











W kontekście architektury systemów i inżynierii bezpieczeństwa wizualizacja przepływu danych to nie tylko ćwiczenie projektowe; jest to podstawowa praktyka bezpieczeństwa. Diagram przepływu danych (DFD) pełni rolę mapy informacji poruszającej się przez system. Gdy prawidłowo wykorzystywany do analizy ryzyka, ta mapa staje się kluczowym narzędziem do identyfikacji luk w zabezpieczeniach przed ich wykryciem w środowiskach produkcyjnych. Niniejszy przewodnik szczegółowo opisuje metodologię integrowania strategii identyfikacji i ograniczania ryzyka bezpośrednio w procesie tworzenia diagramu przepływu danych.
Bezpieczeństwo nie jest dodatkową funkcją; jest inherentną cechą projektu. Analizując sposób przepływu danych między zewnętrznymi jednostkami, procesami i magazynami danych, architekci mogą precyzyjnie wyznaczyć miejsca, w których są przekraczane granice zaufania, gdzie ujawnia się wrażliwa informacja oraz gdzie brakuje odpowiednich kontrolek. Następujące sekcje omawiają mechanizmy tego podejścia, przechodząc od podstawowych koncepcji do praktycznego zastosowania.
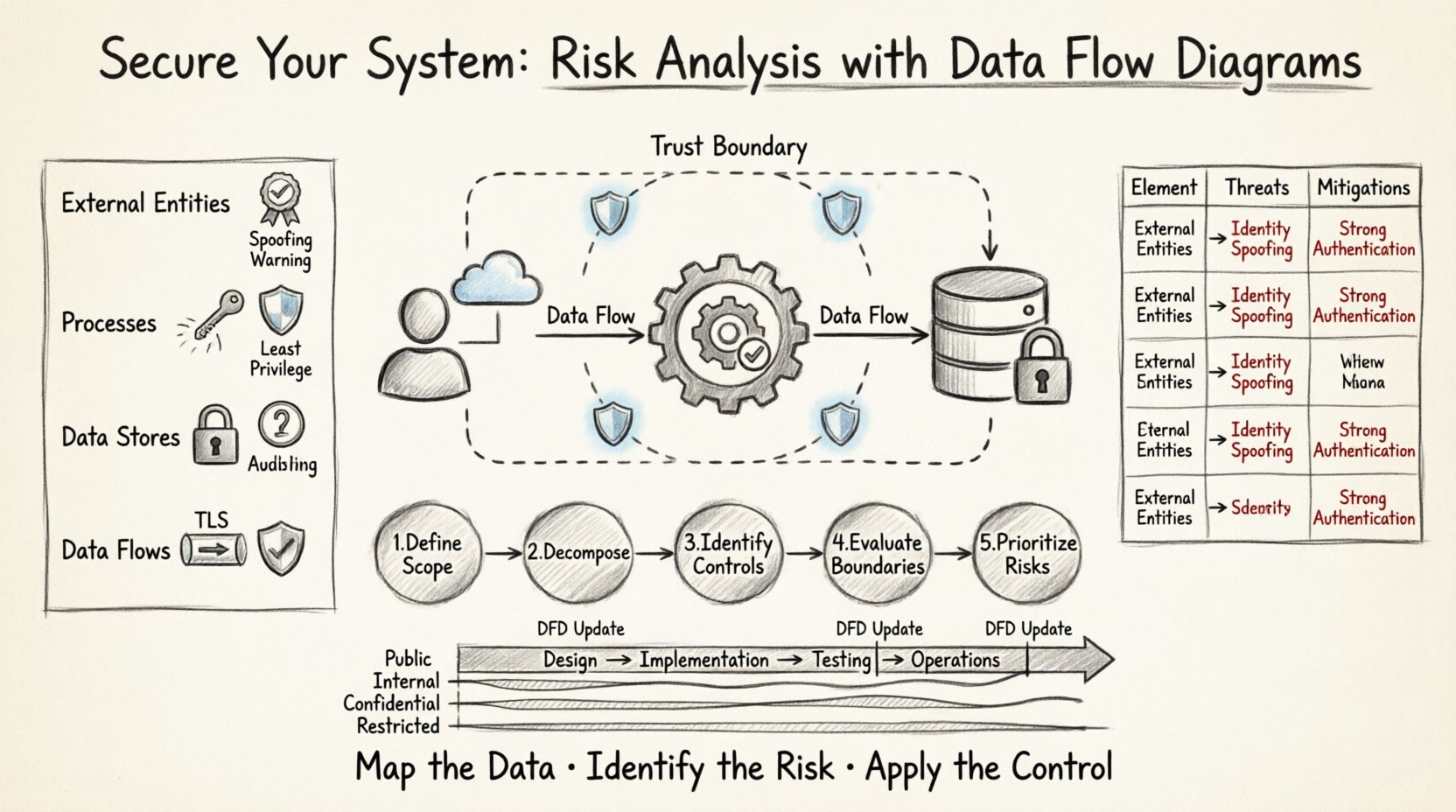
🧩 Zrozumienie podstawowych elementów diagramu przepływu danych
Zanim przejdzie się do analizy ryzyka, należy zrozumieć składniki, które są analizowane. Diagram przepływu danych (DFD) składa się z czterech podstawowych elementów. Każdy z nich ma określone implikacje bezpieczeństwa, które należy ocenić w trakcie przeglądu.
