











In der Landschaft der modernen Geschäftsanalyse ist Klarheit kein bloßes Vergnügen; sie ist eine Notwendigkeit. Organisationen kämpfen mit Arbeitsabläufen, die mehrere Abteilungen, veraltete Systeme und menschliche Interaktionen umfassen. Wenn die Komplexität steigt, nimmt das Risiko von Missverständnissen zu. Hier werden strukturierte Modellierungstechniken unverzichtbar. Insbesondere bietet das Datenflussdiagramm (DFD) eine robuste Methode, um darzustellen, wie Informationen durch ein System fließen. Durch die Zerlegung komplexer Geschäftsprozesse können Analysten überwältigende Aufgaben in handhabbare, logische Komponenten aufteilen. Dieser Leitfaden untersucht die Mechanik, Prinzipien und strategische Anwendung von DFDs bei der Prozesszerlegung.
Verständnis der Grundlagen von Datenflussdiagrammen 🧩
Ein Datenflussdiagramm ist eine grafische Darstellung des Datenflusses durch ein Informationssystem. Im Gegensatz zu Flussdiagrammen, die oft Steuerlogik oder prozedurale Schritte darstellen, konzentrieren sich DFDs ausschließlich auf Daten. Sie zeigen, wo Daten entstehen, wo sie gespeichert werden, wie sie verändert werden und wo sie letztendlich verlassen. Diese Unterscheidung ist entscheidend für Geschäftsanalysten, die den Inhalt der Abläufe verstehen müssen, nicht nur die Reihenfolge der Ereignisse.
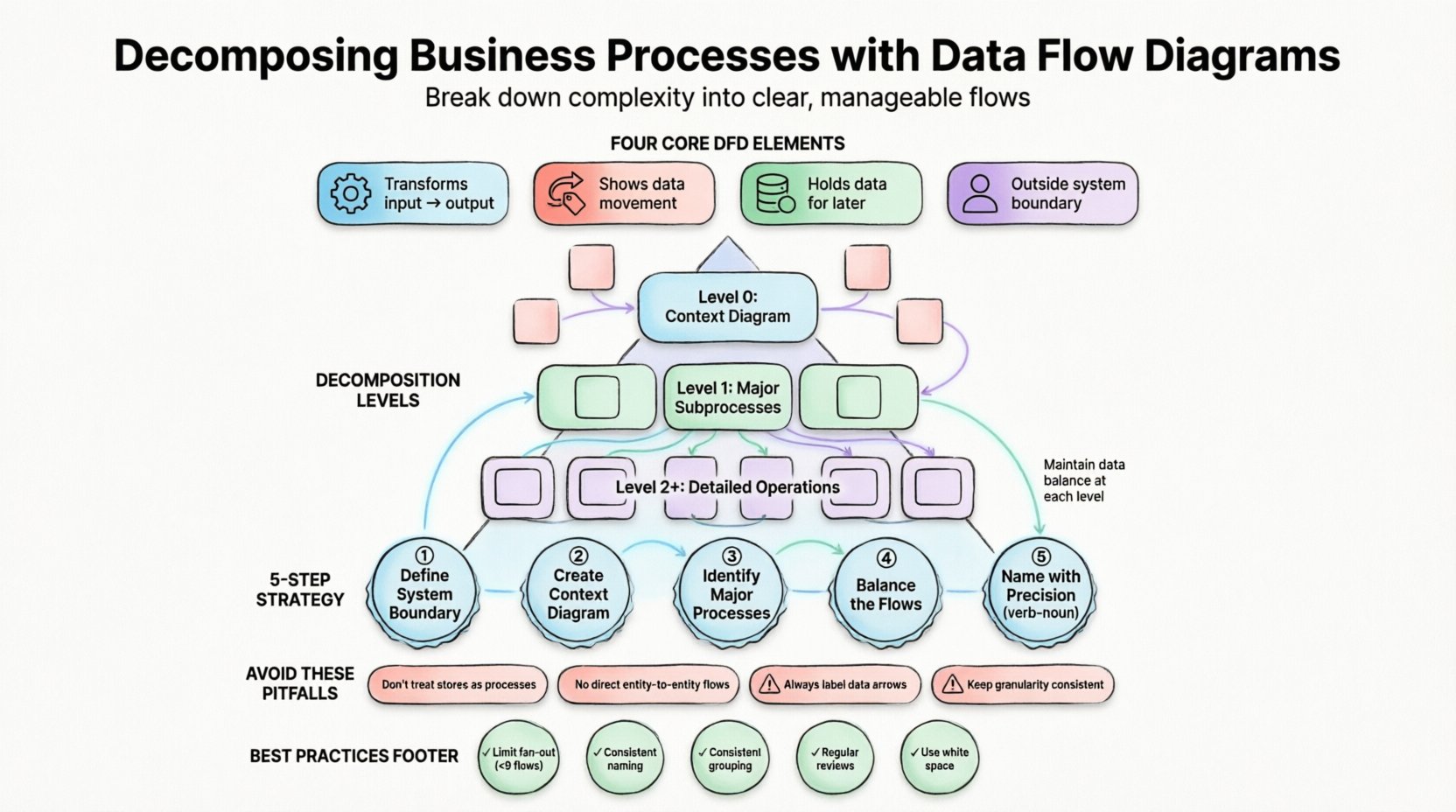
Strukturierte DFDs basieren auf einer spezifischen Notation, um Konsistenz über die Dokumentation hinweg zu gewährleisten. Das Diagramm beruht auf vier Hauptelementen:
- Prozesse:Aktionen, die Eingabedaten in Ausgabedaten umwandeln. Sie werden typischerweise als abgerundete Rechtecke oder Kreise dargestellt. Sie beschreiben wasmit den Daten geschieht.
