











Projektowanie solidnej architektury mikroserwisów wymaga więcej niż tylko podziału kodu na mniejsze fragmenty. Wymaga jasnego zrozumienia, jak informacje poruszają się przez system. Bez strukturalnego podejścia systemy rozproszone często stają się skomplikowanymi sieciami zależności, które trudno utrzymywać i skalować. To właśnie w tym miejscu diagram przepływu danych (DFD) staje się niezbędnym narzędziem dla architektów. Poprzez wizualizację przepływu danych zespoły mogą precyzyjnie określić granice usług i zapewnić spójność logiki danych na całej platformie.
Ten przewodnik omawia sposób wykorzystania DFD w fazie planowania wdrożenia mikroserwisów. Przeanalizujemy hierarchię diagramów, identyfikację kluczowych granic oraz strategie zarządzania własnością danych. Celem jest zaprezentowanie systematycznego podejścia do projektowania systemu, które priorytetowo ustawia przejrzystość i łatwość utrzymania.
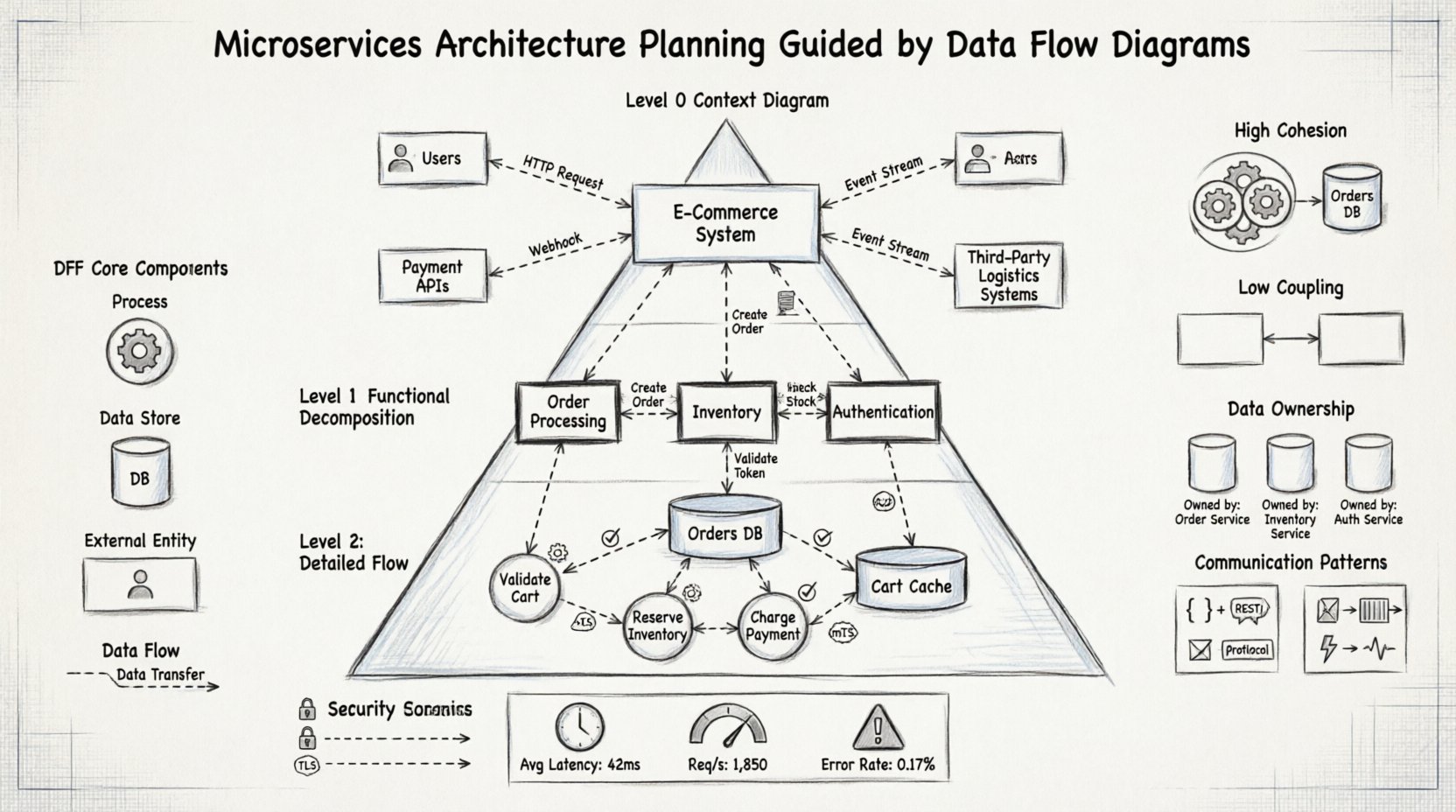
🧩 Zrozumienie roli DFD w systemach rozproszonych
Diagram przepływu danych przedstawia przepływ informacji przez system. W przeciwieństwie do schematu blokowego, który skupia się na przepływie sterowania i logice decyzyjnej, DFD podkreśla przekształcanie i przechowywanie danych. W kontekście mikroserwisów ta różnica jest kluczowa. Mikroserwisy to zasadniczo niezależne jednostki przetwarzania wymieniające dane. Wizualne przedstawienie tego wymiany pomaga stakeholderom zrozumieć skutki zmian.
