











堅牢なマイクロサービスアーキテクチャを設計するには、コードを小さな部分に分割するだけでは不十分です。情報がシステム内でどのように移動するかを明確に理解することが求められます。構造的なアプローチがなければ、分散型システムは維持やスケーリングが困難な依存関係の複雑なネットワークになりがちです。このような状況で、データフローダイアグラム(DFD)はアーキテクトにとって不可欠なツールとなります。データの動きを可視化することで、チームはサービスの境界を正確に定義し、プラットフォーム全体でデータロジックの整合性を保つことができます。
本ガイドでは、マイクロサービスの実装における計画段階でDFDをどのように活用するかを検討します。図の階層構造、重要な境界の特定、データ所有権の管理戦略について考察します。その目的は、明確さと保守性を重視した、体系的なシステム設計のフレームワークを提供することです。
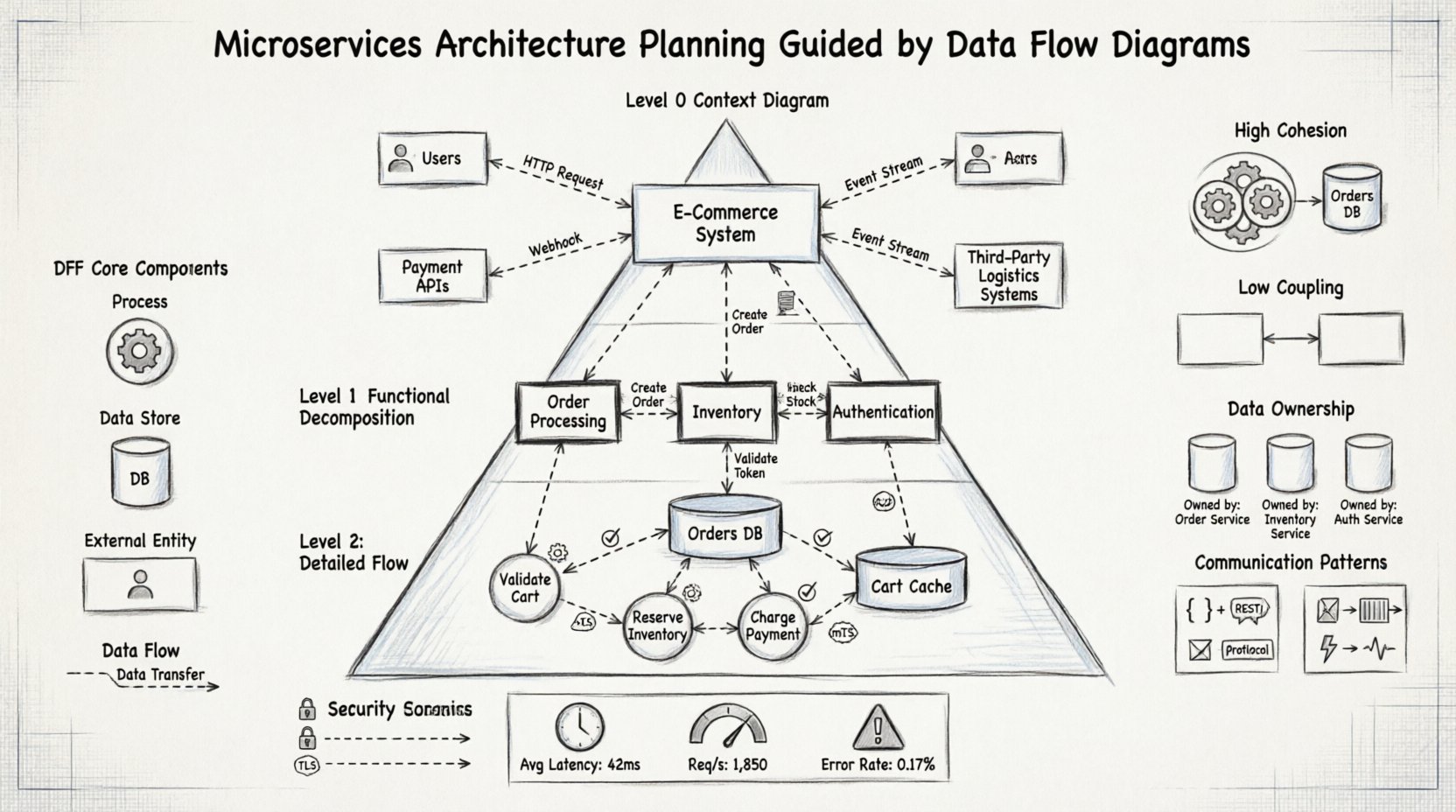
🧩 分散システムにおけるDFDの役割を理解する
データフローダイアグラム(DFD)は、システム内の情報の流れを表します。フローチャートが制御フローと判断論理に注目するのに対し、DFDはデータの変換と保存に重点を置きます。マイクロサービスの文脈では、この違いは非常に重要です。マイクロサービスは本質的に独立した処理ユニットであり、データをやり取りします。このやり取りを視覚的にマッピングすることで、ステークホルダーは変更の影響を理解しやすくなります。
DFDの核心的な構成要素
DFDをアーキテクチャに適用する前に、使用される基本的な記号を理解しておく必要があります:
- プロセス:データの変換を表します。マイクロサービスでは、これらは特定のサービス機能やAPIに対応することが多いです。
- データストア:データが静止状態で保持される場所です。これらはデータベース、キャッシュ、またはファイルシステムに対応します。
- 外部エントリ:システム外のデータの発信元または受信先です。ユーザー、サードパーティシステム、またはレガシーアプリケーションを含みます。
- データフロー:プロセス、ストア、エントリ間でのデータの移動を表します。これらはサービス間のネットワークトラフィックやメッセージキューを意味します。
📊 計画図の階層構造
包括的なアーキテクチャ計画には、複数の抽象化レベルが必要です。高レベルの概要から始めて、具体的な詳細へと掘り下げることで、重要なデータ経路を見逃すことがありません。この階層的アプローチは、マイクロサービスのレイヤード設計と自然に整合します。
レベル0:コンテキスト図
レベル0の図は、しばしばコンテキスト図と呼ばれるもので、最も広い視点を提供します。システム全体を単一のプロセスとして表現し、それとやり取りするすべての外部エントリを特定します。これは計画の第一段階であり、範囲を定義するためのものです。
- 境界を特定する:システムの内部と外部を明確にマークする。
- 外部インターフェース:データのすべての入出力ポイントをリストアップする。
- 主な入出力:システムの主なデータトリガーを特定する。
