











Tworzenie solidnych modeli systemów wymaga dyscyplinowanego podejścia do zapisywania, przemieszczania i przechowywania informacji. W kontekście schematów przepływu danych (DFD) magazyn danych stanowi fundament trwałości systemu. Bez jasnego projektu, gdzie przechowywane są dane, przepływ informacji pozostaje abstrakcyjny i niemożliwy do zaimplementowania. Niniejszy przewodnik omawia podstawowe zasady projektowania magazynów danych w DFD, zapewniając jasność, dokładność oraz zgodność z architekturą systemu.
Skuteczne modelowanie idzie dalej niż rysowanie linii między kształtami. Wymaga głębokiego zrozumienia integralności danych, wzorców dostępu oraz cyklu życia informacji w systemie. Przestrzegając ustanowionych zasad projektowych, analitycy mogą tworzyć schematy, które stanowią wiarygodne projekty dla zespołów programistycznych.
🏷️ Definiowanie magazynu danych 🏷️
Magazyn danych to element bierny w schemacie przepływu danych. W przeciwieństwie do procesów, które przekształcają dane, magazyny danych przechowują dane w stanie spoczynku. Odpowiadają plikom, bazom danych, papierowym rejestracjom lub dowolnemu magazynowi, w którym informacje są zapisywane do późniejszego odtworzenia.
- Charakter bierny: Dane nie opuszczają magazynu, chyba że proces jawnie o nie żąda.
- Tożsamość przechowywania: Nie jest procesem samym w sobie; nie zmienia danych, tylko je przechowuje.
- Reprezentacja wizualna: Zazwyczaj przedstawiany jako prostokąt z otwartym końcem lub dwiema pionowymi liniami, w zależności od użytej normy notacji.
Podczas projektowania tych elementów należy skupić się na wymaganiach logicznych, a nie fizycznej realizacji. DFD opisuje codane, które są potrzebne, a nie jaksą fizycznie indeksowane lub przechowywane na dysku twardym.
