











जटिल सूचना प्रणालियों की वास्तुकला में, डेटा की अखंडता विश्वसनीयता के आधार के रूप में है। जब डेटा प्रक्रियाओं, बाहरी एकाधिकारियों और स्टोरेज स्थानों के बीच आता-जाता है, तो असंगतताएं चुपचाप उत्पन्न हो सकती हैं, जिससे महत्वपूर्ण विफलताएं, रिपोर्टिंग त्रुटियां और सुरक्षा की कमजोरी हो सकती है। डेटा फ्लो डायग्राम (DFD) एक प्रणाली में जानकारी के यात्रा के तरीके को समझने के लिए एक दृश्य नक्शा के रूप में कार्य करते हैं। हालांकि, एक डायग्राम केवल उतना ही अच्छा है जितनी वह अपने द्वारा बल देता है। इस गाइड में विस्तृत DFD विश्लेषण के माध्यम से डेटा सुसंगतता की जांच की कठोर प्रक्रिया का अध्ययन किया गया है, ताकि प्रणाली में प्रवेश करने, प्रसंस्करण करने और बाहर निकलने वाले हर बाइट की सटीकता और विश्वसनीयता सुनिश्चित की जा सके।
डेटा सुसंगतता केवल तकनीकी चेकबॉक्स नहीं है; यह एक संरचनात्मक आवश्यकता है। इसमें प्रणाली डिजाइन के सभी स्तरों पर डेटा परिभाषाओं, परिवर्तनों और स्टोरेज तंत्रों के पूर्ण रूप से अनुकूलन को सुनिश्चित करना शामिल है। इस अनुकूलन के बिना, प्रक्रियाएं पुरानी या गलत जानकारी पर काम कर सकती हैं। डेटा के प्रवाह के विश्लेषण के माध्यम से, वास्तुकार और विश्लेषक एक भी कोड लाइन लिखे बिना असंगतियों की पहचान कर सकते हैं। इस प्रक्रिया के लिए प्रणाली के गतिशीलता, तार्किक संरचना और विभिन्न घटकों के बीच संबंधों की गहन समझ की आवश्यकता होती है।
🛡️ प्रणाली डिजाइन में डेटा सुसंगतता को समझना
पुष्टि के यांत्रिकी में डूबने से पहले, प्रणाली डिजाइन के संदर्भ में डेटा सुसंगतता का अर्थ परिभाषित करना आवश्यक है। यह “सही” या “गलत” की द्विआधारी स्थिति नहीं है। बल्कि, एक ही जानकारी के विभिन्न प्रतिनिधित्वों के बीच संरेखण का एक स्पेक्ट्रम है।
