











W złożonej architekturze nowoczesnych systemów rozproszonych czas nie jest jedynie miarą do pomiaru; jest podstawowym ograniczeniem, które określa zachowanie systemu. Niezawodność oprogramowania nie polega wyłącznie na zapobieganiu awariom lub obsłudze wyjątków; polega na zapewnieniu poprawnej interakcji między składnikami w określonych granicach czasowych. Gdy wiele wątków, usług lub urządzeń sprzętowych próbuje uzyskać dostęp do zasobów współdzielonych, kolejność i czas trwania tych interakcji staje się kluczowy. To właśnie tutaj diagramy czasowe stają się niezastąpione.
Diagramy czasowe zapewniają wizualne przedstawienie, jak sygnały lub komunikaty zmieniają stan w czasie. Pozwalają inżynierom modelować relacje czasowe między zdarzeniami jeszcze przed wykonaniem jednej linii kodu. Wizualizując przepływ czasu, zespoły mogą identyfikować potencjalne przepływy, warunki wyścigu i błędy synchronizacji, które często pozostają niewidoczne na statycznych schematach przepływu lub diagramach sekwencji. Niniejszy przewodnik bada mechanizmy wykorzystania diagramów czasowych w celu poprawy niezawodności oprogramowania, oferując szczegółowe omówienie współbieżności, analizy opóźnień i weryfikacji systemu.
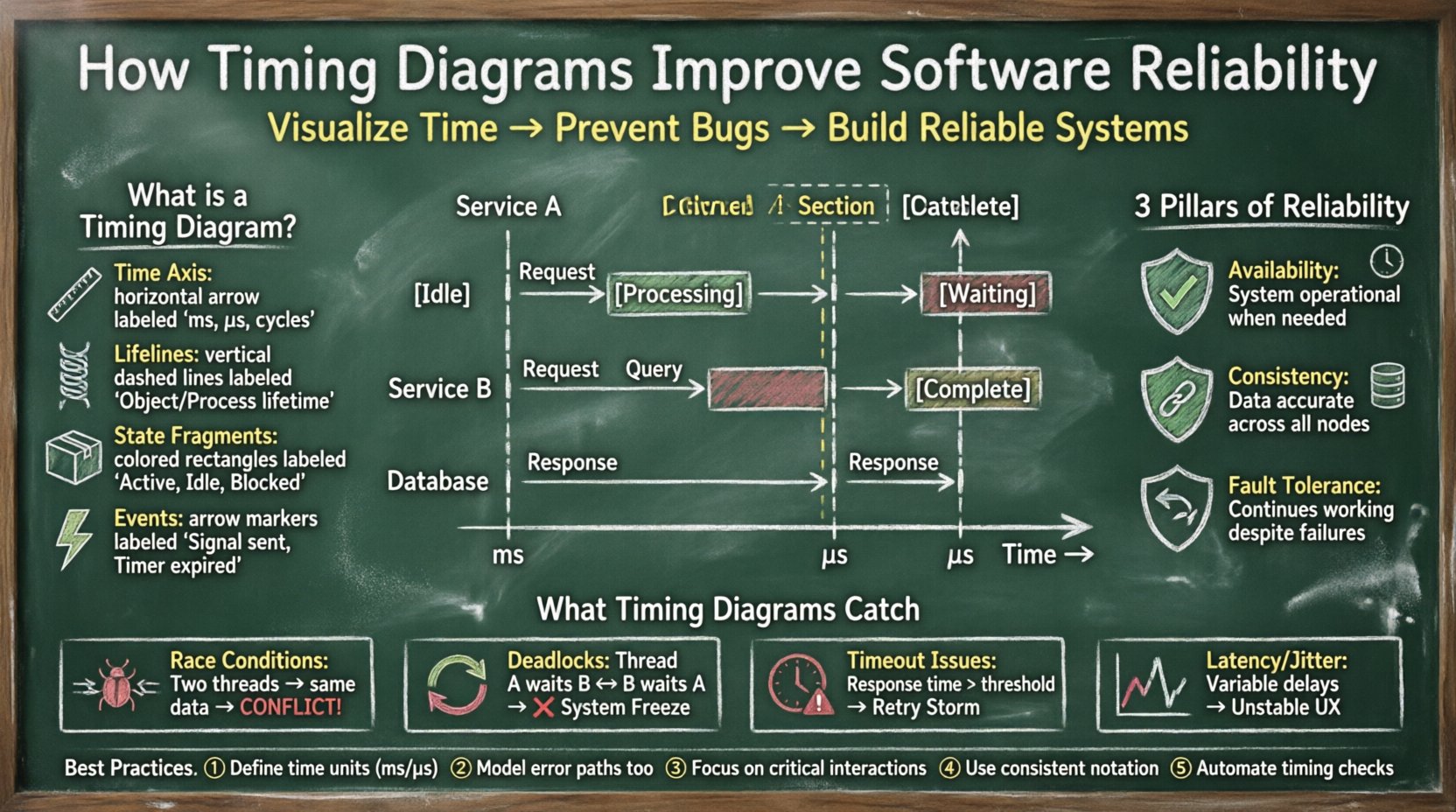
🔍 Definiowanie diagramów czasowych w inżynierii
Diagram czasowy to rodzaj diagramu zachowania w modelowaniu systemu, który opisuje zachowanie obiektów w czasie. W przeciwieństwie do diagramu sekwencji, który skupia się głównie na kolejności komunikatów, diagram czasowy podkreśla relacje czasowe między zdarzeniami. Pokazuje stany obiektów oraz przejścia między nimi wzdłuż poziomej osi czasu.
