











Dans le paysage complexe du génie logiciel, la clarté est une monnaie. Les architectes et les rédacteurs techniques doivent souvent relever le défi de transmettre le déplacement des données à travers un système sans submerger les parties prenantes avec du code ou des fichiers de configuration. C’est là que le diagramme de flux de données (DFD) devient un atout indispensable. Intégrer les DFD dans la documentation d’architecture comble le fossé entre la logique abstraite et la mise en œuvre concrète, offrant un langage visuel que les développeurs, les gestionnaires de produits et les auditeurs peuvent tous comprendre.
Ce guide explore les mécanismes d’intégration des diagrammes de flux de données dans vos documents d’architecture. Il aborde les concepts fondamentaux, le processus d’intégration, les stratégies de maintenance et les bonnes pratiques pour garantir que votre documentation reste une source fiable de vérité. En suivant ces méthodes, vous créez un document vivant qui soutient l’évolution du système plutôt que de devenir un vestige figé.
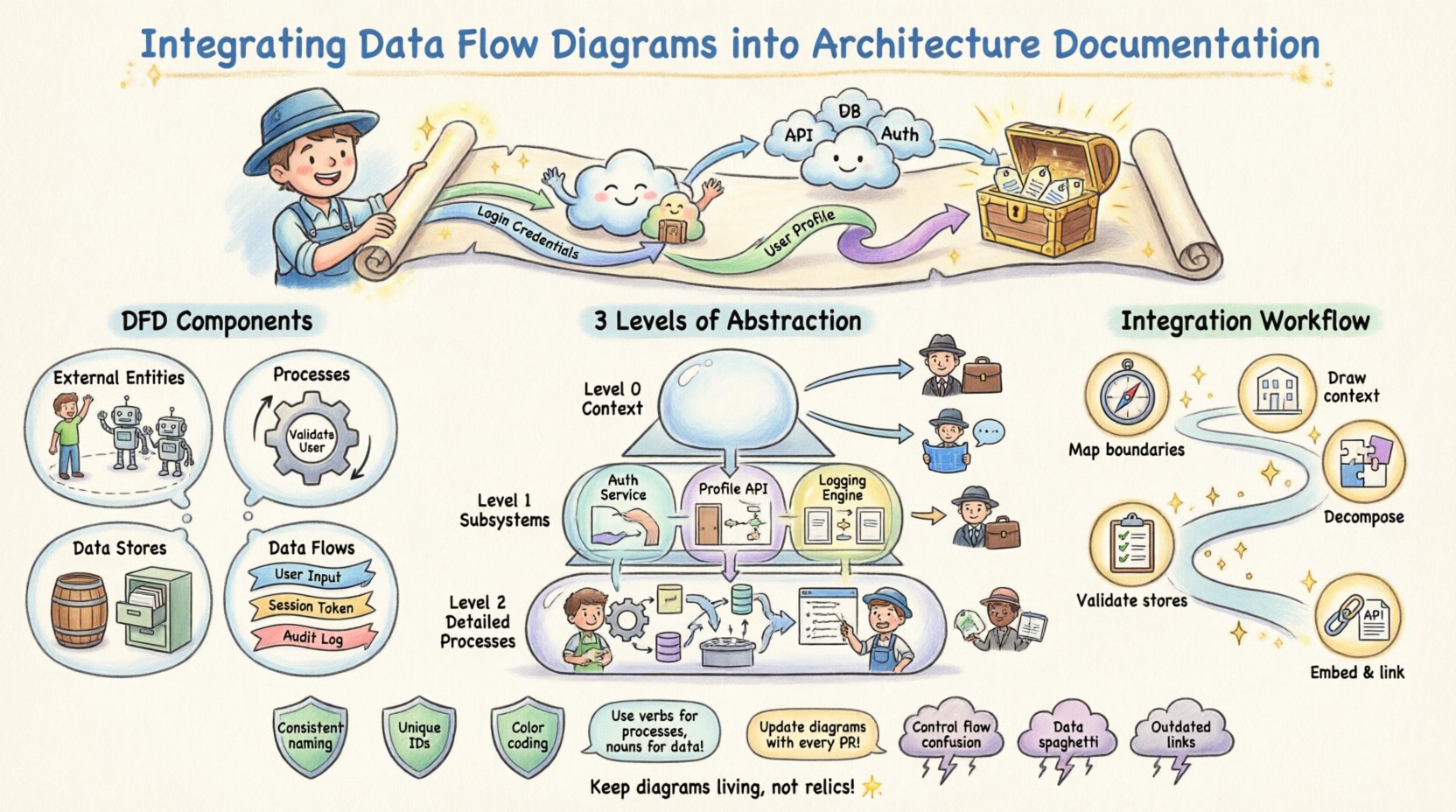
🤔 Comprendre les diagrammes de flux de données dans la conception de systèmes
Un diagramme de flux de données représente le déplacement de l’information à travers un système. Contrairement aux organigrammes, qui mettent l’accent sur le flux de contrôle et la logique décisionnelle, les DFD se concentrent strictement sur le mouvement des données. Ils illustrent l’origine des données, leur transformation, leur emplacement de stockage et leur sortie finale. Cette distinction est essentielle pour la documentation d’architecture, car elle isole le squelette informationnel de l’application de la logique procédurale qui la met en œuvre.
