











एक प्रणाली के माध्यम से जानकारी कैसे आगे बढ़ती है, इसकी समझ यश के लिए आवश्यक है। चाहे आप एक नए प्लेटफॉर्म के लिए आवश्यकताओं को परिभाषित कर रहे हों या मौजूदा वर्कफ्लो का ऑडिट कर रहे हों, डेटा के आंदोलन को दृश्याकृत करना सभी को एक ही पृष्ठभूमि पर रखने में मदद करता है। डेटा फ्लो डायग्राम (DFD) इसी उद्देश्य के लिए डिज़ाइन किया गया एक शक्तिशाली उपकरण है। यह डेटा किस तरह प्रणाली में प्रवेश करता है, वह कैसे बदलता है, और अंततः वह कहाँ जाता है, इसका नक्शा बनाता है। गैर-तकनीकी हितधारकों के लिए, इन डायग्रामों को पढ़ने और समझने का अध्ययन करने से सॉफ्टवेयर विकास और व्यवसाय प्रक्रिया विश्लेषण के रहस्य को दूर कर दिया जाता है।
यह मार्गदर्शिका डेटा फ्लो डायग्राम के पीछे के मूल घटकों, प्रतीकों और तर्क को समझने में मदद करती है। हम वैश्विक स्तर पर उपयोग किए जाने वाले मानक नोटेशन, उपलब्ध विभिन्न विवरण स्तरों और सामान्य त्रुटियों को पहचानने के तरीकों का अध्ययन करेंगे। इस दस्तावेज़ के अंत तक, आप डायग्रामों की समीक्षा करने, सही प्रश्न पूछने और यह सुनिश्चित करने के लिए आत्मविश्वास रखेंगे कि आपकी व्यवसाय प्रक्रियाएँ सही तरीके से प्रतिबिंबित की गई हैं।
🧩 डेटा फ्लो डायग्राम क्या है?
एक डेटा फ्लो डायग्राम एक सूचना प्रणाली के माध्यम से डेटा के प्रवाह का आलेखीय प्रतिनिधित्व है। एक फ्लोचार्ट के विपरीत, जो नियंत्रण प्रवाह या निर्णयों के क्रम को दिखाता है, एक DFD डेटा के आंदोलन पर ही केंद्रित होता है। यह समय, लूप या पारंपरिक प्रोग्रामिंग के अर्थ में शर्ती तर्क के बारे में चिंतित नहीं होता है। इसके बजाय, यह तीन मूलभूत प्रश्नों के उत्तर देता है:
- डेटा कहाँ से आता है? (बाहरी स्रोत)
- डेटा के साथ क्या होता है? (प्रक्रियाएँ)
- डेटा कहाँ जाता है? (गंतव्य या भंडारण)
एक DFD को डेटा के लिए एक नक्शा के रूप में सोचें। जैसे कि एक सड़क नक्शा हाईवे और निकास दिखाता है, लेकिन हर पेड़ या इमारत को नहीं दिखाता, वैसे ही एक DFD जानकारी के मुख्य मार्गों को दिखाता है, कोड के विवरण में फंसे बिना। यह सारांशीकरण ही इसे व्यवसाय हितधारकों के लिए इतना प्रभावी बनाता है, जिन्हें जानकारी के “क्या” और “कहाँ” को समझने की आवश्यकता होती है, तकनीकी कार्यान्वयन के “कैसे” के बजाय।
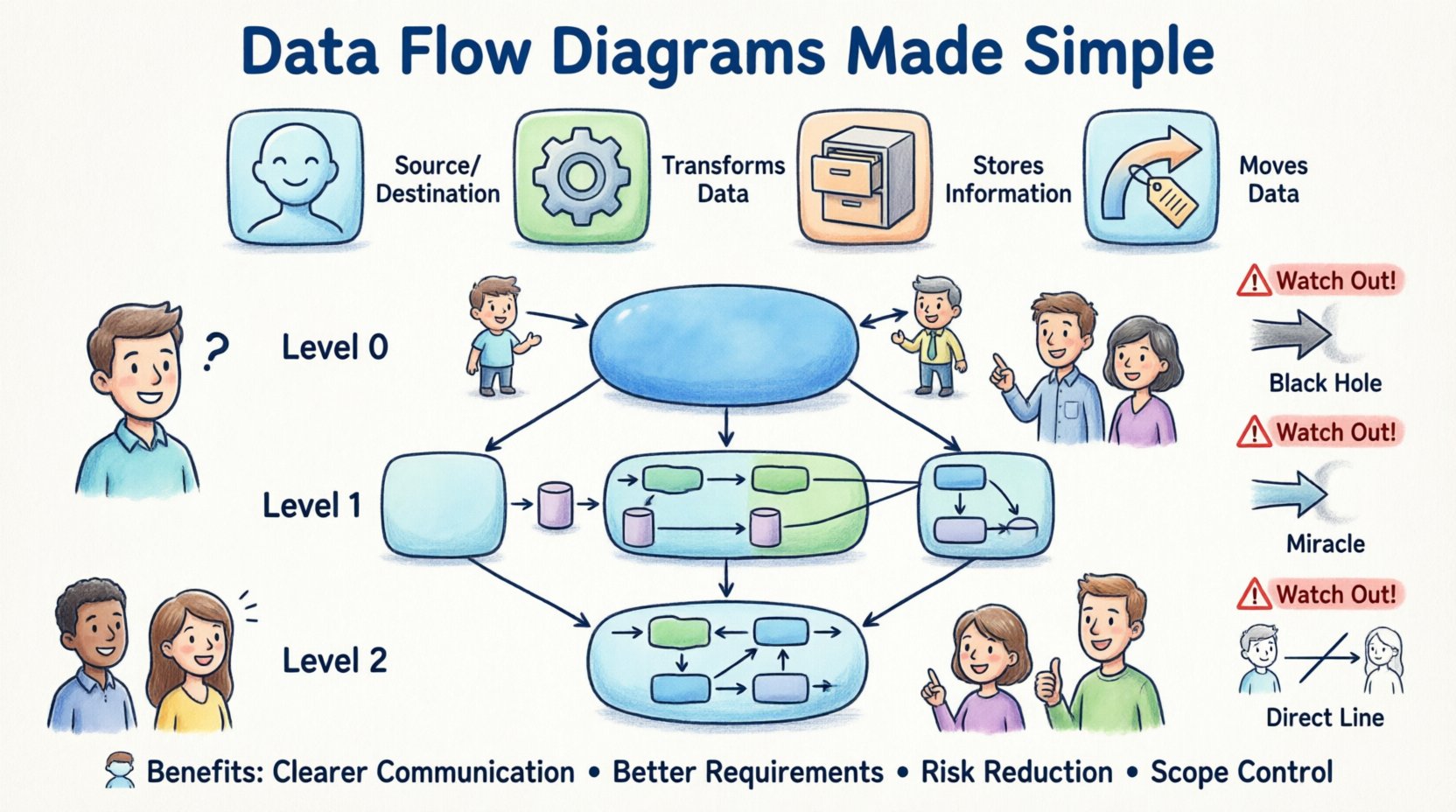
🛑 DFD नोटेशन के चार मूल प्रतीक
आपको जिस विशिष्ट नोटेशन शैली का सामना करना हो, उसके बावजूद, सभी DFDs चार मूल आकृतियों या अवधारणाओं पर निर्भर करते हैं। इन निर्माण ब्लॉक्स को समझना किसी भी डायग्राम के अर्थ को समझने की कुंजी है।