- Oś czasu: Zazwyczaj biegnie poziomo od lewej do prawej, reprezentując postęp czasu w milisekundach, mikrosekundach lub cyklach zegara.
- Życia (lifelines): Pionowe paski reprezentujące istnienie obiektu lub procesu w czasie.
- Fragmenty stanu: Prostokątne obszary na żyłce wskazujące stan obiektu (np. Aktywny, Nieczynny, Zablokowany, Przetwarzanie).
- Zdarzenia: Strzałki lub znaczniki wskazujące, kiedy występuje określona akcja, np. wysłanie sygnału lub wygaśnięcie timera.
Przyporządkowując te elementy, deweloperzy tworzą harmonogram operacji systemu. To wizualne kontekst jest kluczowy do zrozumienia, jak długo proces trwa do zakończenia i jak długo czeka na inne procesy. Przekształca abstrakcyjną logikę w konkretny harmonogram, który można analizować pod kątem błędów.
🏗️ Podstawowe filary niezawodności oprogramowania
Niezawodność w inżynierii oprogramowania odnosi się do prawdopodobieństwa, że system wykona swoje wymagane funkcje w określonych warunkach przez określony czas. Aby tego osiągnąć, należy rozważyć trzy główne filary:
- Dostępność: System musi być gotowy do działania w momencie potrzeby. Diagramy czasowe pomagają zweryfikować, czy procesy odzyskiwania kończą się w akceptowalnych oknach czasowych.
- Spójność: Dane muszą pozostawać dokładne na wszystkich rozproszonych węzłach. Wizualizacja operacji zapisu i odczytu pomaga zapewnić, że integralność danych nie zostanie naruszona przez opóźnienia.
- Wytrzymałość na uszkodzenia: System musi kontynuować działanie mimo awarii. Diagramy czasowe ilustrują, jak długo mechanizm zapasowy potrzebuje do aktywacji, zapewniając, że użytkownik nie odczuwa przerwania usługi.
Bez jasnego zrozumienia ograniczeń czasowych system może być logicznie poprawny, ale praktycznie niezawodny. Na przykład zapytanie do bazy danych może zwracać poprawne dane, ale jeśli trwa 10 sekund, narusza wymóg niezawodności interfejsu użytkownika reaktywnego. Diagramy czasowe ujawniają te naruszenia czasowe.
🐞 Wykrywanie warunków wyścigu poprzez analizę wizualną
Warunek wyścigu występuje, gdy dwa lub więcej procesów dostępne do danych współdzielonych jednocześnie, a końcowy wynik zależy od względnego czasu ich wykonania. Są one znane z trudności w debugowaniu, ponieważ są nieterministyczne i często znikają, gdy dołączamy debuger.
Diagramy czasowe zmniejszają ten ryzyko, wymuszając ściśle określony porządek wizualny zdarzeń. Podczas modelowania potencjalnego warunku wyścigu inżynier może narysować żyłki współbieżnych wątków. Jeśli diagram pokazuje, że oba wątki próbują jednocześnie zapisać dane w tym samym miejscu pamięci bez bariery synchronizacji, błąd jest od razu widoczny.
- Wizualizacja sekcji krytycznych: Wyróżnia okres, gdy zasób jest zablokowany. Jeśli inny proces próbuje uzyskać dostęp w tym oknie, diagram pokazuje konflikt.
