











La création de modèles de systèmes robustes exige une approche rigoureuse quant à la manière dont les informations sont capturées, déplacées et conservées. Dans le contexte des diagrammes de flux de données (DFD), le magasin de données représente l’ossature de la persistance du système. Sans une conception claire de l’emplacement des données, le flux d’information reste abstrait et non implémentable. Ce guide explore les principes fondamentaux de la conception des magasins de données au sein des DFD, garantissant clarté, précision et alignement avec l’architecture du système.
Une modélisation efficace va au-delà du simple tracé de lignes entre des formes. Elle exige une compréhension approfondie de l’intégrité des données, des schémas d’accès et du cycle de vie de l’information au sein du système. En respectant des principes de conception établis, les analystes peuvent produire des diagrammes qui servent de plans fiables aux équipes de développement.
🏷️ Définition du magasin de données 🏷️
Un magasin de données est un élément passif dans un diagramme de flux de données. Contrairement aux processus, qui transforment les données, les magasins de données conservent les données au repos. Ils représentent des fichiers, des bases de données, des dossiers papier ou tout autre répertoire où les informations sont sauvegardées pour une récupération ultérieure.
- Nature passive :Les données ne sortent pas d’un magasin à moins qu’un processus ne le demande explicitement.
- Identité du stockage :Ce n’est pas un processus en soi ; il ne modifie pas les données, il les conserve.
- Représentation visuelle : Habituellement représenté par un rectangle à une extrémité ouvert, ou par deux lignes verticales doubles, selon la norme de notation utilisée.
Lors de la conception de ces éléments, l’attention doit rester centrée sur les exigences logiques plutôt que sur la mise en œuvre physique. Le DFD décritce dontles données sont nécessaires, et non pascommentelles sont physiquement indexées ou stockées sur un disque dur.
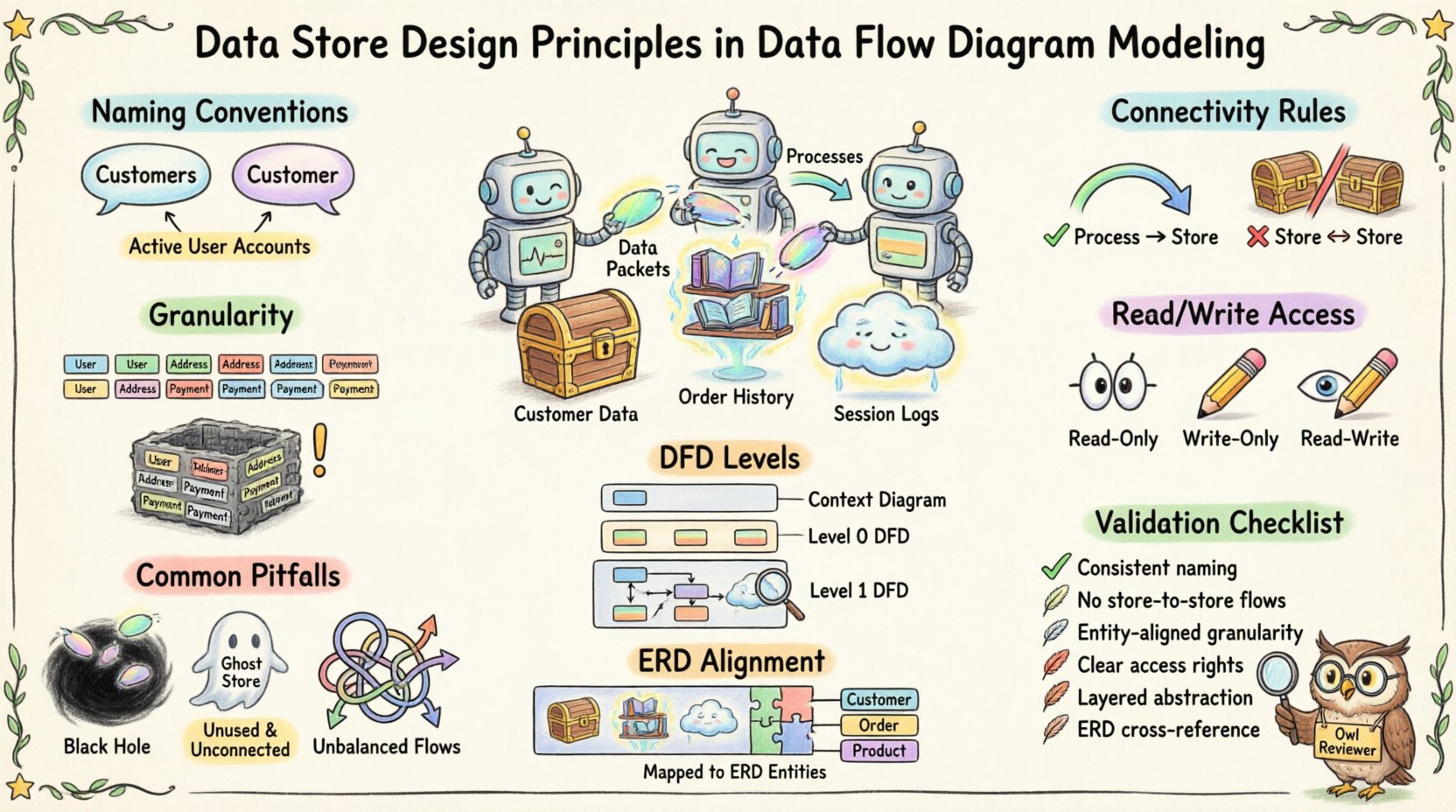
📝 Conventions de nommage pour plus de clarté 📝
Le nommage est la première ligne de défense contre la confusion. Les étiquettes ambiguës entraînent des malentendus pendant la phase de conception. Un magasin de données bien nommé fournit immédiatement un contexte sur les informations qu’il contient.
