











🏗️ La fondation de l’analyse orientée objet
Dans le domaine de l’analyse et de la conception orientées objet (AOAO), l’exactitude du modèle du système repose sur la qualité des entités identifiées durant les phases initiales. Les entités du monde réel représentent les blocs de construction fondamentaux de la solution logicielle. Ce sont les objets qui portent un état, un comportement et des relations au sein du domaine. Lorsqu’elles sont correctement définies, l’architecture résultante est robuste, maintenable et alignée sur les opérations commerciales. À l’inverse, une mauvaise identification des entités peut entraîner un couplage complexe, des structures de données redondantes et un système qui peine à s’adapter aux exigences changeantes.
Une modélisation efficace exige un changement de perspective, passant de la vision des données comme des tables ou variables isolées à celle de leur rôle actif dans un processus métier. L’objectif est de capturer l’essence du domaine sans introduire de complexité inutile. Ce processus implique une analyse approfondie des exigences, une collaboration avec des experts du domaine et l’application de techniques analytiques rigoureuses pour distinguer les entités significatives, les objets valeur et les attributs transitoires.
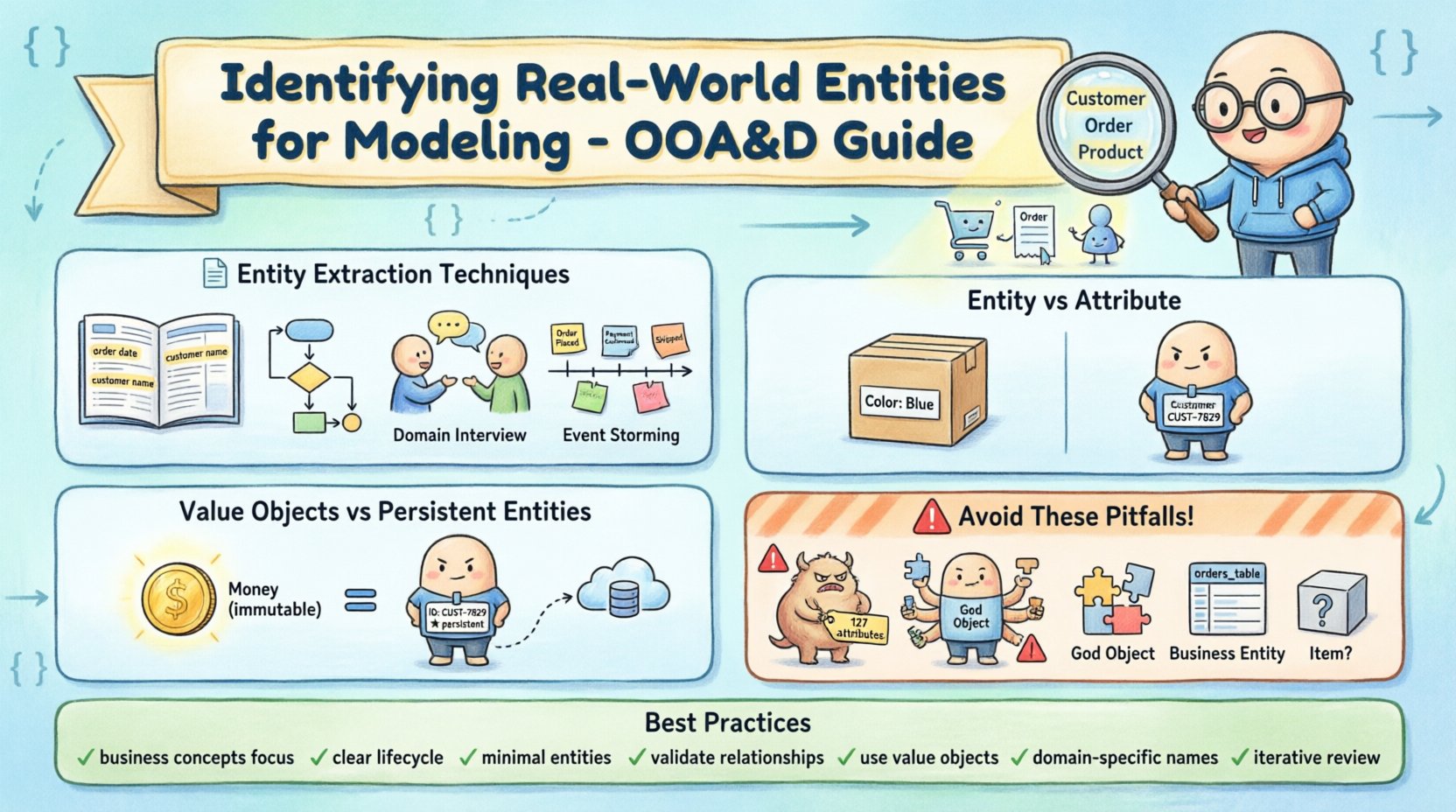
📝 Techniques d’extraction d’entités
Plusieurs méthodes éprouvées existent pour extraire des entités potentielles à partir d’informations brutes. Ces techniques aident à transformer des besoins commerciaux vagues en candidats concrets pour la modélisation.
