











Na tle współczesnej analizy biznesowej jasność nie jest jedynie luksusem; jest koniecznością. Organizacje zmagały się z przepływami pracy obejmującymi wiele działów, systemy dziedziczne oraz interakcje ludzkie. Gdy złożoność rośnie, wzrasta ryzyko nieporozumień. To właśnie tutaj techniki modelowania strukturalnego stają się niezbędne. W szczególności schemat przepływu danych (DFD) oferuje solidny sposób wizualizacji ruchu informacji w systemie. Poprzez rozkładanie złożonych procesów biznesowych analitycy mogą rozłożyć przeważające zadania na zarządzalne, logiczne elementy. Niniejszy przewodnik omawia mechanizmy, zasady oraz strategiczne zastosowanie DFD w rozkładaniu procesów.
Zrozumienie podstaw schematów przepływu danych 🧩
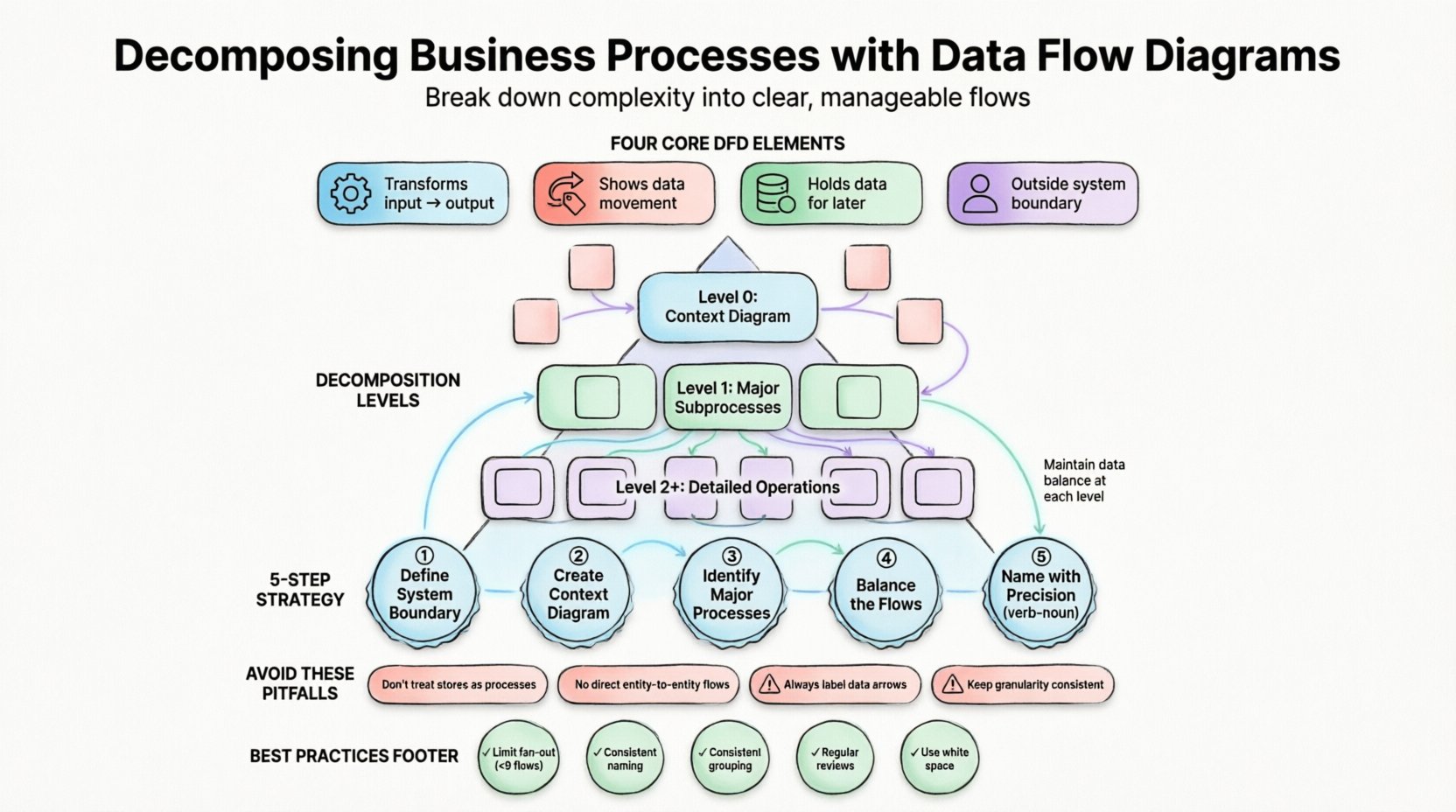
Schemat przepływu danych to graficzne przedstawienie przepływu danych przez system informacyjny. W przeciwieństwie do schematów blokowych, które często przedstawiają logikę sterowania lub kroki proceduralne, DFD skupia się ściśle na danych. Ilustrują one, skąd pochodzą dane, gdzie są przechowywane, jak są przekształcane oraz gdzie w końcu opuszczają system. Ta różnica jest kluczowa dla analityków biznesowych, którzy muszą zrozumieć istotę działań, a nie tylko sekwencję zdarzeń.
Strukturalne DFD opierają się na określonym zapisie, aby zapewnić spójność w dokumentacji. Schemat opiera się na czterech podstawowych elementach:
- Procesy:Działania, które przekształcają dane wejściowe w dane wyjściowe. Są one zazwyczaj przedstawiane jako zaokrąglone prostokąty lub okręgi. Opisującozdarza się z danymi.
- Przepływy danych:Ruch danych między procesami, magazynami i jednostkami. Są one przedstawiane jako strzałki i muszą być jasno oznaczone, aby wskazać zawartość przemieszczaną.
