











Dans l’architecture complexe des systèmes distribués modernes, le temps n’est pas simplement une mesure à effectuer ; c’est une contrainte fondamentale qui dicte le comportement du système. La fiabilité du logiciel ne consiste pas uniquement à éviter les plantages ou à gérer les exceptions ; elle consiste à garantir que les composants interagissent correctement dans des limites temporelles précises. Lorsque plusieurs threads, services ou périphériques matériels tentent d’accéder à des ressources partagées, la séquence et la durée de ces interactions deviennent critiques. C’est là que les diagrammes de timing deviennent indispensables.
Les diagrammes de timing fournissent une représentation visuelle de la manière dont les signaux ou les messages changent d’état au fil du temps. Ils permettent aux ingénieurs de modéliser les relations temporelles entre les événements avant qu’une seule ligne de code ne soit exécutée. En visualisant l’écoulement du temps, les équipes peuvent identifier des goulets d’étranglement potentiels, des conditions de course et des erreurs de synchronisation souvent invisibles dans les schémas statiques ou les diagrammes de séquence. Ce guide explore les mécanismes d’utilisation des diagrammes de timing pour améliorer la fiabilité du logiciel, en offrant une analyse approfondie de la concurrence, de l’analyse de latence et de la validation du système.
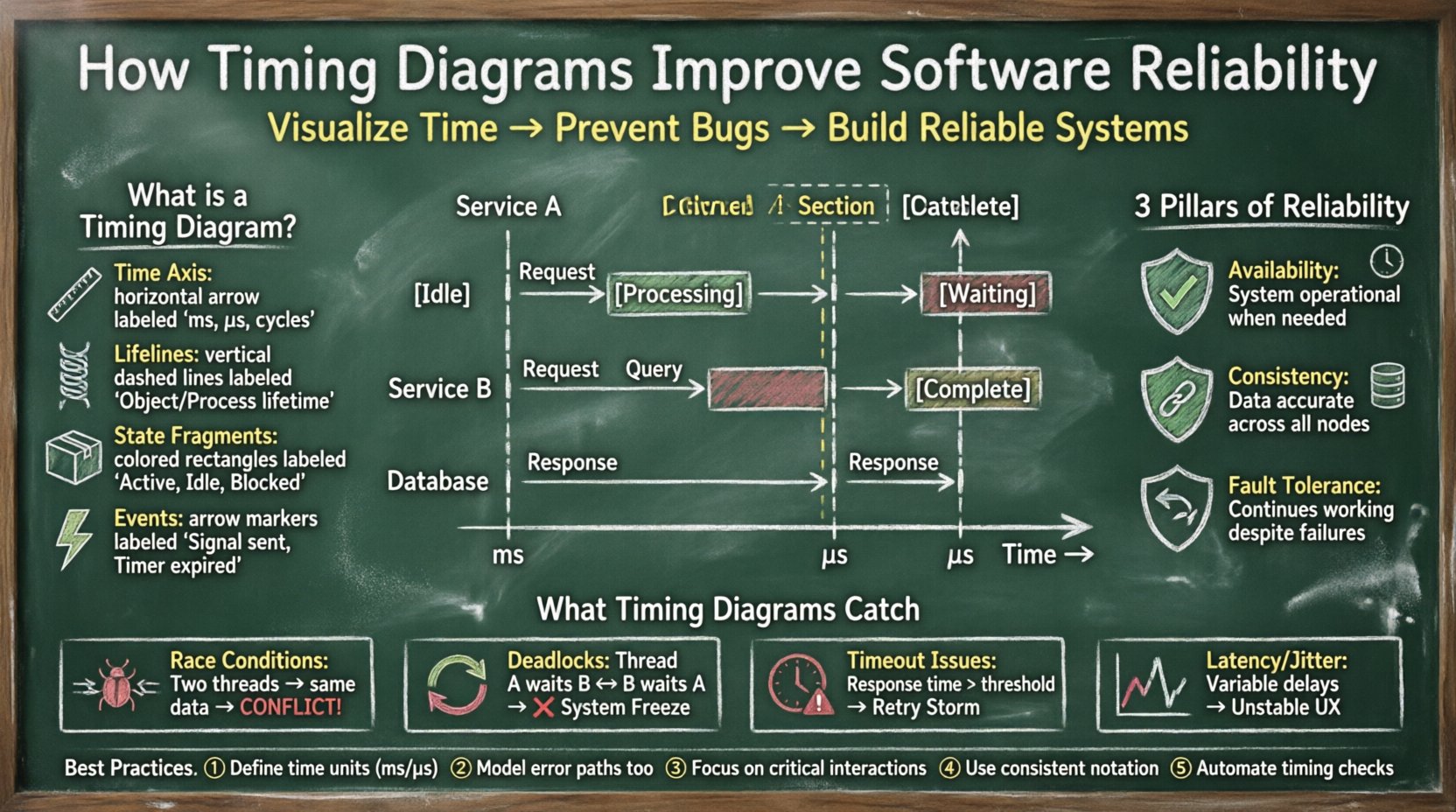
🔍 Définition des diagrammes de timing en ingénierie
Un diagramme de timing est un type de diagramme comportemental en modélisation de système qui décrit le comportement des objets au fil du temps. Contrairement au diagramme de séquence, qui se concentre principalement sur l’ordre des messages, un diagramme de timing met l’accent sur les relations temporelles entre les événements. Il affiche les états des objets et les transitions entre eux le long d’un axe horizontal du temps.
- Axe du temps : Il court généralement horizontalement de gauche à droite, représentant l’évolution du temps en millisecondes, microsecondes ou cycles d’horloge.
- Lignes de vie : Des barres verticales représentant l’existence d’un objet ou d’un processus au fil du temps.
- Fragments d’état : Des zones rectangulaires sur la ligne de vie indiquant l’état de l’objet (par exemple, Actif, Inactif, Bloqué, En traitement).
- Événements : Des flèches ou des repères indiquant le moment où une action spécifique se produit, comme l’envoi d’un signal ou l’expiration d’un minuteur.
