











Dans l’architecture logicielle moderne, comprendre comment les informations circulent est aussi crucial que comprendre comment elles sont stockées. Un diagramme de flux de données (DFD) sert de plan directeur à ce mouvement, cartographiant le parcours des données depuis l’entrée jusqu’à la sortie. Lors de la conception de systèmes destinés à évoluer, ces diagrammes évoluent de simples croquis en cartes complexes qui déterminent les performances, la fiabilité et la maintenabilité. Ce guide explore les modèles essentiels utilisés pour modéliser les flux de données dans des environnements évolutifs.
L’évolutivité ne consiste pas seulement à ajouter davantage de serveurs ; elle passe par une restructuration du parcours des données au sein du système afin d’éviter les goulets d’étranglement. En appliquant des modèles spécifiques de DFD, les architectes peuvent visualiser les limites de capacité avant qu’elles ne deviennent des problèmes en production. Cette approche garantit que le flux logique des informations répond aux besoins actuels tout en prévoyant l’expansion future.
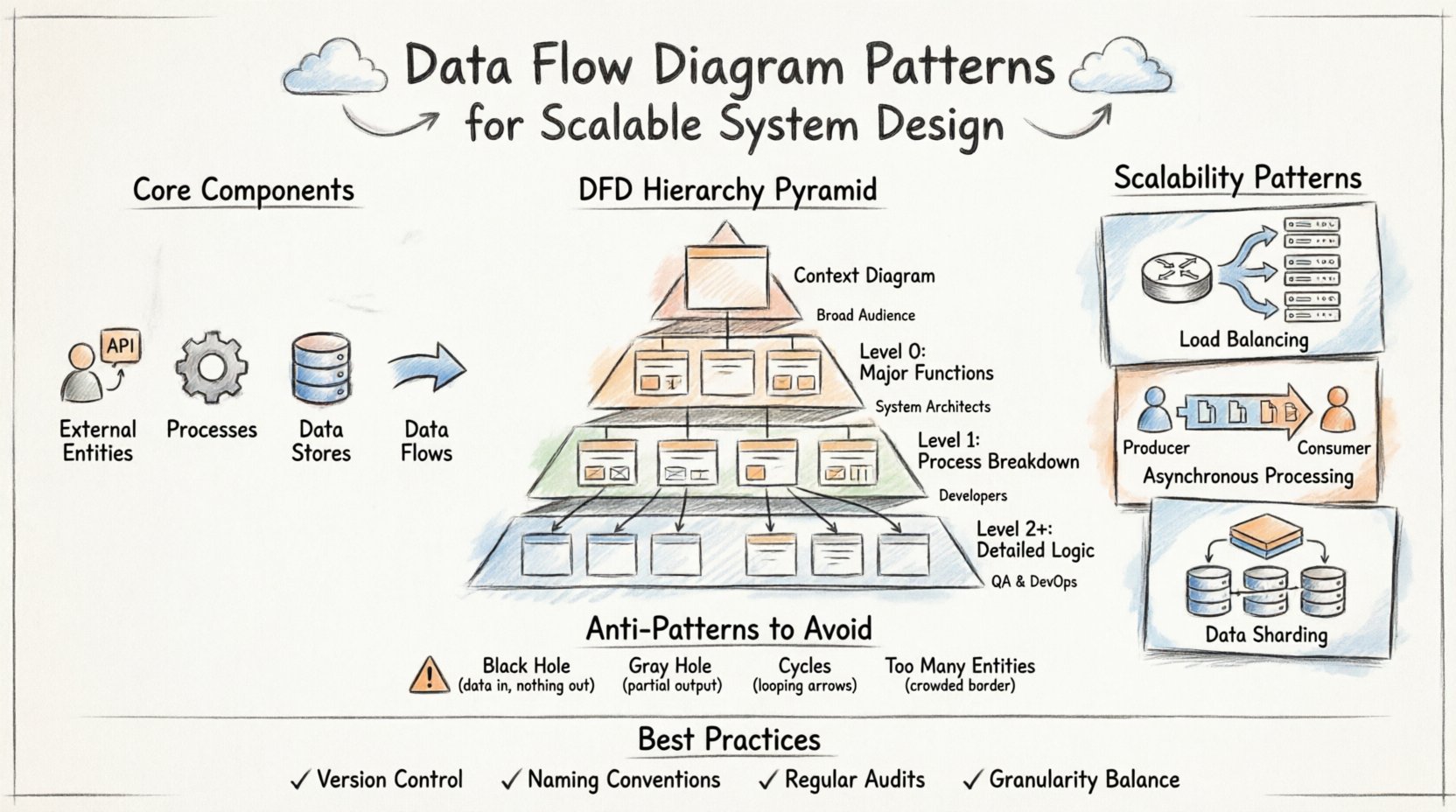
🧩 Composants fondamentaux d’un diagramme de flux de données
Avant de s’attaquer aux modèles, il faut maîtriser les éléments de base. Chaque DFD repose sur quatre éléments fondamentaux. Les confondre entraîne des modèles ambigus qui ne parviennent pas à guider efficacement le développement.
