











正確なデータフローダイアグラムを作成することは、堅牢なシステム分析の基盤です。プロジェクト納品が引渡しフェーズに近づくと、これらの図の整合性が最終システムの明確さを左右します。適切に構築されたDFDは、開発者にとって設計図となり、ステークホルダー間のコミュニケーションツールとなり、テスト担当者にとって検証用のアーティファクトとなります。厳密なレビュー確認事項がなければ、曖昧さが開発サイクルに潜り込み、高コストの再作業を招くことになります。本ガイドは、データフローダイアグラムがプロフェッショナルな基準を満たすことを保証するための必須検証手順を概説しています。
本ドキュメントはDFDの技術的検証に焦点を当てます。構造的整合性、論理的一貫性、およびビジネス要件との整合性をカバーしています。これらの確認事項に従うことで、基盤となる技術スタックにかかわらず、情報の流れが入力から出力まで正確に保たれることをチームは確実にできます。
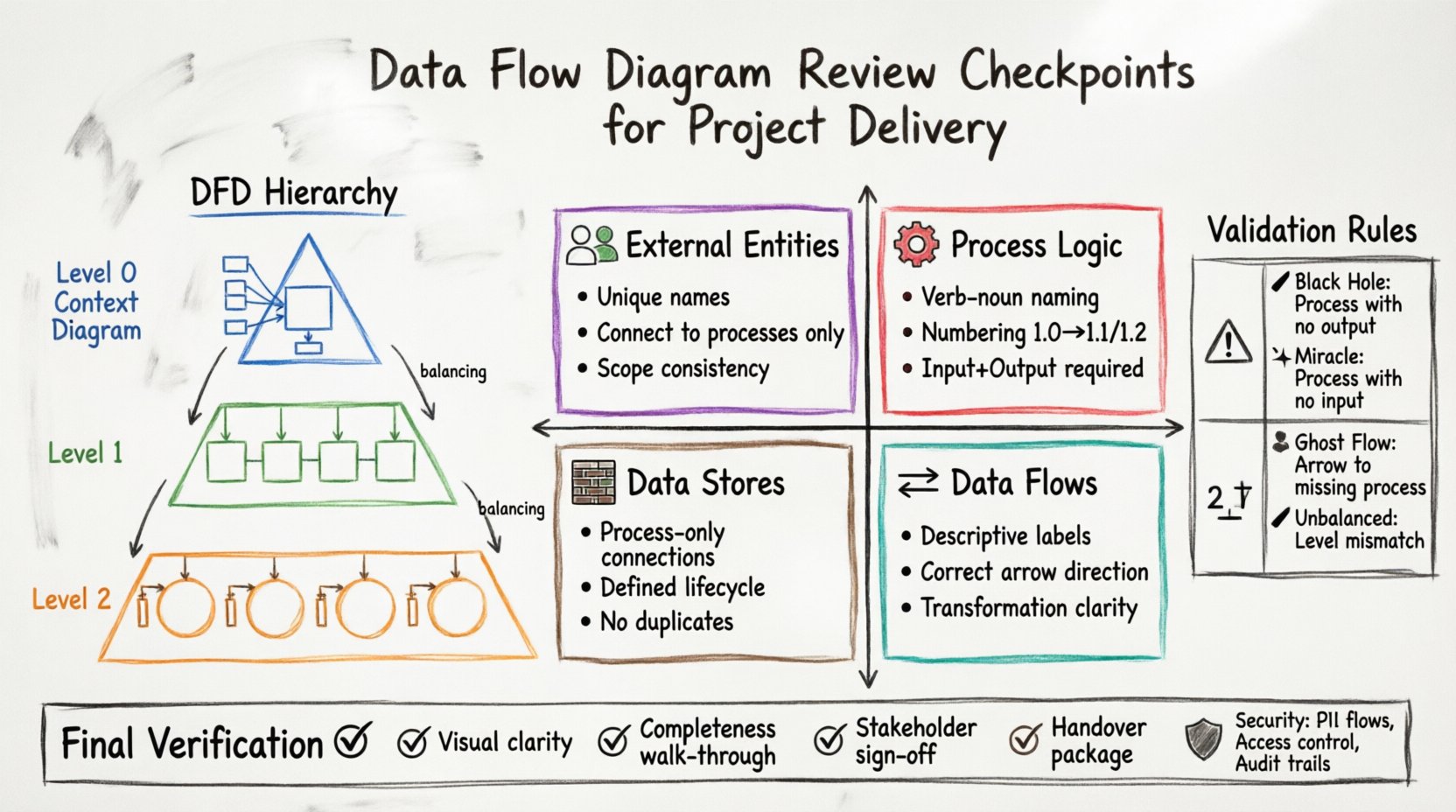
DFDの階層構造を理解する 📚
レビューを開始する前に、図示プロセスで使用される抽象度のレベルを理解することが不可欠です。単一のドキュメントでシステム全体を捉えることはめったにありません。代わりに、図の階層構造が通常採用されます。
-
コンテキスト図(レベル0): これはシステム境界の高レベルな視点を提供します。システムを外部エントリと相互作用する単一のプロセスとして示します。スコープを定義します。
-
レベル1図: これは単一のプロセスを主要なサブプロセスに分解します。これらの機能間の主要なデータ移動を詳細に示します。
-
レベル2図: これは特定のレベル1プロセスをさらに分解します。データ処理ロジックに関する詳細な情報を提供します。
各レベルは、上位のレベルと整合性を保たなければなりません。この概念は「バランス」と呼ばれ、詳細に掘り下げていく際に入力や出力が任意に変化しないことを保証します。
コアレビュー確認事項 🔍
成功したレビューは、構造化されたチェックリストに依存します。以下の領域には特に注意を払い、図がシステム設計を正確に反映していることを確認する必要があります。