📊 मूल स्तंभों को परिभाषित करना
प्रणाली डिजाइन में सुसंगतता सामान्यतः तीन प्रमुख श्रेणियों में आती है:
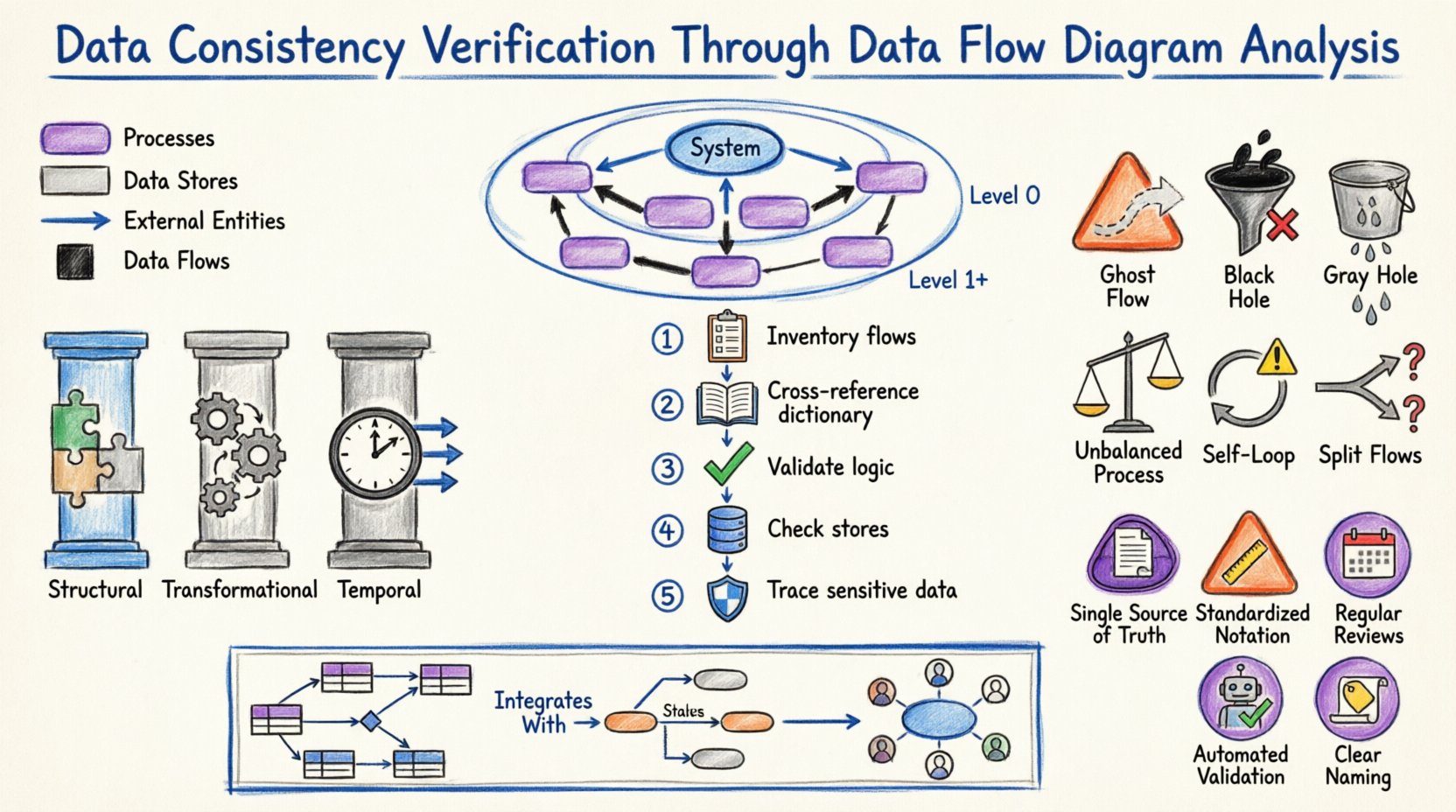
- संरचनात्मक सुसंगतता: इसका तात्पर्य डेटा संरचनाओं के अनुकूलन से है। यदि कोई प्रक्रिया “ग्राहक आईडी” को एक पूर्णांक के रूप में अपेक्षा करती है, तो उस आईडी को प्रदान करने वाला डेटा स्टोर एक स्ट्रिंग नहीं लौटाना चाहिए।
- परिवर्तनात्मक सुसंगतता: इसका तात्पर्य यह सुनिश्चित करना है कि प्रसंस्करण के दौरान डेटा पर लागू तर्क समान रहे। प्रक्रिया A में की गई गणना का परिणाम प्रक्रिया B में समान गणना के परिणाम के समान होना चाहिए, यदि इनपुट समान हों।
- कालात्मक सुसंगतता: इसका तात्पर्य डेटा अद्यतन के समय के संबंध में है। जानकारी को जब भी आवश्यकता हो, उपलब्ध होना चाहिए, और अद्यतनों को प्रणाली में बिना रेस कंडीशन या पुराने पढ़ने के कारण फैलने देना चाहिए।
DFD इन स्तंभों को निर्देशित करने के लिए नक्शा प्रदान करते हैं। डेटा के मार्गों का अनुसरण करके, विश्लेषक उन स्थानों को देख सकते हैं जहां इन स्तंभों में दरार आ सकती है। उदाहरण के लिए, यदि कोई डेटा प्रवाह किसी प्रक्रिया में प्रवेश करता है लेकिन संबंधित आउटपुट प्रवाह नहीं है, तो डेटा गायब हो गया है, जो संरचनात्मक या तार्किक त्रुटि का संकेत है।
🔄 DFD की अखंडता सुनिश्चित करने में भूमिका
डेटा फ्लो डायग्राम केवल चित्र नहीं हैं; वे सूचना गति के औपचारिक विवरण हैं। पुष्टि के संदर्भ में, DFD आवश्यकताओं और कार्यान्वयन के बीच एक संविदा के रूप में कार्य करता है। यह निर्धारित करता है कि डेटा कहां से आता है, कहां जाता है, और यह कैसे बदलता है।
🔎 मुख्य घटक और उनका प्रभाव
सुसंगतता की पुष्टि करने के लिए, प्रत्येक घटक की विशिष्ट भूमिका को समझना आवश्यक है:
- बाहरी एकाधिकारियां: ये प्रणाली सीमा के बाहर डेटा के स्रोत और गंतव्य हैं। यहां पुष्टि में यह सुनिश्चित करना शामिल है कि प्रणाली उपयोगकर्ताओं, अन्य प्रणालियों या हार्डवेयर उपकरणों से आने वाले इनपुट को सही तरीके से व्याख्या करती है।
- प्रक्रियाएं: ये इनपुट डेटा को आउटपुट डेटा में बदलती हैं। यहां सुसंगतता जांच में तर्क और डेटा शब्दकोश परिभाषाओं पर ध्यान केंद्रित करती है। क्या प्रक्रिया वास्तव में वर्णनानुसार डेटा को परिवर्तित करती है?
- डेटा स्टोर: ये वे भंडार हैं जहां डेटा विश्राम करता है। सुसंगतता में यह सुनिश्चित करना शामिल है कि स्कीमा स्टोर में प्रवेश और निकास के प्रवाहों के अनुरूप हो। क्या डेटा एक भंडार में लिखा जा रहा है जो अलग प्रारूप की अपेक्षा करता है?
- डेटा प्रवाह: ये डेटा ले जाने वाले पाइप हैं। प्रत्येक प्रवाह का परिभाषित स्रोत और गंतव्य होना चाहिए। पहचान नहीं वाले प्रवाह सुसंगतता के प्रमुख स्रोत हैं।
📉 DFD के स्तर और सुसंगतता जांच
DFD आमतौर पर पदानुक्रमित होते हैं। उच्च स्तर के सामान्यीकरण से विस्तृत विशिष्टताओं तक जाने से बहु-स्तरीय पुष्टि संभव होती है। प्रत्येक स्तर के लिए अलग प्रकार की सुसंगतता जांच की आवश्यकता होती है।
🏁 संदर्भ स्तर (स्तर 0)
संदर्भ आरेख पूरी प्रणाली को एकल प्रक्रिया के रूप में दर्शाता है। यह बाहरी एकाधिकारियों के साथ बातचीत दिखाता है। इस स्तर पर पुष्टि का ध्यान “सीमा. क्या सभी बाहरी एकाधिकारों को ध्यान में रखा गया है? क्या सभी मुख्य डेटा इनपुट और आउटपुट सीमा को पार करते हैं?
संदर्भ स्तर के लिए चेकलिस्ट:
- क्या सिस्टम का प्रतिनिधित्व करने वाली एक ही प्रक्रिया है?
- क्या सभी बाहरी एकाधिकार सही तरीके से लेबल किए गए हैं?
- क्या सीमा को पार करने वाले सभी डेटा प्रवाहों को स्पष्ट परिभाषा है?
