









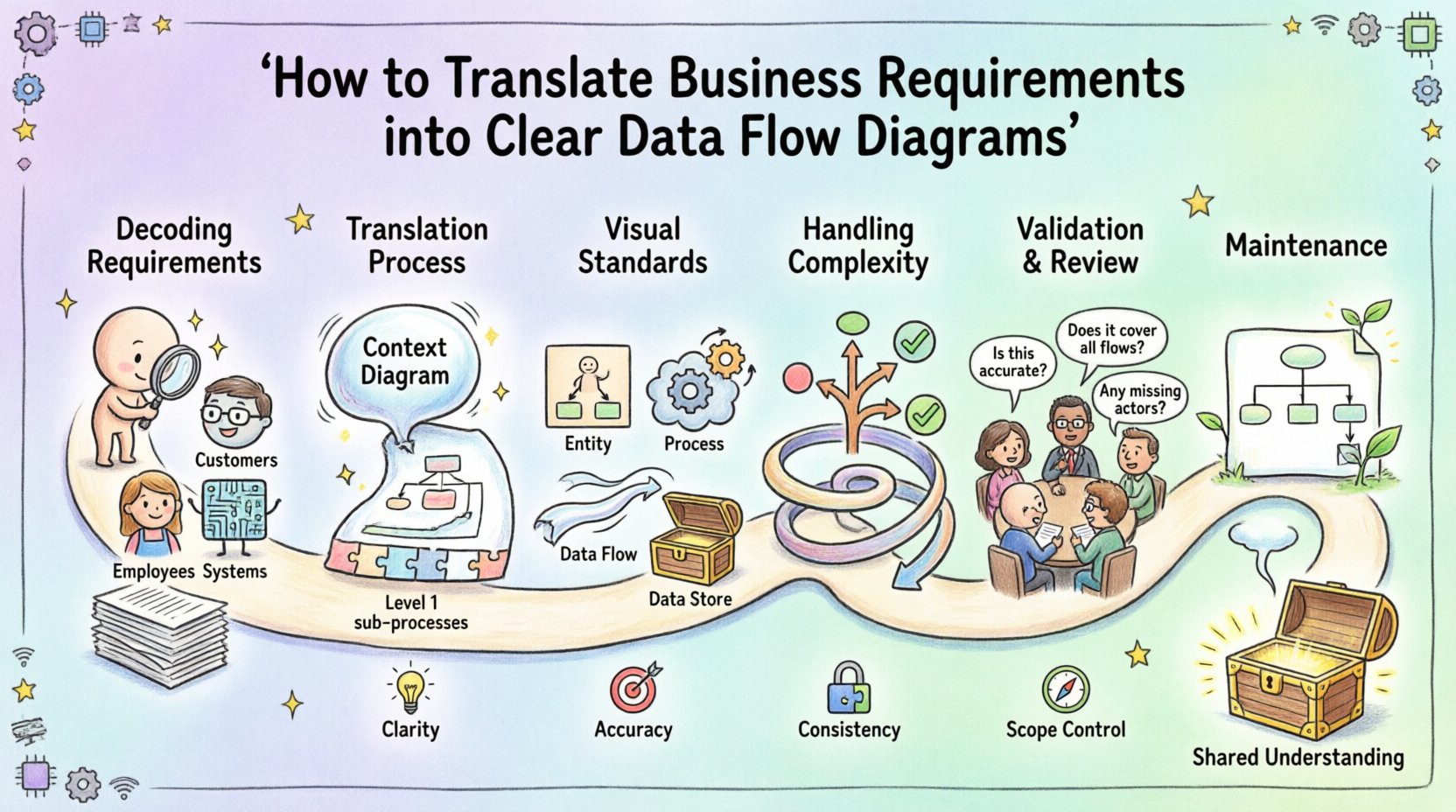
堅牢なシステムを構築するには、コードを書くこと以上に必要なことがある。組織内を情報がどのように移動するかを正確に理解することが求められる。この理解の核となるのが、データフローダイアグラム(DFD)である。この視覚的ツールは、抽象的なビジネスニーズと具体的な技術仕様の間の溝を埋める。ビジネス要件をDFDに成功裏に変換することで、ステークホルダー、開発者、アナリストの間で共有される言語が生まれる。
このガイドは、高レベルのビジネスニーズを構造化された図に変換する体系的なプロセスを丁寧に説明する。必要なステップ、関与する主要な要素、避けなければならない一般的な落とし穴について検討する。この手法に従うことで、最終的なシステムが運用上の現実を正確に反映していることを保証できる。
要件とDFDの関係を理解する 🔗
ビジネス要件とは、組織が達成したいことを示す文言である。技術的実装の詳細を必ずしも明記しないが、プロセス、データの必要性、ユーザーとのインタラクションを記述する。データフローダイアグラムは、これらの文言の視覚的表現である。データの発生源、処理方法、保存場所、次の行き先を示す。
要件をDFDにマッピングするということは、情報の流れを監査しているに等しい。このプロセスにより、技術選定の前に論理的なギャップ、欠落しているデータストア、曖昧なプロセス定義が明らかになる。これにより、『何を』するかについての議論を促す。何をではなく、どのように.