1. Singulier vs. Pluriel
La cohérence est essentielle. Certaines équipes préfèrent les noms au singulier (par exemple, Client) tandis que d’autres utilisent le pluriel (par exemple, Clients). Le facteur crucial est que l’ensemble du modèle utilise la même convention.
- Recommandation :Utilisez des noms au pluriel pour les ensembles de données (par exemple, Commandes, Produits) pour indiquer une collection.
- Exception :Les noms singuliers fonctionnent pour des instances spécifiques si le magasin ne contient qu’un seul type d’enregistrement (par exemple, Configuration).
2. Précision descriptive
Évitez les termes génériques comme Données ou Info. Ces étiquettes ne fournissent aucune information sur le contenu.
- Mauvais exemple : Données système
- Bon exemple : Comptes utilisateurs actifs
Un nom spécifique aide les parties prenantes à identifier immédiatement le périmètre du magasin. Cela réduit la charge cognitive nécessaire pour comprendre le schéma.
3. Temps et état
Les noms doivent refléter l’état des données. Si le magasin contient des enregistrements historiques, le nom doit le refléter.
- Journaux de transactions implique un enregistrement d’événements passés.
- Commandes en attente implique des données en attente d’une action.
🔗 Règles de connectivité 🔗
Le déplacement des données vers l’intérieur et vers l’extérieur d’un magasin est régi par des règles logiques strictes. Violation de ces règles compromet l’intégrité du DFD.
1. Exigence de connexion au processus
Un magasin de données doit toujours être connecté à au moins un processus. Il ne peut pas exister en isolation.
- Entrée : Un processus doit écrire des données dans le magasin (par exemple, enregistrer un nouvel enregistrement).
- Sortie : Un processus doit lire des données depuis le magasin (par exemple, récupérer un enregistrement).
Si un magasin n’est connecté à rien, il s’agit d’un élément fantôme sans fonction. Si un magasin est connecté à plusieurs processus, le flux de données doit être clairement défini pour chaque connexion.
2. Pas de flux direct entre deux magasins
Les données ne peuvent pas se déplacer directement d’un magasin de données à un autre sans qu’un processus ne soit interposé. Cette règle impose le principe selon lequel la transformation ou la validation des données a lieu avant leur stockage.
- Incorrect : Ligne reliant Magasin A directement à Magasin B.
- Correct : Processus X lit à partir de Magasin A, transforme les données, puis écrit dans Magasin B.
Cette séparation garantit que la logique métier, la validation ou le formatage sont appliqués avant que les données ne soient persistées. Elle empêche le modèle de suggérer que les données sont simplement copiées sans surveillance.
3. Étiquetage des flux de données
Chaque ligne reliant un processus à un magasin de données doit être étiquetée. L’étiquette décrit les données spécifiques qui traversent cette frontière.
- Exemple : Une ligne provenant de Processus de commande vers Magasin de commandes pourrait être étiquetée Détails de la commande.
- Exemple : Une ligne provenant de Magasin de commandes vers Processus de rapport pourrait être étiqueté Historique des commandes.
Les étiquettes fournissent un contexte concernant le volume et le type de données transférées. Elles aident les développeurs à comprendre les exigences du schéma ultérieurement.