En cartographiant ces éléments, les développeurs créent une chronologie des opérations du système. Ce contexte visuel est crucial pour comprendre combien de temps un processus met à se terminer et comment il attend d’autres processus. Il transforme la logique abstraite en une chronologie concrète pouvant être analysée à la recherche d’erreurs.
🏗️ Les piliers fondamentaux de la fiabilité logicielle
La fiabilité en génie logiciel fait référence à la probabilité qu’un système exécute ses fonctions requises dans des conditions déterminées pendant une période donnée. Pour y parvenir, trois piliers principaux doivent être abordés :
- Disponibilité : Le système doit être opérationnel lorsqu’il est nécessaire. Les diagrammes de timing aident à vérifier que les processus de récupération s’achèvent dans des délais acceptables.
- Consistance : Les données doivent rester précises sur tous les nœuds distribués. Visualiser les opérations d’écriture et de lecture aide à garantir que l’intégrité des données n’est pas compromise par la latence.
- Résilience aux pannes : Le système doit continuer à fonctionner malgré les pannes. Les diagrammes de timing illustrent combien de temps il faut à un mécanisme de secours pour s’activer, garantissant qu’aucune interruption de service ne soit perçue par l’utilisateur.
Sans une compréhension claire des contraintes temporelles, un système pourrait être logiquement correct mais pratiquement peu fiable. Par exemple, une requête de base de données pourrait retourner les données correctes, mais si elle prend 10 secondes à traiter, elle viole l’exigence de fiabilité d’une interface utilisateur réactive. Les diagrammes de timing mettent en évidence ces violations temporelles.
🐞 Détecter les conditions de course par analyse visuelle
Une condition de course se produit lorsque deux ou plusieurs processus accèdent aux données partagées de manière concurrente, et que le résultat final dépend du timing relatif de leur exécution. Ces situations sont particulièrement difficiles à déboguer car elles sont non déterministes et disparaissent souvent lorsque les débogueurs sont attachés.
Les diagrammes de timing réduisent ce risque en imposant un ordre visuel strict des événements. Lorsqu’on modélise une condition de course potentielle, un ingénieur peut dessiner les lignes de vie des threads concurrents. Si le diagramme montre que les deux threads tentent d’écrire à la même localisation mémoire simultanément sans barrière de synchronisation, l’erreur devient immédiatement visible.