この変換が重要な理由 🎯
- 明確さ:ステークホルダーはしばしば技術用語に苦労する。DFDは視覚的記号を用いて、複雑な流れを理解しやすくする。
- 正確性:要件に言及されたすべてのデータが、明確な経路を持っていることを検証する。
- 一貫性:システムの異なる部分が、データ所有に関して互いに矛盾しないことを保証する。
- 範囲管理:現在のプロジェクトの範囲内にあるものと、将来の反復で扱うべきものを識別するのに役立つ。
第1フェーズ:ビジネス要件の解読 📋
良い図を描くための基盤は、高品質な入力である。領土を知らないのに地図を描くことはできない。最初のステップは、ビジネスから提供された原資料を収集し、分析することである。
1. 外部エントリティを特定する
まず、システムの外部からやり取りする者(またはもの)をリストアップする。これらがデータの発生源および到着先である。要件の文脈では、ユーザー、部門、または外部システムの言及を探る。
- 顧客: 注文を行うか?レポートを受け取るか?
- 従業員: 取引を承認するのは誰か?データを入力するのは誰か?
- 外部システム: APIが関与しているか?第三者サービスからデータを取得しているか?
- 規制当局: 政府機関に報告しなければならないデータはありますか?
ここで特定されたすべてのエンティティは、図面上の四角形または円になります。要件にユーザーの操作が記載されている場合は、ユーザーのエンティティを特定してください。レポートが送信されるという記述がある場合は、受信者のエンティティを特定してください。
2. データフローの抽出
要件文書の中で動詞を探してください。動詞は通常、移動を示しています。「フォームを提出する」「レポートを生成する」「在庫を更新する」といった表現は、情報の流れを示しています。
- 入力フロー: システムに入力されるデータ。例:「顧客が注文内容を提出する。」
- 出力フロー: システムから出力されるデータ。例:「システムが確認メールを送信する。」
- 内部フロー: システム内のプロセス間を移動するデータ。
3. データストアの定義
要件ではしばしば記録の保持が言及されます。データが即時の取引を越えて保持される場合、それはデータストアに属します。『保存する』『アーカイブする』『記録する』『履歴』『データベース』などのキーワードを探してください。
- 取引ログ: 何が起きたかの記録。
- マスターファイル: 商品リストやユーザーのプロファイルなどの静的データ。
- 作業ファイル: 処理中に使用される一時的なデータ。
フェーズ2:翻訳プロセス 🛠️
原始的な要件を収集したら、本格的な翻訳作業が始まります。この段階では自制心が求められます。技術的解決策に飛びつきたくなる衝動を抑える必要があります。論理的な流れに集中してください。
ステップ1:コンテキスト図の作成 🌍
高レベルの視点から始めます。これは通常、コンテキスト図またはレベル0DFDと呼ばれます。システム全体を1つのプロセスバブルとして示し、すべての外部エンティティと接続します。
- システムを描く: すべてのアプリケーションを1つの円または角丸長方形で表します。
- エンティティを追加する: すべての特定された外部エンティティを円の周囲に配置します。
- フローを接続する: エンティティと中心のプロセスの間に矢印を描きます。各矢印に移動するデータをラベル付けします。
- 検証: すべてのエンティティが少なくとも1つの入力または出力フローを持っていることを確認します。
この図は、「システム境界とは何か?」という問いに答えます。あなたの作業の範囲を定義しています。
ステップ2:レベル1のDFDに分解する 🧩
コンテキスト図は、内部の論理を示すにはレベルが高すぎます。単一のプロセスバブルを主要なサブプロセスに分割する必要があります。これらのサブプロセスは、システムの主要な機能領域を表しています。
- 主要な機能を特定する: システムが注文を処理する場合、「注文受領」、「支払い処理」、「商品発送」に分解します。
- データストアをマッピングする: プロセスとデータストアの間に線を引きます。これにより、情報が保存される場所がわかります。
- フローの精査: バリデーションエラーまたはログエントリでない限り、プロセスに入力するすべての矢印は、必ずそのプロセスから出力されるようにしてください。
ステップ3:番号付けと命名 🏷️
読みやすさの鍵は一貫性です。プロセスには標準的な番号付け方式を使用してください。
- レベル0: 単一の中心プロセス(例:0.0)。