1. बाहरी एकाधिकारी (स्रोत या गंतव्य) 👤
एक बाहरी एकाधिकारी एक व्यक्ति, संगठन या प्रणाली का प्रतिनिधित्व करता है जो आपके मॉडलिंग की प्रणाली की सीमा के बाहर स्थित है। यह डेटा का आरंभिक बिंदु या अंतिम प्राप्तकर्ता है। डायग्राम में, इन्हें आमतौर पर आयत या वर्ग के रूप में दर्शाया जाता है।
- उदाहरण: एक ग्राहक आदेश देना।
- उदाहरण: वेतन डेटा प्राप्त करने वाला वेतन प्रणाली।
- उदाहरण: एक नियामक निकाय जो एक रिपोर्ट मांगता है।
यह ध्यान देने योग्य है कि डायग्राम उस एकाधिकारी के आंतरिक कार्यों को नहीं दिखाता है। यह केवल प्रणाली के साथ बातचीत को दिखाता है। यदि डेटा उपयोगकर्ता से आता है, तो उपयोगकर्ता ही एकाधिकारी है। यदि डेटा बैंक API से आता है, तो बैंक ही एकाधिकारी है।
2. प्रक्रिया (क्रिया) ⚙️
एक प्रक्रिया एक क्रिया का प्रतिनिधित्व करती है जो इनपुट डेटा को आउटपुट डेटा में बदलती है। यहीं “काम” होता है। DFD में, प्रक्रियाओं को आमतौर पर गोल आयत या वृत्त के रूप में बनाया जाता है, नोटेशन शैली के अनुसार। प्रत्येक प्रक्रिया के कम से कम एक इनपुट और एक आउटपुट होना चाहिए।
- उदाहरण: आदेश की कुल कीमत की गणना करना।
- उदाहरण: लॉगिन प्रमाणपत्र की प्रमाणीकरण करना।
- उदाहरण: इन्वॉइस PDF बनाना।
प्रक्रियाओं के नाम अंग्रेजी क्रिया के बाद संज्ञा का उपयोग करके रखे जाते हैं (उदाहरण के लिए, “कर की गणना” बजाय केवल “कर”)। इससे यह सुनिश्चित होता है कि क्रिया स्पष्ट हो। एक प्रक्रिया सिर्फ अस्तित्व में नहीं हो सकती; इसे डेटा में किसी तरह परिवर्तन करना होगा।
3. डेटा भंडार (मेमोरी) 🗃️
एक डेटा स्टोर उस स्थान का प्रतिनिधित्व करता है जहां जानकारी बाद में पुनर्प्राप्त करने के लिए सहेजी जाती है। यह सर्वर पर एक भौतिक डेटाबेस नहीं है, बल्कि भंडारण का एक तार्किक प्रतिनिधित्व है। आरेखों में, इन्हें खुले छोर वाले आयत या समानांतर रेखाओं के रूप में दिखाया जाता है।
- उदाहरण: ग्राहक रिकॉर्ड वाली एक फ़ाइल।
- उदाहरण: इन्वेंटरी स्तरों को संग्रहीत करने वाली डेटाबेस तालिका।
- उदाहरण: त्रुटि ट्रैकिंग के लिए एक अस्थायी लॉग फ़ाइल।
डेटा स्टोर सक्रिय नहीं होते हैं। वे अपने आप डेटा को नहीं बदलते; वे किसी प्रक्रिया के उनमें लिखने या उनसे पढ़ने का इंतजार करते हैं। एक डेटा स्टोर (स्थायी या अर्ध-स्थायी) और डेटा फ्लो (गति) के बीच अंतर स्थापित करना बहुत महत्वपूर्ण है।
4. डेटा फ्लो (गति) 🔄
एक डेटा फ्लो एकता, प्रक्रियाओं और स्टोर के बीच डेटा की गति को दर्शाता है। इन्हें तीरों द्वारा दर्शाया जाता है। तीर डेटा की दिशा को दर्शाता है। तीर पर लेबल बताता है कि कौन सी डेटा गति कर रही है।