- Visualisation des sections critiques : Mettre en évidence la durée durant laquelle une ressource est verrouillée. Si un autre processus tente d’accéder à cette ressource pendant cette fenêtre, le diagramme montre un conflit.
- Identification des instabilités : Dans les interfaces matériel-logiciel, des instabilités de signal peuvent survenir si les temps de préparation et de maintien ne sont pas respectés. Les diagrammes de timing montrent explicitement ces fenêtres.
- Dépendances d’ordre : Assurez-vous que l’initialisation A est terminée avant que l’initialisation B ne commence. Le diagramme impose un contrôle temporel sur cette dépendance.
En résolvant ces problèmes pendant la phase de conception, la probabilité d’échecs en production diminue considérablement. Cela déplace la détection des bogues de concurrence des journaux d’exécution vers les revues de conception.
🧵 Gestion de la concurrence et de la synchronisation des threads
Les applications modernes dépendent fortement du traitement asynchrone pour gérer les charges élevées. Les threads, les coroutines et les pools de travailleurs permettent à plusieurs tâches de s’exécuter en parallèle. Toutefois, les primitives de synchronisation telles que les mutex, les sémaphores et les verrous introduisent leurs propres complexités temporelles.
Les diagrammes de temporisation aident à modéliser ces points de synchronisation. Ils aident à répondre à des questions telles que :
- Combien de temps un thread attend-il un verrou avant d’expirer ?
- Le temps d’acquisition du verrou varie-t-il en fonction de la charge du système ?
- Y a-t-il des blocages où deux threads attendent indéfiniment l’un l’autre ?
Lors de la conception d’une application multithreadée, les ingénieurs peuvent esquisser l’état de chaque thread. Si le thread A détient la ressource 1 et attend la ressource 2, tandis que le thread B détient la ressource 2 et attend la ressource 1, un diagramme de temporisation peut révéler la condition d’attente circulaire. Cette preuve visuelle permet de restructurer la logique d’acquisition des ressources avant le début de l’implémentation.
En outre, les diagrammes de temporisation clarifient le comportement de l’inversion de priorité. Dans les systèmes temps réel, une tâche à haute priorité pourrait être bloquée par une tâche à basse priorité détenant un verrou. Un diagramme de temporisation rend cette inversion de priorité évidente, permettant aux architectes d’implémenter des protocoles d’héritage de priorité.
🌐 Protocoles réseau et vérification des échanges
Dans les systèmes distribués, la latence réseau est une variable qu’on ne peut ignorer. Les protocoles comme TCP/IP, HTTP/2 et gRPC reposent sur des échanges pour établir des connexions. Les diagrammes de temporisation sont essentiels pour valider ces interactions.
Prenons un échange standard en trois temps (SYN, SYN-ACK, ACK). Un diagramme de temporisation permet aux ingénieurs de définir une durée maximale autorisée pour ce processus. Si le diagramme montre que l’ACK prend plus de temps que le seuil de temporisation configuré, la connexion risque de échouer sous charge.
- Configuration du délai d’attente : Définir la durée exacte en millisecondes pour une requête avant qu’une nouvelle tentative ne soit déclenchée.
- Logique de retransmission : Visualiser l’intervalle entre un paquet défaillant et sa retransmission afin de s’assurer qu’il n’inonde pas le réseau.
- Intervalles de maintien de connexion : S’assurer que l’intervalle entre les messages de maintien de connexion est plus court que le délai d’inactivité réseau afin d’éviter une déconnexion prématurée.
En modélisant ces interactions réseau, les équipes peuvent s’assurer que leur logiciel gère correctement les variations de latence réseau. Cela évite les échecs en chaîne où une réponse lente d’un microservice provoque le blocage de l’ensemble de l’interface frontale.
⚙️ Temporisation de l’interface matériel-logiciel
La fiabilité du logiciel dépend souvent de la qualité de son interaction avec le matériel. Les systèmes embarqués, les appareils IoT et les plateformes de trading à haute fréquence exigent une temporisation précise. Un retard de quelques microsecondes peut entraîner une corruption des données ou une perte financière.
