











Dans le paysage de l’analyse métier moderne, la clarté n’est pas simplement un luxe ; c’est une nécessité. Les organisations doivent faire face à des flux de travail qui s’étendent sur plusieurs départements, des systèmes hérités et des interactions humaines. Lorsque la complexité augmente, le risque de malentendus s’accroît. C’est là que les techniques de modélisation structurées deviennent essentielles. Plus précisément, le diagramme de flux de données (DFD) offre une méthode solide pour visualiser le déplacement de l’information à travers un système. En décomposant les processus métiers complexes, les analystes peuvent transformer des tâches écrasantes en composants logiques gérables. Ce guide explore les mécanismes, les principes et l’application stratégique des DFD dans la décomposition des processus.
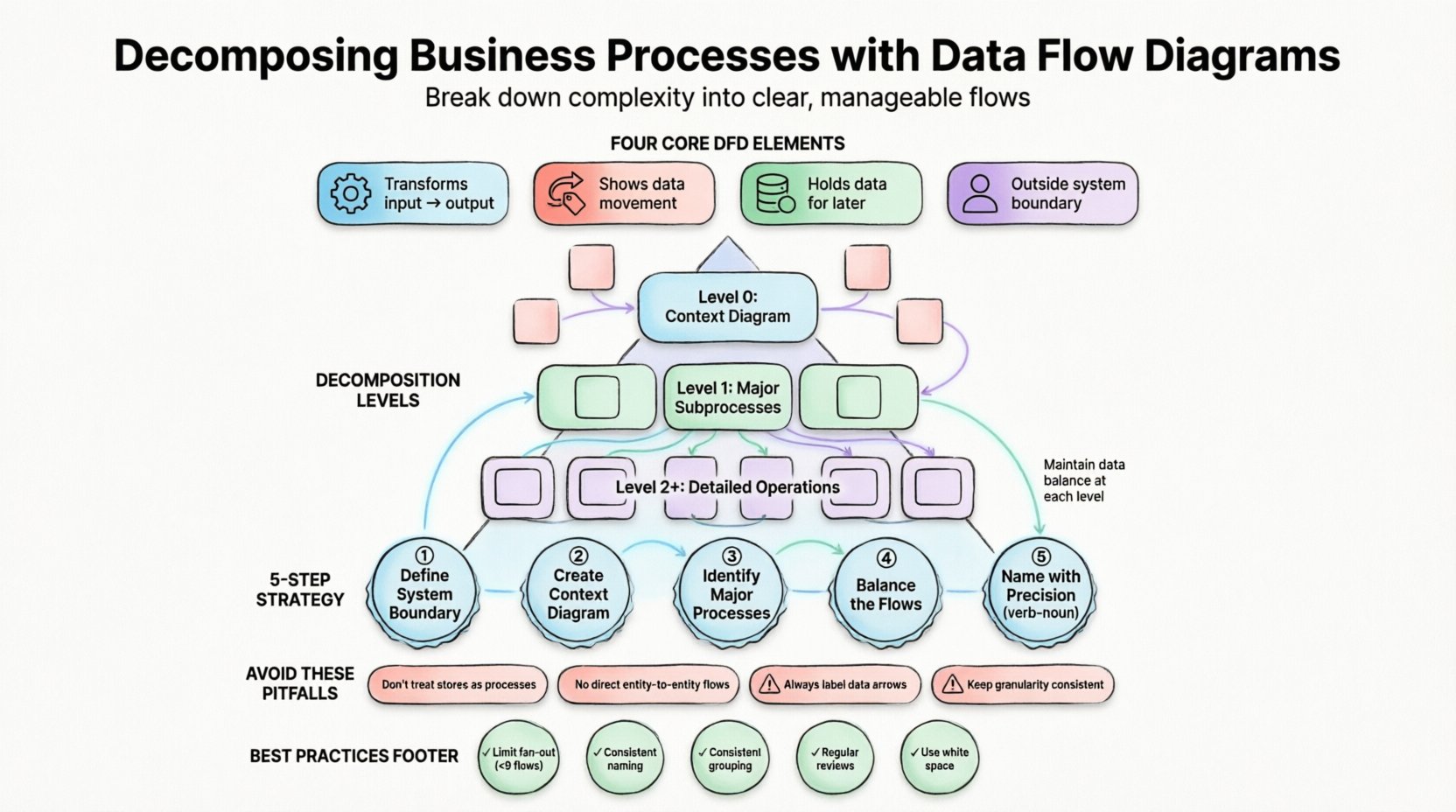
Comprendre les fondements des diagrammes de flux de données 🧩
Un diagramme de flux de données est une représentation graphique du déplacement des données à travers un système d’information. Contrairement aux organigrammes, qui représentent souvent la logique de contrôle ou les étapes procédurales, les DFD se concentrent strictement sur les données. Ils illustrent d’où proviennent les données, où elles sont stockées, comment elles sont transformées et où elles sortent finalement. Cette distinction est cruciale pour les analystes métiers qui doivent comprendre la substance des opérations, et non seulement la séquence des événements.