- उदाहरण: एक तीर जिस पर “ग्राहक आदेश” लेबल है, जो एक एकता से एक प्रक्रिया में जा रहा है।
- उदाहरण: एक तीर जिस पर “अद्यतन इन्वेंटरी” लेबल है, जो एक प्रक्रिया से एक डेटा स्टोर में जा रहा है।
डेटा फ्लो के नाम स्पष्ट रूप से रखे जाने चाहिए। “डेटा” या “जानकारी” जैसे अस्पष्ट लेबल से बचें। इसके बजाय, “क्रेडिट कार्ड विवरण” या “शिपिंग पता” जैसे विशिष्ट शब्दों का उपयोग करें। इस विशिष्टता से समीक्षा बैठकों में भ्रम से बचा जा सकता है।
📐 नोटेशन शैलियों की तुलना
उद्योग में डीएफडी नोटेशन की दो मुख्य शैलियाँ हैं। जबकि वे समान अवधारणाओं का प्रतिनिधित्व करती हैं, आकृतियाँ अलग होती हैं। अंतर को जानना आपको अलग टीमों या विक्रेताओं द्वारा बनाए गए दस्तावेजों की व्याख्या करने में मदद करता है।
| घटक | योरडॉन और डेमार्को नोटेशन | गेन और सर्सन नोटेशन |
|---|---|---|
| प्रक्रिया | गोल आयत | गोल किनारों वाला आयत |
| बाहरी एकता | आयत | आयत |
| डेटा स्टोर | खुले छोर वाला आयत | खुले छोर वाला आयत |
| डेटा फ्लो | वक्र त стрелा | सीधी त्रिभुज |
दोनों शैलियां मान्य हैं। गेन और सार्सन शैली को आधुनिक उद्यम परिवेशों में अक्सर प्राथमिकता दी जाती है क्योंकि आयताकार आकृतियां मानक उपयोगकर्ता इंटरफेस डिजाइनों के साथ अच्छी तरह से मेल खाती हैं। हालांकि, यूरडॉन और डेमार्को शैली अभी भी पुराने दस्तावेजों में व्यापक रूप से उपयोग की जाती है। आकृति के उपयोग के बावजूद तर्क समान रहता है।
🏗️ डीएफडी में विवरण के स्तर
एक ही आरेख सभी बातों को नहीं दिखा सकता है। जटिलता को प्रबंधित करने के लिए, डीएफडी को विभिन्न स्तरों के सारांश के रूप में बनाया जाता है। इस पदानुक्रम के कारण स्टेकहोल्डर्स को पहले बड़ी तस्वीर देखने की अनुमति मिलती है, फिर आवश्यकता के अनुसार विशिष्ट बातों में गहराई से जाने की अनुमति मिलती है।
1. संदर्भ आरेख (स्तर 0) 🌍
संदर्भ आरेख सबसे ऊंचे स्तर के सारांश का प्रतिनिधित्व करता है। इसमें पूरे प्रणाली को केंद्र में एकल प्रक्रिया के रूप में दिखाया जाता है, जिसे बाहरी एकाधिकारों से घेरा गया है। यहां कोई आंतरिक डेटा भंडार या उप-प्रक्रियाएं नहीं दिखाई गई हैं।
- उद्देश्य: प्रणाली की सीमाओं को परिभाषित करना।
- उपयोग के मामले: प्रोजेक्ट के बहुत शुरुआती चरण में उपयोग किया जाता है ताकि यह सहमति बनाई जा सके कि प्रणाली के अंदर क्या है और बाहर क्या है।
- दृश्य: एक वृत्त (प्रणाली) जिसके साथ बाहरी आयतों से तीर जुड़े हैं।