Les routines de service d’interruption (ISR) en sont un exemple typique. Lorsqu’une interruption matérielle se produit, le CPU doit interrompre les tâches en cours pour la traiter. Un diagramme de temporisation représente la latence d’interruption (temps entre la demande d’interruption et l’entrée dans l’ISR) et le temps de réponse à l’interruption.
- Latence d’interruption : Le temps nécessaire pour reconnaître l’interruption.
- Surcharge du changement de contexte : Le temps nécessaire pour sauvegarder et restaurer le contexte pendant l’ISR.
- Préservation des registres : S’assurer que l’état est sauvegardé avant que l’ISR ne le modifie.
Si le diagramme de timing indique que le ISR prend trop de temps, il peut bloquer d’autres interruptions critiques. Cette analyse visuelle permet aux développeurs d’optimiser le code du ISR ou de déporter le traitement vers un thread en arrière-plan, en garantissant que les exigences en temps réel sont respectées.
📉 Identification des problèmes de latence et de jitter
La latence est le délai avant le début du transfert des données après une instruction de transfert. Le jitter est la variation de la latence au fil du temps. Les deux sont néfastes pour l’expérience utilisateur et la stabilité du système. Les diagrammes de timing sont l’outil principal pour analyser ces métriques.
Lors de la modélisation d’un cycle de requête-réponse, les ingénieurs peuvent marquer les points exacts où se produit le traitement. Par exemple :
- Temps d’attente dans la file d’attente : Combien de temps une requête reste-t-elle dans le tampon avant le traitement ?
- Temps de traitement : Combien de temps la logique met-elle réellement à s’exécuter ?
- Transit réseau : Combien de temps les données mettent-elles à voyager à travers le câble ?
En additionnant ces segments, la latence totale est calculée. Si le jitter est élevé, le diagramme de timing montrera un espacement inconstant entre les événements lors de plusieurs itérations. Cette incohérence indique une instabilité dans l’infrastructure sous-jacente, ce qui incite à une investigation plus poussée sur la contention des ressources ou la congestion du réseau.
📝 Documentation des interactions système
La documentation est souvent négligée dans la quête de fonctionnalités, mais elle est essentielle pour la fiabilité à long terme. Le code évolue fréquemment, et de nouveaux membres rejoignent régulièrement l’équipe. Les diagrammes de timing servent de référence durable sur le comportement du système au fil du temps.
Un ensemble de diagrammes de timing bien maintenu fournit :
- Matériel d’intégration :Les nouveaux développeurs peuvent comprendre le flux temporel sans avoir à lire des milliers de lignes de code.
- Aide au débogage :Lorsqu’un bug survient, les ingénieurs peuvent comparer le comportement réel au diagramme de timing documenté afin de repérer les écarts.
- Définition du contrat : Ils définissent le comportement attendu entre les services, agissant comme un contrat d’intégration.
Cette documentation réduit la charge cognitive des ingénieurs lors de la réponse aux incidents. Au lieu de deviner le moment des événements, ils disposent d’une référence visuelle à suivre.
⚠️ Violations de timing courantes
Tous les problèmes de timing ne sont pas équivalents. Certains sont des défaillances critiques, tandis que d’autres représentent une dégradation des performances. Le tableau ci-dessous catégorise les violations courantes observées dans la modélisation système.
| Type de violation | Description | Impact sur la fiabilité |
|---|---|---|
| Violation du temps de préparation | Les données ne sont pas stables avant l’edge d’horloge. | Changements d’état imprévisibles, panne matérielle. |
| Violation du temps de maintien | Les données changent trop tôt après l’edge de l’horloge. | Corruption des données, métastabilité. |
| Expiration du délai d’attente | L’opération prend plus de temps que la limite définie. | Indisponibilité du service, tempêtes de nouvelles tentatives. |
| Bloquage | Deux processus attendent indéfiniment l’un l’autre. | Blocage du système, famine des ressources. |
| Inversion de priorité | Une tâche à haute priorité attend une tâche à basse priorité. | Délais manqués, échec en temps réel. |
| Débordement de tampon | Les données arrivent plus vite qu’elles ne peuvent être consommées. | Perte de paquets, épuisement de la mémoire. |
Examiner ces catégories par rapport aux diagrammes de timing de votre système permet de prioriser les problèmes nécessitant une correction immédiate. Les violations matérielles exigent souvent des mises à jour du firmware, tandis que les délais d’attente logiciels pourraient nécessiter un restructurage de la logique.
