











複雑な情報システムのアーキテクチャにおいて、データの整合性は信頼性の基盤である。データがプロセス、外部エンティティ、ストレージ場所の間を移動する際、静かに整合性の欠如が生じ、重大な障害、レポートエラー、セキュリティの損なわれることにつながる。データフローダイアグラム(DFD)は、情報がシステム内でどのように移動するかを理解するための視覚的設計図として機能する。しかし、図はその整合性を保証する能力に等しい。本ガイドは、詳細なDFD分析を通じてデータ整合性を検証する厳密なプロセスを検討し、システムに入力され、処理され、出力されるすべてのバイトが正確かつ信頼できる状態を保証する。
データ整合性は単なる技術的なチェックボックスではない。それは構造上の必須条件である。データ定義、変換、保存メカニズムが、システム設計のすべてのレイヤーで完全に整合していることを保証する必要がある。この整合性がなければ、プロセスは古くなったり誤った情報に基づいて動作する可能性がある。データの流れを分析することで、コードが1行も書かれる前から不整合を特定できる。このプロセスには、システムのダイナミクス、論理構造、およびさまざまなコンポーネント間の関係を深く理解する必要がある。
🛡️ システム設計におけるデータ整合性の理解
検証のメカニズムに深入りする前に、システム設計の文脈におけるデータ整合性の意味を定義することが不可欠である。それは「正しい」か「間違っている」かという二値の状態ではない。むしろ、同じ情報の異なる表現の間の整合性の度合いを示すスケールである。
📊 コアとなる柱の定義
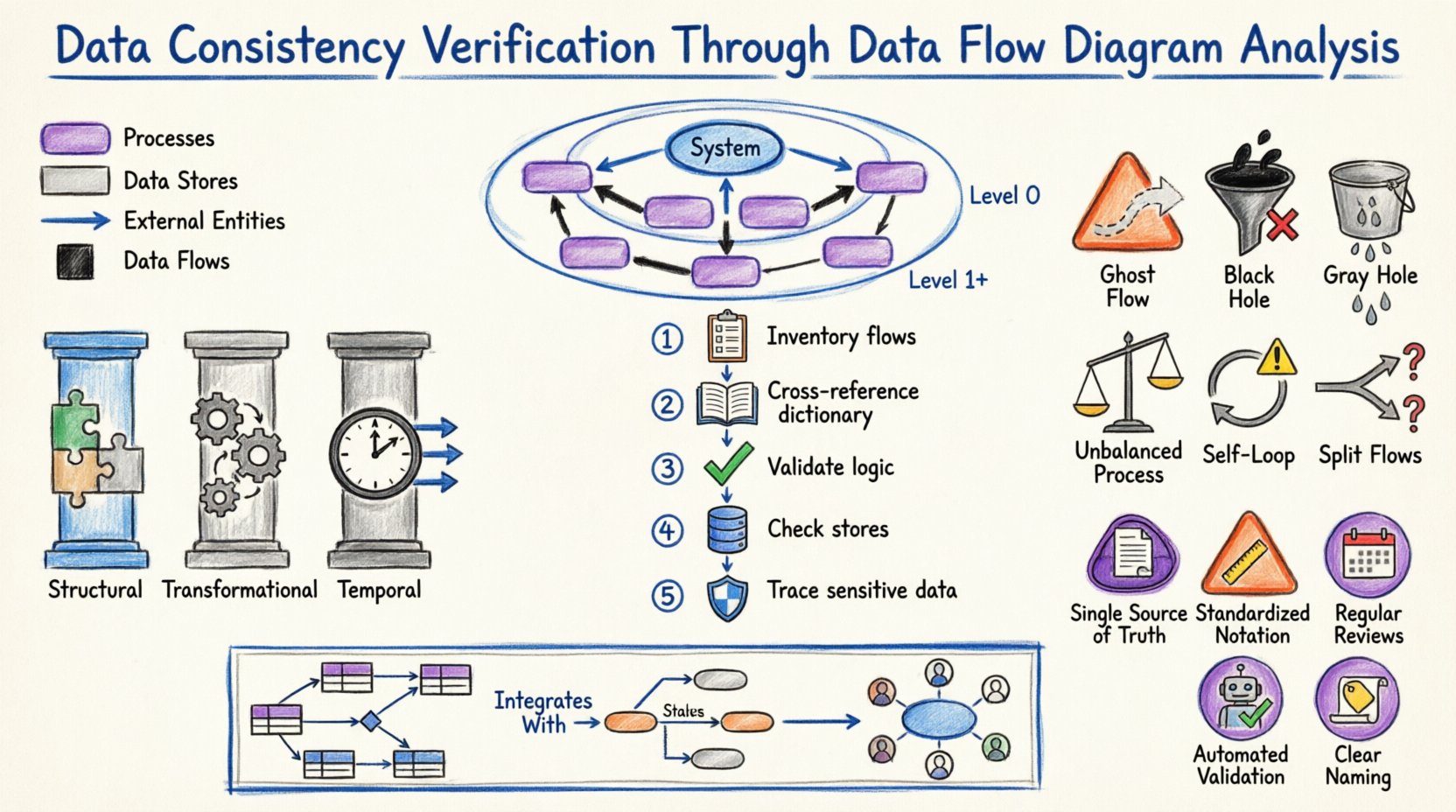
システム設計における整合性は、一般的に3つの主要なカテゴリに分類される:
- 構造的整合性: これはデータ構造の整合性を指す。プロセスが「顧客ID」を整数として期待している場合、そのIDを提供するデータストアは文字列を返してはならない。
- 変換的整合性: これは、処理中にデータに適用される論理が一貫して維持されることを保証する。入力が同一であれば、プロセスAで実行される計算とプロセスBで実行される類似の計算は、同じ結果をもたらすべきである。