स्टेकहोल्डर्स के लिए, यह आरेख प्रश्न का उत्तर देता है: “यह प्रणाली हमारे लिए क्या करती है?” यह आपको मिलने वाला सबसे उच्च स्तर का दृश्य है।
2. स्तर 1 आरेख (कार्यात्मक विभाजन) 🔍
स्तर 1 आरेख संदर्भ आरेख से एकल प्रक्रिया को बड़े उप-प्रक्रियाओं में विस्तारित करता है। यह प्रणाली के मुख्य कार्यात्मक क्षेत्रों को उजागर करता है। यहां डेटा भंडार का परिचय दिया जाता है ताकि इन मुख्य कार्यों के बीच जानकारी कहां रखी जाती है, इसका पता चल सके।
- उद्देश्य: मुख्य कार्यात्मक घटकों को रूपरेखा बनाना।
- उपयोग के मामले: आर्किटेक्चर की योजना बनाने और विभिन्न टीमों को कार्य सौंपने के लिए उपयोग किया जाता है।
- दृश्य: प्रवाहों और भंडारों द्वारा जुड़े कई प्रक्रियाएं।
इस चरण पर, स्टेकहोल्डर्स यह सत्यापित कर सकते हैं कि सभी महत्वपूर्ण व्यावसायिक कार्यों को ध्यान में रखा गया है। यदि इस आरेख में एक महत्वपूर्ण व्यावसायिक आवश्यकता के लिए कोई प्रक्रिया अनुपस्थित है, तो उसे जोड़ना आवश्यक है।
3. स्तर 2 आरेख (विस्तृत तर्क) 🔬
स्तर 2 आरेख स्तर 1 से विशिष्ट प्रक्रियाओं को लेते हैं और उन्हें और अधिक विभाजित करते हैं। इनका उपयोग जटिल गणनाओं या जटिल कार्य प्रवाहों के लिए किया जाता है। ये तकनीकी रूप से अपरिचित स्टेकहोल्डर्स को दिखाए जाते हैं तभी जब किसी विशिष्ट कार्य को डिबग किया जा रहा हो।
- उद्देश्य: विशिष्ट मॉड्यूल के लिए विस्तृत तर्क को परिभाषित करना।
- उपयोग के मामले: विकास टीम के लिए संदर्भ और विस्तृत परीक्षण योजनाएं।
- दृश्य: बहुत बारीक बहाव और निर्णय बिंदु।
हितधारकों को मुख्य रूप से संदर्भ और स्तर 1 आरेखों पर ध्यान केंद्रित करना चाहिए। स्तर 2 आरेख आमतौर पर तकनीकी उपकरण होते हैं जो गहराई प्रदान करते हैं लेकिन उच्च स्तर की समीक्षा के लिए जरूरी व्यावसायिक मूल्य नहीं प्रदान करते।
🚦 डीएफडी को प्रभावी ढंग से पढ़ने का तरीका
डीएफडी को पढ़ने के लिए एक व्यवस्थित दृष्टिकोण की आवश्यकता होती है। आकृतियों को देखने के अलावा डेटा के मार्ग का पालन करें। इससे आपको जानकारी के जीवनचक्र को समझने में सहायता मिलती है।
चरण 1: सीमा की पहचान करें
आरेख को देखें और तय करें कि सिस्टम के अंदर क्या है और बाहर क्या है। सभी चीजें जो अंदर हैं, सिस्टम द्वारा नियंत्रित हैं। सभी चीजें जो बाहर हैं, बाहरी प्रभाव हैं। यदि आप बाहरी सीमा के बाहर किसी प्रक्रिया को देखते हैं जो अंदर होनी चाहिए, तो यह एक सीमा का मुद्दा है।
चरण 2: इनपुट का पता लगाएं