- Analyse des groupes nominaux : L’une des approches les plus courantes consiste à lire attentivement les documents de besoins et les histoires d’utilisateur. Les analystes mettent en évidence les noms et les groupes nominaux qui apparaissent fréquemment. Par exemple, dans un système de logistique, les termes tels que« colis », « conducteur », et « entrepôt » émergent naturellement. Toutefois, tout nom n’est pas une entité. Les termes tels que« manutention » ou « expédition » décrivent souvent des actions ou des relations plutôt que des objets indépendants.
- Scénarios d’utilisation : L’examen des cas d’utilisation fournit un contexte sur la manière dont les données sont consommées. Si un utilisateur interagit avec un objet spécifique dans plusieurs scénarios, il constitue un candidat fort pour une entité. Par exemple, si un utilisateur se connecte, consulte un tableau de bord et modifie son profil, l’objet« Utilisateur » est central au système.
- Entrevues sur les connaissances du domaine : Parler avec les parties prenantes révèle le vocabulaire qu’ils utilisent au quotidien. Cela aide à identifier des entités qui pourraient ne pas être explicitement mentionnées dans les spécifications techniques, mais qui sont cruciales pour la logique métier. Les parties prenantes font souvent référence aux objets par leurs noms fonctionnels plutôt que par des identifiants techniques.
- Event Storming : Cette technique collaborative consiste à représenter les événements métiers sur un chronogramme. Chaque événement implique souvent l’existence d’une entité qui l’a déclenché ou qui en a été affectée. Cette approche visuelle permet de découvrir des relations que l’analyse textuelle pourrait manquer.
🔍 Distinction entre entités et attributs
Un défi courant dans la modélisation consiste à déterminer si un concept doit être une entité indépendante ou simplement un attribut d’une autre entité. Cette décision influence la granularité du modèle et la complexité des requêtes.
Un attribut décrit une propriété d’une entité. Il n’a généralement pas d’identité propre. Par exemple, un« Couleur » attribut sur un« Produit » entité décrit l’aspect du produit. Elle n’existe pas indépendamment en dehors du produit.
Une entité, toutefois, possède son propre identité et son propre cycle de vie. Elle peut exister sans être attachée à une instance parente spécifique dans certains contextes, et elle possède souvent ses propres relations. Pensez à la différence entre« Adresse » et « Ville ». Dans certains modèles, « Adresse » est un attribut complexe contenant « Rue », « Ville », et « Code postal ». Dans d’autres cas, « Ville » est une entité distincte possédant des propriétés telles que « Population » et « Région », liée à plusieurs « Adresse » enregistrements.
| Critère | Attribut | Entité |
|---|---|---|
| Identité | Pas d’identifiant unique | Possède un identifiant unique |
| Complexité | Type de données simple (Chaîne, Nombre) | Peut avoir plusieurs attributs et comportements |
| Réutilisabilité | Utilisé uniquement dans un seul contexte | Peut être partagé entre plusieurs contextes |
| Cycle de vie | Existe uniquement aussi longtemps que son parent existe | Possède un cycle de vie indépendant |
💎 Objets valeur vs. Entités persistantes
Toutes les entités n’ont pas besoin d’être persistantes dans une base de données. Faire la distinction entre les objets valeur et les entités persistantes est essentiel pour les performances et l’intégrité architecturale.
Objets valeur sont des objets qui définissent des caractéristiques mais n’ont pas d’identité distincte. Ils sont définis par leurs attributs. Si vous modifiez un attribut, l’objet est considéré comme différent. Un exemple classique est « Money ». Deux instances d’argent avec la même valeur et la même devise sont considérées comme égales. Vous n’avez pas besoin d’un ID unique pour un montant spécifique en dollars.
Entités persistantes nécessitent un identifiant unique pour les distinguer des autres instances, même si leurs attributs sont identiques. Une « Client » entité, par exemple, doit avoir un ID client. Deux clients pourraient avoir le même nom et la même adresse, mais ce sont des personnes différentes.
Utiliser des objets valeur réduit la complexité du modèle de domaine en éliminant les surcharges inutiles de base de données. Cela permet au modèle de se concentrer sur l’identité uniquement là où elle est véritablement nécessaire.
⚠️ Pièges courants de modélisation
Même les analystes expérimentés peuvent tomber dans des pièges pendant la phase d’identification. Reconnaître ces pièges aide à affiner le modèle.