- 時系列的整合性: これはデータ更新のタイミングに焦点を当てる。情報は必要なときに利用可能でなければならず、更新は競合状態や古くなった読み取りを引き起こさずにシステム全体に伝搬されなければならない。
DFDは、これらの柱を乗り越えるための地図を提供する。データの経路を追跡することで、これらの柱がどこで亀裂が生じるかを特定できる。たとえば、出力フローに対応しない入力フローがある場合、データは消失したことを意味し、構造的または論理的なエラーを示している。
🔄 DFDが整合性を確保する役割
データフローダイアグラムは単なる図面以上のものである。それは情報の移動を形式的に規定するものである。検証の文脈において、DFDは要件と実装の間の契約として機能する。データがどこから来ているか、どこへ向かっているか、どのように変化するかを規定する。
🔎 主要なコンポーネントとその影響
整合性を検証するには、各コンポーネントが果たす具体的な役割を理解する必要がある:
- 外部エンティティ: これらはシステム境界外のデータの発信元および受信先である。ここでの検証は、システムがユーザー、他のシステム、またはハードウェアデバイスからの入力を正しく解釈していることを確認することを含む。
- プロセス: これらは入力データを出力データに変換する。ここでの整合性チェックは、論理とデータ辞書の定義に焦点を当てる。プロセスは実際に記述された通りにデータを変更しているのか?
- データストア: これらはデータが一時的に保管されるリポジトリである。整合性は、スキーマがストアに入出するフローと一致していることを確認することを含む。異なるフォーマットを期待するストアにデータが書き込まれていないか?
- データフロー: これらはデータを運ぶパイプである。すべてのフローには明確な発信元と受信先が必要である。識別されていないフローは、整合性の欠如の主な原因となる。
📉 DFDのレベルと整合性チェック
DFDは通常、階層構造を持つ。高レベルの抽象から詳細な具体的な内容へと移行することで、段階的な検証が可能になる。各レベルには異なる種類の整合性チェックが必要となる。
🏁 コンテキストレベル(レベル0)
コンテキスト図は、システム全体を単一のプロセスとして表現する。外部エンティティとの相互作用を示す。このレベルでの検証は、「境界外部エンティティはすべてカウントされていますか?主要なデータ入力および出力はすべて境界を越えていますか?