एक बाहरी एकाधिकार को ढूंढें। सिस्टम में प्रवेश करने वाली तीर का पालन करें। खुद से पूछें: “इस प्रक्रिया को शुरू करने के लिए किस डेटा की आवश्यकता है?” यदि डेटा गायब है, तो प्रक्रिया काम नहीं कर सकती है। यह गायब आवश्यकताओं की पहचान करने में मदद करता है।
चरण 3: परिवर्तन का पालन करें
एक प्रक्रिया से अगली प्रक्रिया में जाएं। पूछें: “डेटा में कैसे परिवर्तन हुआ?” यदि डेटा प्रक्रिया A से प्रक्रिया B में बहता है, तो A का आउटपुट B का इनपुट बन जाता है। यदि डेटा प्रकार मेल नहीं खाते हैं, तो डिजाइन में दोष है।
चरण 4: स्टोरेज की जांच करें
डेटा स्टोर को स्थापित करें। पूछें: “इस डेटा को क्यों सहेजा जा रहा है?” क्या भविष्य की रिपोर्टिंग के लिए यह आवश्यक है? क्या भूतकालीन लेनदेन को याद करने के लिए यह आवश्यक है? यदि कोई प्रक्रिया स्टोर में लिखती है लेकिन कोई अन्य प्रक्रिया इससे पढ़ती नहीं है, तो वह स्टोरेज अनावश्यक है और लागत बढ़ाती है।
चरण 5: आउटपुट की पुष्टि करें
सिस्टम से बाहर निकलने वाली तीरों का पालन करें। क्या वे सही बाहरी एकाधिकार तक पहुंचती हैं? यदि सिस्टम एक रिपोर्ट उत्पन्न करता है, तो क्या उस रिपोर्ट के उपयोगकर्ता तक पहुंचने का मार्ग है? यदि आरेख एक मृत अंत तक समाप्त होता है, तो सिस्टम अपूर्ण है।
⚠️ आम डीएफडी गलतियाँ और विचित्रताएँ
यहां तक कि अनुभवी मॉडलर भी गलतियाँ करते हैं। एक हितधारक के रूप में, इन आम त्रुटियों को जानने से आप रिव्यू के दौरान उन्हें पकड़ने में सक्षम होते हैं। इन मुद्दों को जल्दी पहचानने से विकास के बाद के चरण में महत्वपूर्ण समय और पैसा बचता है।
1. काले छेद
एक काला छेद तब होता है जब किसी प्रक्रिया के प्रवेश डेटा होता है लेकिन आउटपुट डेटा नहीं होता है। डेटा प्रवेश करता है, गायब हो जाता है, और कुछ भी नहीं होता है। एक वास्तविक सिस्टम में, यह एक त्रुटि है। यदि उपयोगकर्ता एक फॉर्म जमा करता है, तो सिस्टम इसे या तो सहेजे, या अस्वीकार करे, या पुष्टि भेजे। यह बस गायब नहीं हो सकता।
2. चमत्कार
एक चमत्कार काले छेद का विपरीत है। यह एक प्रक्रिया है जिसमें आउटपुट डेटा होता है लेकिन कोई इनपुट डेटा नहीं होता है। डेटा कहाँ से आया? यदि सिस्टम एक दैनिक रिपोर्ट उत्पन्न करता है, तो उस रिपोर्ट को भरने वाले इनपुट ट्रिगर या डेटा स्रोत की आवश्यकता होती है। डेटा को किसी भी चीज से बनाया नहीं जा सकता।
3. एकाधिकार और स्टोर के बीच सीधे डेटा प्रवाह
डेटा को डेटा स्टोर तक पहुंचने के लिए हमेशा किसी प्रक्रिया से गुजरना चाहिए। आप उपयोगकर्ता से सीधे डेटाबेस तक रेखा नहीं खींच सकते। एक प्रक्रिया (उदाहरण के लिए, “रिकॉर्ड सहेजें”) होनी चाहिए जो लेनदेन को संभाले। इससे यह सुनिश्चित होता है कि स्टोरेज से पहले वैधता और तर्क लागू किए जाते हैं।
