











Projektowanie złożonych systemów rozproszonych wymaga więcej niż tylko pisania kodu; wymaga jasnego języka wizualnego, który zrozumieją wszyscy zaangażowani. 🏗️ Schematy przepływu danych (DFD) pełnią tę rolę, pokazując, jak informacje przemieszczają się między różnymi węzłami, usługami i jednostkami przechowywania danych. W środowiskach rozproszonych DFD stają się kluczowymi narzędziami do identyfikacji węzłów zakleszczenia, ryzyk bezpieczeństwa oraz wyzwań związanych z spójnością danych jeszcze przed rozpoczęciem implementacji.
Ten przewodnik omawia metodologię tworzenia skutecznych modeli systemów rozproszonych. Przeanalizujemy podstawowe komponenty, proces dekompozycji oraz specyficzne kwestie, które należy wziąć pod uwagę, gdy dane przemieszczają się przez granice sieci. Przestrzeganie ugruntowanych praktyk modelowania pozwala zespołom zapewnić, że architektura wspiera skalowalność i niezawodność.
🌐 Zrozumienie kontekstu systemów rozproszonych
Systemy rozproszone składają się z wielu niezależnych komputerów, które dla użytkowników wydają się jednym spójnym systemem. W przeciwieństwie do architektur monolitycznych środowiska te wprowadzają złożoność w zakresie komunikacji, zarządzania stanem oraz trybów awarii. 🚀 Modelowanie tych systemów wymaga zmiany perspektywy – od logiki wewnętrznych procesów do zewnętrznych ścieżek komunikacji.
- Granice sieciowe: Dane często przekraczają sieci fizyczne lub logiczne, co wprowadza opóźnienia oraz potencjalne punkty awarii.
- Zamierzenie usługi: Systemy są dzielone na mniejsze usługi, każda z nich obsługuje określone obowiązki.
- Bezstanowość wobec stanowości: Niektóre komponenty przetwarzają żądania bez zachowywania historii, podczas gdy inne zarządzają danymi trwałymi.
- Komunikacja asynchroniczna: Wiele interakcji rozproszonych opiera się na kolejkach komunikatów zamiast bezpośrednich wywołań synchronicznych.
Bez jasnego schematu zespoły ryzykują stworzenie architektury typu „spaghetti”, w której przepływy danych są niejasne. Dobrze zorganizowany DFD wyjaśnia te interakcje, zapewniając, że każdy punkt danych ma zdefiniowane pochodzenie i docelowe miejsce.
🔍 Rola schematów przepływu danych w projektowaniu systemu
Schemat przepływu danych to graficzne przedstawienie przepływu danych przez system informacyjny. Nie pokazuje czasu działania ani logiki sterowania, ale skupia się wyłącznie na tym, jak dane wchodzą do systemu, przetwarzane są, poruszają się i opuszczają go. 🧭
W kontekście rozproszonym DFD pomaga wizualizować:
- Skąd pochodzi dane (Jednostki zewnętrzne).
- Jak jest przetwarzane (Procesy).
- Gdzie jest przechowywane tymczasowo lub na stałe (Magazyny danych).
- Jak porusza się między komponentami (Przepływy danych).
Wykorzystywanie DFD pozwala architektom weryfikować wymagania wobec zaproponowanej architektury. Zapewnia, że żadne dane nie są tworzone ani niszczone bez uzasadnienia, utrzymując integralność na całym etapie życia systemu.