- レベル1: 主要なサブプロセス(例:1.0、2.0、3.0)。
- レベル2: レベル1プロセス内の詳細なステップ(例:1.1、1.2)。
名前は動作指向にするべきです。動詞の後に名詞を配置してください。たとえば、「税金を計算する」は「税金計算」という表現よりも優れています。これはデータフローの動的な性質と整合します。
フェーズ3:視覚的基準と記号 📐
図が普遍的に理解されるようにするため、標準的な表記法に従ってください。ツールによって異なる場合がありますが、核心的な論理は同じです。
| 要素 | 記号の形状 | 意味 | 例 |
|---|---|---|---|
| 外部エンティティ | 長方形または正方形 | システム外のデータの発生源または到着先 | 顧客、銀行、ベンダー |
| プロセス | 円または角が丸い長方形 | データの変換 | 注文の検証、合計金額の計算 |
| データフロー | 矢印 | 要素間のデータの移動 | 注文詳細、支払い領収書 |
| データストア | 開かれた長方形または平行線 | データの受動的保存 | 注文データベース、ユーザーファイル |
移動のルールを理解する 🔄
これらの要素がどのように接続されるかを規定する厳格な論理ルールがあります。それらを違反すると、実現不可能なシステム設計が生じます。
- エンティティ間にはデータフローがない:外部エンティティは、システムを経由せずに直接通信することはできません。
- プロセスからプロセスへ:データは、2つのプロセスの間、またはプロセスとストアの間を流れなければなりません。
- データストアとのインタラクション:データを保存するにはストアへのフローが必要であり、読み出すにはストアからのフローが必要です。プロセスステップをスキップすることはできません。
- 入出力のバランス:すべてのプロセスには少なくとも1つの入力と1つの出力が必要です。データを消費するが何の出力を生成しないプロセスは「ブラックホール」です。何もからデータを生成するプロセスは「奇跡」です。
フェーズ4:複雑性と例外の処理 ⚠️
現実世界のビジネス要件はほとんど線形ではありません。意思決定、ループ、例外を含みます。明確なDFDはこれらのシナリオを考慮しなければなりません。
1. 決定ポイント
要件に条件が含まれる場合、たとえば「注文金額が1000ドルを超える場合はマネージャーの承認を要する」というように、分岐パスが生じます。
- フローの分岐:異なる結果に対して別々の矢印を使用してください。明確にラベルを付けてください(例:「承認済み」対「却下」)。
- 論理演算子:ときにはデータフローを組み合わせる必要があります。これは線の分岐で表されます。
2. 反復ループ
一部のプロセスは繰り返しを必要とします。たとえば、「製品検索」機能は、ユーザーが必要なものを発見するまでループする可能性があります。
- フィードバックループ:後続の段階から前のプロセスへ線を引く。これは修正または再試行を示している。
- 終了:ループが永遠に実行されないよう、明確な終了パスを確保する。
3. データ検証
要件はしばしばデータ品質のチェックを指定する。「メール形式が有効であることを確認する。」
- エラー処理フロー:無効なデータ用に特定のフローを作成する。エラーログへ送るか、ユーザーのエンティティに戻して修正させるべきである。
- 修正プロセス:ユーザーがデータを修正する必要がある場合は、元のプロセスが続行する前に「データ修正」用の新しいプロセスを描く。
フェーズ5:検証とレビュー ✅
図面が作成され次第、検証が必要である。このステップでは、図面が元の要件と一致しており、論理的に整合していることを確認する。
1. ステークホルダーとのウォークスルー
ビジネスユーザーとの会議をスケジュールする。すぐに原始的な図面を提示しない。データフローの物語を説明する。
- トランザクションのトレース:特定のシナリオ(例:「新規顧客が注文を出す」)を選ぶ。図面上のすべてのステップを順に確認する。
- 質問を投げかける:「ここではデータが正しいストアへ送られているか?」「このフローに欠けているステップはないか?」
- 混乱の兆候に耳を傾ける:ステークホルダーが迷う場合は、図面または要件に曖昧さがあることを示している。
2. 技術的実現可能性の確認
ビジネス側の検証後は、技術リーダーを関与させる。彼らは実装上の障害を発見できる。
- データ量:大量のデータ転送を示すフローは存在するか?最適化が必要な可能性があるか?