- Datenflüsse:Die Bewegung von Daten zwischen Prozessen, Speichern und Entitäten. Sie werden als Pfeile dargestellt und müssen klar beschriftet sein, um den Inhalt des bewegten Daten zu kennzeichnen.
- Datenbanken:Orte, an denen Daten für spätere Verwendung aufbewahrt werden. Sie werden als offene Rechtecke oder parallele Linien dargestellt. Sie repräsentieren Datenbanken, Dateien oder physische Archive.
- Externe Entitäten:Quellen oder Ziele von Daten außerhalb der Systemgrenze. Sie werden als Quadrate oder Rechtecke dargestellt und repräsentieren Benutzer, andere Systeme oder Organisationen.
Ohne einen standardisierten Ansatz können diese Diagramme chaotisch werden. Strukturierte DFDs legen eine Disziplin fest, die sicherstellt, dass jeder Datenfluss eine Quelle und ein Ziel hat und jeder Prozess Daten logisch transformiert.
Die Notwendigkeit der Zerlegung 🔨
Komplexe Geschäftsprozesse passen selten auf eine einzige Seite. Wenn man versucht, einen gesamten Unternehmensablauf in einer Ansicht darzustellen, entsteht ein Diagramm, das für Stakeholder unverständlich ist. Die Zerlegung ist die Technik, um einen Hoch-Level-Prozess in detailliertere Unterpunkte aufzuteilen. Dieser hierarchische Ansatz ermöglicht es Analysten, die kognitive Belastung zu steuern und Präzision zu bewahren.
Die Zerlegung erfüllt mehrere entscheidende Funktionen:
- Kontrolle der Granularität:Sie ermöglicht es dem Team, sich auf bestimmte Bereiche des Interesses zu konzentrieren, ohne den übergeordneten Kontext aus den Augen zu verlieren.
- Ausrichtung der Stakeholder:Verschiedene Stakeholder benötigen unterschiedliche Detailgrade. Führungskräfte können das oberste Diagramm betrachten, während Entwickler die detaillierten Teilprozesse benötigen.
- Fehlererkennung:Komplexe Interaktionen werden leichter erkennbar, wenn sie isoliert werden. Dateninkonsistenzen oder fehlende Flüsse sind auf niedrigeren Ebenen besser sichtbar.
- Modularität:Sie fördert das Denken in diskreten Funktionen, was gut mit modernen Softwarearchitekturen und Microservices übereinstimmt.
Der Prozess der Zerlegung ist nicht willkürlich. Er verläuft logisch, wobei ein Elternprozess in Kindprozesse aufgeteilt wird, die gemeinsam alle Daten berücksichtigen, die in den Elternprozess eingehen und ihn verlassen.
Ebenen der Zerlegung in strukturierten DFDs 📈
Um Struktur zu bewahren, werden DFDs typischerweise in Ebenen organisiert. Diese Hierarchie stellt sicher, dass die Abstraktion konsistent bleibt, während Details hinzugefügt werden. Die folgende Tabelle zeigt die Standard-Ebenen der Zerlegung:
| Ebene | Gewöhnlicher Name | Beschreibung |
|---|---|---|
| 0 | Kontextdiagramm | Zeigt das gesamte System als einen einzigen Prozess, der mit externen Entitäten interagiert. |
| 1 | Ebene-0-Diagramm | Teilt den Hauptprozess in Hauptunterprozesse auf (normalerweise 3 bis 9). |
| 2 | Ebene-1-Diagramme | Zerlegt spezifische Ebene-0-Prozesse weiter in detaillierte Operationen. |
| 3+ | Kind-Diagramme | Tiefer Einblick in komplexe Logik für Implementierungsdetails. |
Jede Ebene muss dem Prinzip folgen, dassDatenbilanz. Das bedeutet, dass die Eingaben und Ausgaben eines übergeordneten Prozesses genau mit den kombinierten Eingaben und Ausgaben seiner untergeordneten Prozesse übereinstimmen müssen. Wenn ein Ebene-0-Prozess eine Eingabe von „Bestelldaten“ hat, müssen die Ebene-1-Unterprozesse gemeinsam „Bestelldaten“ akzeptieren und dürfen ohne Begründung keine neuen externen Eingaben einführen.
Schritt-für-Schritt-Zerlegungsstrategie 🚀
Die Durchführung einer Zerlegung erfordert einen systematischen Ansatz. Hastig das Zeichnen von Pfeilen beginnen führt oft zu strukturellen Fehlern. Die folgende Arbeitsabfolge stellt eine stabile Diagrammstruktur sicher.