- Magazyny danych:Miejsca, gdzie dane są przechowywane do późniejszego użytku. Są to prostokąty z otwartym końcem lub równoległe linie. Odpowiadają bazom danych, plikom lub fizycznym archiwizacjom.
- Zewnętrzne jednostki:Źródła lub miejsca docelowe danych poza granicami systemu. Są to kwadraty lub prostokąty i reprezentują użytkowników, inne systemy lub organizacje.
Bez znormalizowanego podejścia te schematy mogą stać się chaotyczne. Strukturalne DFD nakładają dyscyplinę, która zapewnia, że każdy przepływ danych ma źródło i cel, a każdy proces logicznie przekształca dane.
Pilność rozkładania 🔨
Złożone procesy biznesowe rzadko mieszczą się na jednej stronie. Próba zmapowania całej operacji przedsiębiorstwa w jednym widoku prowadzi do schematu niezrozumiałego dla stakeholderów. Rozkładanie to technika używana do rozbicia procesu najwyższego poziomu na szczegółowe elementy niższych poziomów. Ten podejście hierarchiczne pozwala analitykom zarządzać obciążeniem poznawczym i utrzymywać precyzję.
Rozkładanie spełnia kilka kluczowych funkcji:
- Kontrola szczegółowości: Pozwala zespołowi przyjrzeć się konkretnym obszarom zainteresowania, nie tracąc przy tym widoku ogólnego kontekstu.
- Wyrównanie stakeholderów: Różni stakeholderzy wymagają różnych poziomów szczegółowości. Dyrektorzy mogą oglądać schemat najwyższego poziomu, podczas gdy programiści potrzebują szczegółowych podprocesów.
- Wykrywanie błędów: Złożone interakcje stają się łatwiejsze do wykrycia, gdy są izolowane. Niezgodności danych lub brakujące przepływy są bardziej widoczne na niższych poziomach.
- Modułowość: Zachęca do myślenia w kategoriach dyskretnych funkcji, co dobrze pasuje do nowoczesnej architektury oprogramowania i mikroserwisów.
Proces rozkładania nie jest dowolny. Postępuje według logicznego schematu, w którym proces nadrzędny jest rozwijany na procesy potomne, które razem objaśniają wszystkie dane wpływające do i opuszczające proces nadrzędny.
