











在面向对象分析与设计的领域中,有两个度量标准决定了系统的健康状况:耦合与内聚。这些概念不仅仅是学术术语;它们是可维护、可扩展且稳健的软件架构的基石。当开发人员理解模块之间的交互方式以及职责的分配方式时,他们就能构建出能够适应变化而非在压力下崩溃的系统。
本指南将深入探讨这些原则的机制。我们将剖析内聚与耦合的类型,分析它们对开发周期的影响,并提供可操作的策略来优化您的设计。通过关注这些结构性要素,团队可以减少技术债务,提升整体代码质量。
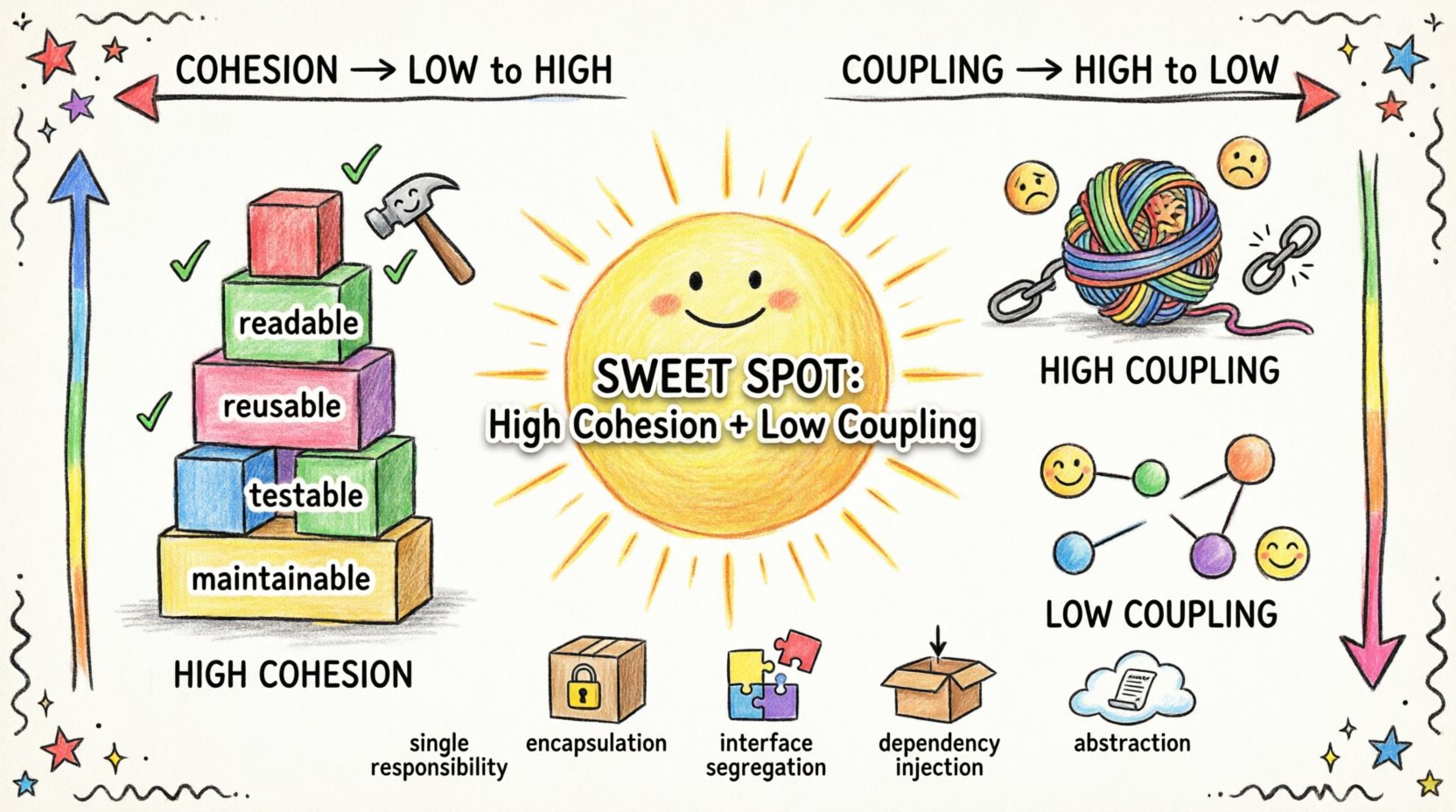
理解内聚:内在的强度 🧱
内聚指的是单个模块、类或组件内部职责之间的关联程度。高内聚意味着一个模块执行单一且明确的任务。低内聚则表明一个模块试图完成太多无关的任务。
想象一个工具集。锤子具有很高的内聚性,因为它专为一项任务而设计。瑞士军刀的内聚性较低,因为它将切割、拧螺丝和开瓶等功能整合到一个工具中。尽管多功能性有其价值,但在软件设计中,我们通常更倾向于锤子式的做法。
内聚的类型
并非所有的内聚性都是一样的。下表概述了从低内聚到高内聚的谱系:
| 级别 | 类型 | 描述 |
|---|---|---|
| 低 | 偶然性 | 元素被随意分组,没有任何有意义的关联。 |
| 低 | 逻辑性 | 元素因在逻辑上相似而被分组(例如,所有报表打印功能)。 |
| 低 | 时间性 | 元素因在同一时间执行而被分组(例如,初始化例程)。 |
| 中等 | 过程性 | 元素因必须按特定顺序执行而被分组。 |
| 中等 | 通信性 | 元素因操作相同数据而被分组。 |
| 高 | 顺序性 | 一个元素的输出是下一个元素的输入。 |
| 高 | 功能性 | 所有元素都致力于单一且特定的任务。 |
功能性与顺序性内聚是良好设计模块的目标。当一个类表现出功能性内聚时,意味着该类中的每个方法都为一个特定目标做出贡献。这使得类更易于理解、测试和修改。
高内聚的优势
- 可读性:开发人员可以快速理解模块的目的。
- 可重用性:一个专注的模块可以以最小的阻力被移动到系统的其他部分。
- 可测试性:独立的功能更容易通过单元测试进行验证。
- 可维护性:对功能某一方面的更改不会在无关逻辑中引发不可预测的连锁反应。
理解耦合:外部连接 🔗