Kluczowe elementy diagramu przepływu danych
Zanim zastosuje się DFD do architektury, należy zrozumieć podstawowe symbole używane:
- Procesy:Reprezentują przekształcenia danych. W mikroserwisach często odpowiadają one określonym funkcjom usług lub interfejsom API.
- Magazyny danych:Miejsca, w których dane są przechowywane w stanie spoczynku. Odpowiadają im bazy danych, pamięci podręczne lub systemy plików.
- Zewnętrzne jednostki:Źródła lub miejsca docelowe danych poza systemem. Obejmują to użytkowników, systemy zewnętrzne lub starsze aplikacje.
- Przepływy danych:Ruch danych między procesami, magazynami i jednostkami. Odpowiadają one ruchowi sieciowemu lub kolejkom komunikatów między usługami.
📊 Hierarchia diagramów planistycznych
Kompleksowy plan architektury wymaga wielu poziomów abstrakcji. Rozpoczynając od ogólnego przeglądu i przechodząc do szczegółów, zapewnia się, że żadna kluczowa droga danych nie zostanie pominięta. To podejście hierarchiczne naturalnie pasuje do warstwowej architektury mikroserwisów.
Poziom 0: Diagram kontekstowy
Diagram poziomu 0, często nazywany diagramem kontekstowym, zapewnia najszerszy widok. Reprezentuje cały system jako pojedynczy proces i identyfikuje wszystkie jednostki zewnętrzne, które z nim współpracują. Jest to pierwszy krok w planowaniu, ponieważ określa zakres.
- Zidentyfikuj granice:Jasno zaznacz, co znajduje się wewnątrz systemu, a co poza nim.
- Interfejsy zewnętrzne:Wymień każdy punkt wejścia i wyjścia danych.
- Główne wejścia/wyjścia:Określ główne sygnały danych dla systemu.
W kontekście mikroserwisów ten poziom pomaga odpowiedzieć na pytanie: „Co system robi dla użytkownika?” Stanowi podstawę do dekompozycji.
Poziom 1: Główna dekompozycja funkcjonalna
Po ustaleniu kontekstu pojedynczy proces jest rozbijany na główne podprocesy. W kontekście mikroserwisów te podprocesy często wskazują na początkowe kandydaty do usług. Ten poziom dzieli system na logiczne domeny.
- Zgodność z domeną:Grupuj procesy według możliwości biznesowych (np. Przetwarzanie zamówień, Zarządzanie zapasami, Uwierzytelnianie użytkowników).
- Kandydaci usługi:Każdy główny proces staje się potencjalną mikro-usługą.
- Komunikacja między usługami:Zidentyfikuj przepływy danych między tymi głównymi domenami.
Poziom 2: szczegółowa analiza przepływu
Ostateczny poziom szczegółowości skupia się na konkretnych funkcjach w ramach usługi. To tam mapuje się walidację danych, przekształcenia oraz logikę przechowywania. Zapewnia to spójność logiki wewnętrznej usługi przed rozpoczęciem implementacji.
🏗️ Mapowanie przepływów danych na granice usług
Jednym z najważniejszych wyzwań w architekturze mikro-usług jest definiowanie granic usług. Jeśli granice są niewłaściwie określone, usługi stają się silnie powiązane, co prowadzi do antypatternu „rozproszonej monolitycznej aplikacji”. Diagramy przepływu danych pomagają narysować te granice, wyróżniając zależności danych.
Identyfikacja spójności
Usługi powinny charakteryzować się wysoką spójnością, co oznacza, że wszystkie funkcje w ramach usługi działają w taki sposób, że wspierają się w obrębie określonego zestawu danych. Diagramy przepływu danych pomagają wizualizować to, grupując procesy, które współdzielą te same magazyny danych i przepływy.
- Zgrupowane procesy:Jeśli proces A i proces B zawsze wymieniają dane bezpośrednio bez zewnętrznego wyzwalacza, najprawdopodobniej należą do tej samej usługi.
