











複雑な分散システムを設計するには、コードを書くこと以上に、ステークホルダーが理解できる明確な視覚的言語が必要です。🏗️ データフローダイアグラム(DFD)はそのような言語として機能し、情報が異なるノード、サービス、ストレージユニットをどのように移動するかをマッピングします。分散環境に適用された場合、DFDは実装の前にボトルネック、セキュリティリスク、整合性の課題を特定するための重要なツールになります。
このガイドでは、効果的な分散システムモデルを作成するための手法について探求します。中心となる構成要素、分解プロセス、データがネットワーク境界を越える際の特定の考慮事項を検討します。確立されたモデリング手法に従うことで、チームはアーキテクチャがスケーラビリティと信頼性をサポートすることを確保できます。
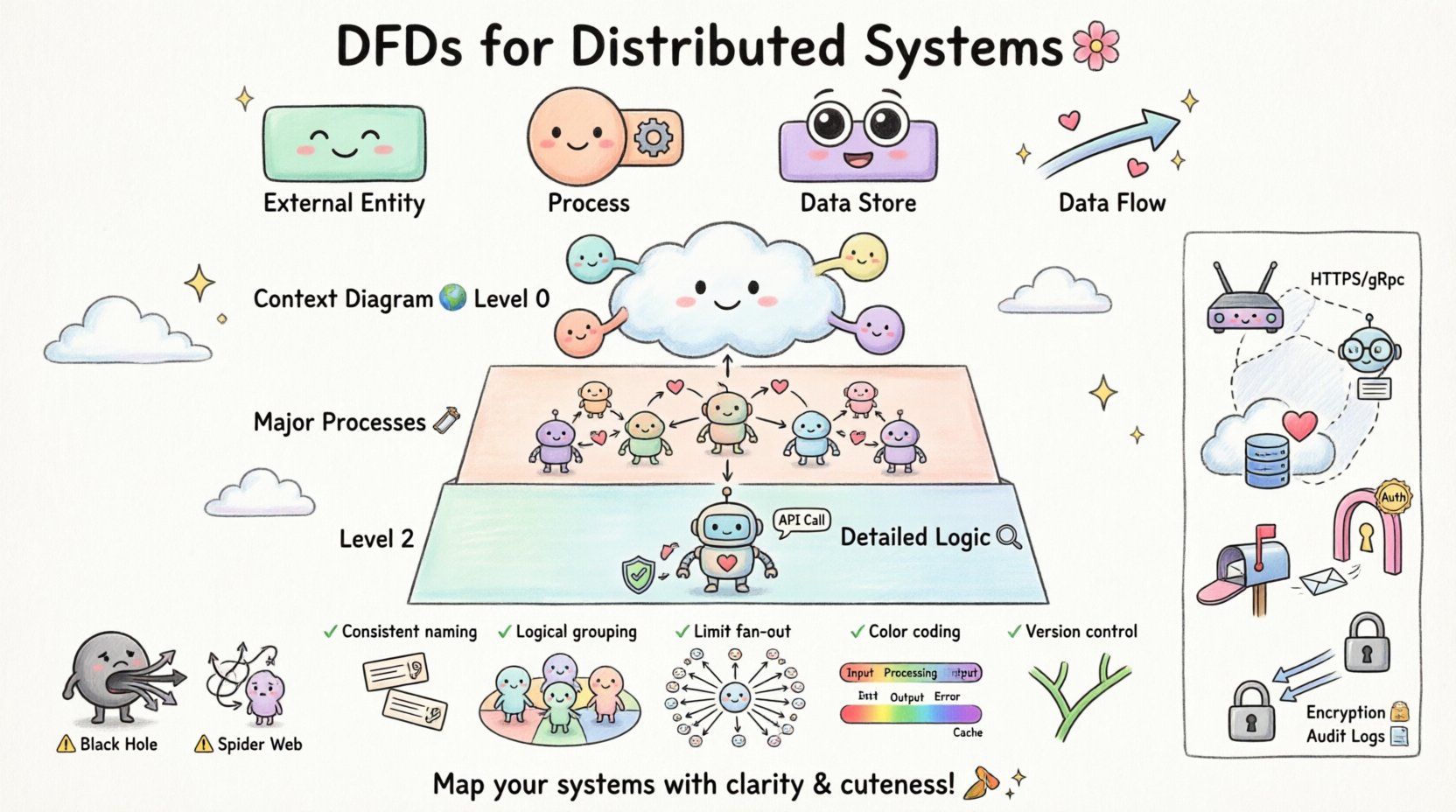
🌐 分散システムの文脈を理解する
分散システムは、複数の自律的なコンピュータから構成され、ユーザーにとっては単一の整合性のあるシステムとして見えるものです。モノリシックアーキテクチャとは異なり、これらの環境では通信、状態管理、障害モードに関する複雑さが生じます。🚀 こうしたシステムをモデリングするには、内部のプロセス論理から外部の通信経路へと視点を変える必要があります。
- ネットワーク境界:データはしばしば物理的または論理的なネットワークを越え、遅延や障害の潜在的要因をもたらします。
- サービスの粒度:システムは、それぞれ特定の責任を担うより小さなサービスに分割されます。
- 無状態性対状態性:一部のコンポーネントは履歴を保持せずにリクエストを処理する一方、他のコンポーネントは永続的なデータを管理します。
- 非同期通信:多くの分散型相互作用は、直接的な同期呼び出しではなくメッセージキューに依存しています。
明確なマップがなければ、チームはデータフローが不明瞭な「スパゲッティアーキテクチャ」を作成するリスクがあります。適切に構成されたDFDはこれらの相互作用を明確にし、すべてのデータポイントが明確な発信元と受信先を持つことを保証します。
🔍 データフローダイアグラムがシステム設計における役割
データフローダイアグラムは、情報システム内を流れるデータの流れを図式的に表現したものです。タイミングや制御論理は示されませんが、データがシステムに入り、変換され、移動し、システムから出る仕組みにのみ焦点を当てます。🧭
分散環境では、DFDは以下の点を可視化するのに役立ちます:
- データが発生する場所(外部エンティティ)。
- どのように処理されるか(プロセス)。
- 一時的または永続的に保存される場所(データストア)。
- コンポーネント間をどのように移動するか(データフロー)。
DFDを使用することで、アーキテクトは提案されたアーキテクチャに対して要件を検証できます。データが正当な理由なく作成されたり破棄されたりしないことを保証し、ライフサイクル全体にわたって整合性を維持します。
DFDの核心的な構成要素
有効なモデルを構築するには、標準表記で使用される4つの主要な記号を理解する必要があります。それぞれが図式表現において異なる目的を果たします。
| コンポーネント | 機能 | 視覚的表現 |
|---|---|---|
| 外部エンティティ | システム境界外のデータの発信元または受信先。 | 長方形 |
| プロセス | 入力から出力へのデータの変換。 | 円またはラウンドされた長方形 |