如果内聚关注的是内部统一性,那么耦合关注的是外部依赖性。耦合衡量的是软件模块之间的相互依赖程度。低耦合意味着模块之间是独立的,可以在不了解彼此内部细节的情况下运行。
高耦合会形成复杂的依赖网络。更改一个模块会迫使其他许多模块也进行更改。这会导致系统脆弱,一次简单的更新就可能破坏整个系统。
耦合的类型
与内聚类似,耦合也存在于一个连续谱上。目标是向该谱系的较低端移动:
- 内容耦合(最高):一个模块修改了另一个模块的内部数据。这是最糟糕的耦合形式。
- 公共耦合:模块共享全局数据结构。对全局结构的更改会影响所有使用者。
- 控制耦合:一个模块向另一个模块传递一个控制标志,以决定其内部逻辑流程。
- 标记耦合:模块共享一个复杂的数据结构(例如一个对象),但仅使用其中的少数部分。
- 数据耦合(最低):模块仅共享其运行所必需的数据。它们不依赖于控制标志或全局状态。
低耦合的优势
- 模块化:模块可以独立地进行开发、测试和部署。
- 并行开发: 团队可以在不干扰彼此代码的情况下,分别开发不同的模块。
- 灵活性: 如果模块的接口保持稳定,替换它会更容易。
- 可扩展性: 系统可以扩展,而不会变成难以管理的依赖关系纠缠。
内聚性与耦合度之间的关系 🔄
这两个概念之间存在直接关联。通常情况下,内聚性越高,耦合度越低。当一个模块专注于单一任务(高内聚性)时,它对外部输入的需求更少,产生的依赖也更少(低耦合)。
相反,一个试图完成所有事情的模块(低内聚性)通常需要与其他许多模块通信以收集数据或触发操作,从而导致高耦合。
设计师应力求达到“高内聚、低耦合”的理想状态。这种组合能够构建出各部分自成一体、仅通过明确定义的接口相互连接的系统。
提升设计的策略 🛠️
我们如何在实践中实现这种平衡?以下策略指导设计过程,而无需依赖特定工具或框架。
1. 单一职责原则
每个模块都应只有一个改变的理由。如果一个类同时处理数据库连接、用户认证和报表生成,就违反了这一原则。应将这些关注点拆分为独立的类。每个类专注于一个职责,从而自然提升内聚性。
2. 封装
隐藏模块的内部状态。仅通过公共接口暴露必要内容。这可以防止其他模块直接访问并修改内部数据,从而降低内容耦合。
3. 接口隔离
不要强迫客户端依赖它们不需要的方法。应创建小型、特定的接口,而不是大型、单一的接口。这可以减少桩耦合,并确保模块仅与它们需要的数据进行交互。
4. 依赖管理
