











Die Gestaltung komplexer verteilter Systeme erfordert mehr als nur das Schreiben von Code; es erfordert eine klare visuelle Sprache, die Stakeholder verstehen können. 🏗️ Datenflussdiagramme (DFDs) dienen als diese Sprache und zeigen auf, wie Informationen über verschiedene Knoten, Dienste und Speichereinheiten fließen. Angewendet auf verteilte Umgebungen werden DFDs zu entscheidenden Werkzeugen, um Engpässe, Sicherheitsrisiken und Konsistenzprobleme zu identifizieren, bevor die Implementierung beginnt.
Diese Anleitung untersucht die Methodik hinter der Erstellung effektiver Modelle verteilter Systeme. Wir werden die zentralen Komponenten, den Zerlegungsprozess und die spezifischen Überlegungen untersuchen, die erforderlich sind, wenn Daten Netzwerkgrenzen überschreiten. Durch die Einhaltung etablierter Modellierungspraktiken können Teams sicherstellen, dass ihre Architektur Skalierbarkeit und Zuverlässigkeit unterstützt.
🌐 Verständnis des Kontexts verteilter Systeme
Verteilte Systeme bestehen aus mehreren autonomen Computern, die für Benutzer wie ein einziges zusammenhängendes System erscheinen. Im Gegensatz zu monolithischen Architekturen bringen diese Umgebungen Komplexität hinsichtlich der Kommunikation, Zustandsverwaltung und Ausfallmodi mit sich. 🚀 Die Modellierung dieser Systeme erfordert eine Veränderung der Perspektive von interner Prozesslogik zu externen Kommunikationspfaden.
- Netzwerkgrenzen:Daten überschreiten häufig physische oder logische Netzwerke und führen so zu Latenzzeiten sowie potenziellen Ausfallstellen.
- Dienstgranularität:Systeme werden in kleinere Dienste aufgeteilt, die jeweils spezifische Verantwortlichkeiten übernehmen.
- Zustandslosigkeit gegenüber Zustandsbehaftetheit:Einige Komponenten verarbeiten Anfragen ohne die Aufbewahrung von Historie, während andere persistente Daten verwalten.
- Asynchrone Kommunikation:Viele verteilte Interaktionen basieren auf Nachrichtenwarteschlangen anstelle direkter synchroner Aufrufe.
Ohne eine klare Karte riskieren Teams, eine „Spaghetti-Architektur“ zu erstellen, bei der die Datenflüsse unklar sind. Ein gut strukturiertes DFD klärt diese Interaktionen und stellt sicher, dass jeder Datenpunkt eine definierte Herkunft und ein Ziel hat.
🔍 Die Rolle von Datenflussdiagrammen in der Systemgestaltung
Ein Datenflussdiagramm ist eine grafische Darstellung des Datenflusses durch ein Informationssystem. Es zeigt weder die Zeitpunkte noch die Steuerlogik, sondern konzentriert sich ausschließlich darauf, wie Daten in das System eintreten, transformiert werden, sich bewegen und das System verlassen. 🧭
Im verteilten Kontext hilft das DFD dabei, folgendes zu visualisieren:
- Wo die Daten entstehen (externe Entitäten).
- Wie sie verarbeitet werden (Prozesse).
- Wo sie temporär oder dauerhaft gespeichert werden (Datenbanken).
- Wie sie zwischen Komponenten reist (Datenflüsse).
Durch die Verwendung von DFDs können Architekten Anforderungen an die vorgeschlagene Architektur überprüfen. Es stellt sicher, dass keine Daten ohne gültigen Grund erstellt oder zerstört werden, wodurch die Integrität über die gesamte Lebensdauer gewährleistet bleibt.