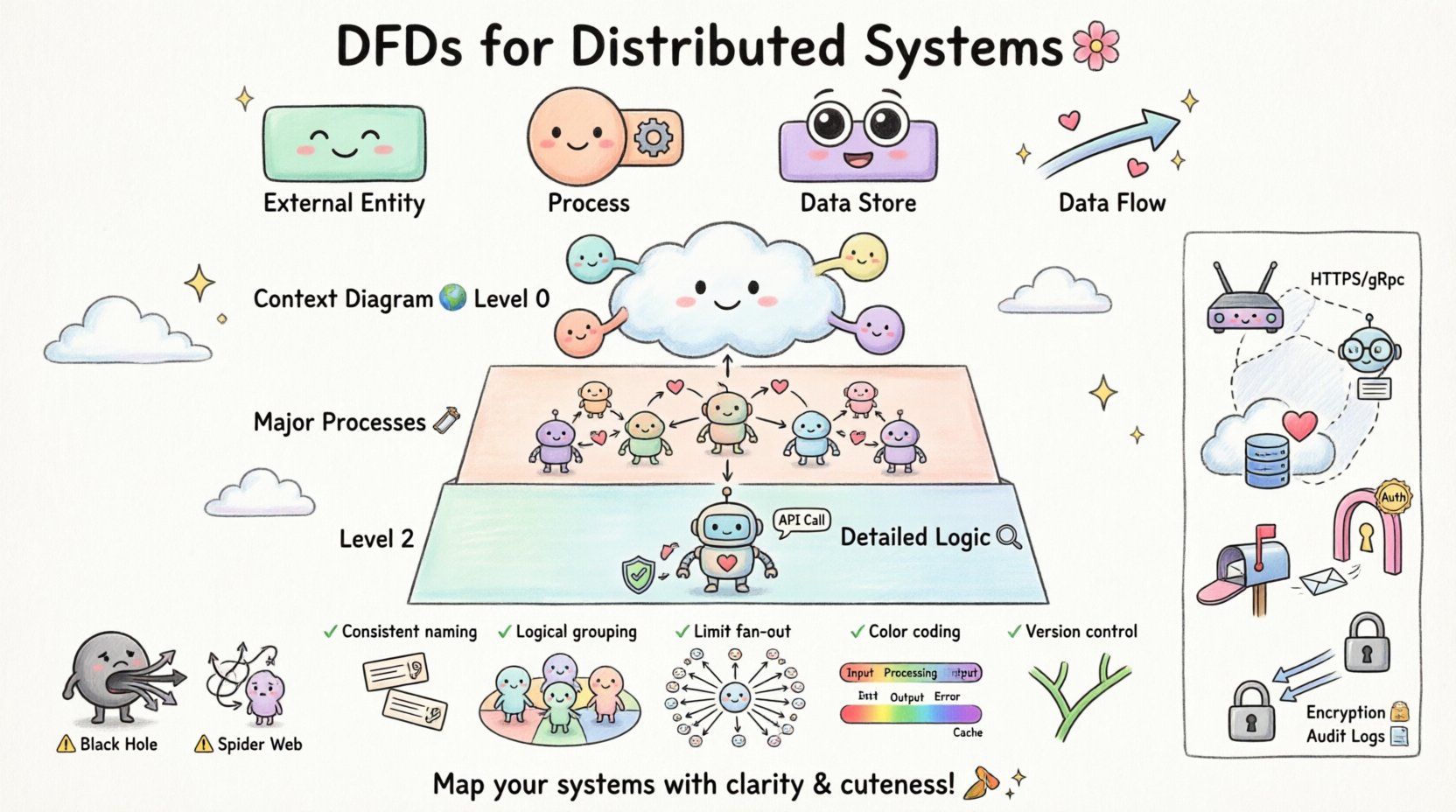
Podstawowe komponenty DFD
Aby stworzyć poprawny model, należy zrozumieć cztery podstawowe symbole używane w standardowej notacji. Każdy z nich pełni określoną funkcję w przedstawieniu graficznym.
| Komponent | Funkcja | Wizualne przedstawienie |
|---|---|---|
| Jednostka zewnętrzna | Źródło lub miejsce docelowe danych poza granicami systemu. | Prostokąt |
| Proces | Przekształcenie danych z wejścia do wyjścia. | Koło lub zaokrąglony prostokąt |
| Magazyn danych | Miejsce, gdzie dane są przechowywane do późniejszego użycia. | Otwarty prostokąt lub równoległe linie |
| Przepływ danych | Ruch danych między składnikami. | Strzałka |
Podczas modelowania systemów rozproszonych bardzo ważne jest etykietowanie każdej strzałki frazą rzeczownikową opisującą zawartość danych, a nie czasownikiem. Na przykład użyj „Dane uwierzytelniające użytkownika” zamiast „Wysyłanie danych uwierzytelniających”.
