











Concevoir une architecture de microservices robuste exige plus que de simples morceaux de code divisés. Il exige une compréhension claire du déplacement de l’information à travers le système. Sans une approche structurée, les systèmes distribués deviennent souvent des tissus emmêlés de dépendances difficiles à maintenir et à faire évoluer. C’est là que le diagramme de flux de données (DFD) devient un outil essentiel pour les architectes. En visualisant le déplacement des données, les équipes peuvent définir les limites des services avec précision et garantir que la logique de données sous-jacente reste cohérente sur l’ensemble de la plateforme.
Ce guide explore la manière d’utiliser les DFD lors de la phase de planification de la mise en œuvre des microservices. Nous examinerons la hiérarchie des diagrammes, l’identification des limites critiques et les stratégies de gestion de la propriété des données. L’objectif est de fournir un cadre méthodique pour la conception du système, en privilégiant la clarté et la maintenabilité.
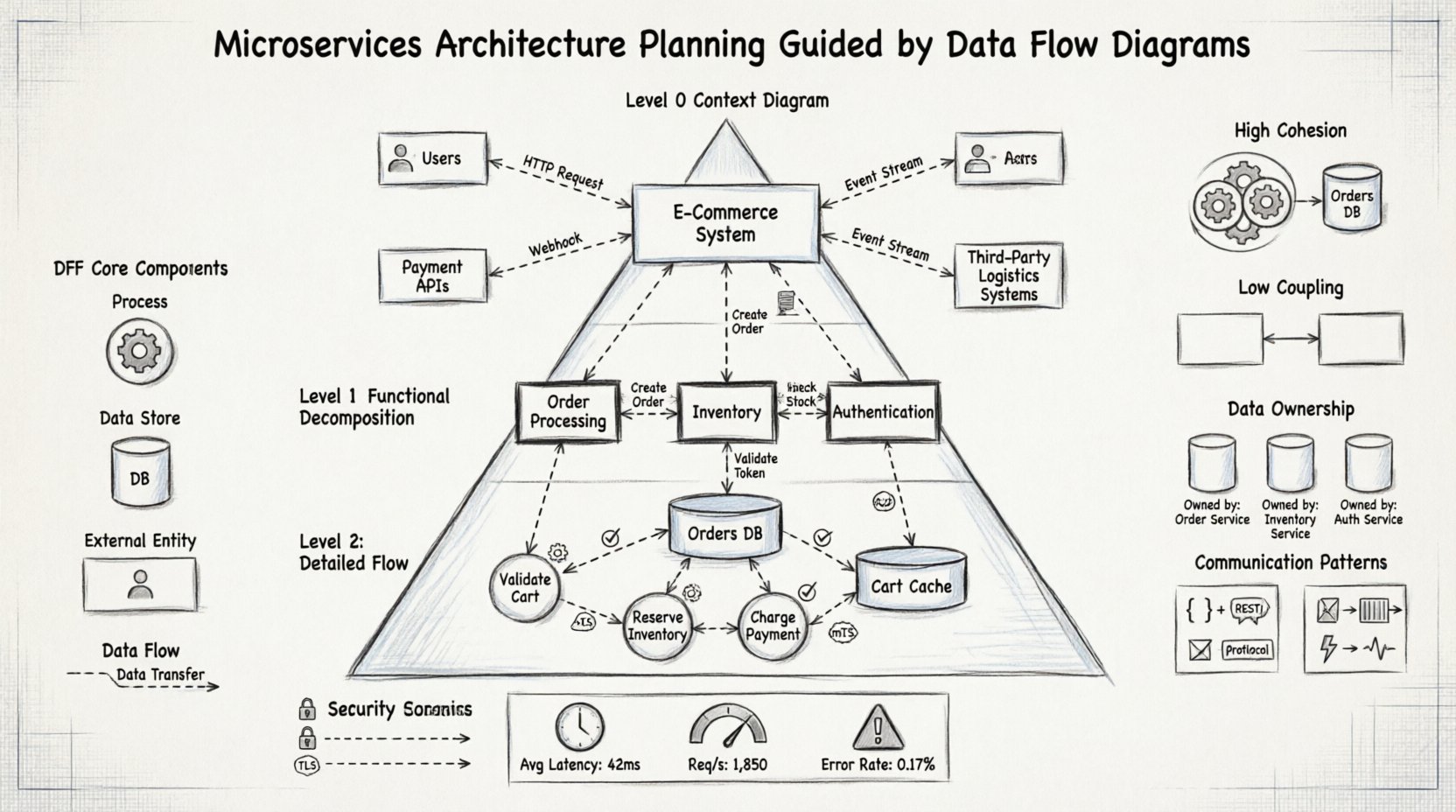
🧩 Comprendre le rôle des DFD dans les systèmes distribués
Un diagramme de flux de données représente le déplacement de l’information à travers un système. Contrairement à un organigramme, qui se concentre sur le flux de contrôle et la logique décisionnelle, un DFD met l’accent sur la transformation et le stockage des données. Dans le contexte des microservices, cette distinction est essentielle. Les microservices sont essentiellement des unités de traitement indépendantes qui échangent des données. Cartographier cet échange visuellement aide les parties prenantes à comprendre l’impact des modifications.