🏗️ स्तर 0 (शीर्ष स्तर का विभाजन)
इस चरण में, एकल प्रक्रिया को मुख्य उप-प्रक्रियाओं में बांटा जाता है। यहां संतुलन महत्वपूर्ण हो जाता है। उप-प्रक्रियाओं के इनपुट और आउटपुट का योग मूल संदर्भ प्रक्रिया के इनपुट और आउटपुट के बराबर होना चाहिए।
यदि संदर्भ आरेख में “आदेश अनुरोध” के इनपुट को दिखाया गया है, तो स्तर 0 आरेख में “आदेश अनुरोध” को कम से कम एक शीर्ष स्तरीय प्रक्रिया में प्रवेश करते हुए दिखाना होगा। यदि यह डेटा गायब हो जाता है, तो यह एक काला छेद—एक महत्वपूर्ण सुसंगतता त्रुटि है।
🧩 स्तर 1 और नीचे (विस्तृत विभाजन)
जैसे आरेख और अधिक विभाजित होते हैं, ध्यान केंद्रित होता है तार्किक प्रवाह. क्या डेटा प्रवाह प्रक्रियाओं के विस्तार के अनुरूप हैं? क्या प्रक्रियाओं के बीच डेटा ऐसे आदान-प्रदान किया जा रहा है जिसे पहले संग्रहीत करना चाहिए? क्या मॉड्यूल के बीच अनावश्यक जुड़ाव है?
📝 चरण-दर-चरण सत्यापन प्रोटोकॉल
सुसंगतता की जांच एक व्यवस्थित गतिविधि है। यह सुनिश्चित करने के लिए एक व्यवस्थित दृष्टिकोण की आवश्यकता होती है कि कोई विवरण न छूटे। निम्नलिखित प्रोटोकॉल विश्लेषण के लिए मानक प्रक्रिया को चित्रित करता है।
1️⃣ सभी प्रवाहों का निरीक्षण करें
आरेख में मौजूद प्रत्येक डेटा प्रवाह को सूचीबद्ध करके शुरुआत करें। एक मास्टर सूची बनाएं जिसमें प्रवाह का नाम, स्रोत और गंतव्य शामिल हो। इस निरीक्षण को सभी बाद की जांचों के आधार के रूप में उपयोग किया जाता है।
2️⃣ डेटा शब्दकोश के साथ तुलना करें
एक डेटा शब्दकोश प्रत्येक डेटा तत्व की संरचना, प्रकार और सीमाओं को परिभाषित करता है। DFD में प्रत्येक डेटा प्रवाह के लिए शब्दकोश में संबंधित प्रविष्टि होनी चाहिए।
- नाम मेल खाएं: सुनिश्चित करें कि आरेख में प्रवाह का नाम शब्दकोश के शब्द से बिल्कुल मेल खाता हो।
- प्रकार मेल खाएं: सुनिश्चित करें कि डेटा प्रकार (उदाहरण के लिए, स्ट्रिंग, पूर्णांक, तारीख) आरेख और शब्दकोश में संगत है।
- सीमाएं मेल खाएं: जांचें कि सत्यापन नियम (उदाहरण के लिए, “धनात्मक होना चाहिए”) संगत रूप से लागू किए गए हैं।
3️⃣ प्रक्रिया तर्क की पुष्टि करें
प्रत्येक प्रक्रिया नोड के लिए, परिवर्तन तर्क की जांच करें। क्या प्रक्रिया इनपुट्स के दिए गए अपेक्षित आउटपुट्स को उत्पन्न करती है? क्या कोई आउटपुट है जो तार्किक कारण के बिना दिखाई देता है? इस चरण में आमतौर पर प्रक्रिया से जुड़े प्रतिकृति कोड या व्यापार नियमों की समीक्षा करने की आवश्यकता होती है।
4️⃣ डेटा स्टोर संरेखण की जांच करें
किसी डेटा स्टोर में प्रवेश करने वाला प्रत्येक डेटा प्रवाह उस स्टोर के स्कीमा से मेल खाना चाहिए। विपरीत रूप से, किसी स्टोर से निकलने वाला प्रत्येक प्रवाह उसमें वास्तव में मौजूद डेटा का प्रतिनिधित्व करना चाहिए। सुनिश्चित करें कि पढ़ने और लिखने के ऑपरेशन संतुलित हैं।
5️⃣ संवेदनशील डेटा के मार्ग का अनुसरण करें
संवेदनशील जानकारी (PII, वित्तीय डेटा) वाले प्रवाहों को पहचानें। सुनिश्चित करें कि सुसंगतता जांच में सुरक्षा प्रोटोकॉल शामिल हैं। यदि डेटा स्रोत पर सीधे एन्क्रिप्ट किया गया है, तो क्या इसे गंतव्य पर डिक्रिप्ट किया जाता है? क्या कोई अनएन्क्रिप्टेड प्रवाह है जिसे सुरक्षित होना चाहिए?