コンテキストレベルのチェックリスト:
- システムを表すプロセスがちょうど1つありますか?
- すべての外部エンティティが正しくラベル付けされていますか?
- 境界を越えるすべてのデータフローは明確な定義を持っていますか?
🏗️ レベル0(トップレベルの分解)
この段階では、単一のプロセスが主要なサブプロセスに分解されます。ここがバランス調整が重要になります。サブプロセスの入力と出力の合計は、親コンテキストプロセスの入力と出力と等しくなければなりません。
コンテキスト図に「注文要求」という入力がある場合、レベル0の図では「注文要求」がトップレベルのプロセスの少なくとも1つに流入している必要があります。このデータが消えてしまう場合はブラックホール—重大な整合性エラーです。
🧩 レベル1以下(詳細な分解)
図がさらに分解されるにつれて、焦点は論理的フローに移ります。データフローはプロセスの粒度と一致していますか?まず保存すべきデータが、プロセス間で渡されているでしょうか?モジュール間に不要な結合があるでしょうか?
📝 ステップバイステップの検証プロトコル
整合性の確認は体系的な作業です。すべての詳細を見落とさないよう、体系的なアプローチが必要です。以下のプロトコルは分析の標準手順を示しています。
1️⃣ すべてのフローを一覧化する
まず、図に存在するすべてのデータフローをリストアップします。フロー名、送信元、受信先を含むマスターリストを作成します。この一覧は、以降のすべてのチェックの基準となります。
2️⃣ データ辞書と照合する
データ辞書は、すべてのデータ要素の構造、型、制約を定義します。DFD内の各データフローには、辞書に該当するエントリが存在しなければなりません。
- 名前を一致させる: 図上のフロー名が辞書の用語と正確に一致していることを確認する。
- 型を一致させる: データ型(例:文字列、整数、日付)が図と辞書の両方で一貫していることを確認する。
- 制約を一致させる: 検証ルール(例:「正の値でなければならない」)が一貫して適用されているか確認する。
3️⃣ プロセス論理の検証
各プロセスノードについて、変換ロジックを確認してください。入力に対して、プロセスがすべて期待される出力を生成しているか?論理的な原因がないのに出力が発生しているものはないか?このステップでは、プロセスに関連する疑似コードやビジネスルールを確認する必要があることが多いです。
4️⃣ データストアの整合性を確認する
データストアに入力されるすべてのデータフローは、そのストアのスキーマと一致している必要があります。逆に、ストアから出力されるすべてのフローは、実際にそのストア内に存在するデータを表している必要があります。読み取りと書き込み操作がバランスしていることを確認してください。
5️⃣ 敏感データの経路を追跡する
機密情報(PII、財務データなど)を含むフローを特定してください。整合性チェックにセキュリティプロトコルが含まれていることを確認してください。データがソースで暗号化されている場合、宛先で復号されているか?セキュアであるべきなのに暗号化されていないフローは存在しないか?