📉 Poziomy dekompozycji DFD
Złożone systemy nie mogą być przedstawione w jednym widoku. Dekompozycja pozwala przejść od ogólnego przeglądu do szczegółów. Ten podejście zapobiega przeciążeniu poznawczemu czytelnika.
Poziom 0: Diagram kontekstowy
Diagram kontekstowy zapewnia najwyższy poziom abstrakcji. Pokazuje cały system jako pojedynczy proces i identyfikuje wszystkie zewnętrzne jednostki oddziałujące z nim. 🌍
- Zakres: Określa granice systemu.
- Oddziaływania: Pokazuje wszystkie wejścia i wyjścia z zewnętrznego świata.
- Jasność: Pomaga stakeholderom zrozumieć cel systemu bez szczegółów technicznych.
Poziom 1: Główne procesy
Poziom 1 rozszerza pojedynczy proces z diagramu kontekstowego na główne podprocesy. Ten poziom dzieli system na logiczne fragmenty oparte na funkcji. 🛠️
- Dekompozycja: Dzieli system na 5 do 9 głównych procesów.
- Przepływ: Pokazuje, jak dane poruszają się między tymi głównymi procesami.
- Magazyny: Wprowadza magazyny danych wspierające te procesy.
Poziom 2 i dalej: Szczegółowa logika
Dalsza dekompozycja następuje na poziomie 2, gdzie konkretne podprocesy są rozłożone. To często jest miejsce, gdzie zaczynają się pojawiać szczegóły implementacji, takie jak konkretne zasady walidacji lub wywołania interfejsów API. 🔍
W modelowaniu rozproszonym diagramy poziomu 2 są szczególnie przydatne do definiowania granic usług. Pomagają one zidentyfikować, w którym węźle usługi powinien znajdować się dany proces.
⚡ Modelowanie środowisk rozproszonych
Standardowe DFD często zakładają środowisko monolityczne. Przy dostosowywaniu ich do systemów rozproszonych należy stosować konkretne oznaczenia i uwzględniać specyficzne aspekty, aby odzwierciedlić rzeczywistości sieciowe. 🌐
Oto porównanie elementów modelowania standardowego i rozproszonego:
| Element | Modelowanie standardowe | Modelowanie rozproszone |
|---|---|---|
| Przepływ danych | Bezpośredni przepływ logiczny. | Przesyłanie przez sieć, opóźnienia, protokół. |
| Proces | Jednostka obliczeniowa. | Usługa mikroserwisowa, kontener lub funkcja bezserwerowa. |
| Magazyn danych | Lokalna baza danych. | Przechowywanie w chmurze, rozproszony bufor lub rozdzielona baza danych. |
| Granica | Granica systemu. | Granica sieciowa, strefa zaufania lub brama interfejsu API. |
Podczas rysowania przepływów danych między procesami w różnych węzłach, przydatne jest oznaczenie przepływu mechanizmem transportu (np. HTTPS, gRPC, kolejka komunikatów). To dodaje kontekst dotyczący wymagań dotyczących wydajności i bezpieczeństwa.
🛡️ Obsługa współbieżności i stanu
Systemy rozproszone często obsługują równoległe żądania. Statyczny DFD może nie wyraźnie pokazywać czasu, ale musi sugerować sposób zarządzania stanem podczas tych interakcji. ⏳
- Procesy bezstanowe: Jeśli proces nie przechowuje stanu, DFD powinien pokazywać dane przepływające przez nie i opuszczające system bez powrotu do magazynu danych w ramach tej konkretnej transakcji.
- Procesy zstanowe: Jeśli proces utrzymuje stan, musi istnieć jasny przepływ danych do magazynu danych, który zapewnia trwałe przechowywanie tej informacji.