Les DFD structurés s’appuient sur une notation spécifique pour assurer une cohérence dans la documentation. Le diagramme repose sur quatre éléments principaux :
- Traitements :Actions qui transforment les données d’entrée en données de sortie. Ils sont généralement représentés par des rectangles arrondis ou des cercles. Ils décrivent ce quiarrive aux données.
- Flux de données :Le déplacement des données entre les traitements, les entrepôts et les entités. Ils sont représentés par des flèches et doivent être clairement étiquetés pour indiquer le contenu qui est déplacé.
- Entrepôts de données :Lieux où les données sont conservées pour une utilisation ultérieure. Ce sont des rectangles ou des lignes parallèles ouverts à une extrémité. Ils représentent des bases de données, des fichiers ou des archives physiques.
- Entités externes :Sources ou destinations de données situées à l’extérieur de la frontière du système. Ce sont des carrés ou des rectangles qui représentent des utilisateurs, d’autres systèmes ou des organisations.
Sans une approche standardisée, ces diagrammes peuvent devenir chaotiques. Les DFD structurés imposent une discipline qui garantit que chaque flux de données a une source et une destination, et que chaque traitement transforme les données de manière logique.
L’impératif de la décomposition 🔨
Les processus métiers complexes ne rentrent rarement sur une seule page. Tenter de représenter l’ensemble d’une opération d’entreprise en une seule vue produit un diagramme incompréhensible pour les parties prenantes. La décomposition est la technique utilisée pour diviser un processus de haut niveau en détails de niveau inférieur. Cette approche hiérarchique permet aux analystes de gérer la charge cognitive et de maintenir une précision constante.
La décomposition remplit plusieurs fonctions essentielles :
- Contrôle de la granularité :Elle permet à l’équipe de zoomer sur des zones spécifiques d’intérêt sans perdre de vue le contexte global.
- Alignement des parties prenantes :Les différentes parties prenantes ont besoin de niveaux de détail différents. Les dirigeants peuvent consulter le diagramme de haut niveau, tandis que les développeurs ont besoin des sous-processus détaillés.
- Détection des erreurs :Les interactions complexes deviennent plus faciles à repérer lorsqu’elles sont isolées. Les incohérences de données ou les flux manquants sont plus visibles aux niveaux inférieurs.
- Modularité :Elle encourage à penser en termes de fonctions discrètes, ce qui s’aligne bien avec l’architecture logicielle moderne et les microservices.
Le processus de décomposition n’est pas arbitraire. Il suit un cheminement logique où un processus parent est étendu en processus enfants qui, ensemble, rendent compte de toutes les données entrant et sortant du processus parent.
Niveaux de décomposition dans les DFD structurés 📈
Pour maintenir une structure, les DFD sont généralement organisés en niveaux. Cette hiérarchie garantit que l’abstraction reste cohérente lors de l’ajout de détails. Le tableau suivant décrit les niveaux standards de décomposition :
| Niveau | Nom courant | Description |
|---|---|---|
| 0 | Diagramme de contexte | Montre l’ensemble du système comme un seul processus interagissant avec des entités externes. |
| 1 | Diagramme de niveau 0 | Découpe le processus principal en sous-processus majeurs (généralement de 3 à 9). |
| 2 | Diagrammes de niveau 1 | Décompose davantage des processus spécifiques du niveau 0 en opérations détaillées. |
| 3+ | Diagrammes enfants | Analyse approfondie de la logique complexe pour les détails d’implémentation. |
Chaque niveau doit respecter le principe de équilibre des données. Cela signifie que les entrées et sorties d’un processus parent doivent correspondre exactement aux entrées et sorties combinées de ses processus enfants. Si un processus de niveau 0 a une entrée « Données de commande », les sous-processus de niveau 1 doivent collectivement accepter les « Données de commande » et ne peuvent pas introduire de nouvelles entrées externes sans justification.
Stratégie de décomposition étape par étape 🚀
Exécuter une décomposition nécessite une approche méthodique. Se précipiter pour dessiner des flèches conduit souvent à des erreurs structurelles. Le flux de travail suivant garantit une structure de diagramme solide.