Lorsque vous incluez des DFD dans votre paquet d’architecture, vous fournissez une carte de la charge cognitive du système. Les parties prenantes peuvent suivre une donnée depuis son ingestion jusqu’à son stockage et sa récupération sans avoir à comprendre la logique du code sous-jacent. Cette abstraction est essentielle pour la prise de décision de haut niveau et les audits de conformité.
- Entités externes : Représentent les utilisateurs, les systèmes ou les organisations qui interagissent avec le système mais qui existent en dehors de sa frontière.
- Traitements : Transformations ou calculs effectués sur les données. Ce ne sont pas des fonctions de code, mais des opérations logiques.
- Stockages de données : Référentiels où les données sont stockées, tels que des bases de données, des systèmes de fichiers ou des journaux.
- Flux de données : Le déplacement des données entre les entités, les traitements et les stockages, généralement étiqueté avec le nom des données transférées.
En définissant clairement ces composants, vous établissez un vocabulaire cohérent. Cela réduit l’ambiguïté lorsqu’les ingénieurs discutent du comportement du système, en garantissant que « les données du profil utilisateur » font référence à la même entité à la fois dans le backend, le frontend et la documentation.
📈 Pourquoi les DFD sont essentiels pour la documentation d’architecture
Intégrer des DFD ne consiste pas seulement à dessiner des images ; c’est améliorer la fonctionnalité de la documentation elle-même. Un DFD bien structuré apporte une valeur précise à la documentation d’architecture dans plusieurs domaines clés.
🔍 Communication améliorée
Les modèles visuels réduisent la charge cognitive nécessaire pour comprendre les interactions du système. Les descriptions textuelles échouent souvent à capturer la nature bidirectionnelle des échanges de données. Un schéma montre instantanément la directionnalité. Lorsqu’un nouveau développeur rejoint un projet, il peut consulter le DFD pour comprendre la topologie des données au niveau élevé avant de plonger dans le dépôt.
🛡️ Sécurité et audit de conformité
Dans les secteurs réglementés, le traçage de la traçabilité des données est une exigence. Les DFD montrent explicitement où les données sensibles sont stockées et comment elles circulent entre les processus. Cela facilite l’identification des vulnérabilités potentielles, telles que les transferts de données non chiffrées ou les points d’accès non autorisés aux stockages de données.
🔄 Intégration du système
Le temps d’intégration est réduit lorsque des outils visuels sont disponibles. Au lieu de lire des centaines de pages de spécifications d’API, un nouveau membre de l’équipe peut comprendre le flux du système en moins d’une heure. Cela accélère le temps de productivité des ressources techniques.
📂 Niveaux d’abstraction : Contexte, Niveau 0 et Niveau 1
Une documentation d’architecture efficace ne repose pas sur un seul schéma. Elle utilise au contraire une hiérarchie de DFD pour fournir le bon niveau de détail selon les publics ciblés. Cette approche en couches évite le surchargement d’informations tout en maintenant la granularité nécessaire.
| Niveau du schéma | Objectif | Public cible | Cas d’utilisation |
|---|---|---|---|
| Diagramme de contexte (Niveau 0) | Système sous la forme d’un seul processus interagissant avec des entités externes. | Parties prenantes exécutives, gestionnaires de produit | Définition du périmètre de haut niveau et identification des limites. |
| Diagramme de niveau 1 | Sous-systèmes majeurs et magasins de données principaux. | Architectes système, développeurs principaux | Compréhension des blocs fonctionnels majeurs et du stockage des données. |
| Diagramme de niveau 2 | Analyse approfondie de processus complexes spécifiques. | Ingénieurs backend, spécialistes QA | Détails d’implémentation et transformations spécifiques des données. |
Lors de l’intégration de ces éléments dans votre documentation, assurez-vous que chaque niveau soit clairement étiqueté. Ne mélangez pas les détails fins dans un aperçu de haut niveau. Le diagramme de contexte ne doit jamais montrer de processus internes, uniquement la frontière du système. Cette discipline préserve l’intégrité de l’abstraction.