- Współdzielone magazyny danych:Procesy uzyskujące dostęp do tego samego magazynu danych powinny zostać ocenione pod kątem potencjalnej konsolidacji.
Minimalizacja sprzężenia
Sprzężenie odnosi się do stopnia wzajemnej zależności między usługami. Diagramy przepływu danych ujawniają sprzężenie, pokazując, ile przepływów danych przekracza zaproponowane granice. Celem jest minimalizacja liczby przepływów danych przekraczających granice usług.
- Bezpośrednie połączenia:Zmniejsz liczbę bezpośrednich przepływów danych między usługami.
- Pośrednie połączenia:Zaleca się używanie komunikacji asynchronicznej lub architektury opartej na zdarzeniach, aby rozłączyć usługi.
🗄️ Zarządzanie własnością danych i spójnością
W bazie danych monolitycznej spójność danych jest zarządzana za pomocą transakcji. W mikro-usługach każda usługa zwykle posiada własne dane. Diagramy przepływu danych są kluczowe do wyjaśnienia własności. Mapując przepływy danych do magazynów, architekci mogą przypisać własność do konkretnych procesów.
Wzorzec bazy danych na usługę
Każda mikro-usługa powinna zarządzać własnym magazynem danych. Diagramy przepływu danych pomagają zidentyfikować, do której usługi należy dane, śledząc źródło danych oraz miejsce ich zużycia.
- Źródło prawdy:Proces, który zapisuje dane, posiada magazyn danych.
- Dostęp do odczytu:Inne procesy mogą odczytywać dane za pomocą zdefiniowanych przepływów (interfejsów API), ale nie mogą ich bezpośrednio modyfikować.
Modele spójności
Systemy rozproszone często opierają się na spójności ostatecznej zamiast na natychmiastowej spójności. Diagramy przepływu danych wyróżniają miejsca, w których spójność jest krytyczna, oraz te, w których może być osłabiona.
- Silna spójność: Wymagana dla transakcji finansowych lub aktualizacji zapasów. Te przepływy są oznaczone jako synchroniczne.
- Spójność ostateczna: Akceptowalna dla profili użytkowników lub dzienników. Te przepływy są często asynchroniczne.
🔗 Wzorce komunikacji i integracja
Po zdefiniowaniu usług architektura musi określić, jak się ze sobą komunikują. Diagramy przepływu danych (DFD) rozróżniają różne typy przepływów danych, co wpływa na wybór technologii komunikacji.
Wymagaj-Odpowiedz vs. Zdarzeniowy
Nie wszystkie przepływy danych wymagają natychmiastowej odpowiedzi. Diagramy przepływu danych pomagają kategoryzować przepływy na podstawie ich wymagań czasowych.
- Przepływy synchroniczne: Używane, gdy proces dolny potrzebuje danych natychmiast, aby kontynuować. Zazwyczaj odpowiadają interfejsom API REST lub gRPC.
- Przepływy asynchroniczne: Używane do przetwarzania w tle lub powiadomień. Odpowiadają kolejkom komunikatów lub szynom zdarzeń.
⚠️ Powszechne pułapki w planowaniu opartym na DFD
Choć DFD są potężne, łatwo je źle zinterpretować, jeśli nie są używane poprawnie. Architekci powinni być świadomi powszechnych błędów, które mogą zniszczyć proces planowania.
Pułapka 1: Nadmierna szczegółowość na poziomie kontekstu
Zaczynanie z nadmierną szczegółowością na poziomie kontekstu może zakłócić widok ogólny. Zachowaj poziom 0 prostym. Dodawaj złożoność tylko przy przejściu do poziomu 1 i 2.
Pułapka 2: Ignorowanie wymagań niiefunkcjonalnych
DFD skupiają się na danych, a nie na wydajności czy bezpieczeństwie. Podczas mapowania przepływów należy brać pod uwagę wymagania dotyczące opóźnień i granice bezpieczeństwa. Przepływ danych może być technicznie możliwy, ale naruszać zasady bezpieczeństwa.
Pułapka 3: Cykliczne zależności
DFD mogą ujawniać cykliczne przepływy danych, gdzie Usługa A wywołuje Usługę B, która z kolei wywołuje Usługę A. Powoduje to zakleszczenie lub nieskończoną pętlę. Te pętle należy przerwać poprzez przeorganizowanie własności danych.