| データストア | 後で使用するためにデータが保持される場所。 | 開かれた長方形または平行線 |
| データフロー | コンポーネント間でのデータの移動。 | 矢印 |
分散システムをモデル化する際、矢印にデータの内容を表す名詞句を記載することが重要であり、動詞ではなくする。たとえば、「送信中の資格情報」ではなく「ユーザー資格情報」を使用する。
📉 DFDの分解レベル
複雑なシステムは1つのビューでは表現できない。分解により、高レベルの概要から詳細な部分まで掘り下げることができる。このアプローチにより、読者の認知的負荷を防ぐことができる。
レベル0:コンテキスト図
コンテキスト図は、最も高いレベルの抽象化を提供する。システム全体を単一のプロセスとして示し、それと相互作用するすべての外部エンティティを特定する。🌍
- 範囲: システムの境界を定義する。
- 相互作用: 外部世界からのすべての入力と出力を示す。
- 明確さ: ステークホルダーが技術的な詳細なしにシステムの目的を理解するのを助ける。
レベル1:主要プロセス
レベル1では、コンテキスト図の単一のプロセスを主要なサブプロセスに拡張する。このレベルでは、機能に基づいてシステムを論理的な部分に分割する。🛠️
- 分解: システムを5〜9つの主要プロセスに分割する。
- フロー: これらの主要プロセス間でデータがどのように移動するかを示す。
- ストア: これらのプロセスを支援するデータストアを導入する。
レベル2以降:詳細な論理
レベル2では、特定のサブプロセスがさらに分解される。ここでは、特定の検証ルールやAPI呼び出しといった実装の詳細が現れ始めることが多い。🔍
分散型モデリングでは、レベル2の図はサービス境界を定義するのに特に役立ちます。どのプロセスがどのサービスノードに配置されるべきかを特定するのに役立ちます。
⚡ 分散環境のモデリング
標準的なDFDはしばしばモノリシックな環境を前提としています。分散システムに適応させる際には、ネットワークの現実を反映するために特定の記法と考慮事項を適用しなければなりません。🌐
以下は、標準的モデリングと分散型モデリングの要素の比較です:
| 要素 | 標準的モデリング | 分散型モデリング |
|---|---|---|
| データフロー | 直接的な論理フロー。 | ネットワーク送信、遅延、プロトコル。 |
| プロセス | 単一の計算ユニット。 | マイクロサービス、コンテナ、またはサーバーレス関数。 |
| データストア | ローカルデータベース。 | クラウドストレージ、分散キャッシュ、またはシャーデッドDB。 |
| 境界 | システム境界。 | ネットワーク境界、信頼ゾーン、またはAPIゲートウェイ。 |
異なるノード内のプロセス間のデータフローを描く際には、トランスポートメカニズム(例:HTTPS、gRPC、メッセージキュー)をフローに注釈を付けると便利です。これにより、パフォーマンスおよびセキュリティ要件に関する文脈が追加されます。
🛡️ 同時実行と状態の扱い
分散システムは頻繁に同時リクエストを処理します。静的なDFDはタイミングを明示的に示さないことがあるかもしれませんが、これらの相互作用中に状態がどのように管理されるかを示す必要があります。⏳
- 状態なしプロセス: プロセスが状態を保持しない場合、DFDはその特定のトランザクションにおいて、データがストアに戻らずに通過して出力されることを示す必要があります。