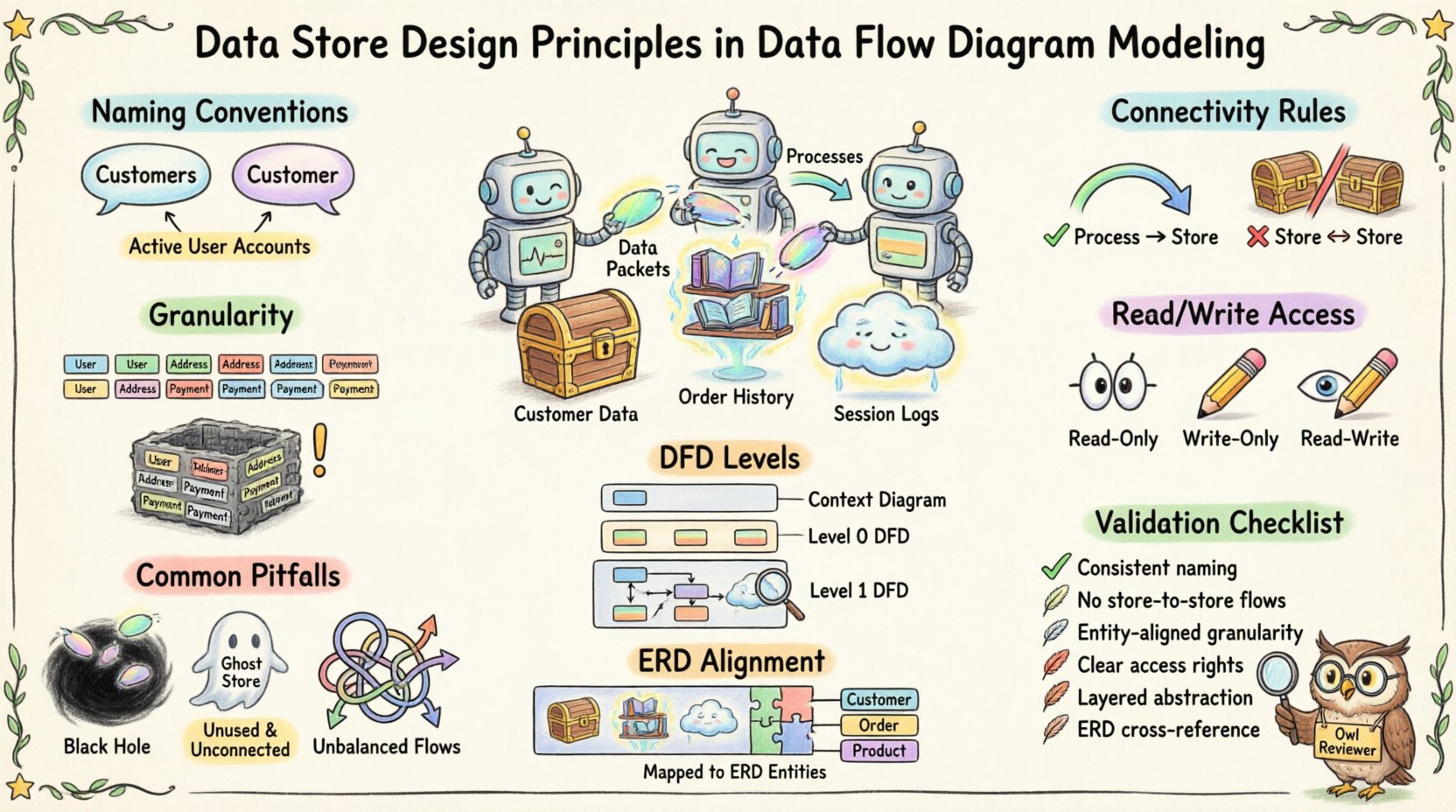
📝 Zasady nazewnictwa dla jasności 📝
Nazewnictwo jest pierwszą linii obrony przed zamieszaniem. Niejasne etykiety prowadzą do nieporozumień w fazie projektowania. Dobrze nazwany magazyn danych natychmiast daje kontekst informacji, które zawiera.
1. Liczba pojedyncza vs. mnoga
Spójność jest kluczowa. Niektóre zespoły preferują liczby pojedyncze (np. Klient), inne zaś używają liczby mnogiej (np. Klienci). Kluczowym czynnikiem jest to, że cały model używa tej samej konwencji.
- Zalecenie: Używaj liczb mnogich dla zbiorów danych (np. Zamówienia, Produkty) aby wskazać na zbiór.
- Wyjątek:Imiona liczby pojedynczej działają dla konkretnych przypadków, jeśli sklep przechowuje tylko jeden typ rekordu (np. Konfiguracja).
2. Precyzja opisowa
Unikaj ogólnych terminów takich jak Dane lub Informacje. Te etykiety nie dostarczają żadnych informacji o treści.
- Zły przykład: Dane systemu
- Dobry przykład: Aktywne konta użytkowników
Precyzyjne nazewnictwo pomaga stakeholderom natychmiast zidentyfikować zakres sklepu. Zmniejsza obciążenie poznawcze potrzebne do zrozumienia schematu.
3. Czas i stan
Nazwy powinny odzwierciedlać stan danych. Jeśli sklep przechowuje rekordy historyczne, nazwa powinna to odzwierciedlać.
- Dzienniki transakcji oznacza zapis przeszłych zdarzeń.
- Oczekujące zamówienia oznacza dane oczekujące na działanie.
🔗 Zasady łączenia 🔗
Ruch danych do i z magazynu regulowany jest ściśle zasadami logicznymi. Naruszenie tych zasad niszczy integralność DFD.
1. Wymóg połączenia z procesem
Magazyn danych musi zawsze być połączony z co najmniej jednym procesem. Nie może istnieć samodzielnie.
- Wejście: Proces musi zapisywać dane do magazynu (np. zapisywanie nowego rekordu).
- Wyjście: Proces musi odczytywać dane z magazynu (np. pobieranie rekordu).