- Sur-modélisation : Créer des entités pour des concepts peu utilisés ou qui n’apportent pas de valeur significative. Cela conduit à un modèle gonflé, difficile à naviguer.
- Sous-modélisation : Regrouper trop de concepts dans une seule entité. Cela entraîne souvent des « objets-Dieu » difficiles à maintenir et qui violent les principes de responsabilité unique.
- Ignorer les relations : Se concentrer uniquement sur les objets sans définir leur interaction. Une entité sans relations est isolée et souvent inutile dans un système connecté.
- Biais technique : Nommer les entités en fonction des noms de tables de base de données ou des contraintes de programmation plutôt que des concepts métiers. Le modèle doit refléter le domaine, pas l’infrastructure.
- Abstraire trop tôt : Créer des entités génériques comme « Article » ou « Objet » avant de comprendre les exigences spécifiques. La spécificité révèle souvent des détails nécessaires que les modèles génériques cachent.
🔄 Processus de validation et d’ajustement
L’identification n’est pas un événement ponctuel. C’est un processus itératif qui exige une validation constante par rapport à la réalité métier.
1. Revues avec les parties prenantes
Présentez le modèle initial aux experts du domaine. Demandez-leur de vérifier si les entités reflètent leur réalité. Reconnaissent-ils les relations ? Manque-t-il des objets critiques ? Ce cycle de retour d’information garantit que le modèle reste ancré dans les besoins métiers.
2. Tests de scénarios
Faites passer des scénarios métiers spécifiques à travers le modèle. Si un utilisateur doit générer un rapport impliquant plusieurs entités, vérifiez si les relations permettent cette requête de manière efficace. Si le modèle nécessite des jointures complexes ou des contournements, la structure des entités pourrait nécessiter un ajustement.
3. Vérifications de cohérence
Assurez-vous que les conventions de nommage sont cohérentes. Si vous utilisez « Utilisateur » dans une section et « Client » dans une autre pour le même concept, la confusion est inévitable. Standardisez la terminologie sur l’ensemble du modèle de domaine.
4. Identification des limites
Définissez les limites du système. Certaines entités existent en dehors du système logiciel mais interagissent avec lui. Ce sont des entités externes. Distinger entre les entités internes et externes aide à gérer les dépendances et les points d’intégration.
📊 Résumé des meilleures pratiques
Pour garantir une modélisation de haute qualité, respectez la liste suivante durant la phase d’identification.
- ✅ Concentrez-vous sur les concepts métiers, et non sur l’implémentation technique.
- ✅ Assurez-vous que chaque entité a un objectif clair et un cycle de vie défini.
- ✅ Minimisez le nombre d’entités pour réduire la complexité.
- ✅ Validez les relations avant de finaliser les attributs.
- ✅ Utilisez des objets valeur pour les types de données sans identité.
- ✅ Gardez les noms descriptifs et spécifiques au domaine.
- ✅ Révisez le modèle de manière itérative au fur et à mesure que les exigences évoluent.
🚀 L’impact d’une modélisation précise
L’effort investi dans l’identification précise des entités du monde réel rapporte des bénéfices tout au long du cycle de vie du logiciel. Un modèle précis réduit la nécessité de refactorisation ultérieure. Il clarifie la communication entre les développeurs et les parties prenantes métiers. Il sert de plan directeur qui guide la conception de la base de données, la définition des API et la structure de l’interface utilisateur.
Lorsque les entités sont modélisées correctement, le système devient plus souple. L’ajout de nouvelles fonctionnalités nécessite souvent la modification des entités existantes plutôt que la restructuration de toute la fondation. Cette stabilité permet à l’organisation de réagir aux changements du marché sans être entravée par la dette technique.
En fin de compte, l’objectif est de créer un modèle vivant qui reflète la vérité métier. Cela exige de la patience, une compréhension approfondie et un engagement en faveur de la clarté. En évitant les raccourcis et en respectant des techniques d’analyse rigoureuses, le système résultant résistera aux épreuves du temps et des changements.
🔗 Étapes suivantes dans le parcours de modélisation
Une fois les entités identifiées, l’attention se concentre sur la définition de leurs comportements et de leurs relations. Cela implique la création de diagrammes d’état, de diagrammes de séquence et de diagrammes de classes. Les entités identifiées ici servent de nœuds dans ces diagrammes plus larges. S’assurer qu’elles sont solides avant de poursuivre empêche les erreurs en cascade pendant la phase de conception.
L’apprentissage continu et l’adaptation sont essentiels. Au fur et à mesure que le domaine métier évolue, le modèle doit évoluer avec lui. Des revues régulières maintiennent le processus d’identification pertinent et efficace. Cette approche dynamique garantit que la solution logicielle reste alignée sur les objectifs de l’organisation.