- 状態保持プロセス: プロセスが状態を保持する場合、その情報を永続化するデータストアへの明確なデータフローが存在しなければなりません。
- 整合性: 更新を表すデータフローは、ノード間で整合性がどのように維持されるかを示す必要があります。
たとえば、ショッピングカートをモデリングする場合、DFDは「カートデータ」がユーザー実体からカートサービスへ、そしてデータベースストアへと流れることを示す必要があります。カートサービスが分散されている場合、フローはデータの権威あるコピーを保持しているノードを示す必要があります。
🚫 分散型モデリングにおける一般的な落とし穴
経験豊富なアーキテクトでさえ、分散データフローを可視化する際に誤りを犯すことがあります。こうした一般的な誤りに気づくことで、モデルの品質を向上させることができます。 🚧
| 落とし穴 | 影響 | 修正 |
|---|---|---|
| ブラックホールプロセス | データはプロセスに入りますが、決して出て行きません。 | すべての入力に対して、対応する出力または保存先があることを確認してください。 |
| グレイホールプロセス | 出力は存在しますが、それらを説明する入力がありません。 | すべての出力フローについて、そのデータソースを確認してください。 |
| 蜘蛛の巣 | 交差する線が多すぎて混乱を招きます。 | 関連するフローをグループ化するためにサブプロセスを使用してください。 |
| ネットワーク無視 | 遅延や障害ポイントを無視している。 | フローにプロトコルや信頼性に関するメモを付記してください。 |
プロセスを介さずにデータストア同士に直接接続を描かないようにしてください。データストアは、データの検証および変換を行うプロセスを介してのみ相互に通信すべきです。これにより、不正な直接アクセスを防ぎ、ビジネスロジックが適用されることを保証します。
📝 明確性のためのベストプラクティス
正確かつ読みやすい図を作成するには、特定の設計原則に従う必要があります。 🎨
- 一貫した命名:すべての図において、同じデータに対して同じ用語を使用してください。レベル0で「User ID」と使用している場合、レベル1では「Customer Key」とは呼びません。
- 論理的グループ化:関連するプロセスを視覚的にまとめてください。これにより、サービス境界を明確にできます。
- ファンアウトの制限:単一のプロセスが10本以上のデータフローに接続されないようにしてください。もしそうなったら、プロセスを分解してください。
- 色分け:色を使って内部プロセス、外部エンティティ、データストアを区別してください。これにより、素早く確認できます。
- バージョン管理:図をコードのように扱ってください。変更履歴を追跡できるように、バージョン管理に保存してください。
分散システムのモデル化を行う際には、異なる信頼ゾーンやネットワークセグメントを表すためにスイムレーンを使用することを検討してください。これにより、どのコンポーネントがパブリック向けであるか、内部向けであるかがすぐにわかります。
🔒 セキュリティの考慮事項の統合
セキュリティは後から考えるものではなく、機能性と並行してモデル化されるべきである。🔐 データフローダイアグラムは、設計段階の初期にセキュリティリスクを特定するユニークな機会を提供する。
- 認証ポイント:ユーザー資格情報が検証される場所をマークする。これは通常、外部エンティティと最初のプロセスの境界で発生する。