- Zewnętrzne jednostki: Odnoszą się do źródeł lub miejsc docelowych danych poza granicami systemu. Przykłady to użytkownicy, inne systemy lub usługi trzecich stron.Implikacje bezpieczeństwa: Jednostki zewnętrzne często są źródłem ataków podmiany tożsamości lub prób nieautoryzowanego dostępu. Każda jednostka musi zostać uwierzytelniona i uprawniona przed interakcją z wewnętrznymi procesami.
- Procesy: To funkcje lub przekształcenia działające na danych. Przekształcają dane wejściowe w dane wyjściowe.Implikacje bezpieczeństwa: Procesy to miejsca, w których pojawiają się błędy logiki. Jeśli proces nie zwaliduje danych wejściowych, może to prowadzić do ataków wstrzyknięcia lub obejścia logiki. Zapewnienie zasady minimalnych uprawnień w kontekście wykonania każdego procesu jest kluczowe.
- Magazyny danych: Odnoszą się do miejsc, w których dane są przechowywane w stanie nieaktywnym. Mogą to być bazy danych, pliki lub bufor pamięci.Implikacje bezpieczeństwa: Magazyny danych są głównym celem wykrywania danych. Kontrole dostępu, szyfrowanie danych w spoczynku oraz sprawdzanie integralności są tu obowiązkowe.
- Przepływy danych: To ścieżki, po których dane poruszają się między pozostałymi trzema elementami.Implikacje bezpieczeństwa: Przepływy reprezentują kanały sieciowe lub komunikacji międzyprocesowej. Dane w tranzycji muszą być szyfrowane. Monitorowanie nieautoryzowanych przepływów jest kluczowe do wykrywania ruchu poziomego przez atakujących.
🔍 Przecięcie DFD i modelowania zagrożeń
Zintegrowanie analizy ryzyka z diagramami przepływu danych wymaga strukturalnego podejścia. Często nazywa się to modelowaniem zagrożeń przy użyciu diagramów przepływu danych. Celem jest identyfikacja potencjalnych zagrożeń związanych z każdym elementem i przepływem, a następnie określenie odpowiednich środków ograniczających.
Podczas przeprowadzania tej analizy skupienie zmienia się z pytania „jak działa system?” na pytanie „jak system może zostać atakowany?”. Ta zmiana perspektywy pozwala zespołom proaktywnie projektować kontrole, zamiast reaktywnie zamykać luki.
Kluczowe cele analizy ryzyka w DFD
- Identyfikacja aktywów: Określ, które elementy danych są wrażliwe. Nie wszystkie dane wymagają tego samego poziomu ochrony.
- Definicja granic zaufania: Jasną granicę zaznacz, gdzie kończy się granica systemu, a zaczyna się środowisko zewnętrzne. Poziom zaufania zmienia się na tych granicach.
- Wyliczanie zagrożeń: Wymień konkretne zagrożenia dotyczące elementów schematu.
- Mapowanie kontrolek: Przypisz kontrole bezpieczeństwa do konkretnych elementów schematu w celu ograniczenia wykrytych zagrożeń.