Poziomy rozkładania w strukturalnych DFD 📈
Aby zachować strukturę, DFD są zwykle organizowane na poziomy. Ta hierarchia zapewnia, że abstrakcja pozostaje spójna w miarę dodawania szczegółów. Poniższa tabela przedstawia standardowe poziomy rozkładania:
| Poziom | Nazwa wspólna | Opis |
|---|---|---|
| 0 | Diagram kontekstowy | Pokazuje całą system jako pojedynczy proces oddziałujący z zewnętrznymi jednostkami. |
| 1 | Diagram poziomu 0 | Rozdziela główny proces na główne podprocesy (zazwyczaj 3 do 9). |
| 2 | Diagramy poziomu 1 | Dalsze rozkładanie określonych procesów poziomu 0 na szczegółowe operacje. |
| 3+ | Diagramy potomne | Głęboka analiza złożonej logiki w celu szczegółów implementacji. |
Każdy poziom musi przestrzegać zasadyzrównoważenie danych. Oznacza to, że wejścia i wyjścia procesu nadrzędnego muszą dokładnie odpowiadać połączeniu wejść i wyjść jego procesów potomnych. Jeśli proces poziomu 0 ma wejście „Dane zamówienia”, procesy poziomu 1 muszą wspólnie przyjąć „Dane zamówienia” i nie mogą wprowadzać nowych zewnętrznych wejść bez uzasadnienia.
Krok po kroku strategia dekompozycji 🚀
Wykonywanie dekompozycji wymaga systematycznego podejścia. Pośpiech w rysowaniu strzałek często prowadzi do błędów strukturalnych. Poniższy przepływ pracy zapewnia solidną strukturę diagramu.
1. Zdefiniuj granice systemu
Zanim narysujesz cokolwiek, określ, co znajduje się wewnątrz systemu, a co na zewnątrz. Ta granica definiuje zakres projektu. Jednostki zewnętrzne znajdują się poza tą granicą. Wszystko, co dzieje się wewnątrz granicy, to proces lub magazyn. Ta definicja zapobiega rozszerzaniu zakresu podczas fazy analizy.
2. Stwórz diagram kontekstowy
Zacznij od widoku najwyższego poziomu. Umieść system jako pojedynczą kropkę w centrum. Zidentyfikuj główne jednostki zewnętrzne, które z nim współpracują. Narysuj główne przepływy danych między nimi. Ten diagram zapewnia „widok z helikoptera” dla stakeholderów w celu potwierdzenia zakresu.
3. Zidentyfikuj główne procesy
Spójrz na przepływy danych wchodzące do systemu i wychodzące z niego. Każda odrębna transformacja sugeruje główny proces. Na przykład, jeśli „Dane klienta” wchodzą, a „Dane faktury” wychodzą, transformacja to prawdopodobnie „Wygeneruj fakturę”. Zgrupuj je w logiczne grupy.
4. Zrównowaguj przepływy
Podczas dekompozycji procesu sprawdź wejścia i wyjścia. Upewnij się, że żadne dane nie znikają (czarna dziura) i że żadne dane nie pojawiają się znikąd (czarodziejstwo). Każda strzałka wchodząca do podprocesu musi być wyjaśniona przez dane wychodzące z niego.
5. Nadawaj nazwy z precyzją
Oznaczanie często pomijane, ale jest kluczowe dla czytelności. Nazwy procesów powinny być złożone z czasownika i rzeczownika, np. „Weryfikuj zamówienie” lub „Oblicz podatek”. Unikaj nieprecyzyjnych etykiet takich jak „Przetwarzaj dane”. Etykieta musi opisywać konkretną przemianę, która zachodzi.
Typowe pułapki w modelowaniu procesów ⚠️
Nawet doświadczeni analitycy napotykają problemy podczas modelowania przepływów danych. Wczesne rozpoznanie tych wzorców może zaoszczędzić znaczne prace nad poprawką. Poniżej przedstawiono typowe błędy obserwowane podczas dekompozycji.