マイクロサービスにおいて、このレベルは「システムはユーザーに対して何をしているのか?」という問いに答えるのに役立ちます。分解の段階を準備するものです。
レベル1:主要な機能分解
コンテキストが確立されると、単一のプロセスが主要なサブプロセスに分解されます。マイクロサービスの文脈では、これらのサブプロセスは初期のサービス候補を示唆することが多いです。このレベルでは、システムを論理的なドメインに分割します。
- ドメインの整合:ビジネス機能(例:注文処理、在庫管理、ユーザー認証)ごとにプロセスをグループ化する。
- サービス候補:各主要プロセスは、潜在的なマイクロサービスとなる。
- サービス間通信:これらの主要なドメイン間のデータフローを特定する。
レベル2:詳細なフロー分析
最終的な詳細レベルでは、サービス内の特定の機能に注目する。ここでは、データ検証、変換、ストレージロジックがマッピングされる。実装を開始する前に、サービスの内部論理が整合していることを保証する。
🏗️ データフローをサービス境界にマッピングする
マイクロサービスアーキテクチャにおける最も重要な課題の一つは、サービス境界を定義することである。境界が誤って設定されると、サービス同士が強く結合され、「分散型モノリス」という反パターンに陥る。DFDは、データ依存関係を強調することで、これらの境界線を描くのを支援する。
一貫性の特定
サービスは高い一貫性を示すべきであり、これはサービス内のすべての機能が特定のデータセットに対して密接に連携していることを意味する。DFDは、同じデータストアやフローを共有するプロセスをグループ化することで、これを可視化する。
- グループ化されたプロセス:プロセスAとプロセスBが外部のトリガーなしに常に直接データを交換する場合、それらは同じサービスに属している可能性が高い。
- 共有データストア:同じデータストアにアクセスするプロセスは、統合の可能性について評価すべきである。
結合度の最小化
結合度とは、サービス間の相互依存の程度を指す。DFDは、提案された境界を越えるデータフローの数を示すことで、結合度を明らかにする。目標は、サービス境界を越えるデータフローの数を最小限に抑えることである。
- 直接接続:サービス間の直接的なデータフローの数を減らす。
- 間接接続:サービスを分離するために、非同期メッセージングやイベント駆動型アーキテクチャを優先する。
🗄️ データ所有権と整合性の管理
モノリシックデータベースでは、データ整合性はトランザクションによって管理される。マイクロサービスでは、各サービスが通常そのデータを所有する。DFDは所有権を明確にする上で不可欠である。データフローをストアにマッピングすることで、アーキテクトは特定のプロセスに所有権を割り当てる。
サービスごとのデータベースパターン
各マイクロサービスは、自身のデータストアを管理すべきである。DFDは、データの発生源と消費先を追跡することで、どのデータがどのサービスに属するかを特定するのを支援する。
- 真実の源泉:データを書き込むプロセスが、データストアを所有する。
- 読み取りアクセス:他のプロセスは定義されたフロー(API)を介してデータを読み取ることができるが、直接変更することはできない。