🔄 Intégration dans le cycle de vie du développement
Pour utiliser efficacement les diagrammes de timing en matière de fiabilité, ils doivent être intégrés dans le cycle de vie du développement logiciel (SDLC). Ils ne doivent pas être une réflexion tardive ajoutée après le déploiement.
- Phase de conception :Créer des diagrammes de timing de haut niveau lors des revues d’architecture système. Identifier les chemins critiques et les contraintes de timing.
- Phase d’implémentation :Utiliser les diagrammes de timing pour guider les tests unitaires. S’assurer que les tests unitaires couvrent les limites de timing, et non seulement la correction logique.
- Phase d’intégration :Effectuer une analyse de timing sur les composants intégrés. Vérifier que le système combiné respecte les exigences globales de timing.
- Phase de test :Utiliser des outils de test de charge pour générer des données de timing. Comparer les journaux de timing réels aux diagrammes d’origine.
- Phase de maintenance :Mettre à jour les diagrammes lorsque des modifications de code affectent le timing. S’assurer que la documentation reste synchronisée avec la base de code.
Cette intégration garantit que les considérations de timing font partie de la discussion à chaque étape, réduisant ainsi le coût de correction des problèmes de fiabilité plus tard dans le pipeline.
📊 Mesure des améliorations de fiabilité
Comment mesurez-vous l’avantage de l’utilisation des diagrammes de timing ? Bien que la fiabilité soit souvent mesurée en pourcentage de temps de fonctionnement, les diagrammes de timing contribuent à des métriques spécifiques :
- Moyenne du temps entre les pannes (MTBF) : En évitant les conditions de course et les blocages, la fréquence des pannes diminue.
- Moyenne du temps de réparation (MTTR) : Une meilleure documentation et des journaux visuels réduisent le temps nécessaire pour diagnostiquer les problèmes.
- Percentiles de latence : La latence P99 et P999 devient plus stable lorsque les goulets d’étranglement de temps sont identifiés tôt.
- Utilisation des ressources : Optimiser les temps d’attente réduit le temps d’inactivité du CPU et améliore le débit global.
Suivre ces métriques au fil du temps permet aux équipes de voir la corrélation directe entre une modélisation rigoureuse du temps et la stabilité du système. Cela fait passer la fiabilité d’un objectif qualitatif à une réalité quantitative.
💡 Résumé des meilleures pratiques
Pour maximiser l’impact des diagrammes de timing sur la fiabilité logicielle, adoptez les pratiques suivantes :
- Définir des unités de temps claires : Précisez toujours l’unité de temps (ms, s, cycles) pour éviter toute ambiguïté.
- Inclure les états d’erreur : Modélisez non seulement le parcours normal, mais aussi les parcours d’expiration et les parcours de gestion des erreurs.
- Se concentrer sur les chemins critiques : Ne diagrammez pas chaque opération individuelle. Concentrez-vous sur les interactions qui affectent la stabilité du système.
- Utiliser une notation cohérente : Adoptez une notation standard pour les lignes de vie et les événements afin d’assurer une compréhension commune au sein de l’équipe.
- Automatiser lorsque cela est possible : Intégrez des outils d’analyse de timing dans le pipeline CI/CD pour détecter automatiquement les régressions.
La fiabilité logicielle est un effort continu. Elle exige de la vigilance, une modélisation précise et une compréhension approfondie de la manière dont le temps affecte le comportement du système. Les diagrammes de timing offrent la clarté visuelle nécessaire pour naviguer dans cette complexité. En adoptant ces pratiques, les équipes d’ingénierie peuvent construire des systèmes qui ne sont pas seulement fonctionnels, mais aussi robustes, prévisibles et résilients face à la nature imprévisible du temps.
Quand vous visualisez le temps, vous en prenez le contrôle. Ce contrôle se traduit directement en fiabilité. À mesure que les systèmes deviennent plus distribués et complexes, la capacité à modéliser les relations temporelles devient un avantage concurrentiel. Elle distingue les systèmes qui fonctionnent simplement de ceux qui fonctionnent de manière cohérente sous pression.