📉 Analiza ryzyk według poziomu DFD
Diagramy przepływu danych są zwykle tworzone na poziomach, przechodząc od ogólnego kontekstu do szczegółowej logiki procesu. Każdy poziom oferuje inną dokładność wskazania ryzyka.
Diagram kontekstowy (poziom 0)
Jest to najwyższy poziom widoku. Pokazuje system jako pojedynczy proces oddziałujący z jednostkami zewnętrznymi.
- Skupienie się na ryzyku:bezpieczeństwo brzegu sieci i kontrola dostępu na najwyższym poziomie.
- Analiza: Zidentyfikuj wszystkie połączenia zewnętrzne. Czy istnieje bezpośredni dostęp do internetu? Czy istnieją systemy dziedziczne, które współpracują z nowym projektem? Na tym poziomie główne ryzyka obejmują ataki typu man-in-the-middle na główne kanały komunikacji.
Poziom 1 DFD
Główny proces jest rozbijany na podprocesy. Magazyny danych i przepływy stają się widoczne.
- Skupienie się na ryzyku:Obsługa danych wewnętrznych i izolacja procesów.
- Analiza: Poszukaj przepływów, które pomijają sprawdzanie bezpieczeństwa. Na przykład, czy dane przepływają bezpośrednio z niezaufanej jednostki do poufnego magazynu danych bez przejścia przez proces weryfikacji? Ten poziom często ujawnia luki w logice przepływów uwierzytelniania.
Poziom 2 DFD (i wyższe)
Podprocesy są dalej szczegółowo opisane. Ten poziom często służy do analizy konkretnych modułów.
- Skupienie się na ryzyku:Weryfikacja danych, implementacja szyfrowania i obsługa błędów.
- Analiza: Przejrzyj konkretne algorytmy lub przekształcenia danych. Czy operacje kryptograficzne są jasno pokazane? Czy komunikaty o błędach są rejestrowane w sposób, który ujawnia informacje? Ten poziom jest kluczowy dla przeglądów bezpieczeństwa na poziomie kodu.
📋 Macierz ryzyka: mapowanie elementów na zagrożenia
Poniższa tabela podsumowuje typowe ryzyka związane z konkretnymi elementami DFD. Ta macierz służy jako lista kontrolna podczas przeglądu projektu.
| Element DFD | Typowe zagrożenia | Strategie ograniczania |
|---|---|---|
| Jednostka zewnętrzna |
|
|
| Proces |
|
|
| Magazyn danych |
|
|
| Przepływ danych |
|
|
🛠️ Krok po kroku: proces analizy ryzyka
Wdrożenie tej analizy wymaga dyscyplinowanego przepływu pracy. Poniższe kroki przedstawiają procedurę przeprowadzania szczegółowej analizy ryzyka przy użyciu schematów przepływu danych (DFD).
Krok 1: Zdefiniuj zakres i granice
Zacznij od narysowania diagramu kontekstowego. Jasnieto zdefiniuj, co znajduje się w systemie, a co poza nim. Ta granica to obszar zaufania. Każde dane przekraczające tę linię wymagają szczegółowej analizy. Dokumentuj poziom zaufania przypisany do każdego zewnętrznego elementu. Czy element jest całkowicie zaufany, częściowo zaufany czy niezaufany?
Krok 2: Rozkład systemu
Utwórz diagramy poziomu 1 i poziomu 2. Podczas rozkładania głównego procesu upewnij się, że każdy przepływ danych jest oznaczony typem przesyłanych danych. Na przykład oznacz przepływ jako „Numer karty kredytowej”, a nie tylko „Dane płatności”. Dokładność pozwala na dokładniejsze kategoryzowanie ryzyka.
Krok 3: Identyfikacja kontrolek bezpieczeństwa
Przejrzyj każdy element diagramu pod kątem macierzy ryzyka. Zadaj następujące pytania dla każdego komponentu:
- Czy ten komponent obsługuje poufne dane?
- Czy istnieje mechanizm uwierzytelniania?
- Czy dane są szyfrowane podczas przesyłania?
- Czy generowane są dzienniki do celów audytu?