🔄 Flux de travail d’intégration étape par étape
Intégrer les DFD n’est pas une action ponctuelle. C’est un flux de travail qui évolue parallèlement au cycle de développement. Ci-dessous se trouve une approche structurée pour intégrer efficacement ces diagrammes.
1. Identifier les limites des données
Avant de dessiner, définissez le périmètre. Qu’est-ce qui est inclus dans le système ? Qu’est-ce qui est externe ? Listez toutes les entités externes (utilisateurs, API tierces) et les magasins de données internes. Cette liste devient l’inventaire de votre diagramme.
2. Cartographier les flux de haut niveau
Créez d’abord le diagramme de contexte. Dessinez le système sous forme de cercle ou de boîte centrale. Connectez toutes les entités externes à ce centre à l’aide de flèches. Étiquetez chaque flèche avec le chargement de données spécifique échangé (par exemple, « Identifiants de connexion », « Données de facture », « Mise à jour du profil utilisateur »).
3. Décomposer les processus
Prenez le processus central du diagramme de contexte et divisez-le en sous-processus. Cela devient le diagramme de niveau 1. Assurez-vous que chaque flux de données du niveau supérieur est pris en compte au niveau inférieur. Ne présentez pas de nouvelles entités externes à ce stade, sauf si elles ont été omises précédemment.
4. Valider les magasins de données
Revoyez chaque magasin de données. Est-il en lecture seule ? En écriture seule ? Les données persistent-elles ? Documentez ces attributs aux côtés du diagramme dans vos notes d’architecture. Cela évite les hypothèses sur la durée de vie des données.
5. Intégrer et lier
Placez les diagrammes dans le dépôt de documentation. Utilisez des hyperliens pour relier le diagramme aux spécifications API pertinentes ou aux schémas de base de données. Si un processus change, mettez à jour le diagramme et la documentation liée simultanément.
🛡️ Meilleures pratiques pour la clarté et la cohérence
Pour garantir que les DFD restent utiles dans le temps, une adhésion stricte aux notations et aux normes de nommage est requise. Les incohérences entraînent de la confusion, ce qui contredit l’objectif du diagramme.
- Conventions de nommage cohérentes :Utilisez un format standard pour les étiquettes. Par exemple, utilisez toujours des verbes pour les processus (par exemple, « Valider l’utilisateur ») et des noms pour les flux de données (par exemple, « Entrée utilisateur »). Ne mélangez jamais les styles verbe et nom dans le même diagramme.
- Identification unique des processus :Numérotez vos processus de manière séquentielle. Cela facilite la référence à des transformations spécifiques lors des revues de code (par exemple, « Examiner le processus 3.1 »).
- Minimiser les croisements : Essayez d’organiser les éléments pour minimiser les croisements de lignes. Si des lignes doivent se croiser, utilisez une notation de pont pour indiquer qu’elles ne sont pas connectées. Cela améliore considérablement la lisibilité.
- Regroupement logique : Regroupez visuellement les processus liés. Si trois processus traitent les paiements, placez-les dans un groupe. Cela aide le lecteur à comprendre rapidement les domaines fonctionnels.
- Codage par couleur : Utilisez des variations subtiles de couleur pour distinguer les différents types de données ou niveaux de sécurité. Par exemple, des bordures rouges pour les flux de données sensibles et des vertes pour les données publiques.
La documentation ne doit jamais supposer que le lecteur possède des connaissances préalables. Chaque flèche, boîte et étiquette doit être auto-explicative ou liée à un glossaire inclus dans la documentation.
🧹 Stratégies de maintenance et de gestion de version
Un diagramme qui ne correspond pas au code est pire qu’aucun diagramme. Il crée un faux sentiment de sécurité et induit en erreur les ingénieurs. Par conséquent, la maintenance est la phase la plus critique de l’intégration des DFD.