Composants fondamentaux d’un DFD
Avant d’appliquer les DFD à l’architecture, il faut comprendre les symboles fondamentaux utilisés :
- Processus : Représentent les transformations des données. Dans les microservices, ils correspondent souvent à des fonctions spécifiques de service ou à des API.
- Bases de données de données : Emplacements où les données sont stockées au repos. Elles correspondent aux bases de données, aux caches ou aux systèmes de fichiers.
- Entités externes : Sources ou destinations de données en dehors du système. Cela inclut les utilisateurs, les systèmes tiers ou les applications héritées.
- Flux de données : Le déplacement des données entre les processus, les bases de données et les entités. Ils représentent le trafic réseau ou les files d’attente de messages entre les services.
📊 La hiérarchie des diagrammes de planification
Un plan d’architecture complet nécessite plusieurs niveaux d’abstraction. En commençant par une vue d’ensemble de haut niveau et en descendant vers des détails spécifiques, on s’assure que aucun chemin critique de données n’est négligé. Cette approche hiérarchique s’aligne naturellement avec la conception en couches des microservices.
Niveau 0 : Le diagramme de contexte
Le diagramme de niveau 0, souvent appelé diagramme de contexte, fournit la vue la plus large. Il représente l’ensemble du système comme un seul processus et identifie toutes les entités externes interagissant avec lui. C’est la première étape de la planification, car elle définit le périmètre.
- Identifier les limites : Marquer clairement ce qui est à l’intérieur du système et ce qui est à l’extérieur.
- Interfaces externes : Listez chaque point d’entrée et de sortie des données.
- Entrées / Sorties principales : Déterminez les principaux déclencheurs de données pour le système.
Pour les microservices, ce niveau aide à répondre à la question : « Que fait le système pour l’utilisateur ? » Il prépare le terrain à la décomposition.
Niveau 1 : Décomposition fonctionnelle majeure
Une fois le contexte établi, le processus unique est décomposé en sous-processus majeurs. Dans un contexte de microservices, ces sous-processus indiquent souvent les candidats initiaux de services. Ce niveau décompose le système en domaines logiques.
- Alignement du domaine : Regrouper les processus par capacité métier (par exemple, traitement des commandes, gestion des stocks, authentification des utilisateurs).
- Candidats de service :Chaque processus majeur devient un microservice potentiel.
- Communication entre services :Identifiez les flux de données entre ces domaines majeurs.
Niveau 2 : Analyse détaillée des flux
Le dernier niveau de détail se concentre sur des fonctions spécifiques au sein d’un service. C’est là que la validation des données, la transformation et la logique de stockage sont mappées. Cela garantit que la logique interne d’un service est cohérente avant le début de la mise en œuvre.
🏗️ Mappage des flux de données aux limites des services
L’un des défis les plus critiques dans l’architecture des microservices est la définition des limites des services. Si ces limites sont mal définies, les services deviennent étroitement couplés, ce qui entraîne le pattern anti-« monolithe distribué ». Les diagrammes de flux de données aident à tracer ces limites en mettant en évidence les dépendances des données.