Krok 4: Ocena granic zaufania
Zaznacz każdą granicę zaufania na diagramie. Granica zaufania to miejsce, w którym zmienia się poziom zaufania. Na przykład granica istnieje między publicznym serwerem internetowym a wewnętrzną bazą danych. Przekroczenie tej granicy to punkt największego ryzyka. Upewnij się, że każdy punkt przekroczenia ma określoną kontrolkę bezpieczeństwa, taką jak reguła zapory, brama interfejsu API lub tunel szyfrowania.
Krok 5: Dokumentowanie i priorytetyzowanie ryzyk
Wypisz każde zidentyfikowane ryzyko. Użyj systemu oceny nasilenia (np. Niskie, Średnie, Wysokie, Krytyczne). Priorytetyzuj ryzyka na podstawie dwóch czynników: prawdopodobieństwa wykorzystania oraz skutków dla biznesu, jeśli ryzyko zostanie wykorzystane. Ryzyka o dużym wpływie powinny zostać rozwiązane przed wdrożeniem.
🚧 Powszechne pułapki w analizie bezpieczeństwa DFD
Nawet doświadczeni architekci mogą pominąć istotne detale. Znajomość powszechnych błędów pomaga zapewnić solidną postawę bezpieczeństwa.
- Przepływy duchów:Upewnij się, że każdy przepływ danych ma zdefiniowany źródło i docelowy punkt. Przepływy zaczynające się lub kończące w próżni często wskazują na brakujące logiki lub porzucone procesy danych. Te luki mogą zostać wykorzystane przez atakujących.
- Ignorowanie danych w spoczynku:Skupianie się wyłącznie na danych w przesyłce. Wiele naruszeń danych dzieje się dlatego, że dane przechowywane w bazach danych nie są szyfrowane lub są dostępne poprzez nadmiernie uproszczone zapytania.
- Pomijanie uwierzytelniania:Zakładanie, że ponieważ przepływ istnieje, jest bezpieczny. Przepływy danych nie oznaczają automatycznie bezpieczeństwa. Jawne kroki uwierzytelniania i autoryzacji muszą być zamodelowane jako procesy lub kontrole.
- Brak kontroli wersji:Diagramy przepływu danych ewoluują wraz z zmianami systemu. Jeśli diagram nie odpowiada aktualnej implementacji, analiza ryzyka jest nieważna. Zachowuj kontrolę wersji diagramów równolegle z wersjami kodu.
- Ogólne etykiety:Używanie nieprecyzyjnych etykiet, takich jak „Dane użytkownika”, bez określenia typu danych. Konkretny typ danych wywołuje konkretne wymagania regulacyjne i bezpieczeństwa (np. PII, PHI, PCI-DSS).
🔄 Integracja do cyklu życia rozwoju oprogramowania
Aby analiza DFD była skuteczna, nie może być jednorazowym zdarzeniem. Musi być zintegrowana z cyklem życia rozwoju oprogramowania (SDLC).
Faza projektowania
W trakcie początkowego projektowania utwórz diagram kontekstowy i diagramy poziomu 1. Przeprowadź ocenę ryzyka na wysokim poziomie. Zapewnia to, że podstawowe wady bezpieczeństwa nie zostaną wbudowane w architekturę.
Faza wdrożenia
Podczas budowania funkcji przez programistów powinni aktualizować diagramy poziomu 2. Dzięki temu model bezpieczeństwa pozostaje aktualny. Programiści mogą wykorzystać diagram do weryfikacji, czy ich kod implementuje niezbędne kontrole dla przepływów danych, które tworzą.
Faza testowania
Testerzy bezpieczeństwa mogą używać DFD do planowania testów przenikania. Mogą skupić się na przepływach o wysokim ryzyku i granicach zaufania wykrytych w analizie. Dzięki temu testy stają się bardziej efektywne i skierowane.
Faza operacyjna
Utrzymuj diagramy w trakcie działania systemu. Jeśli zintegrowano nowy usługi zewnętrzne, zaktualizuj diagram. Przejrzyj analizę ryzyka, aby upewnić się, że nowa integracja nie wprowadza nowych wektorów ataku.
📈 Ocena skuteczności analizy
Jak możesz wiedzieć, czy analiza ryzyka DFD działa? Szukaj następujących wskaźników dojrzałej postawy bezpieczeństwa.
- Zmniejszona liczba wadliwych elementów:Mniejsza liczba ustaleń zabezpieczeń podczas przeglądów kodu i testów przenikania.