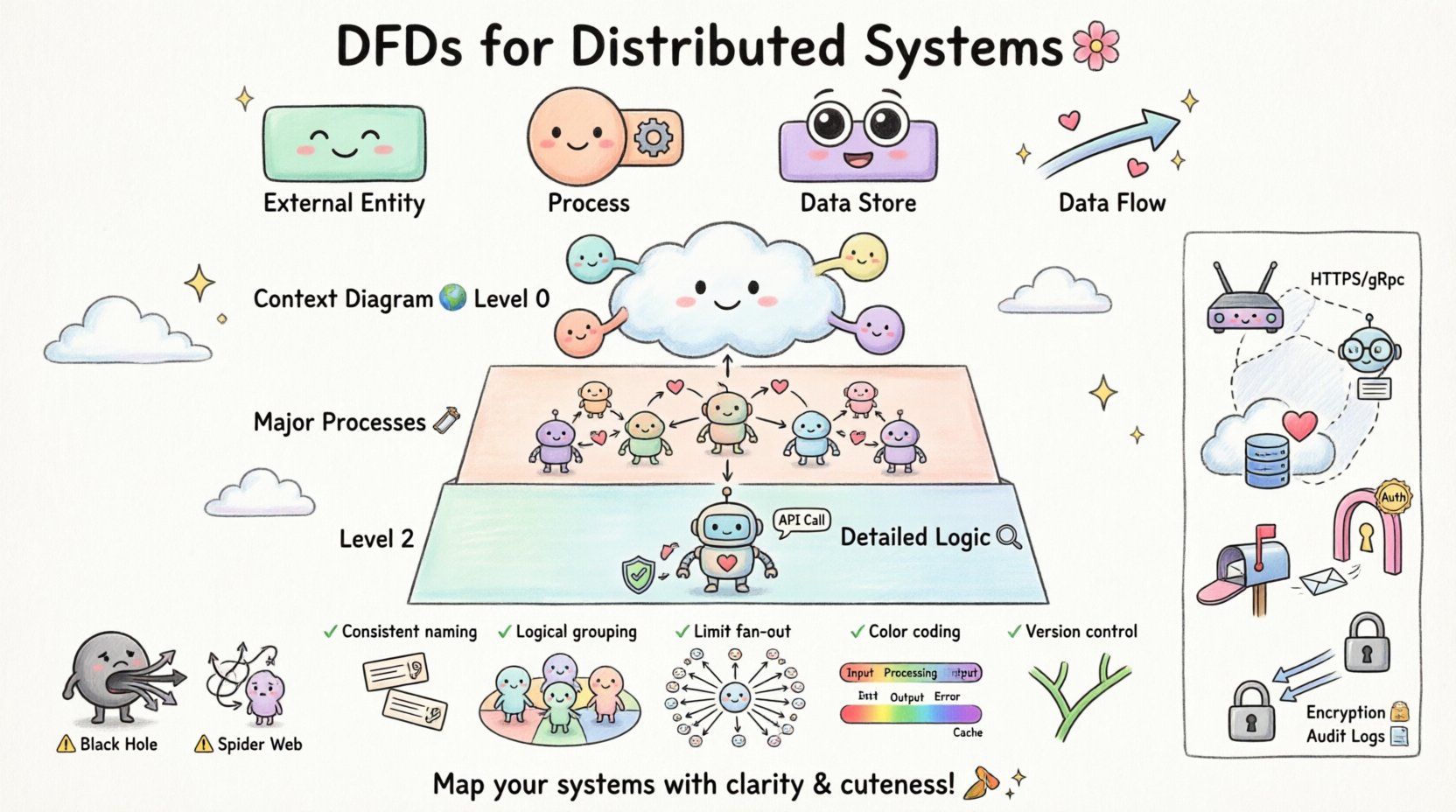
Kernkomponenten eines DFD
Um ein gültiges Modell zu erstellen, müssen Sie die vier primären Symbole verstehen, die in der Standardnotation verwendet werden. Jedes hat eine unterschiedliche Funktion in der diagrammatischen Darstellung.
| Komponente | Funktion | Visuelle Darstellung |
|---|---|---|
| Externe Entität | Quelle oder Ziel von Daten außerhalb der Systemgrenze. | Rechteck |
| Prozess | Transformation von Daten von Eingabe zu Ausgabe. | Kreis oder abgerundetes Rechteck |
| Datenbank | Ort, an dem Daten für spätere Verwendung gespeichert werden. | Offenes Rechteck oder parallele Linien |
| Datenfluss | Die Bewegung von Daten zwischen Komponenten. | Pfeil |
Beim Modellieren verteilter Systeme ist es entscheidend, jeden Pfeil mit einem Substantiv-Phrasen zu beschriften, die den Dateninhalt beschreiben, nicht mit einem Verb. Verwenden Sie beispielsweise „Benutzeranmeldeinformationen“ anstelle von „Anmeldeinformationen senden“.