📝 Gestion des versions
Incluez les numéros de version dans le pied de page de chaque diagramme. Liez la version du diagramme à la version de publication du logiciel. Si une fonctionnalité est obsolète, archivez le diagramme ancien plutôt que de le supprimer. Cela préserve l’historique des modifications des flux de données pour un débogage futur.
🔄 Gestion des changements
Intégrez les mises à jour des DFD dans le flux de travail des demandes de fusion. Lorsqu’un développeur modifie un magasin de données ou ajoute un nouveau point d’entrée API, il doit mettre à jour le DFD correspondant. Cela garantit que la documentation fait partie de la définition du « terminé ».
📅 Audits réguliers
Programmez des revues trimestrielles de la documentation d’architecture. Un architecte désigné doit passer en revue les diagrammes avec le codebase actuel. Si des incohérences sont détectées, elles doivent être enregistrées et corrigées immédiatement.
⚠️ Pièges courants et comment les éviter
Même les architectes expérimentés commettent des erreurs lors de la modélisation des flux de données. Reconnaître ces pièges tôt peut éviter des semaines de restructuration et de confusion.
| Piège | Conséquence | Stratégie d’atténuation |
|---|---|---|
| Confusion entre flux de contrôle et flux de données | Le diagramme suggère une logique là où il n’y a que des données. | Assurez-vous que les flèches représentent des données, et non des chemins d’exécution. Utilisez des diagrammes de flux de contrôle pour la logique. |
| Spaghetti de données | Trop de lignes qui se croisent, rendant le diagramme illisible. | Utilisez des sous-processus pour décomposer la complexité. Regroupez les flux liés. |
| Magasins de données manquants | Supposition que les données persistent sans stockage explicite. | Définissez explicitement chaque magasin de données. Ne supposez pas que les tampons en mémoire sont considérés comme un stockage. |
| Références obsolètes | Liens vers des processus qui n’existent plus. | Mettre en place un processus rigoureux de revue lors des fusion de code. |
Une autre erreur courante est le sur-découpage. Créer un diagramme de niveau 2 pour une opération CRUD simple est une perte d’espace. Décomposez un processus uniquement s’il contient une logique complexe nécessitant une clarification. Si un processus peut être compris en une seule ligne de code, gardez-le au niveau élevé.
🔗 Liaison des diagrammes de flux de données avec d’autres éléments architecturaux
Un diagramme de flux de données n’existe pas en isolation. Il interagit avec d’autres types de documentation pour former une image architecturale complète. En les intégrant, on crée un récit cohérent.
- Diagrammes de relations entre entités (ERD) : Le DFD montre comment les données circulent ; l’ERD montre comment les données sont structurées. Liez les magasins de données du DFD à leurs tables correspondantes dans l’ERD.
- Spécifications de l’API : Associez les points de terminaison de l’API aux flux de données. Si un flux est étiqueté « Envoyer une commande », la spécification de l’API doit contenir le point de terminaison responsable de cette soumission.
- Diagrammes de déploiement : Montrez quels magasins de données sont des serveurs physiques ou des conteneurs cloud. Cela aide les équipes d’infrastructure à comprendre la répartition de la charge implicite dans le flux de données.
- Politiques de sécurité : Faites correspondre les flux de données sensibles aux normes de chiffrement. Si un flux traverse une frontière réseau, indiquez le protocole de chiffrement requis.
En tissant ensemble ces éléments, vous créez un réseau de vérité. Un ingénieur lisant le DFD peut cliquer pour accéder à la spécification de l’API, puis au schéma de la base de données, et enfin à la configuration de déploiement. Cela réduit les frictions liées au changement de contexte pendant le développement.
🚀 Réflexions finales sur l’intégrité de la documentation
L’objectif de l’intégration des diagrammes de flux de données n’est pas de créer une image parfaite dès le premier jour. Il s’agit d’établir une norme pour la manière dont les données sont perçues et gérées tout au long du cycle de vie du projet. Lorsque la documentation évolue parallèlement au code, elle devient un outil vivant plutôt qu’un simple document historique.
Concentrez-vous sur la cohérence plutôt que sur la perfection. Un diagramme légèrement simplifié, toujours à jour, est plus précieux qu’un diagramme hyper-détaillé qui est devenu obsolète. En suivant les flux de travail et les normes décrits ici, vous assurez que votre documentation architecturale sert efficacement l’équipe, en réduisant les erreurs et en accélérant la livraison.