











W nowoczesnej architekturze oprogramowania zrozumienie, jak informacje się poruszają, jest równie ważne, jak zrozumienie, jak są przechowywane. Diagram przepływu danych (DFD) pełni rolę projektu tego ruchu, mapując podróż danych od wejścia do wyjścia. Przy projektowaniu systemów przeznaczonych do obsługi wzrostu, te diagramy ewoluują z prostych szkiców do złożonych map, które decydują o wydajności, niezawodności i utrzymywalności. Niniejszy przewodnik bada kluczowe wzorce używane do modelowania przepływów danych w skalowalnych środowiskach.
Skalowalność to nie tylko dodawanie więcej serwerów; to przekształcanie sposobu, w jaki dane przemieszczają się przez system, aby uniknąć węzłów zakłóceń. Przy użyciu określonych wzorców DFD architekci mogą wizualizować limity pojemności przed tym, jak stają się problemami produkcyjnymi. Ten podejście zapewnia, że logiczny przepływ informacji wspiera zarówno obecne wymagania, jak i przyszłe rozszerzenia.
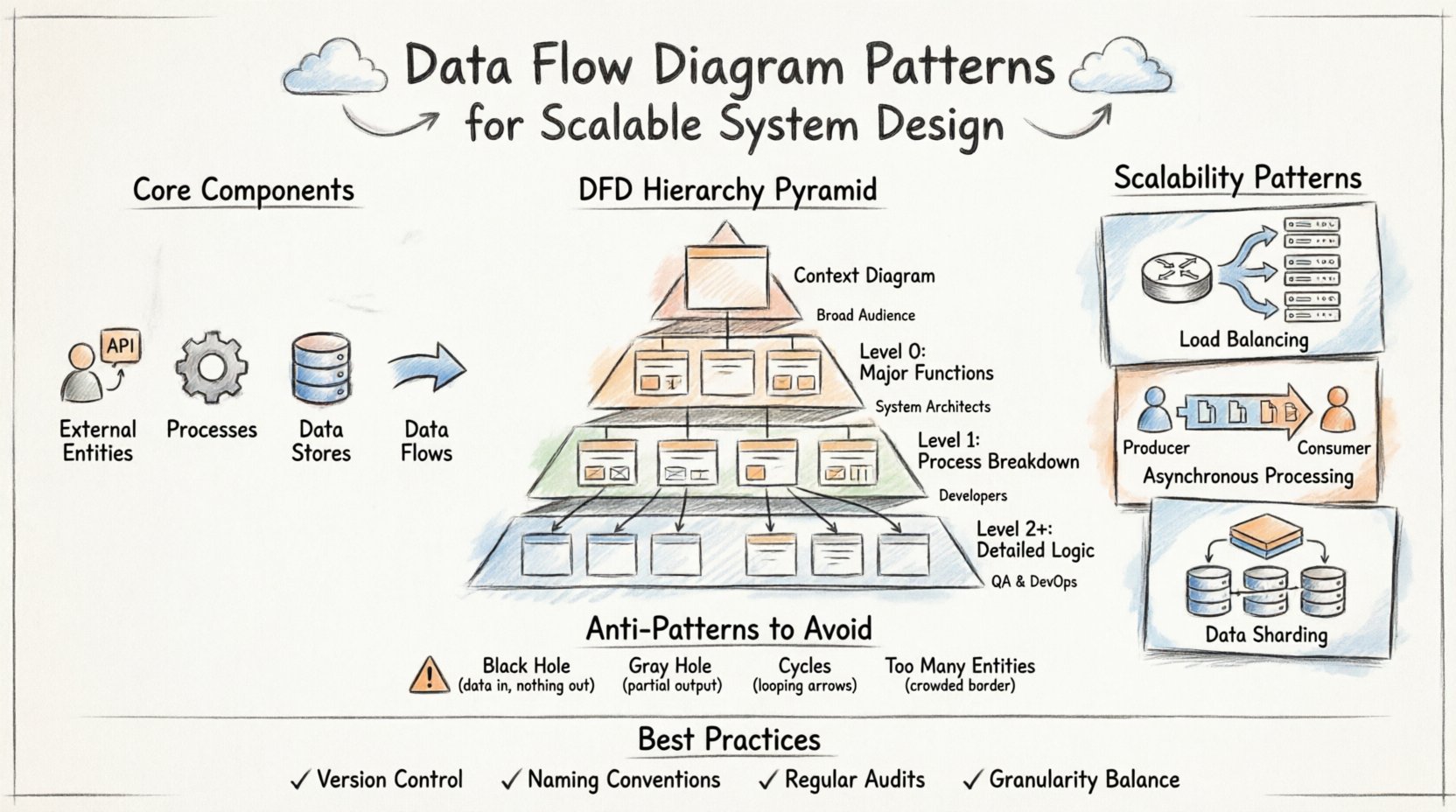
🧩 Podstawowe elementy diagramu przepływu danych
Zanim przejdziemy do wzorców, należy opanować elementy budowlane. Każdy DFD opiera się na czterech podstawowych elementach. Pomylenie ich prowadzi do niejasnych modeli, które nie skutecznie prowadzą rozwoju.
- Zewnętrzne jednostki: Oznaczają źródła lub miejsca docelowe poza granicami systemu. Do nich należą użytkownicy, interfejsy API firm trzecich lub urządzenia sprzętowe.
- Procesy: Przekształcają dane z jednej postaci w drugą. Są to aktywne obliczenia lub punkty logiki biznesowej wewnątrz systemu.
- Magazyny danych: Miejsca, gdzie dane spoczywają w spoczynku. Mogą to być bazy danych, systemy plików lub pamięci podręczne.
- Przepływy danych: Ścieżki, które dane przebywają między jednostkami, procesami i magazynami. Strzałki wskazują kierunek i zawartość.