Magazyny danych jako procesy
Czytelnik może mieć ochotę traktować bazę danych jako proces, ponieważ dane interagują z nią. Jednak baza danych jest pasywnym magazynem. Nie przetwarza danych, tylko je przechowuje. Proces musi być związany z czasownikiem działania. Magazyn jest dostępnym dla procesu, a nie sam jest procesem.
Połączenie jednostek bezpośrednio
Dane nie mogą przepływać bezpośrednio z jednej jednostki zewnętrznej do drugiej bez przechodzenia przez system. Jeśli klient wysyła żądanie i otrzymuje odpowiedź, dane muszą wejść do procesu, zostać przetworzone, a następnie wyjść. Bezpośrednia linia między dwiema jednostkami oznacza, że są one tym samym obiektem lub system jest pomijany.
Nieoznaczone przepływy danych
Strzałka bez etykiety jest bez znaczenia. Nie wskazuje, jaką informację przemieszcza się. Każdy przepływ musi być oznaczony, np. „Adres wysyłki” lub „Status płatności”. Niejasność tutaj prowadzi do błędów w implementacji w przyszłości.
Niespójna szczegółowość
Jeden proces może być szczegółowy, podczas gdy sąsiedni proces jest niejasny. Ta niespójność zmyli odbiorcę. Jeśli jeden podproces jest rozbity na trzy kroki, sąsiednie procesy powinny mieć porównywalny poziom szczegółowości, chyba że są z natury prostsze.
Integracja DFD z wymaganiami biznesowymi 📝
Diagram ma sens tylko wtedy, gdy odzwierciedla rzeczywiste potrzeby biznesowe. Diagramy przepływu danych nie mogą istnieć w próżni. Powinny stanowić wizualną podstawę dokumentacji wymagań. Gdy wymaganie mówi, że „System musi weryfikować karty kredytowe”, diagram DFD powinien pokazywać proces weryfikacji odbierający dane karty i zwracający flagę statusu.
Taka śledzenie jest kluczowe dla audytu i zgodności. W branżach regulowanych możliwość udowodnienia, skąd pochodzą dane i jak są chronione, jest obowiązkowa. Diagram DFD stanowi mapę do przeglądów bezpieczeństwa. Analitycy mogą identyfikować miejsca przepływu danych poufnych i zapewniać odpowiednie kontrole na poziomie procesu.
Najlepsze praktyki w modelowaniu strukturalnym ✅
Aby utrzymać wysoką jakość diagramów, przestrzegaj poniższych najlepszych praktyk. Te zasady wspierają spójność i ułatwiają utrzymanie.
- Ogranicz rozgałęzienie:Unikaj łączenia jednego procesu z więcej niż dziewięcioma przepływami danych. Jeśli proces jest tak skomplikowany, najprawdopodobniej wymaga dalszej dekompozycji.
- Spójne nazewnictwo:Używaj tej samej terminologii dla przepływów danych na wszystkich poziomach. Jeśli na poziomie 0 użyto „Danych zamówienia”, nie nazywaj tego „Żądaniem klienta” na poziomie 1.
- Logiczne grupowanie:Grupuj powiązane procesy razem. Jeśli zestaw procesów zawsze obsługuje dane finansowe, zachowaj je wizualnie skupione, aby ułatwić zrozumienie.
- Regularnie przeglądarka:Procesy biznesowe się zmieniają. Diagram DFD to dokument żywy. Zaprojektuj okresowe przeglądy, aby upewnić się, że diagram odzwierciedla aktualne działania.
- Używaj pustego miejsca:Nie gromadź elementów razem. Wystarczająca przestrzeń zmniejsza obciążenie poznawcze i ułatwia odczyt diagramu.
Rola dekompozycji w projektowaniu systemu 🏗️
Poza dokumentacją, dekompozycja DFD wpływa na sposób budowy systemów. Gdy procesy są jasno zdefiniowane, zespoły programistyczne mogą przypisać moduły konkretnym programistom lub zespołom. Ta moduowość zmniejsza zależności między zespołami. Jeśli proces A i proces B są niezależne, mogą być rozwijane równolegle.