- Identyfikacja zakłóceń: W interfejsach sprzętowo-oprogramowych zakłócenia sygnału mogą wystąpić, jeśli nie są spełnione czasy ustalania i utrzymywania. Diagramy czasowe jasno pokazują te okna.
- Zależności kolejności: Upewnij się, że inicjalizacja A zostanie ukończona przed rozpoczęciem inicjalizacji B. Diagram wymusza sprawdzenie czasowe tej zależności.
Rozwiązując te problemy w fazie projektowania, znacznie zmniejsza się prawdopodobieństwo awarii w środowisku produkcyjnym. Przesuwa wykrywanie błędów współbieżności z dzienników czasu działania do przeglądu projektu.
🧵 Zarządzanie współbieżnością i synchronizacją wątków
Nowoczesne aplikacje mocno opierają się na przetwarzaniu asynchronicznym w celu radzenia sobie z dużymi obciążeniami. Wątki, koreuty i puly workerów pozwalają na równoległe wykonywanie wielu zadań. Jednakże mechanizmy synchronizacji takie jak muteksy, semafory i blokady wprowadzają własne złożoności czasowe.
Diagramy czasowe pomagają modelować te punkty synchronizacji. Pomagają odpowiedzieć na pytania takie jak:
- Jak długo wątek czeka na blokadę przed wygaśnięciem?
- Czy czas nabycia blokady zależy od obciążenia systemu?
- Czy istnieją zakleszczenia, w których dwa wątki bez końca czekają na siebie nawzajem?
Podczas projektowania aplikacji wielowątkowej inżynierowie mogą narysować stan każdego wątku. Jeśli wątek A trzyma zasób 1 i czeka na zasób 2, a wątek B trzyma zasób 2 i czeka na zasób 1, diagram czasowy może ujawnić warunek cyklicznego oczekiwania. To dowód wizualny pozwala na przebudowę logiki nabycia zasobów przed rozpoczęciem implementacji.
Dodatkowo, diagramy czasowe wyjaśniają zachowanie odwrócenia priorytetów. W systemach czasu rzeczywistego zadanie o wysokim priorytecie może być blokowane przez zadanie o niskim priorytecie trzymające blokadę. Diagram czasowy czyni to odwrócenie priorytetów oczywistym, umożliwiając architektom zaimplementowanie protokołów dziedziczenia priorytetów.
🌐 Protokoły sieciowe i weryfikacja ustanowienia połączenia
W systemach rozproszonych opóźnienie sieciowe to zmienna, którą nie można zignorować. Protokoły takie jak TCP/IP, HTTP/2 i gRPC opierają się na ustanowieniu połączenia za pomocą wymiany pakietów. Diagramy czasowe są niezbędne do weryfikacji tych interakcji.
Rozważ standardową trzykrotną wymianę pakietów (SYN, SYN-ACK, ACK). Diagram czasowy pozwala inżynierom ustawić maksymalny dopuszczalny czas tej procedury. Jeśli diagram pokazuje, że ACK zajmuje dłużej niż skonfigurowany próg czasowy, połączenie prawdopodobnie nie przejdzie pod obciążeniem.
- Konfiguracja limitu czasu: Zdefiniuj dokładny czas w milisekundach dla żądania, przed wywołaniem ponownej próby.
- Logika ponownej transmisji: Wizualizuj odstęp między nieudanym pakietem a jego ponowną transmisją, aby upewnić się, że nie spowoduje to nadmiernego obciążenia sieci.
- Interwały keep-alive: Upewnij się, że odstęp między komunikatami keep-alive jest krótszy niż limit czasu bezczynności sieci, aby zapobiec przedwczesnemu rozłączeniu.
Modelując te interakcje sieciowe, zespoły mogą zapewnić, że ich oprogramowanie zgodnie radzi sobie z niestabilnością sieci. Zapobiega to zjawisku kaskadowych awarii, gdy powolna odpowiedź jednego mikroserwisu powoduje zawieszenie całego frontendu.
⚙️ Czasowanie interfejsu sprzętowo-programowego
Nieustalność oprogramowania często zależy od tego, jak dobrze oddziałuje z sprzętem. Systemy wbudowane, urządzenia IoT oraz platformy handlu高频owe wymagają precyzyjnego czasowania. Opóźnienie kilku mikrosekund może spowodować uszkodzenie danych lub straty finansowe.
Obsługa przerwań (ISRs) to doskonały przykład. Gdy występuje przerwanie sprzętowe, procesor musi zawiesić bieżące zadania, aby je obsłużyć. Diagram czasowy pokazuje opóźnienie przerwania (czas od żądania przerwania do wejścia do ISR) oraz czas reakcji na przerwanie.
