











🏗️ オブジェクト指向分析の基盤
オブジェクト指向分析と設計(OOA&D)の分野において、システムモデルの正確さは初期段階で特定されたエンティティの質にかかっています。現実世界のエンティティはソフトウェアソリューションの核となる構成要素を表します。これらはドメイン内で状態、振る舞い、関係性を保持するオブジェクトです。これらのエンティティが正しく定義されれば、得られるアーキテクチャは堅牢で、保守が容易であり、ビジネス運用と整合性を持ちます。逆に、エンティティを誤って特定すると、複雑な結合、重複するデータ構造、変化する要件に適応しづらいシステムにつながる可能性があります。
効果的なモデル化には、データを孤立したテーブルや変数として見るのではなく、ビジネスプロセスの積極的な参加者として捉える姿勢の転換が必要です。目的は、不要な複雑さを導入せずにドメインの本質を捉えることです。このプロセスには、要件を厳密に検討し、専門家と協働し、厳密な分析手法を用いて重要なエンティティ、価値オブジェクト、一時的な属性を区別することを含みます。
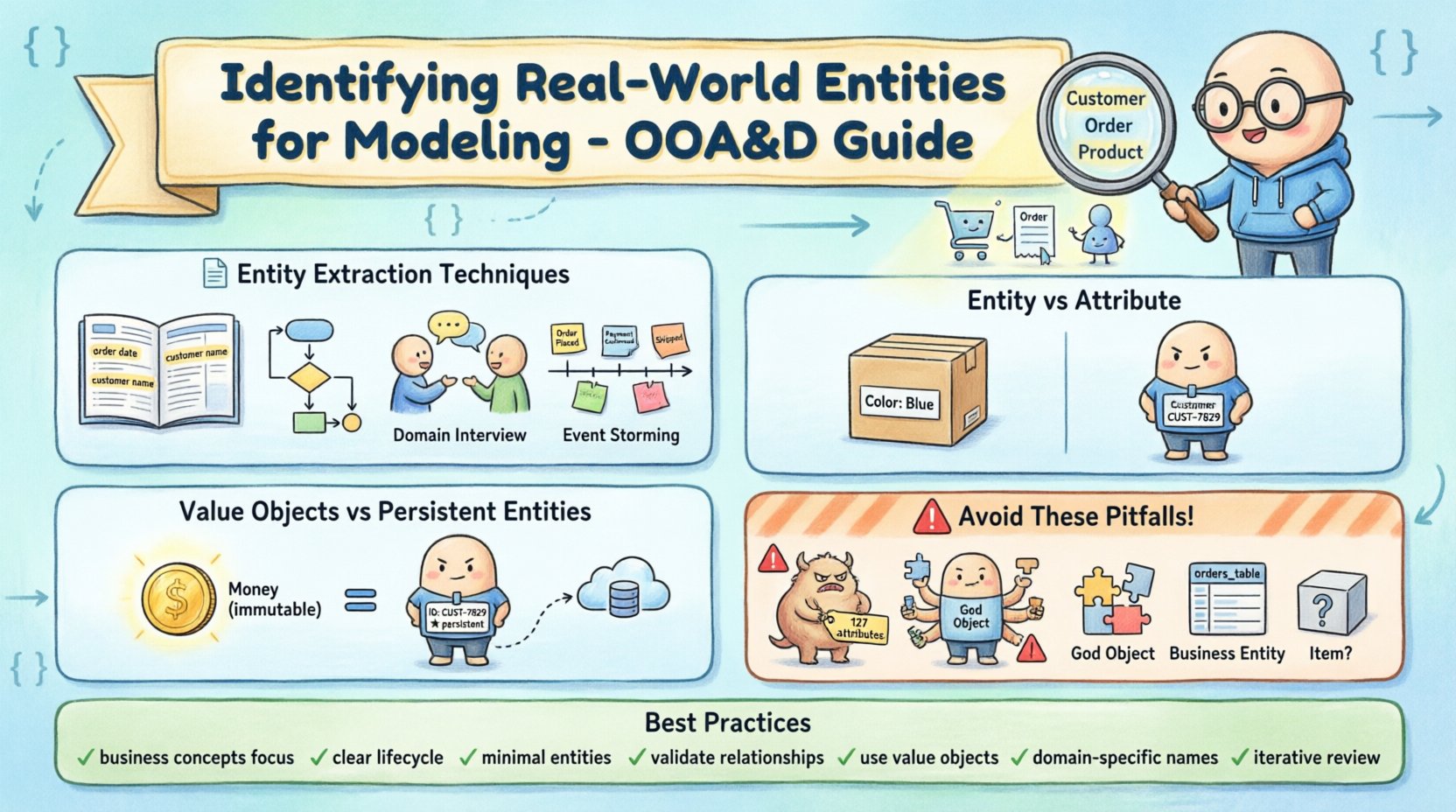
📝 エンティティ抽出の手法
原始的な情報から潜在的なエンティティを抽出するための、いくつかの検証済みの手法が存在します。これらの手法は、曖昧なビジネスニーズを具体的なモデル化候補に変換するのに役立ちます。
- 名詞句分析:最も一般的なアプローチの一つは、要件文書やユーザーストーリーを読み進めるものです。アナリストは頻繁に出現する名詞や名詞句を強調します。たとえば、物流システムでは、「「パッケージ」、 「ドライバー」、および「倉庫」という用語が自然に浮かび上がります。しかし、すべての名詞がエンティティというわけではありません。たとえば、「「ハンドリング」または「配送」という用語は、独立したオブジェクトではなく、行動や関係性を表すことが多いです。
- ユースケースシナリオ:ユースケースを検討することで、データがどのように利用されるかの文脈が得られます。ユーザーが複数のシナリオで特定のオブジェクトとやり取りする場合、それはエンティティの有力な候補です。たとえば、ユーザーがログインし、ダッシュボードを表示し、プロフィールを編集する場合、「「User」」オブジェクトはシステムの中心に位置します。
- ドメイン知識のインタビュー:ステークホルダーと対話することで、彼らが日常的に使用する用語が明らかになります。これにより、技術仕様に明示的に記載されていなくてもビジネスロジックにとって不可欠なエンティティを特定できます。ステークホルダーは、技術的な識別子ではなく、機能的な名前でオブジェクトを指すことが多いです。
- イベントストーミング:この協働的な技法では、ビジネスイベントをタイムライン上にマッピングします。各イベントは、それを引き起こした、または影響を受けたエンティティの存在を示唆することが多いです。この視覚的なアプローチにより、テキストベースの分析では見逃されがちな関係性を明らかにすることができます。
🔍 エンティティと属性の区別
モデル化における一般的な課題は、ある概念が独立したエンティティであるべきか、それとも他のエンティティの属性にすぎないかを判断することです。この判断は、モデルの粒度とクエリの複雑さに影響を与えます。
属性はエンティティの性質を記述するものです。通常、独自の識別子を持ちません。たとえば、「Color」という属性は「製品」エンティティは製品の外観を記述するものであり、製品以外の独立した存在として存在しない。