📉 Ebenen der DFD-Entwicklung
Komplexe Systeme können nicht in einer einzigen Ansicht dargestellt werden. Die Zerlegung ermöglicht es Ihnen, von einer übersichtlichen Gesamtsicht in detaillierte Einzelheiten vorzudringen. Dieser Ansatz verhindert kognitive Überlastung für den Leser.
Ebene 0: Das Kontextdiagramm
Das Kontextdiagramm bietet die höchste Abstraktionsebene. Es zeigt das gesamte System als einen einzigen Prozess und identifiziert alle externen Entitäten, die mit ihm interagieren. 🌍
- Umfang: Definiert die Grenze des Systems.
- Interaktionen: Zeigt alle Eingaben und Ausgaben aus der Außenwelt an.
- Klarheit: Hilft den Stakeholdern, den Zweck des Systems ohne technische Details zu verstehen.
Ebene 1: Hauptprozesse
Ebene 1 erweitert den einzelnen Prozess aus dem Kontextdiagramm in Hauptunterprozesse. Diese Ebene teilt das System in logische Abschnitte auf der Grundlage der Funktion. 🛠️
- Zerlegung: Teilt das System in 5 bis 9 Hauptprozesse auf.
- Fluss: Zeigt, wie Daten zwischen diesen Hauptprozessen fließen.
- Speicher: Führt Datenbanken ein, die diese Prozesse unterstützen.
Ebene 2 und darüber: Detaillierte Logik
Weitere Zerlegung erfolgt auf Ebene 2, wo spezifische Unterprozesse aufgegliedert werden. Hier beginnen oft Implementierungsdetails zu erscheinen, wie beispielsweise spezifische Validierungsregeln oder API-Aufrufe. 🔍
Bei der verteilten Modellierung sind Level-2-Diagramme besonders nützlich, um Dienstgrenzen zu definieren. Sie helfen dabei, festzustellen, welcher Prozess in welchem Dienstknoten verbleiben sollte.
⚡ Modellierung verteilter Umgebungen
Standard-DFDs gehen oft von einer monolithischen Umgebung aus. Bei der Anpassung für verteilte Systeme müssen spezifische Notationen und Überlegungen angewendet werden, um die Netzwerkwirklichkeit widerzuspiegeln. 🌐
Hier ist ein Vergleich der Elemente der Standard- gegenüber der verteilten Modellierung:
| Element | Standard-Modellierung | Verteilte Modellierung |
|---|---|---|
| Datenfluss | Direkter logischer Fluss. | Netzwerkübertragung, Latenz, Protokoll. |
| Prozess | Einzelne Recheneinheit. | Mikroservice, Container oder serverlose Funktion. |
| Datenbank | Lokale Datenbank. | Cloud-Speicher, verteilter Cache oder sharded DB. |
| Grenze | Systemgrenze. | Netzwerkgrenze, Vertrauenszone oder API-Gateway. |
Beim Zeichnen von Datenflüssen zwischen Prozessen in verschiedenen Knoten ist es hilfreich, den Fluss mit dem Übertragungsmechanismus (z. B. HTTPS, gRPC, Nachrichtenwarteschlange) zu kennzeichnen. Dies fügt Kontext hinsichtlich Leistungs- und Sicherheitsanforderungen hinzu.
🛡️ Umgang mit Konkurrenz und Zustand
Verteilte Systeme verarbeiten häufig gleichzeitige Anfragen. Ein statisches DFD zeigt die Zeitpunkte möglicherweise nicht explizit, muss aber andeuten, wie der Zustand während dieser Interaktionen verwaltet wird. ⏳
- Zustandslose Prozesse: Wenn ein Prozess keinen Zustand speichert, sollte das DFD zeigen, dass Daten durchlaufen und verlassen werden, ohne für diese spezifische Transaktion zurück in einen Speicher zu gelangen.
- Zustandsbehaftete Prozesse: Wenn ein Prozess Zustand beibehält, muss ein klarer Datenfluss zu einem Datenbank-Store bestehen, der diese Informationen persistiert.
- Konsistenz:Datenflüsse, die Aktualisierungen darstellen, müssen angeben, wie die Konsistenz über die Knoten hinweg gewährleistet wird.
