ出ることはありません。
- 保存領域の性質:それはプロセスそのものではなく、データを変更するのではなく保持するものです。
- 視覚的表現:使用される表記規則に応じて、通常は開口部のある長方形または二重の垂直線で表現されます。
これらの要素を設計する際には、物理的実装ではなく論理的要件に注目しなければなりません。DFDは「何」のデータが必要かを記述するものであり、「どのように」ハードディスク上に物理的にインデックス付けまたは保存されるかを記述するものではありません。何のデータが必要かを記述するものであり、どのようにハードディスク上に物理的にインデックス付けまたは保存されるかを記述するものではありません。
📝 明確性のための命名規則 📝
命名は混乱に対する最初の防衛線です。曖昧なラベルは設計段階で誤解を招きます。適切に命名されたデータストアは、含まれる情報について即座に文脈を提供します。
1. 単数形 vs. 複数形
一貫性が鍵です。一部のチームは単数名詞(例:顧客)を好む一方、他のチームは複数形(例:顧客たち)を使用します。重要なのは、全体のモデルで同じ規則を使用することです。
- 推奨:データの集合には複数形の名詞を使用してください(例:注文, 製品)とすることで、集合を示すことができます。
- 例外:単数名詞は、ストアが1つのレコードタイプしか保持しない場合、特定のインスタンスに適しています(例:設定).
2. 説明の正確性
次のような一般的な用語を避けてください:データ または 情報。これらのラベルはコンテンツについてまったく情報を提供しません。
- 悪い例: システムデータ
- 良い例: アクティブなユーザー アカウント
具体的な命名は、関係者があっという間にストアの範囲を特定できるようにします。図の理解に必要な認知的負荷を軽減します。
3. 時制と状態
名前はデータの状態を反映すべきです。ストアが履歴記録を保持している場合、名前もそれを反映すべきです。
- 取引ログ過去の出来事の記録を意味します。
- 保留中の注文処理を待っているデータを意味します。
🔗 接続ルール 🔗
データがストアに入り、出る動きは厳密な論理ルールによって制御されます。これらのルールに違反すると、DFDの整合性が損なわれます。
1. プロセス接続要件
データストアは常に少なくとも1つのプロセスに接続されている必要があります。孤立して存在することはできません。
- 入力: プロセスはストアにデータを書き込む必要があります(例:新しいレコードの保存)。
- 出力: プロセスはストアからデータを読み取る必要があります(例:レコードの取得)。
ストアが何にも接続されていない場合、それは機能のないゴースト要素です。複数のプロセスに接続されている場合、各接続におけるデータの流れは明確に定義されている必要があります。
2. ストア間の直接的なデータフローは禁止
データは、プロセスを介さずに、1つのデータストアから別のデータストアへ直接移動することはできません。このルールは、データの変換や検証が保存の前に行われることを強制する原則を適用します。
- 誤り:接続するライン:ストアA直接ストアB.
- 正しい: プロセスXから読み込みストアA、データを変換し、ストアB.
この分離により、データが永続化される前に、ビジネスロジック、検証、フォーマットが適用されることが保証されます。これにより、データが監視なしに単にコピーされているように見えることを防ぎます。
3. データフローのラベル付け
プロセスとデータストアを結ぶすべてのラインにはラベルを付ける必要があります。ラベルは、その境界を越えて移動する特定のデータを説明します。
- 例: ラインは注文プロセスから注文ストアにラベルを付ける可能性があります注文詳細.
- 例: ラインは注文ストアからレポート処理はラベル付けされる可能性がある注文履歴.