Każdy element musi być jasno zdefiniowany, aby uniknąć niejasności. Na przykład proces nigdy nie powinien mieć strzałki wskazującej na inny proces bez odpowiedniego przepływu danych. Każda strzałka musi reprezentować rzeczywistą informację przemieszczającą się przez system.
📉 Hierarchia poziomów DFD
Systemy skalowalne wymagają różnych poziomów abstrakcji. Jedno diagram rzadko oddaje całą złożoność. Zamiast tego stosuje się hierarchię, aby przejść od ogólnego kontekstu do szczegółowej logiki implementacji. Ta struktura pozwala zespołom przeglądać całość bez utraty orientacji w szczegółach.
| Poziom | Skupienie | Złożoność | Główna grupa docelowa |
|---|---|---|---|
| Diagram kontekstowy | Granica systemu i interakcje zewnętrzne | Niska | Zainteresowane strony, zarządzanie |
| Poziom 0 (DFD 0) | Główne funkcje systemu i magazyny danych | Średnia | Architekci systemów |
| Poziom 1 | Rozbicie procesów poziomu 0 | Wysoki | Programiści, inżynierowie |
| Poziom 2+ | Specyficzna logika algorytmiczna lub podprocesu | Bardzo wysoki | Specjalistyczni inżynierowie |
Zachowanie spójności na tych poziomach jest kluczowe. Magazyn danych zidentyfikowany na poziomie 0 musi być poprawnie odwoływany na poziomie 1. Jeśli proces jest podzielony na poziomie 1, przepływy wejściowe i wyjściowe muszą odpowiadać procesowi nadrzędnemu na poziomie 0. To równowaga zapewnia, że model pozostaje wiarygodnym źródłem informacji przez cały cykl życia.
🚀 Wzorce skalowalności w architekturze systemu
Projektowanie z myślą o skalowalności wymaga konkretnych wyborów modelowania. Standardowe schematy często ukrywają mechanizmy obsługi obciążenia. Aby rozwiązać problem skalowalności, architekci muszą jawnie przedstawić wzorce rozkładania pracy lub zarządzania zasobami.