Jeśli magazyn nie jest połączony z niczym, jest to element przyzwoity bez funkcji. Jeśli jest połączony z wieloma procesami, przepływ danych musi być jasno zdefiniowany dla każdego połączenia.
2. Brak bezpośredniego przepływu danych między sklepami
Dane nie mogą przemieszczać się bezpośrednio z jednego magazynu danych do drugiego bez procesu pośredniego. Ta zasada wprowadza zasadę, że przekształcanie danych lub ich weryfikacja odbywa się przed zapisaniem.
- Niepoprawnie: Linia łącząca Magazyn A bezpośrednio z Magazyn B.
- Poprawnie: Proces X odczytuje z Magazyn A, przekształca dane i zapisuje do Magazyn B.
To rozdzielenie zapewnia, że logika biznesowa, weryfikacja lub formatowanie są stosowane przed trwałym zapisaniem danych. Zapobiega to sugerowaniu, że dane są po prostu kopiowane bez nadzoru.
3. Etykietowanie przepływu danych
Każda linia łącząca proces z magazynem danych musi być oznaczona etykietą. Etiqueta opisuje konkretne dane przemieszczające się przez tę granicę.
- Przykład: Linia z Proces Zamówienia do Magazyn Zamówień może być oznaczona jako Szczegóły Zamówienia.
- Przykład: Linia z Magazyn Zamówień do Proces raportowania może być oznaczony jakoHistoria zamówień.
Etykiety dostarczają kontekst dotyczący objętości i typu danych przesyłanych. Pomagają programistom zrozumieć wymagania dotyczące schematu w późniejszym etapie.
🎯 Dokładność i zakres 🎯
Decyzja o tym, jak podzielić dane na magazyny, to kluczowe zagadnienie projektowe. Zbyt wiele magazynów rozpraszają model, podczas gdy zbyt mało tworzy monolityczny blok informacji.
1. Grupowanie oparte na encjach
Grupuj dane według logicznej encji. Jeśli system śledzi klientów, produkty i faktury, to one powinny zazwyczaj znajdować się w osobnych magazynach.
- Zaleta: Uproszczenie utrzymania. Zmiany danych klientów nie wpływają na logikę przechowywania faktur.
- Zaleta: Zmniejsza ryzyko przypadkowego uszkodzenia danych podczas aktualizacji.
2. Oddzielenie odczytu i zapisu
Zastanów się, czy magazyn służy głównie do odczytu czy zapisu. Wysokowydajne dzienniki transakcji często wymagają innej obsługi przechowywania niż dane referencyjne.
- Dane referencyjne: Magazyny takie jakKody krajów to magazyny o dużym obciążeniu odczytu i rzadko się zmieniają.
- Dane transakcyjne: Magazyny takie jakDzienniki sprzedaży to magazyny o dużym obciążeniu zapisu i rosną z czasem.
Rozróżnianie tych typów pomaga w planowaniu pojemności i wzorców dostępu, nawet jeśli DFD pozostaje modelem logicznym.
3. Tymczasowe vs. stałe
Nie wszystkie magazyny danych reprezentują stałe przechowywanie. Niektóre są tymczasowymi buforami.
- Dane sesji: Magazyny używane do tymczasowych sesji użytkownika podczas procesu logowania.
- Magazyny pamięci podręcznej: Tymczasowe miejsca przechowywania danych często dostępnego.
Jasne oznaczenie tymczasowych magazynów zapobiega nieporozumieniom dotyczącym zasad przechowywania danych. Tymczasowy magazyn powinien być opróżniony lub wyczyszczony po zakończeniu procesu.
🔄 Przepływ danych i interakcja procesów 🔄
Związek między procesem a magazynem danych jest w wielu przypadkach dwukierunkowy, ale nie zawsze. Zrozumienie kierunkowości jest istotne dla poprawnego modelowania.
1. Dostęp tylko do odczytu
Niektóre magazyny są dostępne wyłącznie do odczytu. Proces może zapytać magazyn o wyświetlenie informacji bez ich modyfikacji.