ラベルは、転送中のデータの量と種類に関する文脈を提供します。開発者が後でスキーマ要件を理解するのを助けます。
🎯 精細度と範囲 🎯
データをストアにどのように分割するかは、重要な設計意思決定です。ストアが多すぎるとモデルが分散し、少なすぎると情報の巨大な単一ブロックが生じます。
1. エンティティベースのグループ化
データを論理的なエンティティごとにグループ化する。システムが顧客、製品、請求書を追跡している場合、これらは一般的に別々のストアに配置すべきである。
- 利点:保守を簡素化する。顧客データの変更は請求書のストレージロジックに影響しない。
- 利点:更新中の誤ったデータ破損のリスクを低減する。
2. 読み書きの分離
ストアが主に読み取り用か書き込み用かを検討する。大量のトランザクションログは、参照データと異なるストレージ処理を必要とする場合が多い。
- 参照データ: 例えば 国コードは読み取りが主で、ほとんど変更されない。
- トランザクションデータ: 例えば 売上ログは書き込みが主で、時間とともに増加する。
これらの種類を区別することは、容量とアクセスパターンの計画に役立つが、DFDは論理モデルのままである。
3. 一時的 vs. 永続的
すべてのデータストアが永続的な保持を意味するわけではない。一部は一時的なバッファである。
- セッションデータ:ログインプロセス中の一時的なユーザー セッションに使用されるストア。
- キャッシュストア:頻繁にアクセスされるデータの一時的な保管領域。
一時的なストアを明確にマークすることで、データ保持ポリシーに関する混乱を防ぐことができます。プロセスが完了したら、一時的なストアは空にするか、クリアする必要があります。
🔄 データフローとプロセスの相互作用 🔄
プロセスとデータストアの関係は多くの場合双方向的ですが、常にそうとは限りません。方向性を理解することは、正確なモデル化に不可欠です。
1. 読み取り専用アクセス
一部のストアは読み取りのみでアクセスされます。プロセスは情報を表示するためにストアを照会するが、それを変更することはありません。
- 例: A プロファイル表示 プロセスが以下から読み取りを行う:ユーザー・プロファイル・ストア.
- 制約:同じトランザクションにおいて、ストアからプロセスへ、そしてその逆方向にデータフローの矢印が存在するべきではない。ただし、書き込み操作を意味する場合は除く。
2. 書き込み専用アクセス
一部のプロセスは、データを取得する前に書き込むことができます。
- 例: An イベントログ プロセスが以下に書き込みを行う:システム監査ストア.
- 制約:外部からの入力なしで、プロセスがデータを正しく書き込むために必要なコンテキストを持っていることを確認する。
3. 読み書きアクセス
ほとんどのビジネスプロセスは、データの取得、変更、保存を含みます。
- 例: 在庫更新現在の在庫を読み取り、新しい数量を計算し、保存する。
- モデリング:読み取りと書き込みのための別々のフローを使用して、操作の順序を明確にする。
この区別は、開発者がデータベーストランザクションがロックを必要とするか、直ちにコミットを必要とするかを理解するのを助けます。
📊 DFDのレベルとデータストアの可視性 📊
DFDはしばしばレベルに分解され、コンテキスト図(レベル0)から詳細な分解(レベル2、レベル3)まで行われます。各レベルでデータストアの表示方法が異なります。
1. コンテキストレベル(レベル0)
最も高いレベルでは、簡潔さを保つためにデータストアがしばしば省略されます。注目点は外部エンティティとメインシステムの境界です。
- 理由:あまりに詳細な情報は、高レベルのデータ交換を曖昧にします。
- 例外:システム境界にとって重要な場合、主要な外部データベースが表示されることがあります。
2. レベル1の分解
システムが主要なプロセスに分解されるにつれて、データストアが可視化されます。ここでは主なストレージアーキテクチャが定義されます。
- 注目点:各主要機能に必要なコアリポジトリを特定する。
- 詳細:すべてのプロセスが出力データの宛先を持っていることを確認する。
3. レベル2以降
さらなる分解により、大きなデータストアがより小さく、より具体的なストアに分割されることがあります。
- 例: 顧客ストア レベル1では、連絡先情報ストア と請求情報ストア レベル2に分割されることがあります。