1. Définir la frontière du système
Avant de dessiner quoi que ce soit, déterminez ce qui se trouve à l’intérieur du système et ce qui se trouve à l’extérieur. Cette frontière définit le périmètre du projet. Les entités externes existent à l’extérieur de cette frontière. Tout ce qui se produit à l’intérieur de la frontière est un processus ou un stockage. Cette définition empêche le débordement de portée pendant la phase d’analyse.
2. Créer le diagramme de contexte
Commencez par la vue de haut niveau. Placez le système sous forme d’une seule bulle au centre. Identifiez les entités externes majeures qui interagissent avec lui. Dessinez les principaux flux de données entre elles. Ce diagramme fournit une vue « en hélicoptère » pour que les parties prenantes confirment le périmètre.
3. Identifier les processus majeurs
Examinez les flux de données entrant et sortant du système. Chaque transformation distincte suggère un processus majeur. Par exemple, si les « Données client » entrent et que les « Données de facture » sortent, la transformation est probablement « Générer une facture ». Regroupez-les en clusters logiques.
4. Équilibrer les flux
Lorsque vous décomposez un processus, vérifiez les entrées et sorties. Assurez-vous qu’aucune donnée ne disparaît (un trou noir) et qu’aucune donnée n’apparaît de nulle part (un miracle). Chaque flèche entrant dans un sous-processus doit être justifiée par les données sortant de celui-ci.
5. Nommer avec précision
L’étiquetage est souvent négligé mais est crucial pour la lisibilité. Les noms des processus doivent être des phrases verbe-nom, comme « Valider la commande » ou « Calculer la taxe ». Évitez les étiquettes vagues comme « Traiter les données ». L’étiquette doit décrire la transformation spécifique en cours.
Péchés courants dans la modélisation des processus ⚠️
Même les analystes expérimentés rencontrent des problèmes lors de la modélisation des flux de données. Reconnaître ces schémas tôt peut éviter un travail de reprise important. Les erreurs suivantes sont fréquemment observées lors de la décomposition.
Les magasins de données comme processus
Il est tentant de considérer une base de données comme un processus parce que les données interagissent avec elle. Cependant, une base de données est un stockage passif. Elle ne transforme pas les données ; elle les conserve. Un processus doit être associé à un verbe d’action. Un magasin est accédé par un processus, et non un processus lui-même.
Connecter les entités directement
Les données ne peuvent pas circuler directement d’une entité externe à une autre sans passer par le système. Si un client envoie une demande et reçoit une réponse, les données doivent entrer dans un processus, être transformées, puis sortir. Une ligne directe entre deux entités implique qu’elles sont la même entité ou que le système est contourné.
Flux de données non étiquetés
Une flèche sans étiquette est sans signification. Elle ne précise pas quelles informations circulent. Chaque flux doit être nommé, par exemple « Adresse d’expédition » ou « Statut du paiement ». L’ambiguïté ici entraîne des erreurs d’implémentation ultérieures.
Granularité incohérente
Un processus peut être détaillé tandis qu’un processus voisin est vague. Cette incohérence confond les lecteurs. Si un sous-processus est décomposé en trois étapes, les processus adjacents doivent être au même niveau de détail, sauf s’ils sont intrinsèquement plus simples.
Intégrer les diagrammes en flux de données aux exigences métiers 📝
Un diagramme n’est utile que s’il correspond aux besoins métiers réels. Les diagrammes en flux de données ne doivent pas exister en vase clos. Ils doivent servir de fondement visuel à la documentation des exigences. Lorsqu’une exigence stipule que « Le système doit valider les cartes de crédit », le DFD doit montrer un processus de validation recevant les données de la carte et produisant un indicateur de statut.
Cette traçabilité est essentielle pour les audits et la conformité. Dans les secteurs réglementés, la capacité à prouver d’où proviennent les données et comment elles sont protégées est obligatoire. Le DFD fournit la carte pour les revues de sécurité. Les analystes peuvent identifier où les données sensibles circulent et s’assurer que des contrôles appropriés sont appliqués au niveau des processus.
Meilleures pratiques pour la modélisation structurée ✅
Pour maintenir une haute qualité dans vos diagrammes, respectez les meilleures pratiques suivantes. Ces directives favorisent la cohérence et la facilité de maintenance.
- Limitez le fan-out :Évitez de connecter un seul processus à plus de neuf flux de données. Si un processus est aussi complexe, il a probablement besoin d’être décomposé davantage.