1. 外部エントリの検証 👥
外部エントリは、システム境界外のデータの発生源または到着先を表します。これらはシステム自体の一部ではなく、システムと相互作用します。
-
識別: すべての外部エントリに明確で一意の名前があることを確認してください。「ユーザー」などの汎用ラベルは避け、具体的な役割を示すようにしてください。「ユーザー」 と明記せずに使用しないでください。代わりに「登録済み顧客」や「請求システム」などの具体的な役割を使用してください。「登録済み顧客」 または 「請求システム」.
-
接続性: エントリがプロセスにのみ接続されており、他のエントリやデータストアに直接接続されていないことを確認してください。これにより、表記法の構造的ルールが維持されます。
-
スコープ: コンテキスト図に記載されているエントリが、レベル1図と一致していることを確認してください。レベル1図にコンテキスト図に存在しなかった新しいエントリが現れた場合、スコープが変更されたことになります。
2. プロセス論理と番号付け ⚙️
プロセスはデータを変換します。これらは図のアクティブな構成要素です。
-
命名規則: 名前は動詞+名詞の構造に従わなければなりません。例として “税額を計算する” または “レポートを生成する” 。名詞のみの名前(例:“税額計算”)は避けましょう。これは動作ではなく状態を表しているためです。
-
番号付け: 厳密な番号付け方式を維持してください。プロセスが1.0とラベル付けされている場合、その子プロセスは1.1、1.2などと順次番号を付ける必要があります。これによりドキュメントの相互参照が容易になります。
-
完全性: すべてのプロセスには少なくとも1つの入力と1つの出力が必要です。出力のないプロセスは到達不能な終点となり、入力のないプロセスはソース(発生源)となり、通常は外部エンティティであるべきです。
3. データフローの方向性 🔄
データフローは情報の移動を表します。これらはコンポーネントをつなぐ矢印です。
-
ラベル: すべてのフローには、内容を示す説明的なラベルが必要です。“データ” という表現の代わりに、“注文詳細” または “支払い確認”.