Zum Beispiel sollte das DFD beim Modellieren eines Warenkorbs den „Korb-Daten“ vom Benutzer-Entität zum Warenkorbdienst und dann zu einem Datenbank-Store zeigen. Wenn der Warenkorbdienst verteilt ist, sollte der Fluss anzeigen, welcher Knoten die autoritative Kopie der Daten hält.
🚫 Häufige Fehler bei der verteilten Modellierung
Sogar erfahrene Architekten können Fehler machen, wenn sie verteilte Datenflüsse visualisieren. Die Aufmerksamkeit für diese häufigen Fehler hilft, die Qualität des Modells zu verbessern. 🚧
| Fallstrick | Auswirkung | Korrektur |
|---|---|---|
| Schwarzes Loch-Prozess | Daten betreten einen Prozess, verlassen ihn aber niemals. | Stellen Sie sicher, dass jeder Eingang einer entsprechenden Ausgabe oder Speicherung entspricht. |
| Graues Loch-Prozess | Ausgaben existieren, aber keine Eingabe erklärt sie. | Überprüfen Sie alle Datenquellen für jeden Ausgabestrom. |
| Spinnennetz | Zu viele sich kreuzende Linien verursachen Verwirrung. | Verwenden Sie Unterprozesse, um verwandte Flüsse zu gruppieren. |
| Netzwerkunachtsamkeit | Ignorieren von Latenzzeiten oder Ausfallpunkten. | Markieren Sie Flüsse mit Protokoll- und Zuverlässigkeitsnotizen. |
Vermeiden Sie direkte Verbindungen zwischen Datenspeichern ohne dazwischenliegenden Prozess. Datenspeicher sollten sich nur über Prozesse, die die Daten validieren und transformieren, austauschen. Dies verhindert unerlaubten direkten Zugriff und stellt sicher, dass Geschäftslogik angewendet wird.
📝 Best Practices für Klarheit
Die Erstellung eines Diagramms, das sowohl genau als auch lesbar ist, erfordert die Einhaltung spezifischer Gestaltungsprinzipien. 🎨
- Konsistente Benennung:Verwenden Sie für dieselben Daten in allen Diagrammen die gleiche Terminologie. Wenn in Ebene 0 „Benutzer-ID“ verwendet wird, nennen Sie es in Ebene 1 nicht „Kunden-Schlüssel“.
- Logische Gruppierung:Gruppieren Sie verwandte Prozesse visuell zusammen. Dies hilft, Dienstgrenzen zu erkennen.
- Grenzen Sie die Verzweigung ein:Vermeiden Sie, dass ein einzelner Prozess mit mehr als zehn Datenflüssen verbunden ist. Falls dies der Fall ist, zerlegen Sie den Prozess.
- Farbcodierung:Verwenden Sie Farben, um interne Prozesse, externe Entitäten und Datenspeicher voneinander zu unterscheiden. Dies erleichtert das schnelle Scannen.
- Versionskontrolle:Behandeln Sie Diagramme wie Code. Speichern Sie sie in der Versionskontrolle, um Änderungen im Laufe der Zeit nachverfolgen zu können.
Bei der Modellierung verteilter Systeme sollten Sie überlegen, Schwimmzellen zu verwenden, um unterschiedliche Vertrauenszonen oder Netzwerkkomponenten darzustellen. Dadurch wird sofort deutlich, welche Komponenten öffentlich zugänglich sind und welche intern sind.
🔒 Sicherheitsaspekte integrieren
Sicherheit ist kein nachträglicher Gedanke; sie muss zusammen mit der Funktionalität modelliert werden. 🔐 Datenflussdiagramme bieten die einzigartige Gelegenheit, Sicherheitsrisiken bereits in der Entwurfsphase frühzeitig zu identifizieren.
- Authentifizierungspunkte:Markieren Sie die Stellen, an denen Benutzeranmeldeinformationen validiert werden. Dies erfolgt normalerweise an der Grenze zwischen einer externen Entität und dem ersten Prozess.
- Datenverschlüsselung:Geben Sie an, wo sensible Datenflüsse verschlüsselt werden. Verwenden Sie Beschriftungen wie „Verschlüsselter Kanal“ auf dem Pfeil.
- Zugriffssteuerung:Zeigen Sie, welche Prozesse die Berechtigung haben, auf bestimmte Datenbanken zuzugreifen.