⚠️ सामान्य असंगतियाँ और पैटर्न
सावधानी से योजना बनाने के बावजूद, असंगतियाँ धीरे-धीरे घुस जाती हैं। त्रुटि के सामान्य पैटर्न को पहचानने से विश्लेषण के दौरान तेजी से पता लगाने में मदद मिलती है। नीचे दी गई तालिका में आम समस्याओं और उनके प्रभावों का वर्णन किया गया है।
| पैटर्न का नाम | विवरण | सुसंगतता प्रभाव |
|---|---|---|
| गॉस्ट प्रवाह | कोई स्रोत या गंतव्य नहीं वाला डेटा प्रवाह। | डेटा की निरंतरता को तोड़ता है; सिस्टम त्रुटियों का कारण बनता है। |
| ब्लैक होल | इनपुट्स वाली लेकिन कोई आउटपुट नहीं वाली प्रक्रिया। | डेटा खो जाता है; सिस्टम की स्थिति अपरिभाषित हो जाती है। |
| ग्रे होल | एक प्रक्रिया जहां आउटपुट इनपुट्स के योग से कम है, या तर्क सभी इनपुट्स को ध्यान में नहीं रखता है। | आंशिक डेटा हानि या गलत समावेश। |
| असंतुलित प्रक्रिया | एक बच्चा प्रक्रिया उस माता पिता प्रक्रिया से अलग इनपुट/आउटपुट वाली होती है जिसे वह विभाजित करती है। | हायरार्की को तोड़ता है; आवश्यकताएं पूरी नहीं होती हैं। |
| सेल्फ-लूपिंग डेटा | एक डेटा प्रवाह जो किसी डेटा स्टोर के बिना उसी प्रक्रिया में वापस आता है। | अनंत लूप या राज्य प्रबंधन की कमी का संकेत देता है। |
| स्प्लिट प्रवाह | डेटा बिना निर्णय नोड के कई मार्गों में विभाजित हो जाता है। | अस्पष्ट रूटिंग; संभावित डेटा दोहराव। |
🔗 डेटा डिक्शनरी एकीकरण
डेटा डिक्शनरी डेटा परिभाषाओं के लिए एकमात्र सच्चाई का स्रोत है। डिक्शनरी के बिना, DFDs अस्पष्ट होते हैं। इस भंडार के बीच आरेख के तुलना के बिना सत्यापन अधूरा है।
📋 समन्वय आवश्यकता
जब कोई DFD अद्यतन किया जाता है, तो डेटा शब्दकोश को एक साथ अद्यतन करना आवश्यक है। यहाँ असंगति एक रूप है। उदाहरण के लिए, यदि शब्दकोश में किसी फ़ील्ड का नाम “User_Name” से “Username” कर दिया जाता है, तो DFD में इस परिवर्तन को तुरंत प्रतिबिंबित करना चाहिए। ऐसा न करने से डिज़ाइन दस्तावेज़ और कार्यान्वयन विवरण के बीच असंगति उत्पन्न होती है।
📌 मेटाडेटा संगतता
नामों और प्रकारों के अलावा, मेटाडेटा की संगतता होनी चाहिए। इसमें शामिल है:
- माप के इकाइयाँ: करेंसी USD या EUR में है? वजन kg या lbs में है? इसे उस डेटा के सभी प्रवाहों में संगत रहना चाहिए।
- एन्कोडिंग मानकों: क्या टेक्स्ट UTF-8 या ASCII में एन्कोड किया गया है? असंगत एन्कोडिंग डेटा को क्षति पहुँचाती है।
- समय क्षेत्र: क्या प्रणाली समय को UTC या स्थानीय समय में संग्रहीत करती है? टाइमस्टैम्प्स वाले प्रवाहों को मानक पर सहमति होनी चाहिए।