- Przykład: A Wyświetl profil proces odczytujący z Magazyn profilu użytkownika.
- Ograniczenie:Strzałka przepływu danych nie powinna wskazywać z magazynu na proces i z powrotem w ramach tej samej transakcji, chyba że oznacza operację zapisu.
2. Dostęp tylko do zapisu
Niektóre procesy zapisują dane bez konieczności ich wcześniejszego pobrania.
- Przykład: An Dziennik zdarzeń proces zapisujący do Magazyn audytu systemu.
- Ograniczenie:Upewnij się, że proces ma odpowiednie kontekst, aby poprawnie zapisać dane bez zewnętrznego wpływu.
3. Dostęp do odczytu i zapisu
Większość procesów biznesowych obejmuje pobieranie, modyfikację i zapisywanie danych.
- Przykład: Aktualizuj inwentarz odczytuje aktualny stan magazynowy, oblicza nową wartość i ją zapisuje.
- Modelowanie: Używaj oddzielnych przepływów do odczytu i zapisu, aby wyjaśnić kolejność operacji.
Ta różnica pomaga programistom zrozumieć, czy transakcja bazy danych wymaga natychmiastowego zamknięcia blokadą lub zatwierdzenia.
📊 Poziomy DFD i widoczność magazynów 📊
Diagramy przepływu danych (DFD) są często rozkładane na poziomy, od diagramów kontekstowych (poziom 0) po szczegółowe rozbiory (poziom 2, poziom 3). Magazyny danych wyglądają inaczej na każdym poziomie.
1. Poziom kontekstowy (poziom 0)
Na najwyższym poziomie magazyny danych są często pomijane w celu zachowania prostoty. Uwaga skupia się na jednostkach zewnętrznych i głównym ograniczeniu systemu.
- Powód:Zbyt dużo szczegółów zakłóca widoczność wymiany danych na najwyższym poziomie.
- Wyjątek:Duże zewnętrzne bazy danych mogą być pokazane, jeśli są kluczowe dla granicy systemu.
2. Rozkład poziomu 1
Gdy system jest rozkładany na główne procesy, magazyny danych stają się widoczne. To właśnie tutaj definiowana jest główna architektura przechowywania danych.
- Skupienie: Zidentyfikuj podstawowe repozytoria wymagane dla każdej głównej funkcji.
- Szczegóły: Upewnij się, że każdy proces ma miejsce docelowe dla danych wyjściowych.
3. Poziom 2 i dalej
Dalszy rozkład może podzielić duże magazyny danych na mniejsze i bardziej specyficzne.
- Przykład: Magazyn klientów na poziomie 1 może zostać podzielony naMagazyn informacji kontaktowych i Magazyn rozliczeń na poziomie 2.
- Spójność: Upewnij się, że dane na niższych poziomach odpowiadają danym na wyższych poziomach. Nie wprowadzaj nowych typów danych, które nie występowały na diagramie nadrzędnej.
⚠️ Powszechne pułapki ⚠️
Nawet doświadczeni analitycy popełniają błędy podczas projektowania magazynów danych. Unikanie tych powszechnych błędów zapewnia, że diagram pozostaje dokładny.
- Czarne dziury: Proces, który pobiera dane, ale nie zapisuje ich nigdzie. Oznacza to utratę danych.
- Płomienie:Proces, który pobiera dane, ale tworzy dane bez magazynu. Oznacza to, że dane powstają z niczego (czarodziejstwo).
- Przecieki:Magazyny danych bez połączonych procesów. Są to martwe końce.
- Niezrównoważone przepływy:Przy przechodzeniu z poziomu 1 na poziom 2 wejścia i wyjścia muszą się zgadzać. Jeśli w poziomie 2 dodawany jest magazyn, musi być uzasadniony wejściami/wyjściami procesu nadrzędnego.
- Zbyt duża złożoność: Próba modelowania każdej tabeli bazy danych jako osobnego magazynu na diagramie poziomu 1. Przytrzymaj się jednostek logicznych, a nie fizycznych tabel.