- Opóźnienie przerwania: Czas potrzebny na potwierdzenie przerwania.
- Nadwyżka czasu przy zmianie kontekstu: Czas potrzebny na zapisanie i przywrócenie stanu podczas ISR.
- Zachowanie rejestrów: Zapewnienie, że stan zostanie zapisany przed modyfikacją przez ISR.
Jeśli wykres czasowy pokazuje, że ISR trwa zbyt długo, może blokować inne krytyczne przerwania. Ta analiza wizualna pozwala programistom zoptymalizować kod ISR lub przesunąć przetwarzanie na wątek tła, zapewniając spełnienie wymagań czasu rzeczywistego.
📉 Identyfikacja problemów z opóźnieniem i fluktuacją
Opóźnienie to opóźnienie przed rozpoczęciem przesyłania danych po wydaniu polecenia do przesłania. Fluktuacja to zmienność opóźnienia w czasie. Oba są szkodliwe dla doświadczenia użytkownika i stabilności systemu. Wykresy czasowe są głównym narzędziem do analizy tych metryk.
Podczas modelowania cyklu żądanie-odpowiedź inżynierowie mogą zaznaczać dokładne punkty, w których zachodzi przetwarzanie. Na przykład:
- Czas oczekiwania w kolejce: Jak długo żądanie czeka w buforze przed przetworzeniem?
- Czas przetwarzania: Jak długo logika faktycznie trwa wykonywanie?
- Przejazd przez sieć: Jak długo dane potrzebują, aby przejść przez przewód?
Sumując te odcinki, oblicza się całkowite opóźnienie. Jeśli fluktuacja jest duża, wykres czasowy pokaże nieregularne odstępy między zdarzeniami w wielu iteracjach. Ta nieregularność wskazuje na niestabilność infrastruktury podstawowej, co wymusza dalsze badania w zakresie konkurencji zasobów lub przeciążenia sieci.
📝 Dokumentowanie interakcji systemu
Dokumentacja często jest pomijana w poszukiwaniu funkcjonalności, ale jest kluczowa dla długoterminowej niezawodności. Kod często się zmienia, a nowi członkowie zespołu regularnie dołączają. Wykresy czasowe są trwałą referencją, jak system zachowuje się w czasie.
Dobrze utrzymany zestaw wykresów czasowych zapewnia:
- Materiał wstępnego wdrażania:Nowi programiści mogą zrozumieć przepływ czasowy bez czytania tysięcy linii kodu.
- Pomoc w debugowaniu:Gdy występuje błąd, inżynierowie mogą porównać rzeczywiste zachowanie z zapisanym wykresem czasowym, aby wykryć odstępstwa.
- Definicja kontraktu: Określają oczekiwane zachowanie między usługami, działając jako kontrakt integracyjny.
Ta dokumentacja zmniejsza obciążenie poznawcze inżynierów podczas reagowania na incydenty. Zamiast zgadywać o czasie zdarzeń, mają wizualną referencję do przestrzegania.
⚠️ Powszechne naruszenia czasowe
Nie wszystkie problemy czasowe są jednakowe. Niektóre to krytyczne awarie, inne to degradacja wydajności. Poniższa tabela kategoryzuje typowe naruszenia występujące w modelowaniu systemu.
| Typ naruszenia | Opis | Wpływ na niezawodność |
|---|---|---|
| Naruszenie czasu ustawienia | Dane nie są stabilne przed krawędzią zegara. | Nieprzewidywalne zmiany stanu, awaria sprzętu. |
| Naruszenie czasu utrzymania | Dane ulegają zmianie zbyt szybko po krawędzi zegara. | Zakłócenie danych, metastabilność. |
| Przekroczenie limitu czasu | Operacja trwa dłużej niż zdefiniowany limit. | Niedostępność usługi, burze ponownych prób. |
| Zawieszenie (zamknięcie) | Dwa procesy oczekują na siebie bez końca. | Zamrożenie systemu, niedobór zasobów. |
| Odwrócenie priorytetów | Zadanie o wysokim priorytecie oczekuje na zadanie o niskim priorytecie. | Przegrane terminy, awaria w czasie rzeczywistym. |
| Przepełnienie bufora | Dane przychodzą szybciej, niż mogą być przetworzone. | Utrata pakietów, wyczerpanie pamięci. |
Przeglądanie tych kategorii w kontekście diagramów czasowych systemu pomaga ustalić priorytety dla problemów wymagających natychmiastowego rozwiązania. Naruszenia sprzętowe często wymagają aktualizacji firmware, podczas gdy przekroczenia limitów czasu w oprogramowaniu mogą wymagać ponownej strukturyzacji logiki.