使用依赖注入的概念来管理关系。模块不应自行创建依赖,而应从外部接收所需内容。这使得替换实现更加容易,并能独立测试组件。
5. 抽象
使用抽象类或接口来定义契约。具体实现可以变化,而不会影响使用它们的代码。这使逻辑与具体实现细节解耦。
对测试与维护的影响 🧪📝
耦合与内聚的结构性质量直接影响软件的运行生命周期。
测试效率
高度内聚的模块更容易测试。你可以模拟依赖项,专注于该模块的特定逻辑。低耦合确保一个模块的测试不会因另一个模块的更改而失效。这将带来一个稳定的测试套件,使重构时更具信心。
维护成本
软件维护通常是开发过程中成本最高的阶段。内聚性低且耦合度高的系统需要更多时间来理解与修改。一个区域的更改会在整个系统中引发连锁反应,需要进行大量回归测试。而高内聚与低耦合则能将更改局限在局部,降低修复缺陷或添加功能所需的努力。
重构技术
在审查遗留代码时,应寻找内聚性差和耦合度高的迹象:
- 上帝类: 知识过多或行为过多的类。
- 全局变量: 在整个应用程序中共享的状态。
- 过长的参数列表: 高耦合或数据封装不良的指示。
- 重复的逻辑: 在多个地方出现的代码,表明需要一个共享的服务。
重构涉及移动代码以提高内聚性。例如,如果一个方法只使用了类中一半的数据,就将该方法移到一个新的类中。如果一个类依赖另一个类进行配置,就引入工厂或注入器。
常见的陷阱,应避免 ⚠️
在追求高内聚性和低耦合性的同时,避免极端情况,以免影响性能或可用性。
- 过度抽象: 创建过多的接口会使代码更难导航。保持抽象简单且有意义。
- 微优化: 如果性能提升微不足道,就不要仅仅为了降低耦合而拆分类。可维护性比微小的效率提升更重要。
- 刚性接口: 确保接口足够灵活,能够适应未来的变更,而不会破坏现有的实现。
- 忽视业务逻辑: 不要仅为了技术上的纯粹性而设计。结构必须有效支持业务需求。
设计质量的结论 🏁
管理耦合与内聚是一个持续的过程,而非一次性任务。它需要在代码审查、重构会话和架构规划中保持警惕。通过优先考虑这些原则,开发者能够构建出能够抵御变化的系统。
目标不是完美,而是进步。定期评估你的模块。问自己一个类是否责任过多。问自己一个依赖是否必要。随着时间的推移,微小的调整将带来稳健的架构。
记住,这些原则是指导方针,而非僵化的法律。运用你的判断力,在它们能带来价值的地方应用。专注于明确的责任和最少的依赖,你就能构建出经得起时间考验的软件。