1. Rozkład obciążenia i dystrybucja
W systemach o wysokim ruchu pojedynczy proces nie może obsłużyć wszystkich przychodzących żądań. DFD musi odzwierciedlać mechanizm dystrybucji.
- Wzorzec routera: Wprowadź węzeł procesu, który kieruje ruch do wielu węzłów usług.
- Replikacja: Pokaż wiele identycznych procesów otrzymujących ten sam przepływ danych do przetwarzania równoległego.
- Kolejkowanie: Przedstaw magazyn danych działający jako bufor przed rozpoczęciem przetwarzania, wygładzając szczyty obciążenia.
Podczas rysowania routera upewnij się, że przepływ dzieli się logicznie. Jeśli system wykorzystuje strategię round-robin, schemat powinien wskazywać, że decyzja opiera się na obciążeniu, a nie na zawartości danych. Ta różnica ma wpływ na sposób implementacji logiki backendu.
2. Przetwarzanie asynchroniczne
Przepływy synchroniczne mogą tworzyć węzły zatyczki, jeśli jedna operacja czeka na drugą. Wzorce asynchroniczne rozdzielają procesy, umożliwiając niezależne skalowanie systemu.
- Kolejki komunikatów: Użyj magazynu danych do przedstawienia kolejki. Producent zapisuje do magazynu, a konsument odczytuje dane później.
- Strumienie zdarzeń: Pokaż proces emitujący zdarzenie, które aktywuje wiele konsumentów dolnych bez blokowania nadawcy.
- Zadania w tle: Oddziel długotrwałe zadania od żądań użytkownika, kierując je do dedykowanego puli procesów.
To rozdzielenie pozwala procesom skierowanym do użytkownika pozostawać lekkimi, podczas gdy ciężka praca odbywa się w tle. DFD czyni to rozdzielenie widoczne, zapobiegając programistom zakładaniu natychmiastowych czasów odpowiedzi.
3. Fragmentacja danych i partycjonowanie
Wraz ze wzrostem objętości danych jednostki przechowywania stają się barierami wydajności. Wzorce fragmentacji w DFD pomagają wizualizować, jak dane są dzielone między wiele magazynów.
- Podziały poziome: Pokazuje proces, który kieruje określonymi zestawami danych do różnych magazynów danych na podstawie identyfikatora lub klucza.
- Kopie odczytowe:Wskazuje osobne przepływy odczytu danych z kopii odczytowych, podczas gdy zapisy są kierowane do głównego magazynu.
- Warstwy buforowania:Wstawia magazyn danych bufora między proces a główną bazę danych w celu zmniejszenia opóźnienia.
| Wzorzec | Zysk skalowalności | Zalety i wady |
|---|---|---|
| Rozdzielanie obciążenia | Zwiększa przepustowość | Zwiększone złożenie zarządzania stanem |
| Asynchroniczne kolejki | Odłącza zależności | Konsystencja ostateczna |
| Fragmentacja | Rozszerza pojemność magazynowania | Złożone zapytania między fragmentami |
| Buforowanie | Zmniejsza opóźnienie | Ryzyko użycia przestarzałych danych |
⚠️ Powszechne wzorce do unikania
Nawet z dobrymi intencjami, DFD mogą zawierać błędy strukturalne prowadzące do awarii systemu. Wczesne rozpoznanie tych wzorców zapobiega kosztownemu przepisaniu kodu w przyszłości.
1. Czarna dziura
Czarna dziura występuje, gdy proces otrzymuje dane, ale nie generuje żadnego wyjścia. Zdarza się to często, gdy proces jest uznawany za usuwający dane lub przetwarzający je w sposób niezauważalny.
- Ryzyko:Utrata danych bez powiadomienia o błędzie.
- Rozwiązanie: Upewnij się, że każdy wejściowy przepływ ma odpowiadający mu przepływ wyjściowy lub jasną ścieżkę błędu.