🔄 Integracja do cyklu życia rozwoju oprogramowania
Aby skutecznie wykorzystywać diagramy czasowe pod kątem niezawodności, muszą one zostać zintegrowane z cyklem życia rozwoju oprogramowania (SDLC). Nie powinny być dodatkowym elementem rozważanym dopiero po wdrożeniu.
- Faza projektowania: Twórz diagramy czasowe najwyższego poziomu podczas przeglądu architektury systemu. Zidentyfikuj krytyczne ścieżki i ograniczenia czasowe.
- Faza wdrożenia: Używaj diagramów czasowych do kierowania testami jednostkowymi. Upewnij się, że testy jednostkowe obejmują granice czasowe, a nie tylko poprawność logiczną.
- Faza integracji: Przeprowadź analizę czasową na zintegrowanych komponentach. Upewnij się, że zintegrowany system spełnia globalne wymagania czasowe.
- Faza testowania: Użyj narzędzi testowania obciążenia do generowania danych czasowych. Porównaj rzeczywiste logi czasowe z oryginalnymi diagramami.
- Faza utrzymania: Aktualizuj diagramy, gdy zmiany kodu wpływają na czas. Upewnij się, że dokumentacja pozostaje zsynchronizowana z kodem źródłowym.
Ta integracja zapewnia, że rozważania dotyczące czasu są częścią rozmowy na każdym etapie, zmniejszając koszt naprawy problemów z niezawodnością na późniejszych etapach procesu.
📊 Pomiar poprawy niezawodności
Jak możesz zilustrować korzyści z wykorzystania diagramów czasowych? Choć niezawodność często mierzy się w procentach czasu działania, diagramy czasowe przyczyniają się do konkretnych metryk:
- Średni czas między awariami (MTBF): Zapobiegając warunkom wyścigu i zakleszczeniom, częstotliwość awarii zmniejsza się.
- Średni czas naprawy (MTTR): Lepsza dokumentacja i wizualne logi zmniejszają czas potrzebny do diagnozowania problemów.
- Percentyle opóźnień: Opóźnienia P99 i P999 stają się bardziej stabilne, gdy wczesne wykrywanie węzłów zakłóceń czasowych.
- Wykorzystanie zasobów:Optymalizacja czasów oczekiwania zmniejsza czas bezczynności procesora i poprawia ogólną przepustowość.
Śledzenie tych metryk w czasie pozwala zespołom zobaczyć bezpośrednią korelację między dokładnym modelowaniem czasu a stabilnością systemu. Przenosi niezawodność z jakościowego celu do rzeczywistości ilościowej.
💡 Podsumowanie najlepszych praktyk
Aby maksymalnie wykorzystać wpływ diagramów czasowych na niezawodność oprogramowania, przestrzegaj poniższych praktyk:
- Określ jasne jednostki czasu: Zawsze określ jednostkę czasu (ms, s, cykle), aby uniknąć niejasności.
- Uwzględnij stany błędów: Modeluj nie tylko drogę sukcesu, ale także drogi wygaśnięcia czasu i obsługi błędów.
- Skup się na kluczowych ścieżkach: Nie rysuj każdej pojedynczej operacji. Skup się na interakcjach wpływających na stabilność systemu.
- Używaj spójnej notacji: Używaj standardowej notacji dla linii życia i zdarzeń, aby zapewnić zrozumienie przez cały zespół.
- Automatyzuj tam, gdzie to możliwe: Zintegruj narzędzia analizy czasu do potoku CI/CD, aby automatycznie wykrywać regresje.
Niezawodność oprogramowania to ciągła praca. Wymaga ona czujności, dokładnego modelowania oraz głębokiego zrozumienia, jak czas wpływa na zachowanie systemu. Diagramy czasowe zapewniają klarowność wizualną potrzebną do poruszania się w tej złożoności. Przyjmując te praktyki, zespoły inżynieryjne mogą budować systemy, które są nie tylko funkcjonalne, ale również wytrzymałe, przewidywalne i odporności na niestabilny charakter czasu.
Kiedy wizualizujesz czas, nabierasz nad nim kontrolę. Ta kontrola bezpośrednio przekłada się na niezawodność. W miarę jak systemy stają się bardziej rozproszone i złożone, umiejętność modelowania relacji czasowych staje się przewagą konkurencyjną. Oddziela systemy, które po prostu działają, od systemów, które działają spójnie pod presją.