- Szybsze usuwanie wad:Gdy wykryje się problemy, są one łatwiejsze do znalezienia, ponieważ przepływ danych jest zapisany.
- Zgodność z wymogami:Diagramy są bezpośrednio zgodne z wymogami zgodności (np. RODO, HIPAA), pokazując, gdzie przetwarzane i przechowywane są dane poufne.
- Zdrowa świadomość zespołu:Programiści i zaangażowani strony rozumieją konsekwencje bezpieczeństwa swoich wyborów projektowych, ponieważ diagram wizualizuje ryzyka.
🛑 Obsługa wyjątków i systemów dziedziczonych
Nie wszystkie systemy są nowe. Wiele organizacji musi analizować systemy dziedziczne, w których dokumentacja brakuje lub jest niepełna.
Inżynieria wsteczna DFD
Jeśli diagram nie istnieje, musisz go stworzyć na podstawie kodu lub plików konfiguracyjnych. Ten proces, znany jako inżynieria wsteczna, pozwala wizualizować rzeczywisty przepływ danych, a nie tylko zamierzony. Różnice między rzeczywistym przepływem a zaplanowanym projektem często są miejscem, gdzie ukrywają się ryzyka.
Zarządzanie długiem technicznym
Systemy dziedziczne mogą nie mieć nowoczesnych funkcji zabezpieczeń. Podczas analizy tych systemów skup się na kontrolach kompensacyjnych. Jeśli szyfrowanie nie może być zaimplementowane na poziomie kodu, czy może zostać zaimplementowane na poziomie sieci? Jeśli uwierzytelnianie jest słabe, czy brama API może dodać warstwę bezpieczeństwa przed aplikacją dziedziczoną?
🔗 Rola klasyfikacji danych
Identyfikacja ryzyka jest nieodłącznie związana z klasyfikacją danych. Nie możesz chronić tego, czego nie rozumiesz. Przepływy danych muszą być oznaczone poziomami klasyfikacji.
- Publiczne:Informacje, które mogą być udostępniane otwarcie. Niskie ryzyko w przypadku ujawnienia.
- Wewnętrzne:Informacje przeznaczone wyłącznie do użytku wewnętrznego. Średnie ryzyko w przypadku ujawnienia.
- Poufne:Czułe informacje biznesowe lub osobiste. Wysokie ryzyko w przypadku ujawnienia.
- Ograniczone:Bardzo poufne dane wymagające ścisłych kontroli dostępu. Krytyczne ryzyko w przypadku ujawnienia.
Podczas analizy schematu przepływu danych (DFD) wyróżnij przepływy zawierające poufne lub ograniczone dane innym kolorem. Ten wizualny sygnał natychmiast skieruje uwagę zespołu bezpieczeństwa do najważniejszych ścieżek.
🧭 Wnioski dotyczące metodyki
Wykorzystywanie schematów przepływu danych do identyfikacji ryzyka przekształca bezpieczeństwo z reaktywnej listy kontrolnej w zasadę projektowania proaktywnego. Poprzez wizualizację ruchu danych zespoły mogą dostrzec niewidoczne zagrożenia ukryte w architekturze. Proces ten wymaga dyscypliny, regularnych aktualizacji oraz jasnego zrozumienia składników systemu. Poprawnie wykonany, zapewnia jasny plan działania w zakresie zabezpieczania systemu przed znanymi i rozwijającymi się zagrożeniami.
Wartość tej metody tkwi w przejrzystości. Zmusza architektów do stawienia czoła rzeczywistości, jak dane się poruszają i gdzie są narażone. Usuwa niepewność z dyskusji dotyczącej bezpieczeństwa. W miarę jak systemy stają się bardziej złożone, potrzeba takiej strukturalnej analizy staje się jeszcze bardziej krytyczna. Zachowanie dokładnych schematów oraz rygorystyczne stosowanie analizy ryzyka zapewnia, że bezpieczeństwo pozostaje zsynchronizowane z funkcjonalnością biznesową przez cały cykl życia oprogramowania.
Zacznij od schematu. Zmapuj dane. Zidentyfikuj ryzyko. Zastosuj kontrolę. Ten cykl tworzy odporny system zdolny do przetrwania presji nowoczesnej sceny zagrożeń.