- セキュリティ:機密データのフローは保護されているか?図面は暗号化やアクセス制御を示しているか?
- パフォーマンス:順次処理が多すぎてボトルネックを引き起こす可能性はないか?
3. 一貫性の確認
レベル1の図面がコンテキスト図と整合していることを確認する。
- 入出力の一致: レベル1の合計入力および出力フローは、コンテキスト図のフローと一致しなければなりません。
- エンティティの一貫性: 図のすべてのレベルで同じエンティティ名を使用することを確認してください。
避けるべき一般的な落とし穴 🚫
経験豊富なアナリストですらミスを犯します。一般的な誤りに気づいておくことで、図の整合性を保つことができます。
1. 「制御フロー」の罠
DFDはデータの流れを示し、制御の流れを示します。何時何かが起こるかを示すために矢印を描いてはいけません。データの移動を示す場合にのみ矢印を描いてください。
- 悪い例:「Start」という矢印がプロセスを指している。
- 良い例:外部エンティティが「スタートリクエスト」というデータパケットを送信している。
2. 図を複雑化しすぎること
すべての詳細を1ページに載せたくなるのはわかりますが、これにより誰も読めない「ヘアボール」図になってしまいます。
- 分解を使用する: プロセスが複雑すぎる場合は、それを新しいサブ図に分割してください。
- 論理に注目する: ボタンクリックのようなUI設計の詳細は含めないでください。下層のデータ移動に注目してください。
3. データストアを無視すること
一部の図はプロセスにのみ注目し、データがどこに保存されているかを無視しています。これは重大な見落としです。
- 永続性を追跡する: 記憶が必要なすべてのデータに対して、ストアが存在することを確認してください。
- ストアにラベルを付ける: データストアの名前を明確に(例:「アクティブユーザー」対「アーカイブ済ユーザー」)。
4. エンティティを併合すること
すべてのユーザーを1つのボックスにまとめるのは一般的ですが、「マネージャー」と「顧客」ではデータの要件が異なります。
- 役割の区別:データの入力または出力が著しく異なる場合は、エンティティを分割する。
- セキュリティの文脈:異なるエンティティは、異なるアクセスレベルを意味する。セキュリティ計画のためにそれらを明確に区別する。
フェーズ6:保守と進化 🔄
DFDは一度きりの納品物ではない。ビジネスとともに進化しなければならない、生きている文書である。
1. 変更管理
要件が変更されたら、図も変更しなければならない。マップを更新せずにコードだけを更新してはならない。
- 影響分析:新しいデータソースが追加された場合、そのデータの流れを追跡する。既存のプロセスに影響を与えるか?
- バージョン管理:図のバージョンを保持する。これにより、何がいつ変更されたかを監査しやすくなる。
2. ドキュメントの統合
図はテキストで補完されるべきである。各データフローの特定のフィールドを定義するために、データ辞書を使用する。
- フィールドの定義:データフローが「注文詳細」の場合、フィールドをリストアップする(例:SKU、数量、価格)。
- 仕様書へのリンク:技術仕様書の中で図を参照する。
システム設計に関する最終的な考察 🧠
ビジネス要件をデータフロー図に翻訳することは、システム分析における重要なスキルである。忍耐力、細部への注意、明確さへのコミットメントが求められる。これらのステップに従うことで、開発を導く設計図を作成し、最終製品がビジネス目標を達成することを保証できる。
単に線を引くことが目的ではない。システムを理解することが目的である。非技術的なステークホルダーにデータフローを説明できるようになったら、成功したと言える。この共有された理解はリスクを低減し、スコープの拡大を防ぎ、成功するプロジェクトの基盤を築く。
図を簡潔に保ち、ラベルを正確にし、論理をしっかり持つこと。DFDを組織内で情報がどのように移動するかという真実のソースとして扱う。練習を重ねることで、この翻訳プロセスは自然なものになる。その結果、技術的な細部に迷い込むのではなく、複雑なビジネス問題の解決に集中できる。