- データ暗号化:機密データの流れが暗号化される場所を示す。矢印上に「暗号化チャネル」などのラベルを使用する。
- アクセス制御:どのプロセスが特定のデータストアにアクセスする権限を持っているかを示す。
- ログ記録:監査ログを別途のログストアに送信するフローを含める。これによりトレーサビリティが確保される。
これらのセキュリティフローを明示的にモデル化することで、チームは実装段階で暗号化や認証が忘れられることを防ぐことができる。また、データプライバシーおよびコンプライアンス要件についての議論を促進する。
🔄 メンテナンスと進化
システムは進化する。要件は変化し、新しいサービスが追加される。DFDは有用なまま維持するためには、常にメンテナンスされるべき生きている文書である。🔄
- 定期的なレビュー:開発チームと定期的にDFDをレビューするスケジュールを組み、現在のコードベースと一致していることを確認する。
- 変更管理:新しい機能が追加されたら、すぐに図を更新する。次回のドキュメントスプリントまで待ってはいけない。
- 依存関係の追跡:図を使って依存関係を追跡する。データストアが削除された場合、DFDはどのプロセスが壊れるかを明確に示す。
現実を反映しないドキュメントは技術的負債を生む。DFDを最新の状態に保つことで、新規エンジニアのオンボーディング時間を短縮し、アーキテクチャのずれを防ぐことができる。
🛠️ 実装戦略
実際に複雑なシステムをモデル化するにはどうすればよいのか?完全性を確保するために、構造的なアプローチに従う。📋
- エンティティの特定:システムとやり取りするすべてのユーザー、外部システム、デバイスをリストアップする。
- 境界の定義:システムの境界線を明確に描く。境界内にあるものはシステム、境界外にあるものは外部である。
- 高レベルのフローのマッピング:まずコンテキスト図を描く。すべての入力と出力がカバーされていることを確認する。
- プロセスの分解:主なプロセスをサブプロセスに分解する。各プロセスには動詞でラベルを付ける。
- データストアを追加する:データを永続化する必要がある場所を特定する。関連するプロセスに接続する。
- 検証する:ブラックホールやグレイホールがないか確認する。すべてのデータフローが発信元と受信先を持っていることを確認する。
- 精緻化する:分散環境におけるプロトコル、暗号化、ネットワーク境界に関する詳細を追加する。
この反復的なプロセスにより、コードが書かれる前にモデルが堅牢であることが保証される。論理的な誤りを早期に発見できるため、時間を節約できる。
🚀 結論
データフローダイアグラムは、分散システムを設計するための基盤となるツールである。複雑なネットワークを介してデータがどのように移動するかを理解するための必要な明確さを提供する。ベストプラクティスに従い、一般的な落とし穴を避け、図を継続的に維持することで、スケーラブルで、安全かつ信頼性の高いシステムを構築できる。🌟
モデル化に費やした努力は、開発および保守の段階で大きなリターンをもたらす。明確な図は、開発者、ステークホルダー、運用チーム間のコミュニケーションを円滑にする。これらはシステムアーキテクチャに関する唯一の真実の情報源となる。
今日から分散システムのマッピングを始めよう。明確さ、一貫性、正確性に注目する。アーキテクチャをスケーリングするときや、新しいメンバーをオンボーディングするときに、将来の自分があなたに感謝するだろう。🏁