- 一貫性:低いレベルのデータが、高いレベルのデータと一致していることを確認する。親図に存在しなかった新しいデータ型を導入してはならない。
⚠️ 一般的な落とし穴 ⚠️
経験豊富なアナリストですら、データストアを設計する際に誤りを犯すことがあります。これらの一般的な誤りを避けることで、図が正確なまま保たれます。
- ブラックホール:データを入力するが、どこにも書き込まないプロセス。これはデータ損失を意味します。
- 火災状態:データを入力するが、ストアを経由せずにデータを出力するプロセス。これは、データが何からも生成されている(奇跡)ことを意味する。
- 幽霊ストア:接続するプロセスのないデータストア。これらは行き止まりである。
- バランスの取れていないフロー:レベル1からレベル2に移行する際、入力と出力は一致している必要がある。レベル2にストアを追加する場合は、親プロセスの入力/出力によって正当化されなければならない。
- 過剰設計:データベースのすべてのテーブルをレベル1の図で個別のストアとしてモデル化しようとする。物理的なテーブルではなく、論理的なエンティティに焦点を当てるべきである。
📚 データモデルとの整合性を保つ 📚
DFDは流れに注目するが、エンティティ関係図(ERD)または論理データモデルと整合性を持たなければならない。DFD内のデータストアは、ERD内のエンティティに対応しているべきである。
- 整合性の確認: DFDに「製品ストア」がある場合、ERDには「製品」エンティティが存在するべきである。
- 属性のマッピング:プロセスがストアとやり取りするために必要な属性は、データモデル内に存在しなければならない。
- 正規化:DFDは正規化を強制しないが、設計は明白な重複を避け、悪いデータベース設計を示唆するものにしてはならない。
この整合性により、論理設計(DFD)が物理的実装(データベーススキーマ)に変換される際に、大幅な再作業を回避できることが保証される。
🔍 デザイン検証チェックリスト 🔍
データフローダイアグラムを最終化する前に、以下のチェックリストを使用してデータストア設計の妥当性を検証する。
| 原則 | チェックリスト項目 | 状態 |
|---|---|---|
| 命名 | すべてのストア名は説明的で一貫性があるか? | ☐ |
| 接続性 | すべてのストアが少なくとも1つのプロセスに接続されていますか? | ☐ |
| 流れの方向 | 矢印がプロセスとストアの間で正しい方向を指していますか? | ☐ |
| ラベル付け | データがコンテンツ名でラベル付けされた線を通過していますか? | ☐ |
| ストア同士の直接リンク禁止 | ストア同士を直接結ぶ線はありますか? | ☐ |
| 一貫性 | 下位レベルのストアは親レベルの範囲と一致していますか? | ☐ |
| 整合性 | 利用可能なストアがプロセスのすべてのデータ要件を満たしていますか? | ☐ |
🔄 メンテナンスと進化 🔄
システム要件は変化する。データストアはモデルを破壊せずにこれらの変化に適応できる必要がある。
- バージョン管理:ストア定義の変更を追跡する。ストアが分割された場合は、移行経路を文書化する。
- レガシーデータ:ストアスキーマが変更されたときに古いデータをどのように扱うかを計画する。これにはしばしばアーカイブストアが必要になる。
- フィードバックループ:開発チームからのフィードバックを活用してストアの粒度を最適化する。開発者がストアの範囲が広すぎると思う場合は分割し、逆に細切れすぎると感じる場合は統合する。
静的なモデルは負債である。ビジネスルールが変更されたときや新しいコンプライアンス要件が導入されたときは、データストア設計を常に見直す必要がある。これによりDFDが常にシステムのデータニーズを正確に反映する動的な文書のまま保たれる。
📝 実装に関する結論
データフローダイアグラムにおけるデータストアの設計は、システム分析の基盤となる作業である。抽象的なプロセスと具体的なデータ永続化の間のギャップを埋める。厳格な命名規則、接続ルール、粒度の原則に従うことで、読みやすく、実行可能なモデルを作成できる。
目標はデータベーススキーマを完璧に再現することではなく、データ保存の論理的必要性を捉えることである。DFDが正確であれば、開発への移行がスムーズになり、データ損失や不整合のリスクが大幅に低下する。明確さ、一貫性、情報の論理的流れに注目することで、高品質なシステム設計を生み出す。