-
方向: 矢印の方向が正しいことを確認してください。データはソースから宛先へと流れなければなりません。クエリ・レスポンスのペアを明示的に表す場合を除き、双方向の矢印は一般的に避けます。
-
一貫性: プロセスへの入力のデータラベルと、そのプロセスからの出力のデータラベルは、変換が行われない場合、一致している必要があります。変換が行われる場合は、ラベルが変化を反映するようにしてください(例:“未処理注文” 入力:“処理済み注文” 出力)。
4. データストア管理 🗃️
データストアは情報が保管されるリポジトリです。これらは受動的なコンポーネントです。
-
読み取り/書き込みアクセス:データストアはプロセスにのみ接続されるべきです。外部エンティティに直接接続してはいけません。データがエンティティからストアへ移動する場合、論理処理を行うプロセスを経由しなければなりません。
-
ストレージ論理:すべてのデータストアに明確なライフサイクルがあることを確認してください。一時的か永続的か?アーカイブが必要か?図はストレージへのデータ流入と流出の流れを反映している必要があります。
-
一意性:データストアは不必要に重複してはいけません。2つのプロセスが同じ情報をアクセスする場合、同じストアエンティティを参照すべきです。
検証ルールとバランス調整 ⚖️
検証は図の階層構造全体における論理的一貫性を保証します。これはしばしばレビューの最も重要な段階です。
フローの保存則
すべてのレベル間で入力と出力のフローの合計が保存されなければなりません。レベル0の図で入力が「顧客要求」」と表示されている場合、その入力はレベル1の図において対応するサブプロセスへの入力として現れなければなりません。分解の過程でデータフローを生成したり消去したりしてはいけません。
バランスチェック
このルールは、親プロセスの入力と出力が、その子プロセスの入力と出力の合計と一致しなければならないことを規定しています。レベル1のプロセスが「請求書」」を出力する場合、そのレベル1プロセスを構成するレベル2プロセスは、 collectively 「請求書」.
|
ルール |
説明 |
違反例 |
|---|---|---|
|
ブラックホール |
出力のないプロセス。 |
データを受け取るが、どこにも送らないプロセス。 |
|
ミラクル |
入力のないプロセス。 |
何らのトリガーや情報を受け取らずにデータを生成するプロセス。 |
|
ゴーストフロー |
存在しないプロセスに接続されているフロー。 |
矢印が削除されたか名前が変更されたプロセスを指している。 |
|
バランスの取れていないフロー |
レベル間で入力/出力が一致していない。 |
レベル1ではレベル0が考慮していない出力が示されている。 |
一般的な図式エラー ⚠️
経験豊富なアナリストはしばしば繰り返される誤りに気づく。これらの落とし穴に注意することで、レビューのプロセスをスムーズにすることができる。
-
制御フローとデータフローの違い:データの流れと制御の流れを混同する。DFDは制御信号ではなくデータの流れを追跡する。信号がプロセスをトリガーするがデータが移動しない場合は、データフローとして表現してはならない。
-
過剰設計:高レベルの図にあまり詳細を含めること。レベル0とレベル1は主要な機能に焦点を当てるべきである。詳細な論理はレベル2または別個の論理仕様に記載すべきである。
-
データベースの誤解:データベーステーブルをプロセスとして扱うこと。テーブルはデータの保管場所である。クエリがプロセスである。データベースのアイコンを関数を表す円として描いてはならない。
-
ループ:whileループはコードでは一般的だが、DFDは一般的に線形の流れを表す。プロセスが自分自身に戻る場合、直接的なフローループではなく、明確なデータストアとのやり取りであることを確認する。
ステークホルダーとの整合 🤝
図は単なる技術的成果物ではない。それはコミュニケーションツールである。レビューにはステークホルダーの理解との整合性を確認するプロセスを含めるべきである。
-
ビジネス用語: 図で使用するラベルがビジネスユーザーが使用する用語と一致していることを確認する。ビジネスがそれを「クライアント」 と呼んでいるのに、図では「ユーザー」と表示している場合、混乱が生じる。
-
ワークフローの現実: 図は実際に仕事がどのように行われているかを反映しているか? ときにはビジネスプロセスは非公式であるが、図は公式である。レビューでは理想プロセスと文書化されたプロセスの間のギャップを特定すべきである。
-
承認基準: 承認の基準を明確に定義する。ビジネス側が「はい」と言うだけで十分か? それとも技術チームが論理が実装可能であることを確認する必要があるのか?「はい」?