- Wpływ na skalowalność:Ciche błędy są trudne do diagnozowania w systemach rozproszonych.
2. Szaraj Dziura
Szaraj dziura przypomina czarną dziurę, ale z częściowym wyjściem. Proces zużywa więcej danych niż generuje, ale nie wyjaśnia, co stało się z resztą.
- Ryzyko:Nieobjaśnione zużycie danych prowadzi do wycieków pamięci lub błędów transakcji.
- Rozwiązanie:Jawnie modeluj wszystkie ścieżki danych, w tym dzienniki błędów lub śledzenie operacji.
3. Pętle w przepływie danych
Choć niektóre pętle zwrotne są konieczne (np. mechanizmy ponownych prób), niekontrolowane pętle mogą powodować nieskończone pętle przetwarzania.
- Ryzyko:Zawieszenie systemu lub wyczerpanie zasobów.
- Rozwiązanie:Ogranicz głębokość rekursji na diagramie i zaimplementuj mechanizmy timeout w projekcie.
4. Nieskończone jednostki zewnętrzne
Zbyt wiele jednostek zewnętrznych sprawia, że diagram jest nieczytelny i zakrywa podstawową logikę.
- Ryzyko:Zagubienie jasności dotyczącej granic systemu.
- Rozwiązanie:Grupuj powiązane jednostki w jedną jednostkę „Systemu Rekordów” lub „Interfejsu Użytkownika”, gdy to odpowiednie.
🔄 Najlepsze praktyki utrzymania i ewolucji
Diagram przepływu danych nie jest jednorazowym produktem. Musi ewoluować wraz z rozwojem systemu. Zachowanie dokładności modelu zapewnia, że nowi członkowie zespołu zrozumieją architekturę bez konieczności odwrotnej analizy kodu.
- Kontrola wersji:Traktuj diagramy jak kod. Przechowuj je w repozytorium, aby śledzić zmiany w czasie.
- Zasady nazewnictwa:Używaj spójnego nazewnictwa dla procesów i przepływów danych. „Aktualizuj Użytkownika” powinien zawsze być „Aktualizuj Użytkownika”, a nie „Zmień szczegóły użytkownika”.
- Regularne audyty:Zaplanuj okresowe przeglądy, aby upewnić się, że diagram odpowiada aktualnej implementacji.
- Zrównoważenie szczegółowości:Nie przekształcaj każdego procesu w podproces. Grupuj powiązane logiki, aby zachować przejrzysty obraz systemu.
📝 Ostateczne rozważania
Skuteczny projekt systemu opiera się na jasnej komunikacji. Diagram przepływu danych zapewnia wspólny język między architektami, programistami i stakeholderami. Przestrzegając ustanowionych wzorców i unikając typowych pułapek, zespoły mogą budować systemy, które rosną harmonijnie.
Pamiętaj, że schematy to modele, a nie rzeczywistość sama w sobie. Uproszczają złożoność, aby była zrozumiała. Jednak uproszczenie nie może usuwać istotnych szczegółów dotyczących integralności i przepływu danych. Gdy DFD poprawnie odzwierciedla ruch danych, staje się potężnym narzędziem do przewidywania zatorów i optymalizacji wydajności.
W miarę jak systemy stają się bardziej rozproszone, rośnie potrzeba szczegółowego modelowania. Wzorce opisane tutaj stanowią podstawę tego szczegółowego podejścia. Niezależnie od tego, czy projektujesz aplikację monolityczną, czy ekosystem mikroserwisów, zasady przepływu danych pozostają niezmienne. Skup się na przepływie informacji, a struktura sam się uformuje.
Zacznij od diagramu kontekstowego. Jasnookreśl granice. Przechodź do szczegółów procesów tylko wtedy, gdy jest to konieczne. Zachowaj skupienie na danych, a nie na stosie technologii. Ta dyscyplina zapewnia, że architektura pozostanie elastyczna i skalowalna przez wiele lat.