











🏗️ 物件導向分析的基礎
在物件導向分析與設計(OOA&D)的領域中,系統模型的準確性取決於初期階段所識別實體的品質。現實世界中的實體代表了軟體解決方案的核心構建模塊。它們是承載狀態、行為與領域內關係的物件。當這些實體被正確定義時,所產生的架構將具備強韌性、可維護性,並與業務運作保持一致。相反地,錯誤識別實體可能導致複雜的耦合、重複的資料結構,以及一個難以適應變動需求的系統。
有效的建模需要從將資料視為孤立的資料表或變數,轉變為將其視為業務流程中的主動參與者。目標是在不引入不必要的複雜性的前提下,捕捉領域的核心本質。此過程包括仔細審查需求、與領域專家互動,並運用嚴謹的分析技術,以區分重要的實體、值物件與暫時性屬性。
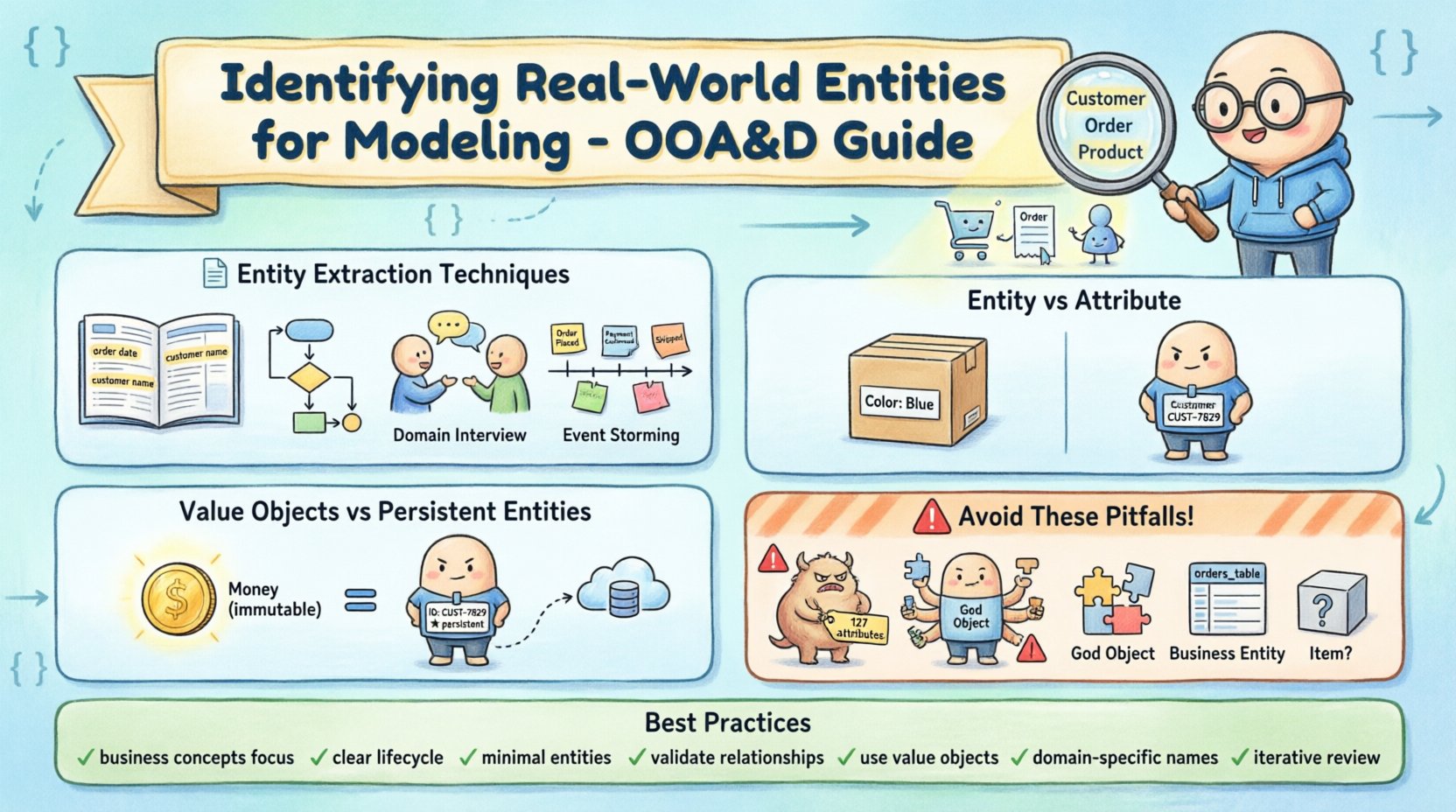
📝 實體提取技術
已有幾種經過驗證的方法,可用於從原始資訊中提取潛在實體。這些技術有助於將模糊的業務需求轉化為具體的建模候選項目。
- 名詞片語分析: 最常見的方法之一是閱讀需求文件與使用者故事。分析師會標示出頻繁出現的名詞與名詞片語。例如,在物流系統中,「包裹」、「駕駛員」與「倉庫」等詞語自然浮現。「包裹」, 「駕駛員」,以及「倉庫」自然浮現。然而,並非每個名詞都是實體。像「處理」或「運送」等詞語,通常描述的是動作或關係,而非獨立的物件。「處理」或「運送」通常描述的是動作或關係,而非獨立的物件。
- 使用案例情境:檢視使用案例能提供資料被使用的背景脈絡。如果使用者在多個情境中與特定物件互動,該物件便是實體的強烈候選者。例如,若使用者登入、檢視儀表板並編輯個人檔案,則「使用者」物件便是系統的核心。「使用者」物件是系統的核心。
- 領域知識訪談:與利害關係人對話能揭示他們日常使用的術語。這有助於識別那些未明確寫入技術規格中,卻對業務邏輯至關重要的實體。利害關係人通常以功能名稱而非技術識別碼來指稱物件。
- 事件風暴(Event Storming): 這是一種協作技術,涉及在時間軸上繪製業務事件。每個事件通常暗示著一個觸發它或受其影響的實體的存在。這種視覺化方法有助於發現文字分析可能遺漏的關係。
🔍 區分實體與屬性
建模中常見的挑戰在於判斷一個概念是否應作為獨立實體,還是僅作為另一實體的屬性。此決策會影響模型的細緻程度與查詢的複雜性。