Identification de la cohésion
Les services doivent présenter une forte cohésion, ce qui signifie que toutes les fonctions au sein d’un service travaillent étroitement ensemble sur un ensemble de données spécifique. Les diagrammes de flux de données aident à visualiser cela en regroupant les processus qui partagent les mêmes magasins de données et flux.
- Processus regroupés :Si le processus A et le processus B échangent toujours des données directement sans déclencheurs externes, ils appartiennent probablement au même service.
- Magasins de données partagés :Les processus qui accèdent au même magasin de données doivent être évalués pour une consolidation potentielle.
Minimisation du couplage
Le couplage fait référence au degré d’interdépendance entre les services. Les diagrammes de flux de données révèlent le couplage en montrant combien de flux de données traversent la frontière proposée. L’objectif est de minimiser le nombre de flux de données qui traversent les frontières des services.
- Connexions directes :Réduisez le nombre de flux de données directs entre les services.
- Connexions indirectes :Préférez les messages asynchrones ou les architectures pilotées par événements pour découpler les services.
🗄️ Gestion de la propriété des données et de la cohérence
Dans une base de données monolithique, la cohérence des données est gérée via des transactions. Dans les microservices, chaque service possède généralement ses propres données. Les diagrammes de flux de données sont essentiels pour clarifier la propriété. En cartographiant les flux de données vers les magasins, les architectes peuvent attribuer la propriété à des processus spécifiques.
Le modèle Base de données par service
Chaque microservice doit gérer son propre magasin de données. Les diagrammes de flux de données aident à identifier quelles données appartiennent à quel service en suivant l’origine des données et leur consommation.
- Source de vérité :Le processus qui écrit les données détient le magasin de données.
- Accès en lecture :D’autres processus peuvent lire les données via des flux définis (APIs), mais ne peuvent pas les modifier directement.
Modèles de cohérence
Les systèmes distribués reposent souvent sur la cohérence éventuelle plutôt que sur la cohérence immédiate. Les diagrammes de flux de données mettent en évidence où la cohérence est critique par rapport à où elle peut être assouplie.
- Consistance forte : Nécessaire pour les transactions financières ou les mises à jour de stock. Ces flux sont marqués comme synchrones.
- Consistance éventuelle : Acceptable pour les profils utilisateurs ou la journalisation. Ces flux sont souvent asynchrones.
🔗 Modèles de communication et intégration
Une fois les services définis, l’architecture doit définir comment ils communiquent entre eux. Les diagrammes de flux de données (DFD) distinguent différents types de flux de données, ce qui influence le choix de la technologie de communication.
Demande-Réponse vs. Piloté par événements
Tous les flux de données n’exigent pas de réponse immédiate. Les DFD aident à catégoriser les flux en fonction de leurs exigences de temporisation.
- Flux synchrones : Utilisés lorsque le processus en aval a besoin des données immédiatement pour poursuivre. Ils correspondent généralement aux API REST ou gRPC.
- Flux asynchrones : Utilisés pour le traitement en arrière-plan ou les notifications. Ils correspondent aux files de messages ou aux bus d’événements.
⚠️ Pièges courants dans la planification basée sur les DFD
Bien que les DFD soient puissants, ils sont sujets à des malentendus s’ils ne sont pas utilisés correctement. Les architectes doivent être conscients des erreurs courantes qui peuvent compromettre le processus de planification.
Piège 1 : Contexte trop détaillé
Commencer avec trop de détails au niveau du contexte peut masquer la vue d’ensemble. Gardez le niveau 0 simple. Ajoutez de la complexité uniquement en passant au niveau 1 et 2.
Piège 2 : Ignorer les exigences non fonctionnelles
Les DFD se concentrent sur les données, pas sur les performances ou la sécurité. Lors de la cartographie des flux, prenez en compte les exigences de latence et les frontières de sécurité. Un flux de données pourrait être techniquement possible mais violer des politiques de sécurité.
Piège 3 : Dépendances circulaires
Les DFD peuvent révéler des flux de données circulaires où le Service A appelle le Service B, qui appelle à son tour le Service A. Cela crée un blocage ou une boucle infinie. Ces boucles doivent être rompues en réorganisant la propriété des données.