⚠️ 一般的な不整合とパターン
慎重な計画を立てても、不整合が少しずつ入り込むことがあります。一般的なエラーのパターンを認識することで、分析時に迅速に検出が可能になります。以下の表は、頻発する問題とその影響を概説しています。
| パターン名 | 説明 | 整合性への影響 |
|---|---|---|
| ゴーストフロー | ソースもしくは宛先のないデータフロー。 | データの連続性を破壊する;システムエラーを引き起こす。 |
| ブラックホール | 入力はあるが、出力がないプロセス。 | データが失われる;システムの状態が定義不能になる。 |
| グレイホール | 出力が入力の合計より少ない、またはロジックがすべての入力を考慮していないプロセス。 | 部分的なデータ損失または誤った集計。 |
| アンバランスプロセス | 子プロセスの入力/出力が、分解対象の親プロセスと異なる。 | 階層構造が崩れる;要件を満たさない。 |
| セルフループデータ | データストアを経由せずに、同じプロセスに戻るデータフロー。 | 無限ループや状態管理の欠如を示す。 |
| スプリットフロー | 決定ノードなしにデータが複数の経路に分岐する。 | ルーティングが不明瞭;データの重複が発生する可能性がある。 |
🔗 データ辞書の統合
データ辞書は、データ定義の唯一の真実の源です。辞書がなければ、DFDは曖昧になります。このリポジトリと図面を照合せずに検証を行うことは不完全です。
📋 同期要件
DFDが更新された場合、データ辞書も同時に更新されなければならない。ここでの不一致は一貫性の欠如の一形態である。たとえば、フィールドが辞書内で「User_Name」から「Username」に名前が変更された場合、DFDも即座にこの変更を反映しなければならない。これを行わないと、設計書と実装仕様の間に乖離が生じる。
📌 メタデータの一貫性
名前や型を超えて、メタデータは一貫性を保たなければならない。これには以下が含まれる:
- 測定単位:通貨はUSDかEURか?重量はkgかlbsか?このデータを含むすべてのフローにおいて一貫性が保たれなければならない。
- エンコーディング規格:テキストはUTF-8かASCIIでエンコードされているか?エンコーディングの不一致はデータ破損を引き起こす。
- タイムゾーン:システムは時刻をUTCで保存するか、ローカルタイムで保存するか?タイムスタンプを含むフローは標準に合意しなければならない。
🧭 論理的整合性と物理的整合性
よくある落とし穴は、論理的設計と物理的設計を混同することである。論理的DFDは、システムが何をするかを示すのに対し、物理的DFDはシステムがそれをどう行うかを示す。整合性の検証は、これらを区別しなければならない。
🧱 論理的整合性
これはビジネスルールとデータ整合性に注目する。フローはビジネス視点から意味があるか?たとえば、支払い承認前に注文を出荷できるか?論理的整合性は技術を無視し、価値の流れに注目する。
💻 物理的整合性
これは技術的制約に注目する。データフローはネットワークプロトコルと一致しているか?データフォーマットはデータベースエンジンと互換性があるか?物理的整合性の欠如はビジネスロジックを破壊しないかもしれないが、デプロイ時にシステム障害を引き起こす。
🔄 差を埋める
論理から物理へ移行する際、新しいフローがしばしば現れる(例:エラーログ、監査トレース)。これらは整合性を保つために図に追加されなければならない。物理的実装が論理図で考慮されていなかったステップを追加した場合、論理図は現実と整合しなくなる。
🔎 エンティティ関係モデルとの照合
DFDは移動を記述するのに対し、エンティティ関係図(ERD)は構造を記述する。完全な整合性を確保するため、これら2つの図は一致している必要がある。
🗺️ マッピング作業
DFD内のすべてのデータストアに対して、ERDに対応するエンティティセットが存在するべきである。すべてのデータフローに対しては、その移動を正当化する関係または属性が存在するべきである。
- 基数チェック:DFDがプロセスへの多対一のフローを示している場合、ERDは対応する関係の基数を反映しているべきである。
- キーの一貫性:ERDでレコードを識別するために使用される主キーは、データフローでそれらのレコードを参照するために使用されるキーと同一でなければならない。
ここでの不一致は、実行時においてパフォーマンスのボトルネックや参照整合性の違反を引き起こすことがよくあります。厳密なレビューでは、データストアのスキーマをERDのエンティティと比較します。
🛠️ メンテナンスとライフサイクル管理