屬性描述的是實體的一種特性。它通常沒有自身的識別。例如,一個「顏色」屬性「顏色」屬性,可能出現在一個「產品」實體描述產品的外觀。它不能獨立於產品之外存在。
然而,實體具有自己的身份和生命週期。在某些情境下,它可以獨立存在,而不必依附於特定的父實例,並且通常擁有自己的關係。考慮以下兩者的差異:「地址」和「城市」。在某些模型中,「地址」是一個包含「街道」, 「城市」、「郵政編碼」的複雜屬性。在其他模型中,「城市」是一個獨立的實體,具有如「人口」和「地區」等屬性,與多個「地址」記錄相關聯。
| 標準 | 屬性 | 實體 |
|---|---|---|
| 身份 | 無唯一識別符 | 具有唯一識別符 |
| 複雜性 | 簡單的資料類型(字串、數字) | 可以具有多個屬性和行為 |
| 可重用性 | 僅在單一情境中使用 | 可在多個情境中共享 |
| 生命週期 | 僅在父物件存在時才存在 | 具有獨立的生命週期 |
💎 值物件 vs. 持久化實體
並非所有實體都需要在資料庫中持久化。區分值物件與持久化實體對於效能與架構完整性至關重要。
值物件 是定義特徵但沒有明確身分的物件。它們由屬性定義。若更改任一屬性,物件即被視為不同。一個經典範例是「金錢」。具有相同金額與幣別的兩個金錢實例被視為相等。特定美元金額無需獨特的識別碼。
持久化實體 需要獨特的識別碼來區分彼此,即使其屬性完全相同。例如「顧客」實體必須擁有顧客識別碼。兩個顧客可能擁有相同的姓名與地址,但他們是不同的人。
使用值物件可透過移除不必要的資料庫負載,降低領域模型的複雜度。這讓模型僅在真正需要時才關注身分。
⚠️ 常見的建模陷阱
即使經驗豐富的分析師也可能在識別階段陷入陷阱。識別這些陷阱有助於優化模型。
- 過度建模:為使用頻率極低或無顯著價值的概念建立實體。這將導致模型臃腫,難以導航。
- 建模不足:將過多概念歸為單一實體。這通常會導致難以維護的「上帝物件」,並違反單一責任原則。
- 忽略關係:僅關注物件,卻未定義它們之間的互動方式。缺乏關係的實體是孤立的,在連結系統中通常毫無用處。
- 技術偏見:根據資料庫表格名稱或程式設計限制來命名實體,而非基於商業概念。模型應反映領域,而非基礎架構。
- 過早抽象化: 創建像這樣的通用實體“項目” 或 “物件” 在理解具體需求之前。具體性通常會揭示出通用模型所隱藏的必要細節。
