








正確なプロジェクト見積もりは、成功したソフトウェア開発の基盤です。システムを計画する際、データの流れを理解することで、リソース要件を予測するための明確な基盤が得られます。データフローダイアグラム(DFD)は、これらの流れを可視化する強力なツールです。DFDの構造的複雑さを分析することで、機能要件にのみ依存するよりも、より信頼性の高い作業量推定が可能になります。
本ガイドでは、DFDの複雑さ指標を活用して作業量推定を精緻化する方法を探ります。複雑さを引き起こす要因、これらの要素を定量化する手法、図式分析をプロジェクトスケジュールに変換するプロセスについて検討します。
🔍 計画におけるデータフローダイアグラムの理解
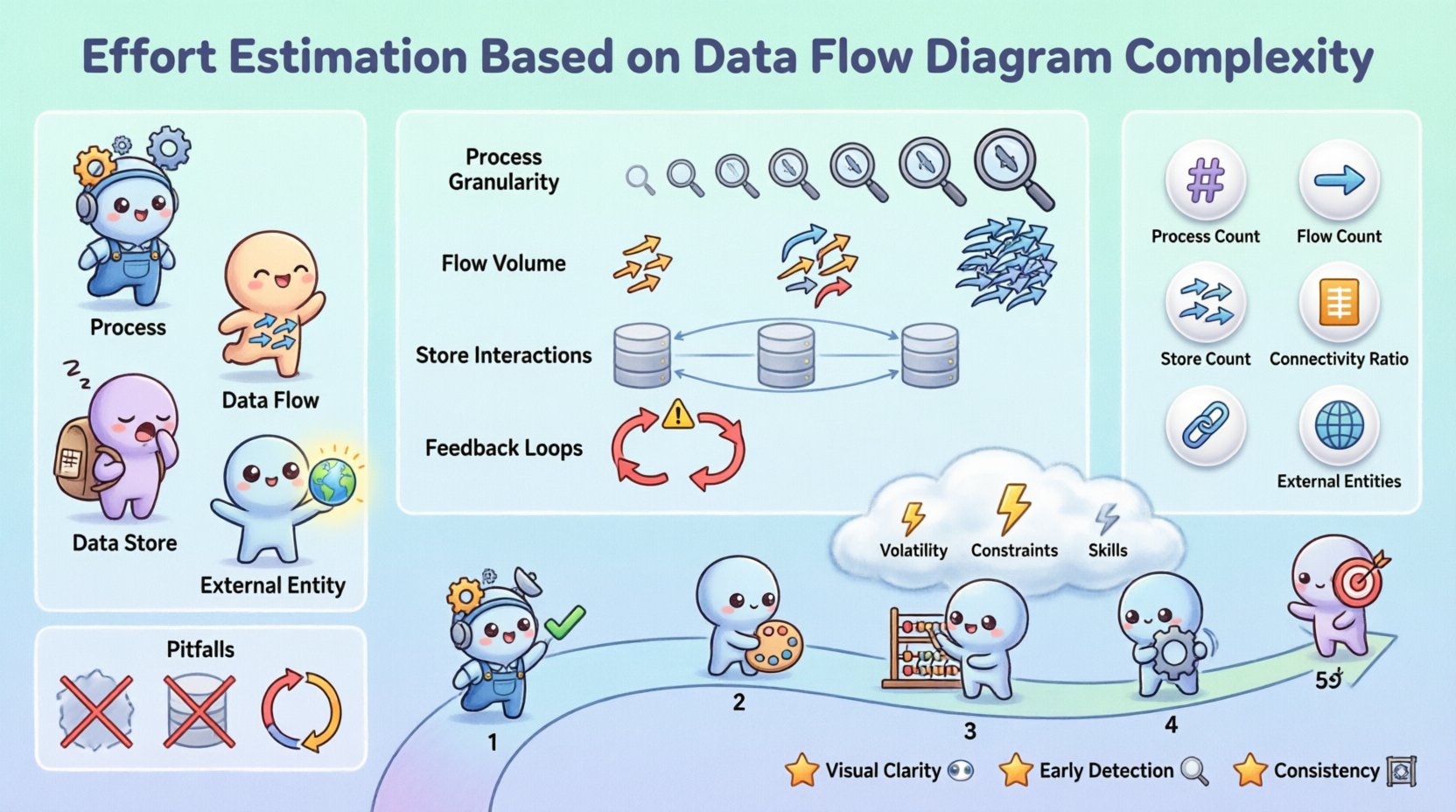
データフローダイアグラムは、情報システム内を流れるデータの流れを図式的に表現したものです。フローチャートが制御論理に注目するのに対し、DFDはデータ変換に注目します。見積もりの文脈では、DFDは関与する作業の設計図として機能します。
- プロセス:データの変換を表します。各プロセスは通常、コード内の特定の関数やモジュールに対応します。
- データフロー:プロセス、ストア、エンティティ間のデータの移動を示します。これらはインターフェースや統合ポイントを表します。
- データストア:データが静止している場所を示します。これらはデータベースのテーブルやファイルシステムに対応します。
- 外部エンティティ:システム外のデータの発信元または受信先です。これらは統合要件を定義します。
作業量を推定する際、これらの要素の視覚的密度と接続性は、システムを実装するために必要な認知負荷の程度を示す手がかりになります。シンプルで線形的なフローを持つ疎な図は低複雑性を示す一方、密集した相互作用のネットワークは、大きな統合課題を示唆します。
🏗️ 複雑さの要因の特定
すべてのデータフローが同じではありません。一部は単純なフィールド転送を表す一方、他のものは複雑なビジネスロジック、検証、セキュリティプロトコルを含みます。正確な見積もりを行うためには、図内での複雑さを高める具体的な要因を特定する必要があります。
1. プロセスの粒度
プロセスの詳細度は重要です。「注文処理」のような高レベルのプロセスは、数十のサブステップを隠している可能性があります。DFDが高レベルの場合、そのプロセスの分解を見積もりに反映させる必要があります。逆に、レベル2やレベル3の詳細なDFDは、実際の作業単位を明らかにします。
- 粗い粒度のプロセス:分解に時間がかかる。
- 細かい粒度のプロセス:より直接的な見積もりが可能だが、統合のオーバーヘッドを見逃す可能性がある。
2. データフローの量
要素をつなぐ矢印の数は、データ処理の量を示します。各矢印は、検証、変換、保存または送信が必要なデータ構造を表します。
- 多くのフローは、多くのAPIエンドポイントやデータベースクエリを意味します。
- 複雑なフローは、エラー処理や再試行ロジックを必要とする場合があります。
3. データストアとのインタラクション
データストアとのすべてのインタラクションは、レイテンシの考慮、同時実行の問題、スキーマ管理をもたらします。複数のストアに同時に読み書きを行うプロセスは、単一のストアとやり取りするプロセスよりも複雑です。
4. フィードバックループ
図内のループは、反復処理や状態の変化を示します。これらは開発における最もエラーが発生しやすい領域です。ループの見積もりには、複数のサイクルにわたって状態が保持されるテストシナリオを考慮する必要があります。
📏 評価のための定量的指標
定性的な観察から定量的な推定へ移行するためには、DFDから導き出された特定の指標を適用することができる。これらの指標は、異なるプロジェクト間で推定プロセスを標準化するのを助けます。