🎯 Granularité et portée 🎯
Déterminer comment diviser les données en magasins est une décision de conception cruciale. Trop de magasins fragmentent le modèle, tandis que trop peu en créent un bloc monolithique d’informations.
1. Regroupement par entité
Regroupez les données par entité logique. Si le système suit les clients, les produits et les factures, ceux-ci devraient généralement résider dans des magasins distincts.
- Avantage :Simplifie la maintenance. Les modifications des données clients n’affectent pas la logique de stockage des factures.
- Avantage :Réduit le risque de corruption accidentelle des données lors des mises à jour.
2. Séparation lecture-écriture
Pensez si un magasin est principalement destiné à la lecture ou à l’écriture. Les journaux de transactions à fort volume nécessitent souvent une gestion de stockage différente des données de référence.
- Données de référence : Des magasins comme Codes pays sont très utilisés en lecture et changent rarement.
- Données de transaction : Des magasins comme Journaux de ventes sont très utilisés en écriture et augmentent au fil du temps.
Différencier ces types aide à planifier la capacité et les modèles d’accès, même si le diagramme de flux de données reste un modèle logique.
3. Temporaire vs. Permanent
Tous les magasins de données ne représentent pas un stockage permanent. Certains sont des tampons temporaires.
- Données de session : Des magasins utilisés pour les sessions utilisateur temporaires pendant un processus de connexion.
- Magasins de cache : Zones de stockage temporaire pour les données fréquemment consultées.
Marquer clairement les magasins temporaires empêche toute confusion concernant les politiques de conservation des données. Un magasin temporaire doit être vidé ou effacé une fois que le processus est terminé.
🔄 Flux de données et interaction des processus 🔄
Le lien entre un processus et un magasin de données est bidirectionnel dans de nombreux cas, mais pas toujours. Comprendre la directionnalité est essentiel pour une modélisation précise.
1. Accès en lecture seule
Certains magasins sont consultés uniquement en lecture. Un processus peut interroger un magasin pour afficher des informations sans les modifier.
- Exemple : Un Afficher le profil processus lisant à partir de Magasin des profils utilisateurs.
- Contrainte :Aucune flèche de flux de données ne doit pointer du magasin vers le processus ET revenir pour la même transaction, sauf si cela implique une opération d’écriture.
2. Accès en écriture seule
Certains processus écrivent des données sans avoir besoin de les récupérer au préalable.
- Exemple : Un Journal des événements processus écrivant dans Magasin d’audit du système.
- Contrainte :Assurez-vous que le processus dispose du contexte nécessaire pour écrire les données correctement sans entrée externe.
3. Accès en lecture-écriture
La plupart des processus métier impliquent la récupération, la modification et l’enregistrement des données.
- Exemple : Mettre à jour le stock lit le stock actuel, calcule le nouveau montant et l’enregistre.
- Modélisation :Utilisez des flux distincts pour la lecture et l’écriture afin de clarifier la séquence des opérations.
Cette distinction aide les développeurs à comprendre si une transaction de base de données nécessite un verrouillage ou un commit immédiat.
📊 Niveaux des DFD et visibilité des magasins 📊
Les DFD sont souvent décomposés en niveaux, des diagrammes de contexte (niveau 0) aux analyses détaillées (niveau 2, niveau 3). Les magasins de données apparaissent différemment à chaque niveau.
1. Niveau de contexte (niveau 0)
Au niveau le plus élevé, les magasins de données sont souvent omis afin de maintenir la simplicité. L’accent est mis sur les entités externes et la frontière principale du système.
- Raison :Trop de détails masquent l’échange de données au niveau élevé.
- Exception :Les bases de données externes majeures pourraient être affichées si elles sont critiques pour la frontière du système.
2. Décomposition au niveau 1
Lorsque le système est décomposé en processus majeurs, les magasins de données deviennent visibles. C’est ici que l’architecture de stockage principale est définie.
- Focus :Identifier les entrepôts principaux nécessaires à chaque fonction majeure.
- Détail :Assurez-vous que chaque processus dispose d’une destination pour ses données de sortie.
3. Niveau 2 et au-delà
Une décomposition supplémentaire peut diviser de grands magasins de données en magasins plus petits et plus spécifiques.
- Exemple : Magasin client au niveau 1 pourrait se diviser en Magasin des informations de contact et Magasin de facturation au niveau 2.
- Consistance :Assurez-vous que les données aux niveaux inférieurs correspondent aux données aux niveaux supérieurs. N’introduisez pas de nouveaux types de données qui n’étaient pas présents dans le diagramme parent.