🧭 तार्किक बनाम भौतिक संगतता
एक सामान्य गलती तार्किक और भौतिक डिज़ाइन को मिलाना है। एक तार्किक DFD दिखाता हैक्या प्रणाली क्या करती है, जबकि एक भौतिक DFD दिखाता हैकैसे यह कैसे करती है। संगतता सत्यापन को दोनों के बीच अंतर करना चाहिए।
🧱 तार्किक संगतता
इसका ध्यान व्यापार नियमों और डेटा अखंडता पर होता है। क्या प्रवाह व्यापार के दृष्टिकोण से समझ में आता है? उदाहरण के लिए, क्या भुगतान के अनुमोदन से पहले ऑर्डर भेजा जा सकता है? तार्किक संगतता तकनीक को नजरअंदाज़ करती है और मूल्य के प्रवाह पर ध्यान केंद्रित करती है।
💻 भौतिक संगतता
इसका ध्यान तकनीकी सीमाओं पर होता है। क्या डेटा प्रवाह नेटवर्क प्रोटोकॉल के अनुरूप है? क्या डेटा प्रारूप डेटाबेस इंजन के साथ संगत है? भौतिक असंगति व्यापार तर्क को नहीं तोड़ सकती है, लेकिन डेप्लॉयमेंट के दौरान प्रणाली विफलता का कारण बन सकती है।
🔄 अंतराल को पार करना
जब तार्किक से भौतिक में संक्रमण किया जाता है, तो नए प्रवाह अक्सर दिखाई देते हैं (उदाहरण के लिए, त्रुटि लॉग, ऑडिट ट्रेल)। इन्हें संगतता बनाए रखने के लिए आरेख में जोड़ना चाहिए। यदि भौतिक कार्यान्वयन उस चरण को जोड़ता है जिसकी तार्किक आरेख ने गणना नहीं की थी, तो तार्किक आरेख अब वास्तविकता के अनुरूप नहीं रहता।
🔎 एंटिटी रिलेशनशिप मॉडल्स के साथ प्रतिच्छेदन
DFD गति का वर्णन करते हैं, जबकि एंटिटी रिलेशनशिप आरेख (ERD) संरचना का वर्णन करते हैं। संपूर्ण संगतता सुनिश्चित करने के लिए, इन दोनों आरेखों को समान रूप से व्यवस्थित करना चाहिए।
🗺️ मैपिंग अभ्यास
DFD में प्रत्येक डेटा स्टोर के लिए ERD में एक संगत एंटिटी सेट होना चाहिए। प्रत्येक डेटा प्रवाह के लिए एक संबंध या लक्षण होना चाहिए जो गति के लिए तर्कसंगतता प्रदान करे।
- कार्डिनैलिटी जांच: यदि DFD किसी प्रक्रिया में बहुत-एक प्रवाह दिखाता है, तो ERD में संबंधित संबंध कार्डिनैलिटी को प्रतिबिंबित करना चाहिए।
- की संगतता:ERD में रिकॉर्ड की पहचान के लिए उपयोग किए जाने वाले प्राथमिक की को डेटा प्रवाह में उन रिकॉर्ड को संदर्भित करने के लिए उपयोग किए जाने वाले समान की होना चाहिए।
यहाँ अंतर अक्सर चलाने के दौरान प्रदर्शन के बैरियर या संदर्भात्मक अखंडता के उल्लंघन के कारण बनते हैं। एक कठोर समीक्षा डेटा स्टोर के स्कीमा की तुलना ERD एंटिटीज़ के साथ करती है।
🛠️ रखरखाव और जीवनचक्र प्रबंधन
सुसंगतता एक बार के लिए उपलब्धि नहीं है। यह एक निरंतर अवस्था है जिसे प्रणाली के जीवनचक्र के दौरान बनाए रखना होता है। जैसे-जैसे आवश्यकताएँ बदलती हैं, आरेखों को विकसित होना चाहिए।