| 指標 | 説明 | 作業量への影響 |
|---|---|---|
| プロセス数 | 変換ノードの合計数。 | 機能点と直接相関する。 |
| フロー数 | データ移動矢印の合計数。 | 統合およびインターフェースの複雑さを示す。 |
| ストア数 | データリポジトリの合計数。 | データベース設計および移行作業に影響を与える。 |
| 接続性比 | フロー数とプロセス数の比。 | 高い比は、密結合されたシステムを示唆する。 |
| 外部エンティティ数 | 関与する外部システムの数。 | 通信および依存関係のリスクを増加させる。 |
これらの値を合計することで、複雑度スコアを作成できる。たとえば、単純なシステムはプロセスが5つ、フローが10つである可能性があるが、複雑なシステムではプロセスが50つ、フローが150つになることもある。このスコアは、過去のデータから決定されたベースラインの作業量係数を乗じて計算できる。
🛠️ 評価プロセス
DFDを作業量の推定に変換するには、構造的なアプローチが必要である。計画の整合性と正確性を確保するために、以下のステップに従う。
ステップ1:図の完全性を検証する
推定を行う前に、DFDが要件を正確に反映していることを確認する。フローまたはエンティティが欠落していると、推定が低く抑えられてしまう。すべてのデータ要件に対応するフローがあること、すべてのプロセスに明確な入力と出力があることを確認する。
ステップ2:プロセスの複雑度を分類する
すべてのプロセスが同じ作業量を要するわけではない。各プロセスの論理に基づいて、複雑度の重みを割り当てる。
- シンプル:直接的なデータマッピングまたは取得。 (重み:1)
- 中程度: 検証、計算、またはフォーマットを含む。(重み:2)
- 複雑: 複数のデータストア、外部API、または複雑なアルゴリズムを含む。(重み:3)
ステップ3:基本作業量を計算する
各カテゴリのプロセス数にそれぞれの重みを掛け合わせる。これらの値を合計して、基本複雑度スコア(BCS)を求める。
式: BCS = (シンプル数 × 1)+(ミディアム数 × 2)+(複雑数 × 3)
ステップ4:フロー複雑度に調整を加える
データフローの量が多いほど、インターフェース開発に必要な作業量が増加する。プロセス数に対する合計フロー数に基づいて、フローマルティプライヤーを適用する。
- 低比率(プロセス1つあたり≤2フロー): マルティプライヤー 1.0
- 中程度の比率(プロセス1つあたり3~5フロー): マルティプライヤー 1.2
- 高比率(プロセス1つあたり>5フロー): マルティプライヤー 1.5
ステップ5:外部依存関係を考慮する
外部エンティティはリスクをもたらす。各外部システムには統合テスト、セキュリティ設定、およびベンダーとの調整が必要となる。各外部エンティティに対して固定の時間バッファを追加する。
⚠️ リスクと不確実性への調整
詳細なDFDがあっても、不確実性は残る。要件の変更や技術的負債などの要因が、必要な作業量を変える可能性がある。これらのリスクを考慮して、見積もりを調整する。
1. 要件の変動性
開発中にビジネス要件が変更される可能性がある場合、DFDの大幅な見直しが必要になる可能性がある。そのような場合には、総作業量に15~20%の予備バッファを追加する。
2. 技術的制約
レガシーシステムや特定のインフラ要件は、データフローを複雑にする。DFDにデータがレガシーメインフレームへ移動していると示されている場合、その接続を処理する作業量は、標準的なAPI呼び出しよりも高くなる可能性がある。
3. チームのスキルレベル
見積もりは最低限の熟練度を前提としている。チームがその分野や技術スタックに不慣れな場合、DFDプロセスの複雑さが学習時間の増加につながる可能性がある。プロセス単位あたりの時間を適切に調整する。