整合性モデル
分散システムは、即時整合性よりも最終整合性に依存することが多い。DFDは、整合性が重要である場所と、緩和できる場所を明確に示す。
- 強一貫性:金融取引や在庫更新に必須。これらのフローは同期的とマークされています。
- 最終的一貫性:ユーザーのプロフィールやログ記録に許容可能。これらのフローはしばしば非同期です。
🔗 通信パターンと統合
サービスが定義されると、アーキテクチャはそれらがどのように相互に通信するかを定義しなければなりません。DFDは異なる種類のデータフローを区別し、通信技術の選択に影響を与えます。
リクエスト-リプライ対イベント駆動
すべてのデータフローが即時応答を必要とするわけではありません。DFDはタイミング要件に基づいてフローを分類するのに役立ちます。
- 同期フロー:下流プロセスがデータを即座に必要として進行する場合に使用されます。これらは通常、RESTまたはgRPC APIに対応します。
- 非同期フロー:バックグラウンド処理や通知に使用されます。これらはメッセージキューまたはイベントバスに対応します。
⚠️ DFDに基づく計画における一般的な落とし穴
DFDは強力なツールですが、正しく使わなければ誤解を招きやすいです。アーキテクトは計画プロセスを妨げる可能性のある一般的なミスに注意する必要があります。
落とし穴1:コンテキストの詳細が多すぎる
コンテキストレベルで過剰な詳細から始めると、高レベルの視点が曖昧になります。Level 0はシンプルに保ちましょう。Level 1と2に移行するときだけ複雑性を追加してください。
落とし穴2:非機能要件を無視する
DFDはデータに注目するが、パフォーマンスやセキュリティには注目しない。フローをマッピングする際には遅延要件やセキュリティ境界を考慮する必要があります。データフローは技術的に可能でも、セキュリティポリシーに違反する可能性があります。
落とし穴3:循環依存
DFDは、Service AがService Bを呼び出し、Service BがService Aを呼び出すという循環データフローを明らかにすることがあります。これによりデッドロックや無限ループが発生します。これらのループはデータ所有権の再構築によって解消しなければなりません。
📋 DFDレベルの比較分析
DFDレベルがアーキテクチャ的決定にどのように対応するかをよりよく理解するため、以下の表を参照してください。
| DFDレベル | 注目領域 | アーキテクチャ的出力 |
|---|---|---|
| コンテキスト(レベル0) | システム範囲 | サービス境界の定義 |
| 機能的(レベル1) | 主要ドメイン | サービスカタログおよびAPI契約 |
| 論理的(レベル2) | 内部論理 | データモデルおよび検証ルール |
| 物理的 | インフラストラクチャ | デプロイメントトポロジーおよびネットワーク構成 |
🔄 反復的な精緻化と保守
アーキテクチャは一度きりの出来事ではありません。ビジネスが進化するにつれてデータフローも変化します。DFDはコードベースと並行して更新すべき、生きているドキュメントとして機能します。