要件との統合 🧩
DFDは機能要件文書と整合している必要があります。ここでの不整合は、分析に穴があることを示唆しています。
-
トレーサビリティ: DFD内の各プロセスは、特定の要件に対応する必要があります。プロセスに該当する要件がない場合、範囲の拡大(スコープクリープ)の可能性があります。逆に、要件に対応するプロセスがない場合は、見落としの可能性があります。
-
データ辞書の整合性: 図面を通過するデータ要素は、データ辞書内の定義と一致している必要があります。フィールド長、データ型、必須項目を確認してください。
-
非機能要件: DFDは主に機能的ですが、パフォーマンスやセキュリティ要件も記録できます。たとえば、機密データを含むフローは暗号化が必要であり、これはフロー自体の制約となります。
セキュリティおよびコンプライアンスの考慮事項 🛡️
現代のプロジェクト納品では、セキュリティは後から考えるものではありません。データフローに明確に可視化される必要があります。
-
データの機密性: 個人識別情報(PII)または財務データを含むフローを特定してください。これらのフローは、実装時にセキュリティプロトコルが適用されるよう、マークまたは注釈を付ける必要があります。
-
アクセス制御: 特定のデータストアにアクセスできる外部エンティティを特定してください。DFDは通常、権限を明示的に示しませんが、接続関係がアクセスを示唆しています。不正なエンティティが機密ストアに接続しないようにしてください。
-
監査トレース: データの変更を伴うフローは、ログが生成される場所を明示することが望ましいです。図面は、監査データが別途のストアに送信される場所を示す必要があります。
ドキュメント化とバージョン管理 📝
レビュー過程でドキュメントが生成されます。これを適切に管理する必要があります。
-
バージョン管理: 図面のすべての改訂はバージョン管理する必要があります。変更は追跡するべきです。フローが削除された場合は、その理由を記録する必要があります。これにより開発フェーズでの混乱を防ぎます。
-
変更ログ: レビュー結果のすべてを記録したログを維持してください。誰が問題を提起したか、深刻度、解決状況を記録します。これにより、プロジェクト納品の監査トレースが可能になります。
-
メタデータ: 図面自体にメタデータを含める必要があります。これには、作成者、レビュー日、バージョン番号、ステータス(下書き、レビュー中、承認済み)が含まれます。
最終検証ステップ ✅
プロジェクトが次のフェーズに移行する前に、アーティファクトを最終確認してください。
-
視覚的明確性: 図面は読みやすいですか?可能な限り線の交差を避けてください。線に直角(正交性)を使用することで、読みやすさが向上します。関連するプロセスはまとめて配置してください。
-
完全性確認: 図面を開始から終了まで確認してください。すべての外部エンティティがデータストアへ、そして出力へ戻るパスを持っていることを確認してください。死んだ道(デッドエンド)があってはなりません。
-
ステークホルダーによる確認: 主なステークホルダーと最終的な確認作業を行います。図がシステムの動作を正しい物語として伝えているか確認してください。
-
引継ぎパッケージ: 図面、レビュー確認リスト、要件トレーサビリティマトリクスを1つのパッケージにまとめ、開発チームに渡します。
図面品質が低い影響 📉
これらのチェックポイントを飛ばすと大きなリスクがあります。不正確なDFDは次の結果を招きます:
-
開発の遅延: 開発者は、本来明確であるべき論理の説明に時間を費やすことになります。
-
予算超過: サイクルの後半に発見された論理エラーを修正するために再作業が必要になる。
-
システムの穴: 文書化されていないが想定されていた機能が実装されない。
-
保守の地獄: 将来のチームは、図面がコードと一致していないためシステムを理解できなくなる。
レビューの規律についての結論 📋
データフローダイアグラムの徹底的なレビューを行うことは、プロジェクトライフサイクル全体に利益をもたらす規律です。細部への注意、表記規則への準拠、ステークホルダーとの継続的なコミュニケーションが求められます。このガイドで示されたチェックポイントに従うことで、チームはシステムアーキテクチャの健全性、データフローの論理性、プロジェクトの納品が計画通りに進むことを確保できます。分析段階での正確さは、構築段階での不確実性を低減します。
図面は動的な文書であることを思い出してください。要件が進化するにつれて、DFDもそれに合わせて進化しなければなりません。分析フェーズの終わりにレビューを行うだけでなく、定期的なレビューをスケジュールするべきです。この継続的な検証により、プロジェクトがビジネス目標と一致した状態を保つことができます。
これらの基準にコミットしてください。これらは信頼性の高いシステム分析と成功裏なプロジェクト納品の基盤を成しています。