📂 आरेखों के लिए संस्करण नियंत्रण
जैसे कोड के लिए संस्करण नियंत्रण की आवश्यकता होती है, वैसे ही DFDs के लिए भी आवश्यकता होती है। आरेख में किए गए परिवर्तनों को ट्रैक किया जाना चाहिए। इससे टीमों को यह जांचने में मदद मिलती है कि सुसंगतता कब और क्यों तोड़ी गई या पुनर्स्थापित की गई। DFD के हर अपडेट के साथ एक बदलाव लॉग का होना चाहिए।
🔄 पुनर्परीक्षण परीक्षण
जब एक आरेख को अपडेट किया जाता है, तो सुसंगतता जांच को फिर से चलाना चाहिए। यह सॉफ्टवेयर विकास में पुनर्परीक्षण परीक्षण के समान है। क्या नया फ्लो एक काला छेद लाया? क्या नया प्रक्रिया मातृ संदर्भ के साथ संतुलन तोड़ दिया? स्वचालित उपकरण इसमें सहायता कर सकते हैं, लेकिन जटिल तर्क के लिए हाथ से समीक्षा अक्सर आवश्यक होती है।
👥 स्टेकहोल्डर समन्वय
सुसंगतता में लोगों को भी शामिल करना होता है। व्यावसायिक स्टेकहोल्डरों को डेटा परिभाषाओं पर सहमति बनानी चाहिए। यदि व्यवसाय “सक्रिय उपयोगकर्ता” को पिछले सप्ताह में लॉग इन करने वाले के रूप में परिभाषित करता है, लेकिन तकनीकी टीम इसे पिछले महीने में लॉग इन करने वाले के रूप में परिभाषित करती है, तो DFD तकनीकी परिभाषा को दर्शाएगा, जिससे व्यवसाय रिपोर्टिंग में त्रुटियाँ होंगी। नियमित समन्वय बैठकें आवश्यक हैं।
📈 ऑडिट ट्रेल और ट्रेसेबिलिटी
नियमित उद्योगों में, ट्रेसेबिलिटी एक कानूनी आवश्यकता है। प्रत्येक डेटा के लिए उसके स्रोत से अंतिम गंतव्य तक ट्रेस किया जाना चाहिए। DFDs इस ट्रेसेबिलिटी को स्थापित करने के मुख्य उपकरण हैं।
🔖 फ्लो को टैग करना
प्रत्येक डेटा फ्लो को उसके मूल और उद्देश्य को दर्शाने वाले मेटाडेटा के साथ टैग किया जाना चाहिए। इससे ऑडिट में मदद मिलती है। यदि डेटा ब्रीच होता है, तो विश्लेषक आरेख पर फ्लो को ट्रेस करके यह पहचान सकते हैं कि कहाँ विशेष लचीलापन हो सकता है।
🔗 प्रभाव विश्लेषण
यदि डेटा स्टोर में कोई परिवर्तन प्रस्तावित किया जाता है, तो DFD प्रभाव विश्लेषण की अनुमति देता है। उस स्टोर से जुड़े फ्लो को ट्रेस करके टीम सभी प्रक्रियाओं को पहचान सकती है जिन पर प्रभाव पड़ेगा। इससे एकल पक्ष द्वारा अनजाने में लाए गए असंगतता को रोका जा सकता है।
🎯 रखरखाव के लिए सर्वोत्तम प्रथाएँ
समय के साथ सुसंगतता बनाए रखने के लिए, इन सर्वोत्तम प्रथाओं का पालन करें:
- एकमात्र सत्य का स्रोत:DFD के लिए एक मास्टर रिपॉजिटरी बनाए रखें। अलग-अलग स्थानों में एक से अधिक संस्करणों के अस्तित्व की अनुमति न दें।