🔄 驗證與優化流程
識別並非一次性事件。它是一個需要不斷根據業務現實進行驗證的迭代過程。
1. 與利益相關者進行走查
向領域專家展示初始模型。請他們驗證實體是否反映其現實情況。他們是否能辨識出這些關係?是否有任何關鍵物件遺漏?此反饋迴圈可確保模型始終緊扣業務需求。
2. 情境測試
透過模型執行特定的業務情境。如果使用者需要產生涉及多個實體的報表,請檢查關係是否能有效支援此查詢。若模型需要複雜的連接或變通做法,則可能需要調整實體結構。
3. 一致性檢查
確保命名慣例一致。如果你在一個部分使用“使用者”,而在另一部分使用“客戶”代表同一概念,將會造成混淆。應在整個領域模型中統一術語。
4. 边界識別
定義系統的邊界。有些實體存在於軟體系統之外,但與其互動。這些稱為外部實體。區分內部與外部實體有助於管理依賴關係與整合點。
📊 最佳實務總結
為確保高品質的建模,請在識別階段遵守以下清單。
- ✅ 專注於業務概念,而非技術實現。
- ✅ 確保每個實體都有明確的目的與生命週期。
- ✅ 最小化實體數量以降低複雜度。
- ✅ 在確定屬性之前先驗證關係。
- ✅ 為沒有身分識別的資料類型使用值物件。
- ✅ 保持名稱具描述性且為領域專用。
- ✅ 隨著需求演進,迭代地審查模型。
🚀 精確建模的影響
在準確識別現實世界實體上投入的努力,將在整個軟體生命週期中帶來回報。精確的模型可減少後續重構的需求。它能明確開發人員與業務利益相關者之間的溝通。它作為一份藍圖,引導資料庫設計、API 定義與使用者介面結構。
當實體被正確建模時,系統會變得更具彈性。新增功能通常需要修改現有的實體,而不是重構整個基礎架構。這種穩定性使組織能夠回應市場變化,而不受技術負債的阻礙。
最終,目標是建立一個反映業務真實情況的動態模型。這需要耐心、深入的理解以及對清晰性的承諾。透過避免捷徑並堅持嚴謹的分析技術,所產生的系統將能經受時間與變化的考驗。
🔗 建模之旅的下一步
一旦實體被識別出來,重點便轉向定義它們的行為與關係。這包括建立狀態圖、序列圖和類圖。這裡識別出的實體將作為這些更廣泛圖表中的節點。在繼續前確保它們穩固,可防止設計階段出現連鎖錯誤。
持續學習與適應至關重要。隨著業務領域的演變,模型也必須隨之演進。定期審查可確保識別過程保持相關且有效。這種動態方法能確保軟體解決方案始終與組織的目標保持一致。