Dodatkowo, dekompozycja pomaga w identyfikacji węzłów zakłócających wydajność. Jeśli określony podproces zużywa nadmiernie zasoby lub wprowadza istotne opóźnienia, staje się celem optymalizacji. Bez dekompozycji węzeł zakłócający jest ukryty w monolitycznym obrazie systemu.
Zapewnia również wsparcie dla strategii testowania. Przypadki testowe mogą być bezpośrednio wyprowadzone z przepływów danych. Jeśli proces przekształca „Wejście A” w „Wyjście B”, przypadek testowy musi zweryfikować tę konkretną transformację. Ta zgodność między projektem a testowaniem zapewnia wyższą jakość dostarczania.
Obsługa procesów równoległych i pętli 🔄
Rzeczywiste procesy biznesowe często obejmują pętle i działania współbieżne. Standardowy DFD przedstawia logikę liniowo, ale zasady biznesowe mogą być iteracyjne. Na przykład zamówienie może wymagać wielu kroków weryfikacji przed zatwierdzeniem. Na diagramie jest to przedstawione przepływami danych, które powracają do wcześniejszych procesów.
Podczas modelowania pętli kluczowe jest jasne przedstawienie. Upewnij się, że warunek pętli jest zapisany w opisie procesu, a nie tylko sugerowany przez strzałkę. Przepływ powracający do procesu wskazuje na cykl ponownej pracy lub ponowną weryfikację. Jasne określenie warunku powrotu zapobiega niejasnościom dla zespołu programistów.
Procesy współbieżne są przedstawiane za pomocą równoległych przepływów. Jeśli dwa procesy zachodzą jednocześnie, narysuj je na osobnych gałęziach. Pamiętaj jednak, że DFD nie pokazuje czasu ani punktów synchronizacji. Ten poziom szczegółowości należy do innych notacji modelowania. DFD skupia się na istnieniu przepływu, a nie na jego czasie.
Ostateczne rozważania dla analityków 🤔
Opanowanie sztuki rozkładania wymaga praktyki i cierpliwości. Jest to umiejętność rozwijająca się z czasem, gdy analitycy napotykają różne typy logiki biznesowej. Celem nie jest stworzenie najbardziej szczegółowego diagramu, ale najbardziej użytecznego.
Pamiętaj, że diagram jest narzędziem komunikacyjnym. Jego głównym odbiorcą są często nietechniczni stakeholderzy, którzy muszą zrozumieć przepływ informacji. Jeśli diagram jest zbyt techniczny, nie spełnia swojego celu. Dopasuj poziom abstrakcji do poziomu wiedzy odbiorców.
Dokumentacja powinna zawsze wspierać proces podejmowania decyzji. Gdy lider biznesowy pyta, skąd pochodzi określony punkt danych, DFD powinien szybko udzielić odpowiedzi. Ta wiarygodność buduje zaufanie do funkcji analizy. Z czasem zbiór diagramów staje się cennym aktywem organizacji, stanowiąc odniesienie do przyszłych zmian systemu.
W miarę jak systemy się rozwijają, diagramy muszą się rozwijać razem z nimi. Utrzymanie nieaktualnych diagramów jest gorsze niż ich brak, ponieważ prowadzi do błędnego rozumienia. Postanów dbać o integralność modeli przepływu danych. Traktuj je z tą samą starannością, jak kod, który w końcu zostanie napisany w ich obsługę. Ta dyscyplina zapewnia, że logika biznesowa pozostaje przejrzysta i dostępna.
W końcu wartość tkwi w uzyskanej przejrzystości. Przez rozkładanie złożonego na zrozumiałe analitycy wzbogacają swoje organizacje, umożliwiając im działanie bardziej efektywne. Strukturalny podejście Diagramów Przepływu Danych zapewnia ramy dla tej przejrzystości, zamieniając chaos na porządek.