- Entités externes : Représentent des sources ou des destinations situées en dehors de la frontière du système. Cela inclut les utilisateurs, les API tierces ou les périphériques matériels.
- Traitements : Transforment les données d’une forme à une autre. Ce sont les calculs actifs ou les points de logique métier au sein du système.
- Stockages de données : Emplacements où les données sont au repos. Cela peut être des bases de données, des systèmes de fichiers ou des mémoires tampon.
- Flux de données : Les chemins empruntés par les données entre les entités, les traitements et les stockages. Les flèches indiquent la direction et le contenu.
Chaque composant doit être clairement défini afin d’éviter toute ambiguïté. Par exemple, un traitement ne doit jamais avoir une flèche pointant vers un autre traitement sans un flux de données correspondant. Chaque flèche doit représenter une information réelle qui circule dans le système.
📉 La hiérarchie des niveaux de DFD
Les systèmes évolutifs nécessitent différents niveaux d’abstraction. Un seul diagramme capte rarement toute la complexité. En revanche, une hiérarchie est utilisée pour descendre du contexte de haut niveau jusqu’à la logique d’implémentation détaillée. Cette structure permet aux équipes de revoir le tableau global sans se perdre dans les détails.
| Niveau | Objectif | Complexité | Public cible principal |
|---|---|---|---|
| Diagramme de contexte | Frontière du système et interactions externes | Faible | Intéressés, gestion |
| Niveau 0 (DFD 0) | Fonctions principales du système et stockages de données | Moyen | Architectes système |
| Niveau 1 | Découpage des traitements du niveau 0 | Élevé | Développeurs, ingénieurs |
| Niveau 2+ | Logique algorithmique ou sous-processus spécifique | Très élevé | Ingénieurs spécialisés |
Maintenir la cohérence entre ces niveaux est essentiel. Un magasin de données identifié au niveau 0 doit être référencé correctement au niveau 1. Si un processus est divisé au niveau 1, les flux d’entrée et de sortie doivent correspondre au processus parent au niveau 0. Ce équilibre garantit que le modèle reste une référence fiable tout au long du cycle de vie.
🚀 Modèles d’évolutivité dans l’architecture système
Concevoir pour l’évolutivité nécessite des choix de modélisation spécifiques. Les diagrammes standards masquent souvent les mécanismes de gestion de la charge. Pour répondre à l’évolutivité, les architectes doivent explicitement représenter des modèles qui répartissent le travail ou gèrent les ressources.
1. Équilibrage de charge et distribution
Dans les systèmes à fort trafic, un seul processus ne peut pas gérer toutes les requêtes entrantes. Le diagramme de flux de données doit refléter le mécanisme de distribution.
- Modèle de routeur : Introduisez un nœud de processus qui dirige le trafic vers plusieurs nœuds de service.
- Réplication : Montrez plusieurs processus identiques recevant le même flux de données pour un traitement parallèle.
- File d’attente : Représentez un magasin de données qui agit comme tampon avant le début du traitement, atténuant les pics.
Lors de la création d’un routeur, assurez-vous que le flux se divise de manière logique. Si le système utilise une stratégie de type round-robin, le diagramme doit indiquer que la décision repose sur la charge et non sur le contenu des données. Cette distinction influence la manière dont la logique du backend est implémentée.
2. Traitement asynchrone
Les flux synchrones peuvent créer des goulets d’étranglement si une étape attend une autre. Les modèles asynchrones déconnectent les processus, permettant au système de s’échelonner indépendamment.
- Files de messages : Utilisez un magasin de données pour représenter une file d’attente. Le producteur écrit dans le magasin, et le consommateur lit plus tard.
- Flux d’événements : Montrez un processus qui émet un événement déclenchant plusieurs consommateurs en aval sans bloquer l’expéditeur.
- Tâches en arrière-plan : Séparez les tâches longues des requêtes orientées utilisateur en les aiguillant vers un pool de processus dédié.
Cette séparation permet aux processus orientés utilisateur de rester légers tandis que le travail lourd s’effectue en arrière-plan. Le DFD rend cette séparation visible, empêchant les développeurs de supposer des temps de réponse immédiats.
3. Fractionnement des données et partitionnement
À mesure que le volume de données augmente, les unités de stockage uniques deviennent des barrières de performance. Les modèles de fractionnement dans les DFD aident à visualiser comment les données sont réparties sur plusieurs magasins.
- Fragments horizontaux : Affiche un processus acheminant des sous-ensembles de données spécifiques vers des magasins de données différents en fonction d’un ID ou d’une clé.