📋 Analiza porównawcza poziomów DFD
Aby lepiej zrozumieć, jak poziomy DFD odpowiadają decyzjom architektonicznym, odwołaj się do poniższej tabeli.
| Poziom DFD | Obszar skupienia | Wynik architektoniczny |
|---|---|---|
| Kontekst (poziom 0) | Zakres systemu | Definicja granic usługi |
| Funkcjonalny (poziom 1) | Główne domeny | Katalog usług i umowy API |
| Logiczny (poziom 2) | Wewnętrzna logika | Modele danych i zasady weryfikacji |
| Fizyczny | Infrastruktura | Topologia wdrażania i konfiguracja sieci |
🔄 Iteracyjne doskonalenie i utrzymanie
Architektura to nie jednorazowy wydarzenie. Wraz z rozwojem biznesu zmieniają się przepływy danych. Diagramy przepływu danych (DFD) są żyjącą dokumentacją, którą należy aktualizować równolegle z kodem źródłowym.
Wersjonowanie diagramów
Tak jak API są wersjonowane, również diagramy przepływu danych (DFD) powinny być wersjonowane w celu śledzenia zmian architektonicznych w czasie. Pomaga to zespołom zrozumieć, dlaczego w przeszłości podjęto konkretne decyzje.
- Dzienniki zmian: Dokumentuj każdą modyfikację przepływu danych lub procesu.
- Analiza wpływu: Użyj diagramu, aby ocenić, jak zmiana w jednym serwisie wpływa na inne.
Weryfikacja automatyczna
Choć diagramy ręczne są przydatne, weryfikacja automatyczna może zapewnić, że implementacja odpowiada projektowi. Narzędzia mogą zweryfikować, czy rzeczywisty ruch sieciowy zgadza się z zdefiniowanymi przepływami w diagramie przepływu danych (DFD).
🛡️ Rozważania dotyczące bezpieczeństwa w przepływach danych
Bezpieczeństwo często pojawia się jako pożądane dopiero po zakończeniu projektu, ale diagramy przepływu danych (DFD) pozwalają na jego zintegrowanie od samego początku. Każdy przepływ danych reprezentuje potencjalny wektor ataku.
Definiowanie stref zaufania
Zaznacz obszary diagramu wymagające różnych poziomów bezpieczeństwa. Wewnętrzne przepływy mogą być uznawane za zaufane, podczas gdy przepływy zewnętrzne wymagają szyfrowania i uwierzytelniania.
- Przepływy zewnętrzne: Wymagają TLS, kluczy API lub tokenów OAuth.
- Przepływy wewnętrzne: Wymagają wzajemnego TLS lub uwierzytelniania między usługami.
Klasyfikacja danych
Oznacz przepływy danych w zależności od ich wrażliwości. Dane poufne (PII, finansowe) wymagają bardziej rygorystycznych kontroli niż dane publiczne.
- Wysoka wrażliwość: Szyfruj dane w spoczynku i w trakcie przesyłania.
- Niska wrażliwość: Standardowe protokoły szyfrowania są wystarczające.
📈 Mierzenie sukcesu za pomocą schematów przepływu danych
Jak możesz wiedzieć, czy architektura działa? Schematy przepływu danych (DFD) zapewniają podstawę do pomiaru. Porównując rzeczywisty przepływ danych z zaplanowanym schematem, zespoły mogą identyfikować węzły zatyczki.
Metryki wydajności
- Opóźnienie:Mierz czas potrzebny do przejścia danych przez przepływ.
- Przepustowość:Mierz objętość danych przemieszczających się między procesami.
- Stopy błędów:Zidentyfikuj przepływy, które często zawodzą.
Możliwości optymalizacji
Schematy przepływu danych wyróżniają nadmiarowe ścieżki. Jeśli dwa usługi wielokrotnie wymieniają te same dane, można wprowadzić warstwę buforowania lub wspólny model odczytu w celu optymalizacji wydajności.
🚀 Wnioski dotyczące planowania strategicznego
Wykorzystywanie schematów przepływu danych do planowania mikroserwisów przesuwa uwagę z kodu na informacje. Zapewnia to, że architektura wspiera logikę biznesową, a nie na odwrót. Przestrzegając strukturalnego podejścia do DFD, zespoły mogą tworzyć systemy modułowe, łatwe w utrzymaniu i skalowalne.
Proces wymaga dyscypliny. Wymaga od architektów opuszczenia chęci nadmiernego optymalizowania na wczesnym etapie i skupienia się na jasnych granicach oraz własności danych. Gdy schemat DFD jest dokładny, implementacja następuje naturalnie. Ta metoda zmniejsza dług techniczny i tworzy podstawę do długoterminowego rozwoju.
Pamiętaj, że schemat jest narzędziem komunikacji tak samo jak projektowania. Łączy luki między zespołami technicznymi a stakeholderami biznesowymi. Gdy wszyscy rozumieją, jak przepływa dane, cała organizacja może podejmować lepsze decyzje dotyczące możliwości i ograniczeń systemu.