📚 Wyrównanie z modelami danych 📚
Choć DFD skupia się na przepływie, muszą być zgodne z diagramami relacji encji (ERD) lub modelami danych logicznych. Magazyny danych w DFD powinny odpowiadać encjom w ERD.
- Sprawdzenie spójności: Jeśli DFD zawieraMagazyn Produktów, to ERD powinien zawierać encjęProduktencję.
- Mapowanie atrybutów: Atrybuty wymagane przez proces do interakcji z magazynem muszą istnieć w modelu danych.
- Normalizacja: Choć DFD nie wymusza normalizacji, projekt powinien unikać oczywistej nadmiarowości, która wskazuje na słaby projekt bazy danych.
To wyrównanie zapewnia, że projekt logiczny (DFD) może zostać przekształcony w implementację fizyczną (schemat bazy danych) bez istotnego ponownego projektowania.
🔍 Lista sprawdzania poprawności projektu 🔍
Zanim zakończysz projekt diagramu przepływu danych, użyj poniższej listy kontrolnej do weryfikacji projektu magazynów danych.
| Zasada | Punkt listy kontrolnej | Status |
|---|---|---|
| Nazewnictwo | Czy wszystkie nazwy magazynów są opisowe i spójne? | ☐ |
| Łączność | Czy każdy magazyn jest połączony z co najmniej jednym procesem? | ☐ |
| Kierunek przepływu | Czy strzałki wskazują poprawnie między procesami a magazynami? | ☐ |
| Etykietowanie | Czy dane przepływają przez linie oznaczone nazwami zawartości? | ☐ |
| Brak bezpośrednich połączeń między magazynami | Czy istnieją linie łączące magazyn z magazynem bezpośrednio? | ☐ |
| Spójność | Czy magazyny poziomu niższego odpowiadają zakresowi poziomu wyższego? | ☐ |
| Integralność | Czy wszystkie wymagania danych dla procesów są spełnione przez dostępne magazyny? | ☐ |
🔄 Konserwacja i ewolucja 🔄
Wymagania systemu się zmieniają. Magazyny danych muszą być elastyczne wobec tych zmian bez naruszania modelu.
- Kontrola wersji: Śledź zmiany w definicjach magazynów. Jeśli magazyn się dzieli, zapisz ścieżkę migracji.
- Dane z przeszłości: Zaprojektuj sposób obsługi starych danych, gdy zmienia się schemat magazynu. Często wymaga to magazynu archiwalnego.
- Pętla zwrotna: Wykorzystaj feedback zespołów deweloperskich do dopasowania szczegółowości magazynów. Jeśli deweloperzy uznają magazyn za zbyt ogólny, podziel go. Jeśli za zbyt rozdrobniony, połącz go.
Statyczny model to obciążenie. Projekt magazynu danych powinien być przeglądarki za każdym razem, gdy zmieniają się zasady biznesowe lub pojawiają się nowe wymagania zgodności. Zapewnia to, że DFD pozostaje żyjącym dokumentem odzwierciedlającym rzeczywiste potrzeby systemu w zakresie danych.
📝 Wnioski dotyczące wdrożenia
Projektowanie magazynów danych w diagramach przepływu danych jest podstawowym zadaniem analizy systemu. Łączy luki między abstrakcyjnymi procesami a konkretną trwałą pamięcią danych. Przestrzeganie rygorystycznych zasad nazewnictwa, reguł łączenia oraz zasad szczegółowości pozwala analitykom tworzyć modele czytelne i wykonalne.
Cel nie polega na doskonałym odtworzeniu schematu bazy danych, ale na uchwyceniu logicznej potrzeby przechowywania danych. Gdy DFD jest dokładny, przejście do rozwoju jest płynniejsze, a ryzyko utraty danych lub niezgodności znacznie się zmniejsza. Skup się na przejrzystości, spójności i logicznym przepływie informacji, aby stworzyć wysokiej jakości projekty systemów.