一貫性は一度きりの成果物ではありません。システムのライフサイクル全体にわたって維持されなければならない継続的な状態です。要件が変化するたびに、図は進化しなければなりません。
📂 図のバージョン管理
コードがバージョン管理を必要とするのと同じように、DFDもそれが必要です。図の変更は追跡されるべきです。これにより、チームは一貫性が破られたか復元されたかの時期と理由を監査できます。DFDのすべての更新には変更ログを添付するべきです。
🔄 リグレッションテスト
図が更新された際には、一貫性チェックを再実行すべきです。これはソフトウェア開発におけるリグレッションテストに似ています。新しいフローがブラックホールを導入したでしょうか?新しいプロセスが親コンテキストとのバランスを崩しましたか?自動化ツールはこの作業を支援できますが、複雑な論理については手動でのレビューがしばしば必要です。
👥 ステークホルダーの整合
一貫性は人間にも関係します。ビジネス上のステークホルダーはデータ定義について合意する必要があります。ビジネスが「アクティブユーザー」を先週ログインした人として定義している一方で、技術チームが先月ログインした人として定義している場合、DFDは技術的な定義を反映するため、ビジネスレポートに誤りが生じます。定期的な整合会議は不可欠です。
📈 オーディットトレールとトレーサビリティ
規制業界では、トレーサビリティは法的義務です。データのすべての要素は、その出所から最終的な到達地点まで追跡可能でなければなりません。DFDはこのトレーサビリティを確立する主なツールです。
🔖 フローのタグ付け
各データフローは、その出所と目的を示すメタデータでタグ付けされるべきです。これにより監査が容易になります。データ漏洩が発生した場合、分析者は図上でフローをたどることで、脆弱性が存在した可能性のある場所を特定できます。
🔗 インパクト分析
データストアへの変更が提案された場合、DFDを用いてインパクト分析が可能です。そのストアに接続されたフローをたどることで、影響を受けるすべてのプロセスを特定できます。これにより、単独での変更によって意図しない不整合が生じるのを防ぎます。
🎯 メンテナンスのベストプラクティス
時間の経過にわたって一貫性を維持するためには、以下のベストプラクティスに従いましょう:
- 単一の真実のソース:DFD用のマスターリポジトリを1つだけ維持してください。異なる場所に複数のバージョンが存在することを許してはいけません。
- 標準化された記法:文書全体にわたって一貫した記法(例:Gane & Sarson、またはYourdon & Coad)を使用してください。記法を混在させると混乱を招きます。
- 定期的なレビュー:DFDを現在のシステム状態と照らし合わせて、四半期ごとにレビューをスケジュールしてください。システムは時間とともにずれが生じます。図はそれに追いつく必要があります。
- 自動検証:可能な限り、一貫性ルールを自動的に検証するモデル化ツールを使用してください(例:アンバランスなプロセスの防止)。
- 明確な命名規則:プロセスおよびフローに対して厳格な命名規則を採用してください。曖昧な名前は不整合の温床です。
🌐 他の手法との統合
DFDは空洞に存在するものではありません。設計資産のより大きなエコシステムの一部です。
📋 状態遷移図
DFDはデータの移動を示す一方で、状態遷移図は状態の変化を示す。状態変化を引き起こすデータフローが、状態図で定義された条件と一致していることを確認する。例えば「ログイン試行」のフローが状態変化を引き起こす場合、両方の図で論理が一貫している必要がある。
📊 ユースケース図
ユースケースはユーザー視点からの相互作用を記述する。DFDは内部的なメカニズムを記述する。すべてのユースケースは、DFD内の少なくとも1つのプロセスに対応しなければならない。対応するプロセスがないユースケースがある場合、要件は満たされていない。プロセスにユースケースがない場合、それは無駄なコードである可能性がある。
🏁 検証についてのまとめ
DFD分析を通じてデータの一貫性を確保することは、忍耐と細部への注意を要する専門的作業である。バグを発見することではなく、堅牢な基盤を構築することにある。バランスの確認、辞書の相互参照、論理的視点と物理的視点の整合性を維持することで、システムアナリストは生産環境に問題が発生する前に誤りを防ぐことができる。
この検証に費やされた努力は、システムの安定性向上と保守コストの削減という成果をもたらす。一貫性のある設計とは、自らのデータを理解している設計である。システムの複雑さが増すにつれ、明確で一貫した図への依存が混沌を防ぐ主要な防御手段となる。これらの原則を守ることで、情報の流れがビジネスロジックの駆動力と同等に信頼性を保つことができる。