📋 Analyse comparative des niveaux de DFD
Pour mieux comprendre comment les niveaux de DFD correspondent aux décisions architecturales, reportez-vous au tableau ci-dessous.
| Niveau DFD | Domaine d’attention | Résultat architectural |
|---|---|---|
| Contexte (niveau 0) | Portée du système | Définition des limites du service |
| Fonctionnel (niveau 1) | Grands domaines | Catalogue de services et contrats API |
| Logique (niveau 2) | Logique interne | Modèles de données et règles de validation |
| Physique | Infrastructure | Topologie de déploiement et configuration réseau |
🔄 Affinement itératif et maintenance
L’architecture n’est pas un événement ponctuel. Au fur et à mesure que l’entreprise évolue, les flux de données changent. Les diagrammes de flux de données (DFD) servent de documentation vivante qui doit être mise à jour parallèlement au code source.
Versionnement des diagrammes
Tout comme les API sont versionnées, les DFD doivent l’être pour suivre les évolutions architecturales au fil du temps. Cela aide les équipes à comprendre pourquoi certaines décisions ont été prises par le passé.
- Journaux de modifications : Documentez chaque modification apportée à un flux de données ou à un processus.
- Analyse d’impact : Utilisez le diagramme pour évaluer l’impact d’un changement dans un service sur les autres.
Validation automatisée
Bien que les diagrammes manuels soient utiles, la validation automatisée peut garantir que l’implémentation correspond au design. Les outils peuvent vérifier que le trafic réseau réel correspond aux flux définis dans le DFD.
🛡️ Considérations de sécurité dans les flux de données
La sécurité est souvent une préoccupation tardive dans la conception, mais les DFD permettent de l’intégrer dès le départ. Chaque flux de données représente un vecteur d’attaque potentiel.
Définition des zones de confiance
Marquez les zones du diagramme qui nécessitent des niveaux de sécurité différents. Les flux internes pourraient être considérés comme fiables, tandis que les flux externes exigent chiffrement et authentification.
- Flux externes : Exigent TLS, clés API ou jetons OAuth.
- Flux internes : Exigent TLS mutuel ou authentification service à service.
Classification des données
Étiquetez les flux de données selon leur sensibilité. Les données sensibles (PII, financières) nécessitent des contrôles plus stricts que les données publiques.
- Haute sensibilité : Chiffrez les données au repos et en transit.
- Basse sensibilité :Les protocoles de chiffrement standards sont suffisants.
📈 Mesurer le succès avec les diagrammes de flux de données
Comment savoir si l’architecture fonctionne ? Les diagrammes de flux de données fournissent une base de mesure. En comparant le déplacement réel des données au diagramme prévu, les équipes peuvent identifier les goulets d’étranglement.
Indicateurs de performance
- Latence :Mesurer le temps nécessaire au déplacement des données à travers un flux.
- Débit :Mesurer le volume de données échangées entre les processus.
- Taux d’erreurs :Identifier les flux qui échouent fréquemment.
Opportunités d’optimisation
Les diagrammes de flux de données mettent en évidence les chemins redondants. Si deux services échangent régulièrement les mêmes données, une couche de mise en cache ou un modèle de lecture partagé pourrait être introduite pour optimiser les performances.
🚀 Conclusion sur la planification stratégique
Utiliser les diagrammes de flux de données pour la planification des microservices déplace l’attention du code vers l’information. Cela garantit que l’architecture soutient la logique métier plutôt que l’inverse. En suivant une approche structurée des diagrammes de flux de données, les équipes peuvent concevoir des systèmes modulaires, maintenables et évolutifs.
Le processus exige de la discipline. Il impose aux architectes de résister à la tentation de sur-optimiser prématurément et de se concentrer plutôt sur des frontières claires et une propriété des données. Lorsque le diagramme de flux de données est précis, l’implémentation s’en suit naturellement. Cette méthode réduit la dette technique et établit une base pour une croissance à long terme.
Souvenez-vous que le diagramme est un outil de communication tout autant que de conception. Il comble le fossé entre les équipes techniques et les parties prenantes métiers. Lorsque tout le monde comprend comment les données circulent, toute l’organisation peut prendre de meilleures décisions concernant les capacités et les limites du système.