⚠️ Pièges courants ⚠️
Même les analystes expérimentés commettent des erreurs lors de la conception des magasins de données. Éviter ces erreurs courantes garantit que le diagramme reste précis.
- Les trous noirs :Un processus qui reçoit des données mais ne les écrit nulle part. Cela implique une perte de données.
- Tempêtes de feu : Un processus qui reçoit des données en entrée mais en produit sans stockage. Cela implique que les données sont créées à partir de rien (miracle).
- Bases de données fantômes : Des bases de données sans processus connectés. Ce sont des impasses.
- Flux déséquilibrés : Lors du passage du niveau 1 au niveau 2, les entrées et sorties doivent correspondre. Si un stockage est ajouté au niveau 2, il doit être justifié par les entrées/sorties du processus parent.
- Surconception : Essayer de modéliser chaque table de base de données comme un stockage distinct dans un diagramme de niveau 1. Restez sur des entités logiques, pas sur des tables physiques.
📚 Alignement avec les modèles de données 📚
Bien que les diagrammes de flux de données (DFD) se concentrent sur le flux, ils doivent être alignés avec les diagrammes de relations entité (ERD) ou les modèles logiques de données. Les stocks de données dans le DFD doivent correspondre aux entités dans l’ERD.
- Vérification de cohérence : Si le DFD contient un Stock de produits, l’ERD doit contenir une Produit entité.
- Mappage des attributs : Les attributs requis par le processus pour interagir avec le stock doivent exister dans le modèle de données.
- Normalisation : Bien que les DFD ne forcent pas la normalisation, la conception doit éviter les redondances évidentes qui suggèrent une mauvaise conception de base de données.
Cet alignement garantit que la conception logique (DFD) peut être traduite en implémentation physique (schéma de base de données) sans restructuration importante.
🔍 Liste de contrôle de validation du design 🔍
Avant de finaliser un diagramme de flux de données, utilisez la liste de contrôle suivante pour valider la conception des stocks de données.
| Principe | Élément de la liste de contrôle | Statut |
|---|---|---|
| Nomination | Tous les noms de stock sont-ils descriptifs et cohérents ? | ☐ |
| Connectivité | Chaque magasin est-il connecté à au moins un processus ? | ☐ |
| Sens du flux | Les flèches pointent-elles correctement entre les processus et les magasins ? | ☐ |
| Étiquetage | Les données circulent-elles à travers des lignes étiquetées avec des noms de contenu ? | ☐ |
| Pas de liens directs entre les magasins | Y a-t-il des lignes reliant directement un magasin à un autre magasin ? | ☐ |
| Consistance | Les magasins de niveau inférieur correspondent-ils à la portée du niveau parent ? | ☐ |
| Intégrité | Toutes les exigences de données pour les processus sont-elles satisfaites par les magasins disponibles ? | ☐ |
🔄 Maintenance et évolution 🔄
Les exigences du système évoluent. Les magasins de données doivent être adaptables à ces changements sans rompre le modèle.
- Contrôle de version : Suivez les modifications apportées aux définitions des magasins. Si un magasin se divise, documentez le chemin de migration.
- Données héritées : Prévoyez la gestion des anciennes données lorsqu’un schéma de magasin change. Cela nécessite souvent un magasin d’archivage.
- Boucle de retour : Utilisez les retours des équipes de développement pour affiner la granularité des magasins. Si les développeurs trouvent un magasin trop large, divisez-le. S’ils le trouvent trop fragmenté, fusionnez-le.
Un modèle statique est une charge. La conception du magasin de données doit être revue chaque fois que les règles métier changent ou de nouvelles exigences de conformité sont introduites. Cela garantit que le diagramme de flux de données reste un document vivant qui reflète fidèlement les besoins en données du système.
📝 Conclusion sur l’implémentation
Concevoir des magasins de données dans les diagrammes de flux de données est une tâche fondamentale pour l’analyse du système. Il comble l’écart entre les processus abstraits et la persistance concrète des données. En suivant des conventions de nommage strictes, des règles de connectivité et des principes de granularité, les analystes créent des modèles à la fois lisibles et exploitables.
L’objectif n’est pas de reproduire parfaitement le schéma de base de données, mais de capturer la nécessité logique du stockage des données. Lorsque le DFD est précis, la transition vers le développement est plus fluide, et le risque de perte de données ou de désalignement est considérablement réduit. Concentrez-vous sur la clarté, la cohérence et le flux logique des informations pour produire des conceptions de systèmes de haute qualité.