- Nommage cohérent :Utilisez la même terminologie pour les flux de données à tous les niveaux. Si « Données de commande » est utilisé au niveau 0, ne l’appeler pas « Demande client » au niveau 1.
- Regroupement logique :Regroupez les processus liés ensemble. Si un ensemble de processus traite toujours des données financières, gardez-les regroupés visuellement pour faciliter la compréhension.
- Revoyez régulièrement :Les processus métiers évoluent. Un DFD est un document vivant. Prévoyez des revues périodiques pour vous assurer que le diagramme reflète les opérations actuelles.
- Utilisez l’espace blanc :Ne cramponnez pas les éléments ensemble. Un espacement adéquat réduit la charge cognitive et rend le diagramme plus facile à lire.
Le rôle de la décomposition dans la conception des systèmes 🏗️
Au-delà de la documentation, la décomposition des DFD influence la manière dont les systèmes sont construits. Lorsque les processus sont clairement définis, les équipes de développement peuvent attribuer des modules à des développeurs ou des équipes spécifiques. Cette modularité réduit les dépendances entre les équipes. Si le processus A et le processus B sont indépendants, ils peuvent être développés en parallèle.
En outre, la décomposition aide à identifier les goulets d’étranglement liés aux performances. Si un sous-processus particulier consomme des ressources excessives ou introduit une latence importante, il devient une cible d’optimisation. Sans décomposition, le goulet d’étranglement reste caché dans la vision monolithique du système.
Elle soutient également les stratégies de test. Les cas de test peuvent être directement dérivés des flux de données. Si un processus convertit « Entrée A » en « Sortie B », un cas de test doit vérifier cette transformation spécifique. Cette alignement entre conception et test garantit une livraison de meilleure qualité.
Gérer les processus concurrents et les boucles 🔄
Les processus métiers du monde réel impliquent souvent des boucles et des actions concurrentes. Un DFD standard représente la logique de manière linéaire, mais les règles métier peuvent être itératives. Par exemple, une commande peut nécessiter plusieurs étapes de vérification avant son approbation. Dans le schéma, cela est représenté par des flux de données qui reviennent vers des processus antérieurs.
Lors de la modélisation des boucles, la clarté est primordiale. Assurez-vous que la condition de boucle est documentée dans la description du processus, et non seulement implicite à travers la flèche. Un flux qui revient vers un processus indique un cycle de reprise ou une nouvelle tentative de validation. Déclarer explicitement la condition de retour évite toute ambiguïté pour l’équipe de développement.
Les processus concurrents sont représentés par des flux parallèles. Si deux processus ont lieu simultanément, dessinez-les sur des branches distinctes. Toutefois, rappelez-vous que les DFD ne montrent pas le moment ou les points de synchronisation. Ce niveau de détail appartient à d’autres notations de modélisation. Le DFD se concentre sur l’existence du flux, et non sur son moment.
Considérations finales pour les analystes 🤔
Maîtriser l’art de la décomposition exige de la pratique et de la patience. C’est une compétence qui se développe au fil du temps, au fur et à mesure que les analystes rencontrent divers types de logique métier. L’objectif n’est pas de créer le diagramme le plus détaillé possible, mais le plus utile.
Souvenez-vous que le diagramme est un outil de communication. Son public principal est souvent constitué de parties prenantes non techniques qui doivent comprendre le flux d’information. Si le diagramme est trop technique, il échoue à remplir sa fonction. Équilibrez le niveau d’abstraction en fonction du niveau de compétence de votre public.
La documentation doit toujours soutenir le processus de prise de décision. Lorsqu’un dirigeant métier demande d’où provient un point de données spécifique, le DFD doit fournir la réponse rapidement. Cette fiabilité renforce la confiance dans la fonction d’analyse. Au fil du temps, la collection de diagrammes devient un actif précieux pour l’organisation, servant de référence pour les évolutions futures du système.
Au fur et à mesure que les systèmes évoluent, les diagrammes doivent évoluer avec eux. Les diagrammes obsolètes sont pires que pas de diagrammes du tout, car ils induisent en erreur. Engagez-vous à maintenir l’intégrité des modèles de flux de données. Traitez-les avec le même soin que le code qui sera finalement écrit pour les soutenir. Cette rigueur garantit que la logique métier reste transparente et accessible.
En fin de compte, la valeur réside dans la clarté acquise. En décomposant le complexe en éléments compréhensibles, les analystes permettent à leurs organisations de fonctionner plus efficacement. L’approche structurée des diagrammes de flux de données fournit le cadre pour cette clarté, transformant le chaos en ordre.