- Protokollierung:Schließen Sie Flüsse ein, die Auditspuren an einen separaten Protokollspeicher senden. Dadurch wird die Rückverfolgbarkeit gewährleistet.
Durch die explizite Modellierung dieser Sicherheitsflüsse können Teams sicherstellen, dass Verschlüsselung und Authentifizierung während der Implementierung nicht vergessen werden. Es zwingt zu einer Diskussion über Datenschutz und Compliance-Anforderungen.
🔄 Wartung und Evolution
Systeme entwickeln sich weiter. Anforderungen ändern sich, und neue Dienste werden hinzugefügt. Ein DFD ist ein lebendiges Dokument, das gepflegt werden muss, um nützlich zu bleiben. 🔄
- Regelmäßige Überprüfungen:Planen Sie regelmäßige Überprüfungen der DFDs mit dem Entwicklungsteam, um sicherzustellen, dass sie dem aktuellen Quellcode entsprechen.
- Änderungsmanagement:Wenn eine neue Funktion hinzugefügt wird, aktualisieren Sie die Diagramme sofort. Warten Sie nicht bis zum nächsten Dokumentationssprint.
- Abhängigkeitsverfolgung:Verwenden Sie das Diagramm zur Verfolgung von Abhängigkeiten. Wenn ein Datenbestand entfernt wird, zeigt das DFD auf, welche Prozesse betroffen sind.
Dokumentation, die der Realität nicht entspricht, erzeugt technischen Schulden. Die aktuelle Halterung der DFDs verringert die Einarbeitungszeit für neue Ingenieure und verhindert Architekturverzerrung.
🛠️ Umsetzungsstrategie
Wie beginnen Sie eigentlich mit der Modellierung eines komplexen Systems? Folgen Sie einem strukturierten Ansatz, um Vollständigkeit zu gewährleisten. 📋
- Entitäten identifizieren:Listen Sie alle Benutzer, externen Systeme und Geräte auf, die mit dem System interagieren.
- Grenzen definieren:Zeichnen Sie die Systemgrenze deutlich. Alles, was innerhalb liegt, ist das System; alles außerhalb ist extern.
- Hochlevel-Flüsse abbilden:Zeichnen Sie zuerst das Kontextdiagramm. Stellen Sie sicher, dass alle Eingaben und Ausgaben berücksichtigt sind.
- Prozesse zerlegen:Zerlegen Sie den Hauptprozess in Unterverfahren. Beschriften Sie sie mit Verben.
- Datenquellen hinzufügen:Identifizieren Sie, wo Daten persistiert werden müssen. Verbinden Sie sie mit den entsprechenden Prozessen.
- Überprüfen:Überprüfen Sie auf Schwarze Löcher und Graue Löcher. Stellen Sie sicher, dass jeder Datenfluss eine Quelle und ein Ziel hat.
- Verfeinern:Fügen Sie Details zu Protokollen, Verschlüsselung und Netzwerkgrenzen für verteilte Kontexte hinzu.
Der iterative Prozess stellt sicher, dass das Modell robust ist, bevor Code geschrieben wird. Er spart Zeit, indem logische Fehler früh erkannt werden.
🚀 Schlussfolgerung
Datenflussdiagramme sind ein grundlegendes Werkzeug zur Gestaltung verteilter Systeme. Sie bieten die notwendige Klarheit, um zu verstehen, wie Daten durch komplexe Netzwerke fließen. Indem man bewährte Praktiken befolgt, häufige Fehler vermeidet und die Diagramme über die Zeit pflegt, können Teams Systeme erstellen, die skalierbar, sicher und zuverlässig sind. 🌟
Die in der Modellierung investierte Anstrengung zahlt sich bei der Entwicklung und Wartung aus. Klare Diagramme erleichtern die Kommunikation zwischen Entwicklern, Stakeholdern und Betriebsteams. Sie dienen als einziges Quellen der Wahrheit für die Architektur des Systems.
Beginnen Sie heute mit der Erstellung von Diagrammen für Ihre verteilten Systeme. Konzentrieren Sie sich auf Klarheit, Konsistenz und Genauigkeit. Ihre zukünftige Selbst wird Ihnen danken, wenn die Architektur skaliert werden muss oder neue Teammitglieder eingearbeitet werden müssen. 🏁