- Spójność: Przepływy danych reprezentujące aktualizacje muszą wskazywać sposób utrzymania spójności między węzłami.
Na przykład podczas modelowania koszyka zakupowego DFD powinien pokazywać przepływ „Danych koszyka” od jednostki użytkownika do usługi koszyka, a następnie do magazynu danych. Jeśli usługa koszyka jest rozproszona, przepływ powinien wskazywać, który węzeł przechowuje autorytatywną kopię danych.
🚫 Powszechne pułapki w modelowaniu rozproszonym
Nawet doświadczeni architekci mogą popełniać błędy podczas wizualizacji rozproszonych przepływów danych. Znajomość tych typowych błędów pomaga poprawić jakość modelu. 🚧
| Pułapka | Skutek | Poprawka |
|---|---|---|
| Proces czarnej dziury | Dane wchodzą do procesu, ale nigdy z niego nie wychodzą. | Upewnij się, że każdy wejście ma odpowiednie wyjście lub przechowywanie. |
| Proces szarej dziury | Wyjścia istnieją, ale żadne wejście ich nie wyjaśnia. | Sprawdź wszystkie źródła danych dla każdego przepływu wyjściowego. |
| Pająk | Zbyt wiele przecinających się linii powodujących zamieszanie. | Użyj podprocesów do grupowania powiązanych przepływów. |
| Ignorowanie sieci | Ignorowanie opóźnień lub punktów awarii. | Oznacz przepływy notatkami dotyczącymi protokołu i niezawodności. |
Unikaj rysowania bezpośrednich połączeń między magazynami danych bez procesu pośredniczącego. Magazyny danych powinny komunikować się wyłącznie poprzez procesy, które weryfikują i przekształcają dane. Zapobiega to nieautoryzowanemu bezpośredniemu dostępowi i zapewnia zastosowanie logiki biznesowej.
📝 Najlepsze praktyki dla przejrzystości
Tworzenie schematu, który jest zarówno dokładny, jak i czytelny, wymaga przestrzegania określonych zasad projektowych. 🎨
- Spójne nazewnictwo:Używaj tej samej terminologii dla tych samych danych we wszystkich schematach. Jeśli w poziomie 0 użyto „User ID”, nie nazywaj tego „Customer Key” na poziomie 1.
- Logiczne grupowanie: Wizualnie grupuj powiązane procesy. Pomaga to zidentyfikować granice usług.
- Ogranicz rozgałęzienie: Unikaj sytuacji, gdy pojedynczy proces jest połączony z więcej niż dziesięcioma przepływami danych. W takim przypadku rozłóż proces.
- Kodowanie kolorów: Używaj kolorów do odróżniania procesów wewnętrznych, jednostek zewnętrznych i magazynów danych. Ułatwia to szybkie przeglądanie.
- Kontrola wersji: Traktuj schematy jak kod. Przechowuj je w systemie kontroli wersji, aby śledzić zmiany w czasie.
Podczas modelowania systemów rozproszonych rozważ użycie pasków przepływu, aby przedstawić różne strefy zaufania lub odcinki sieci. Pozwala to od razu zrozumieć, które komponenty są publiczne, a które wewnętrzne.
🔒 Integracja rozważań dotyczących bezpieczeństwa
Bezpieczeństwo nie może być postrzegane jako dodatkowe rozważanie; musi być modelowane równolegle z funkcjonalnością. Diagramy przepływu danych oferują unikalną możliwość wczesnego wykrywania ryzyk bezpieczeństwa w fazie projektowania.
- Punkty uwierzytelniania:Zaznacz miejsca, w których są weryfikowane dane uwierzytelniające użytkownika. Zazwyczaj dzieje się to na granicy między jednostką zewnętrzną a pierwszym procesem.
- Szyfrowanie danych:Wskazuj, gdzie przepływy danych poufnych są szyfrowane. Używaj etykiet takich jak „Zaszyfrowany kanał” na strzałce.