しかしエンティティは独自のアイデンティティとライフサイクルを持つ。特定の文脈では、特定の親インスタンスに紐づかなくても存在可能であり、しばしば独自の関係性を持つ。次の違いを検討してみよう。「住所」および「都市」。あるモデルでは、「住所」は、「通り名」, 「都市」、「郵便番号」を含む複雑な属性である。他方では、「都市」は、「人口」および「地域」といったプロパティを持つ独立したエンティティであり、複数の「住所」レコードに関連付けられている。
| 基準 | 属性 | エンティティ |
|---|---|---|
| アイデンティティ | 一意の識別子なし | 一意の識別子を持つ |
| 複雑性 | シンプルなデータ型(文字列、数値) | 複数の属性と振る舞いを持つことができる |
| 再利用性 | 一つのコンテキスト内でのみ使用される | 複数のコンテキストで共有できる |
| ライフサイクル | 親が存在する間だけ存在する | 独立したライフサイクルを持つ |
💎 値オブジェクトと永続エンティティ
すべてのエンティティがデータベースに永続化される必要があるわけではない。値オブジェクトと永続エンティティを区別することは、パフォーマンスとアーキテクチャの整合性にとって重要である。
値オブジェクトは、特徴を定義するが、明確な識別子を持たないオブジェクトである。属性によって定義される。属性を変更すると、オブジェクトは異なるものと見なされる。代表的な例は「Money」である。同じ金額と通貨を持つ2つのMoneyインスタンスは等価と見なされる。特定のドル額に対して一意のIDは必要ない。
永続エンティティは、属性が同一であっても他のインスタンスと区別するために一意の識別子を必要とする。たとえば「Customer」エンティティはCustomer IDを持つ必要がある。2人の顧客が同じ名前と住所を持っていたとしても、異なる人物である。
値オブジェクトを使用することで、不要なデータベースのオーバーヘッドを削除し、ドメインモデルの複雑さを軽減できる。これにより、識別子の必要がある場所にのみ注力できる。
⚠️ 一般的なモデル化の落とし穴
経験豊富なアナリストですら、識別フェーズで落とし穴にはまることがある。これらの落とし穴を認識することで、モデルを洗練できる。
- 過剰なモデル化:ほとんど使われない、または大きな価値をもたらさない概念に対してエンティティを作成すること。これにより、ナビゲーションが困難な肥大化したモデルになってしまう。
- 不足したモデル化:あまりにも多くの概念を1つのエンティティにまとめること。これにより、保守が困難で単一責任の原則に違反する「ゴッドオブジェクト」が生じることが多い。
- 関係性を無視する:相互作用の仕方を定義せずにオブジェクトにのみ注目すること。関係性を持たないエンティティは孤立しており、接続されたシステムではしばしば無意味になる。
- 技術的バイアス:データベースのテーブル名やプログラミング上の制約に基づいてエンティティの名前を付けること。モデルはインフラストラクチャではなく、ドメインを反映すべきである。
- 早すぎる抽象化:」などとして作成する前に、具体的な要件を理解すること。具体的な視点が、一般的なモデルが隠している必要となる詳細を明らかにすることが多い。「Item」または「Object」具体的な要件を理解する前に。具体的な視点が、一般的なモデルが隠している必要となる詳細を明らかにすることが多い。
🔄 検証と精練プロセス
識別は一度きりの出来事ではない。ビジネスの現実と常に照らし合わせて検証が必要な反復プロセスである。
1. ステークホルダーとのウォークスルー