- Réplicas de lecture : Indiquez des flux distincts pour la lecture des données à partir des réplicas, tandis que les écritures vont vers le magasin principal.
- Niveaux de mise en cache : Insérez un magasin de données de cache entre le processus et la base de données principale pour réduire la latence.
| Schéma | Avantage en matière d’évolutivité | Compromis |
|---|---|---|
| Équilibrage de charge | Augmente le débit | Complexité accrue dans la gestion d’état |
| Files d’attente asynchrones | Découple les dépendances | Consistance éventuelle |
| Fractionnement (sharding) | Élargit la capacité de stockage | Requêtes complexes à travers les shards |
| Mise en cache | Réduit la latence | Risques de données obsolètes |
⚠️ Anti-modèles courants à éviter
Même avec de bonnes intentions, les diagrammes de flux de données peuvent contenir des défauts structurels qui entraînent des échecs du système. Reconnaître ces anti-modèles tôt évite un restructurage coûteux plus tard.
1. Le trou noir
Un trou noir se produit lorsqu’un processus reçoit des données mais ne produit aucun résultat. Cela se produit souvent lorsque l’on suppose qu’un processus supprime des données ou les traite en silence.
- Risque :Perte de données sans notification d’erreur.
- Solution : Assurez-vous que chaque entrée a un flux de sortie correspondant ou un chemin d’erreur clair.
- Impact sur l’évolutivité :Les échecs silencieux sont difficiles à déboguer dans les systèmes distribués.
2. Le trou gris
Un trou gris est similaire à un trou noir, mais avec une sortie partielle. Le processus consomme plus de données qu’il n’en produit, sans expliquer ce qu’est devenu le reste.
- Risque :Une consommation de données non expliquée entraîne des fuites de stockage ou des erreurs de transaction.
- Solution :Modélisez explicitement tous les chemins de données, y compris les journaux d’erreurs ou les traces d’audit.
3. Les cycles dans le flux de données
Bien que certains boucles de rétroaction soient nécessaires (par exemple, les mécanismes de réessai), les cycles non contrôlés peuvent entraîner des boucles infinies de traitement.
- Risque :Blocages du système ou épuisement des ressources.
- Solution :Limitez la profondeur de récursion dans le diagramme et mettez en œuvre des mécanismes d’expiration dans la conception.
4. Les entités externes infinies
Ajouter trop d’entités externes rend le diagramme illisible et masque la logique centrale.
- Risque :Perte de clarté sur les limites du système.
- Solution :Regroupez les entités associées en une seule entité « Système de référence » ou « Interface utilisateur », lorsque cela est pertinent.
🔄 Meilleures pratiques pour la maintenance et l’évolution
Un diagramme de flux de données n’est pas un artefact ponctuel. Il doit évoluer avec le système. Maintenir le modèle précis garantit que les nouveaux membres de l’équipe comprennent l’architecture sans avoir à reverse-engineérer le code.
- Contrôle de version :Traitez les diagrammes comme du code. Stockez-les dans un dépôt pour suivre les modifications au fil du temps.
- Conventions de nommage :Utilisez un nommage cohérent pour les processus et les flux de données. « Mettre à jour l’utilisateur » doit toujours être « Mettre à jour l’utilisateur », et non « Modifier les détails de l’utilisateur ».
- Audits réguliers :Programmez des revues périodiques pour garantir que le diagramme correspond à l’implémentation actuelle.
- Équilibre du niveau de détail :Ne faites pas de chaque processus un sous-processus. Regroupez la logique associée pour maintenir une vue gérable du système.
📝 Considérations finales
Une conception efficace du système repose sur une communication claire. Le diagramme de flux de données fournit un langage commun entre les architectes, les développeurs et les parties prenantes. En suivant des modèles établis et en évitant les pièges courants, les équipes peuvent construire des systèmes qui évoluent de manière fluide.
Souvenez-vous que les diagrammes sont des modèles, et non la réalité elle-même. Ils simplifient la complexité afin de la rendre compréhensible. Toutefois, cette simplification ne doit pas supprimer les détails critiques concernant l’intégrité et le flux des données. Lorsqu’un diagramme de flux de données (DFD) reflète fidèlement le déplacement des données, il devient un outil puissant pour prédire les goulets d’étranglement et optimiser les performances.
À mesure que les systèmes deviennent plus distribués, le besoin de modélisation rigoureuse augmente. Les modèles décrits ici fournissent une base pour cette rigueur. Que vous conceviez une application monolithique ou un écosystème de microservices, les principes du flux de données restent constants. Concentrez-vous sur le déplacement de l’information, et la structure suivra.
Commencez par le diagramme de contexte. Définissez clairement les limites. Descendez dans les processus uniquement lorsque cela est nécessaire. Gardez l’attention portée sur les données, et non sur la pile technologique. Cette discipline garantit que l’architecture reste flexible et évolutif pendant de nombreuses années.