🚫 DFD分析における一般的な落とし穴
一般的なミスを避けることは、見積もりの整合性を保つために不可欠である。いくつかの罠が、大きな誤算を引き起こす可能性がある。
- データ検証を無視する:DFDはデータの移動を示すが、それに適用されるルールは示さない。検証ロジックは、プロセス作業量の20~30%を占めることが多い。
- エラー処理を無視する: ハッピーパスは簡単にマッピングできる。エラーパス、リトライ、ログ記録は、すべてのフローに隠れた複雑性をもたらす。
- 線形成長を仮定して: 複雑さはしばしば非線形に増加する。1つのデータストアを追加するだけで、トランザクションの整合性の必要性から、接続の複雑さが指数関数的に増加する。
- セキュリティを無視する: 暗号化、認証、承認のレイヤーは、DFDではしばしば暗黙のうちに存在する。見積もりの際にこれらを明示的に考慮する必要がある。
- プロセスだけに注目する: データストアやデータフローのセットアップやテストは、プロセス自体よりも時間がかかることが多い。
📅 見積もりをプロジェクトスケジュールに統合する
努力量が計算されたら、それをスケジュールにマッピングしなければならない。これにはリソースの割り当てとマイルストーンの定義が含まれる。
- フェーズ別配信: データフローの依存関係に基づいてプロセスをグループ化する。リスクを低減するために、高優先度のフローを最初に配信する。
- 並行作業フロー: プロセスが独立している場合、並行して開発できる。DFDを使って独立したクラスタを特定する。
- 統合テスト: データフローの整合性をテストするための専用時間をスケジュールする。これは、複雑なDFDが失敗しやすい場所であることが多い。
図に示された構造的依存関係とスケジュールを一致させることで、システムの自然な流れを尊重する現実的なタイムラインを作成できる。
🔄 時間の経過に伴う正確性の維持
見積もりは静的ではない。プロジェクトが進展し、DFDが進化するにつれて、見積もりは再調整されるべきである。
- ベースラインの更新: DFDが最終化された時点で、初期の見積もりを実際の複雑さスコアで更新する。
- リトロスペクティブ分析: フェーズ終了後、見積もりされた複雑さスコアと実際に費やされた努力を比較する。これにより、将来のプロジェクトにおける重み付け要因が改善される。
- 変更管理: DFDに変更が加えられた場合は、再見積もりをトリガーすべきである。小さなフローを追加しても影響が無視できると仮定してはならない。
🛡️ DFDベースの計画に関する最終的な考慮事項
データフローダイアグラムを努力量の見積もりに使用することで、プロジェクトの規模を構造的かつ客観的に評価する方法が得られる。これは、推測から離れて、システムの実際のデータアーキテクチャの分析へと会話の方向を変える。
どんなモデルも完璧ではないが、DFDの複雑さアプローチには大きな利点がある:
- 視覚的明確さ:ステークホルダーはデータの移動を視覚的に確認でき、努力の根拠が透明になる。
- 早期検出: 複雑なフローはコーディングが開始される前に特定でき、アーキテクチャの調整が可能になる。
- 一貫性:異なるプロジェクトに同じメトリクスを適用することで、より良いポートフォリオ管理が可能になる。
完璧を目指すのではなく、情報に基づいた計画を立てることが目的であることを忘れないでください。複雑さの要因を定期的に見直し、基準を更新してください。チームが特定の種類のフローとプロセスに経験を積むにつれて、作業量を予測する能力は自然に向上します。
DFDを主な推定ツールとして扱うことで、構築しているシステムの本質的な性質と計画を一致させることができます。これにより、より現実的な予算やスケジュールが設定され、最終的にソフトウェアソリューションの成功裏な提供につながります。