初期モデルをドメイン専門家に提示する。エンティティが彼らの現実を正確に反映しているか確認してもらう。関係性は認識できるか?重要なオブジェクトが欠けていないか?このフィードバックループにより、モデルがビジネスニーズに基づいた状態を保つことができる。
2. シナリオテスト
モデルを通じて特定のビジネスシナリオを実行する。複数のエンティティを含むレポートを生成する必要がある場合、関係性がそのクエリを効率的にサポートしているか確認する。モデルが複雑な結合や回避策を必要とする場合、エンティティ構造の調整が必要になる可能性がある。
3. 一貫性の確認
命名規則が一貫していることを確認する。たとえば、あるセクションで「User」」を使用している一方で、別のセクションで同じ概念に「Client」」を使用していると、混乱が生じる。ドメインモデル全体で用語を統一する。
4. バウンダリーの特定
システムの境界を定義する。一部のエンティティはソフトウェアシステムの外に存在するが、システムと相互作用する。これらを外部エンティティと呼ぶ。内部エンティティと外部エンティティを区別することで、依存関係や統合ポイントを効果的に管理できる。
📊 最良の実践の要約
高品質なモデリングを確保するため、識別フェーズ中に以下のチェックリストに従う。
- ✅ 技術的実装ではなく、ビジネスコンセプトに注目する。
- ✅ すべてのエンティティが明確な目的とライフサイクルを持っていることを確認する。
- ✅ エンティティの数を最小限に抑えて複雑性を低減する。
- ✅ 属性を確定する前に、関係性を検証する。
- ✅ 身分を持たないデータ型には値オブジェクトを使用する。
- ✅ 名前は説明的でドメイン固有のものにする。
- ✅ 要件の変化に応じて、モデルを反復的に見直す。
🚀 正確なモデリングの影響
現実世界のエンティティを正確に特定するための努力は、ソフトウェアライフサイクル全体にわたって利益をもたらす。正確なモデルは、後のリファクタリングの必要性を減らす。開発者とビジネスステークホルダー間のコミュニケーションを明確にする。データベース設計、API定義、ユーザーインターフェース構造をガイドするためのブループリントとして機能する。
エンティティが正しくモデル化されると、システムはより柔軟になります。新しい機能を追加する場合、全体の基盤を再構築するのではなく、既存のエンティティを修正する方が一般的です。この安定性により、技術的負債の影響を受けずに、組織は市場の変化に迅速に対応できます。
最終的には、ビジネスの真実を反映する生き生きとしたモデルを作ることが目的です。これには、忍耐、深い理解、明確さへのコミットメントが求められます。短絡的なアプローチを避け、厳密な分析手法を堅持することで、結果として得られるシステムは、時間と変化の試練に耐えることができます。
🔗 モデリングの旅の次のステップ
エンティティが特定されると、焦点はそれらの振る舞いや関係性の定義に移ります。これには、状態図、シーケンス図、クラス図の作成が含まれます。ここで特定されたエンティティは、これらの広範な図のノードとして機能します。前進する前にこれらがしっかりしていることを確認することで、設計フェーズでの連鎖的なエラーを防ぐことができます。
継続的な学習と適応は不可欠です。ビジネスドメインが進化するにつれて、モデルもそれに合わせて進化しなければなりません。定期的な見直しにより、識別プロセスが関連性を持ち、効果的であることが保証されます。この動的なアプローチにより、ソフトウェアソリューションは組織の目標と一貫性を保ち続けます。