4. असंतुलित प्रवाह
जब आप स्तर 0 से स्तर 1 तक आरेख को विभाजित करते हैं, तो इनपुट और आउटपुट के मेल बने रहने चाहिए। यदि संदर्भ आरेख में “आदेश” आने का दिखावा करता है, तो स्तर 1 आरेख में भी “आदेश” आने का दिखावा करना चाहिए। यदि वह गायब हो जाता है, तो विभाजन असंतुलित और असही है।
5. वृत्ताकार डेटा प्रवाह
डेटा को प्रक्रिया किए बिना एक वृत्त में बहने नहीं चाहिए। यदि प्रक्रिया A डेटा प्रक्रिया B को भेजती है, और प्रक्रिया B बिना किसी डेटा स्टोर या बाहरी परिवर्तन के डेटा को प्रक्रिया A को वापस भेजती है, तो यह अनंत लूप बनाता है। इससे प्रक्रिया प्रवाह में तार्किक त्रुटि का संकेत मिलता है।
🤝 तकनीकी रूप से अनुभवहीन हितधारकों के लिए लाभ
आपको इस नोटेशन को सीखने की जरूरत क्यों है? लाभ केवल एक आरेख को समझने तक सीमित नहीं है। यह आपके प्रोजेक्ट में भूमिका को महत्वपूर्ण रूप से बेहतर बनाता है।
बेहतर आवश्यकता एकत्रीकरण
जब आप डीएफडी को समझते हैं, तो आप आवश्यकताओं में खामियों को पहचान सकते हैं। यदि कोई हितधारक कहता है, “हमें उपयोगकर्ता लॉगिन को ट्रैक करने की आवश्यकता है,” लेकिन आरेख में प्रमाणीकरण के लिए कोई प्रक्रिया नहीं दिखाई देती है, तो आप तुरंत इसे चिह्नित कर सकते हैं। आप एक सक्रिय मान्यता देने वाले बन जाते हैं, बजाय निष्क्रिय निरीक्षक के।
स्पष्ट संचार
शब्द अस्पष्ट हो सकते हैं। ‘डेटा को सहेजें’ का मतलब ‘फ़ाइल में सहेजें’ या ‘डेटाबेस में सहेजें’ हो सकता है। एक DFD दृश्य रूप से गंतव्य को स्पष्ट करता है। इससे व्यापार टीमों और तकनीकी टीमों के बीच गलत संचार कम होता है। सभी एक ही नक्शे को देखते हैं और गंतव्य के बारे में सहमत होते हैं।
जोखिम कम करना
डिज़ाइन चरण में पाए गए त्रुटियां ठीक करने में सस्ती होती हैं। कोडिंग के बाद पाई गई त्रुटियां महंगी होती हैं। विकास शुरू होने से पहले DFD की समीक्षा करके आप तार्किक दोषों को पकड़ सकते हैं। इससे अनावश्यक रूप से काम न करने वाली सुविधाओं के निर्माण में संसाधनों के बर्बाद होने से बचा जा सकता है।
स्कोप प्रबंधन
DFD स्पष्ट रूप से सीमाओं को परिभाषित करते हैं। वे दिखाते हैं कि क्या सिस्टम के अंदर है और क्या बाहर है। इससे ‘स्कोप क्रीप’ को रोकने में मदद मिलती है। यदि कोई स्टेकहोल्डर एक नई सुविधा के लिए अनुरोध करता है जो परिभाषित एंटिटीज और प्रक्रियाओं के बाहर है, तो DFD उस अनुरोध को प्रबंधित करने के लिए दृश्य साक्ष्य प्रदान करता है।
🔧 DFDs को बनाए रखने के लिए सर्वोत्तम प्रथाएं