バージョン管理図
APIがバージョン管理されるように、DFDも時間の経過とともにアーキテクチャの変更を追跡するためにバージョン管理されるべきです。これにより、チームは過去に特定の意思決定がなされた理由を理解しやすくなります。
- 変更ログ:データフローまたはプロセスのすべての変更を記録する。
- 影響分析:図を用いて、1つのサービスの変更が他のサービスに与える影響を評価する。
自動検証
手動で作成された図は有用ですが、自動検証により実装が設計と一致していることを保証できます。ツールは、実際のネットワークトラフィックがDFDで定義されたフローと一致しているかを検証できます。
🛡️ データフローにおけるセキュリティ上の考慮事項
セキュリティは設計においてしばしば後回しにされますが、DFDを用いることで、セキュリティを最初から統合できます。すべてのデータフローは潜在的な攻撃ベクトルを表しています。
信頼ゾーンの定義
異なるセキュリティレベルを要する図の領域をマークする。内部フローは信頼される可能性があるが、外部フローは暗号化と認証を必要とする。
- 外部フロー: TLS、APIキー、またはOAuthトークンを必要とする。
- 内部フロー: 相互TLSまたはサービス間認証を必要とする。
データ分類
データフローを感度に基づいてラベル付けする。機密データ(PII、財務情報)は公開データよりも厳格な制御を必要とする。
- 高感度:保存時および送信中のデータを暗号化する。
- 低感度:標準的な暗号化プロトコルで十分です。
📈 DFDを用いた成功の測定
アーキテクチャが機能しているかどうかはどうやって知るのですか? DFDは測定の基準を提供します。実際のデータの流れを計画された図と比較することで、チームはボトルネックを特定できます。
パフォーマンス指標
- レイテンシ:データがフローを通過するまでの時間を測定する。
- スループット:プロセス間を移動するデータの量を測定する。
- エラー率:頻繁に失敗するフローを特定する。
最適化の機会
DFDは冗長なパスを強調します。2つのサービスが繰り返し同じデータを交換する場合、パフォーマンスを最適化するためにキャッシュ層や共有リードモデルを導入する可能性があります。
🚀 戦略的計画に関する結論
マイクロサービスの計画にデータフローダイアグラムを使用することで、コードから情報へと焦点が移ります。アーキテクチャがビジネスロジックを支援するように保証し、逆ではないことを確認します。構造化されたDFDアプローチに従うことで、モジュール化され、保守可能でスケーラブルなシステムを構築できます。
このプロセスには規律が必要です。アーキテクトが早期に過剰最適化しようとする誘惑に抵抗し、代わりに明確な境界とデータ所有権に注力する必要があります。DFDが正確であれば、実装は自然に進みます。この方法は技術的負債を削減し、長期的な成長の基盤を築きます。
図は設計だけでなく、コミュニケーションのツールであることを思い出してください。技術チームとビジネス関係者との間の溝を埋めます。データの流れが誰もが理解しているとき、組織全体がシステムの機能と制限に関するより良い意思決定をできるようになります。