- मानकीकृत नोटेशन:पूरे दस्तावेज़ सूट में एक संगत नोटेशन (उदाहरण के लिए, Gane & Sarson या Yourdon & Coad) का उपयोग करें। नोटेशन को मिलाने से भ्रम पैदा होता है।
- नियमित समीक्षाएँ:वर्तमान प्रणाली अवस्था के खिलाफ DFD की तिमाही समीक्षा योजना बनाएं। प्रणालियाँ समय के साथ विचलित हो जाती हैं; आरेखों को इसके अनुरूप बनाए रखना चाहिए।
- स्वचालित प्रमाणीकरण:जहाँ संभव हो, स्वचालित रूप से सुसंगतता नियमों के प्रमाणीकरण करने वाले मॉडलिंग टूल्स का उपयोग करें (उदाहरण के लिए, असंतुलित प्रक्रियाओं को रोकना)।
- स्पष्ट नामकरण प्रथाएँ:प्रक्रियाओं और फ्लो के लिए सख्त नामकरण प्रथाओं को अपनाएं। अस्पष्ट नाम सुसंगतता के लिए उपजाऊ जगह हैं।
🌐 अन्य विधियों के साथ एकीकरण
DFDs एक खाली स्थान में नहीं होते हैं। वे डिज़ाइन अभिलेखों के एक बड़े पारिस्थितिकी तंत्र का हिस्सा हैं।
📋 स्थिति संक्रमण आरेख
जबकि DFDs डेटा के आवागमन को दिखाते हैं, राज्य परिवर्तन आरेख राज्य परिवर्तन को दिखाते हैं। सुनिश्चित करें कि राज्य परिवर्तन को ट्रिगर करने वाले डेटा प्रवाह राज्य आरेख में परिभाषित शर्तों के अनुरूप हों। यदि एक “लॉगिन प्रयास” प्रवाह राज्य परिवर्तन को ट्रिगर करता है, तो तर्क दोनों आरेखों में संगत होना चाहिए।
📊 उपयोग केस आरेख
उपयोग केस उपयोगकर्ता के दृष्टिकोण से बातचीत का वर्णन करते हैं। DFDs आंतरिक यांत्रिकी का वर्णन करते हैं। प्रत्येक उपयोग केस को DFD में कम से कम एक प्रक्रिया से मैप करना चाहिए। यदि किसी उपयोग केस के लिए कोई संबंधित प्रक्रिया नहीं है, तो आवश्यकता पूरी नहीं हुई है। यदि किसी प्रक्रिया के लिए कोई उपयोग केस नहीं है, तो यह मृत कोड हो सकता है।
🏁 सत्यापन पर अंतिम विचार
DFD विश्लेषण के माध्यम से डेटा सुसंगतता सुनिश्चित करना एक अनुशासन है जिसमें धैर्य और विस्तृत ध्यान की आवश्यकता होती है। यह बग्स ढूंढने के बारे में नहीं है; यह एक ठोस आधार बनाने के बारे में है। संतुलन की कठोर जांच, शब्दकोशों की तुलना करना और तार्किक और भौतिक दृष्टिकोण के बीच संरेखण बनाए रखने से, सिस्टम विश्लेषक उत्पादन में त्रुटियों के प्रकट होने से पहले उन्हें रोक सकते हैं।
इस सत्यापन में निवेश की गई मेहनत सिस्टम स्थिरता और रखरखाव लागत में कमी के रूप में लाभ देती है। एक सुसंगत डिज़ाइन वह डिज़ाइन है जो अपने ही डेटा को समझता है। जैसे-जैसे सिस्टम की जटिलता बढ़ती है, स्पष्ट और सुसंगत आरेखों पर भरोसा करना अराजकता के खिलाफ मुख्य रक्षा बन जाता है। इन सिद्धांतों का पालन करने से यह सुनिश्चित होता है कि सूचना का प्रवाह व्यापार तर्क के बराबर विश्वसनीय बना रहे।