एक आरेख केवल तभी उपयोगी होता है जब वह सही हो। समय के साथ, प्रणालियां बदलती हैं, और आरेख पुराने हो सकते हैं। लंबे समय तक सफलता के लिए उन्हें अद्यतन रखना आवश्यक है।
- संस्करण नियंत्रण:DFD को कोड की तरह लें। महत्वपूर्ण बदलाव होने पर संस्करण सहेजें। इससे आप प्रणाली के समय के साथ विकास को ट्रैक कर सकते हैं।
- समीक्षा चक्र:आरेखों की नियमित समीक्षा की योजना बनाएं। उन्हें जांचने के लिए क्राइसिस का इंतजार न करें। तिमाही समीक्षा वर्तमान व्यापार आवश्यकताओं के साथ संरेखण सुनिश्चित करती है।
- स्टेकहोल्डर स्वीकृति:यह सुनिश्चित करें कि कोडिंग शुरू होने से पहले मुख्य स्टेकहोल्डर्स लेवल 1 आरेख पर हस्ताक्षर करें। इस औपचारिक सहमति से यह सत्यापित होता है कि मॉडल व्यापार की अपेक्षाओं के अनुरूप है।
- पूर्णता की तुलना में स्पष्टता:डेटा स्टोर में प्रत्येक एकल फ़ील्ड को दिखाने की कोशिश न करें। तार्किक प्रवाह पर ध्यान केंद्रित करें। बहुत अधिक विवरण आरेख के मुख्य उद्देश्य को छिपा देता है।
- संगत नामकरण:सभी आरेखों में एक ही शब्दों का उपयोग करें। यदि आप एक जगह ‘ग्राहक’ कहते हैं और दूसरी जगह ‘ग्राहक’ कहते हैं, तो यह भ्रम पैदा करता है। शब्दावली का एक शब्दकोष बनाए रखें।
📝 निष्कर्ष
डेटा प्रवाह आरेख केवल तकनीकी ड्राइंग नहीं हैं; वे व्यापार लक्ष्यों और तकनीकी कार्यान्वयन के बीच के अंतर को पार करने वाले संचार उपकरण हैं। चार मुख्य प्रतीकों को समझने, विभिन्न विवरण स्तरों को पहचानने और सामान्य त्रुटियों को पहचानने के तरीके को जानने से आपको प्रणाली परियोजनाओं के प्रबंधन में एक महत्वपूर्ण लाभ मिलता है।
आपको इन आरेखों से मूल्य प्राप्त करने के लिए डेवलपर होने की आवश्यकता नहीं है। आपको केवल जानकारी के प्रवाह को समझने की आवश्यकता है। इस ज्ञान ने आपको बेहतर सवाल पूछने, मान्यताओं को चुनौती देने और यह सुनिश्चित करने में सक्षम बनाता है कि अंतिम उत्पाद वास्तव में व्यापार की आवश्यकताओं को पूरा करता है। जैसे-जैसे प्रणालियां अधिक जटिल होती हैं, स्पष्ट, दृश्य दस्तावेज़ीकरण की आवश्यकता और अधिक महत्वपूर्ण हो जाती है। DFD नोटेशन के बुनियादी बातों को सीखना स्पष्ट, अधिक कुशल परियोजना डिलीवरी की ओर एक कदम है।
याद रखें, लक्ष्य ड्राइंग में पूर्णता नहीं है, बल्कि समझ में स्पष्टता है। इन आरेखों का उपयोग चर्चा को आसान बनाने, जोखिमों को पहचानने और अपनी टीम को प्रणाली के दृष्टिकोण पर सहमत करने के लिए करें। DFD नोटेशन को अच्छी तरह समझने के बाद आप प्रणाली डिज़ाइन की जटिलताओं को आत्मविश्वास और सटीकता के साथ निर्देशित कर सकते हैं।