- Kontrola dostępu:Pokaż, które procesy mają uprawnienia do dostępu do określonych magazynów danych.
- Rejestrowanie:Uwzględnij przepływy, które wysyłają dzienniki audytu do osobnego magazynu rejestrowania. Zapewnia to śledzenie działań.
Jawne modelowanie tych przepływów bezpieczeństwa pozwala zespołom na zapewnienie, że szyfrowanie i uwierzytelnianie nie zostaną zapomniane podczas implementacji. Wymusza to rozmowę na temat prywatności danych i wymogów zgodności.
🔄 Konserwacja i ewolucja
Systemy ewoluują. Wymagania się zmieniają, a do systemu dodawane są nowe usługi. Diagram przepływu danych to żywy dokument, który musi być utrzymywany, aby nadal był przydatny. 🔄
- Regularne przeglądy:Zaplanuj okresowe przeglądy diagramów przepływu danych wraz z zespołem programistów, aby upewnić się, że odpowiadają bieżącej bazie kodu.
- Zarządzanie zmianami:Gdy dodawana jest nowa funkcja, natychmiast zaktualizuj diagram. Nie czekaj aż do kolejnego sprintu dokumentacji.
- Śledzenie zależności:Użyj diagramu do śledzenia zależności. Jeśli usunięto magazyn danych, diagram przepływu danych wskaza, które procesy przestaną działać.
Dokumentacja, która nie odzwierciedla rzeczywistości, tworzy dług techniczny. Zachowanie aktualności diagramów przepływu danych zmniejsza czas wdrażania nowych inżynierów i zapobiega odchyleniu architektury.
🛠️ Strategia implementacji
Jak naprawdę rozpocząć modelowanie złożonego systemu? Postępuj zgodnie z zorganizowanym podejściem, aby zapewnić kompletność.
- Identyfikacja jednostek:Wypisz wszystkich użytkowników, zewnętrznych systemów i urządzeń, które interagują z systemem.
- Zdefiniuj granice:Jasno narysuj linię graniczną systemu. Wszystko wewnątrz to system; wszystko poza nim to zewnętrzne.
- Mapuj przepływy najwyższego poziomu:Najpierw narysuj diagram kontekstowy. Upewnij się, że wszystkie wejścia i wyjścia zostały uwzględnione.
- Rozłóż procesy:Rozłóż główny proces na procesy podstawowe. Oznacz je czasownikami.
- Dodaj magazyny danych: Zidentyfikuj, gdzie dane muszą być trwale przechowywane. Połącz je z odpowiednimi procesami.
- Weryfikuj: Sprawdź obecność czarnych i szarych dziur. Upewnij się, że każdy przepływ ma źródło i docelowy punkt.
- Doskonal: Dodaj szczegóły dotyczące protokołów, szyfrowania i granic sieciowych w kontekście rozproszonych systemów.
Ten proces iteracyjny zapewnia, że model jest odporny przed napisaniem kodu. Oszczędza czas, wykrywając błędy logiczne na wczesnym etapie.
🚀 Wnioski
Diagramy przepływu danych są podstawowym narzędziem do projektowania systemów rozproszonych. Zapewniają niezbędną jasność, aby zrozumieć, jak dane poruszają się przez złożone sieci. Przestrzegając najlepszych praktyk, unikając typowych pułapek i utrzymując diagramy w czasie, zespoły mogą budować systemy skalowalne, bezpieczne i niezawodne. 🌟
Wkład w modelowanie przynosi korzyści podczas rozwoju i utrzymania systemu. Jasne diagramy ułatwiają lepszą komunikację między programistami, stakeholderami i zespołami operacyjnymi. Są jedynym źródłem prawdy dotyczącym architektury systemu.
Zacznij mapować swoje systemy rozproszone już dziś. Skup się na przejrzystości, spójności i dokładności. Przyszły ty będzie Ci dziękować, gdy architektura będzie wymagała skalowania lub przyjęcia nowych członków zespołu. 🏁