1. Definieren Sie die Systemgrenze
Bevor Sie irgendetwas zeichnen, bestimmen Sie, was innerhalb des Systems und was außerhalb liegt. Diese Grenze definiert den Umfang des Projekts. Externe Entitäten befinden sich außerhalb dieser Grenze. Alles, was innerhalb der Grenze geschieht, ist ein Prozess oder eine Speicherung. Diese Definition verhindert einen Umfangsverlust während der Analysephase.
2. Erstellen Sie das Kontextdiagramm
Beginnen Sie mit der obersten Ebene. Plazieren Sie das System als eine einzelne Blase in der Mitte. Identifizieren Sie die wichtigsten externen Entitäten, die mit ihm interagieren. Zeichnen Sie die wichtigsten Datenflüsse zwischen ihnen. Dieses Diagramm bietet eine „Hubschrauberperspektive“ für die Stakeholder, um den Umfang zu bestätigen.
3. Identifizieren Sie die Hauptprozesse
Schauen Sie sich die Datenflüsse an, die in das System hinein- und aus dem System herausgehen. Jede eindeutige Transformation deutet auf einen Hauptprozess hin. Zum Beispiel, wenn „Kundendaten“ eintreffen und „Rechnungsdaten“ verlassen, ist die Transformation wahrscheinlich „Rechnung erstellen“. Gruppieren Sie diese in logische Cluster.
4. Gleichgewicht der Flüsse herstellen
Wenn Sie einen Prozess zerlegen, überprüfen Sie die Eingaben und Ausgaben. Stellen Sie sicher, dass keine Daten verschwinden (ein schwarzes Loch) und keine Daten aus dem Nichts erscheinen (ein Wunder). Jeder Pfeil, der in einen Unterprozess eintritt, muss durch die Daten, die ihn verlassen, erklärt werden.
5. Präzise Benennung
Die Beschriftung wird oft übersehen, ist aber entscheidend für die Lesbarkeit. Prozessnamen sollten Verben-Substantiv-Phrasen sein, wie beispielsweise „Bestellung validieren“ oder „Steuer berechnen“. Vermeiden Sie vage Bezeichnungen wie „Daten verarbeiten“. Die Bezeichnung muss die spezifische Transformation beschreiben, die stattfindet.
Häufige Fehler bei der Prozessmodellierung ⚠️
Selbst erfahrene Analysten stoßen bei der Modellierung von Datenflüssen auf Probleme. Die frühzeitige Erkennung dieser Muster kann erheblichen Umarbeitungsbedarf vermeiden. Folgendes sind häufige Fehler, die bei der Dekomposition beobachtet werden.
Datenbanken als Prozesse
Es ist verführerisch, eine Datenbank als Prozess zu behandeln, da Daten mit ihr interagieren. Eine Datenbank ist jedoch ein passiver Speicher. Sie transformiert Daten nicht, sondern hält sie lediglich. Ein Prozess muss mit einem Aktionsverb verbunden sein. Ein Speicher wird von einem Prozess aufgerufen, ist aber selbst kein Prozess.
Verbindung von Entitäten direkt
Daten können nicht direkt von einer externen Entität zur anderen fließen, ohne durch das System zu gehen. Wenn ein Kunde eine Anfrage sendet und eine Antwort erhält, müssen die Daten einen Prozess betreten, transformiert werden und anschließend verlassen. Eine direkte Verbindung zwischen zwei Entitäten impliziert, dass es sich um dieselbe Entität handelt oder das System umgangen wird.
Unbeschriftete Datenflüsse
Ein Pfeil ohne Beschriftung ist bedeutungslos. Er zeigt nicht an, welche Informationen fließen. Jeder Fluss muss benannt werden, beispielsweise „Lieferadresse“ oder „Zahlungsstatus“. Hier bestehende Unklarheiten führen später zu Implementierungsfehlern.
Inkonsistente Granularität
Ein Prozess könnte detailliert sein, während ein benachbarter Prozess ungenau ist. Diese Inkonsistenz verwirrt Leser. Wenn ein Unterverfahren in drei Schritte aufgeteilt wird, sollten benachbarte Prozesse auf einem vergleichbaren Detailgrad stehen, es sei denn, sie sind intrinsisch einfacher.
Integration von DFDs mit Geschäftsanforderungen 📝
Eine Darstellung ist nur dann nützlich, wenn sie tatsächlichen Geschäftsanforderungen entspricht. Datenflussdiagramme sollten nicht isoliert existieren. Sie müssen die visuelle Grundlage für die Dokumentation von Anforderungen bilden. Wenn eine Anforderung besagt, dass „Das System muss Kreditkarten validieren muss“, sollte das DFD einen Validierungsprozess zeigen, der Karteninformationen empfängt und einen Status-Flag ausgibt.
Diese Rückverfolgbarkeit ist für Audits und Compliance von entscheidender Bedeutung. In regulierten Branchen ist die Fähigkeit, nachzuweisen, woher Daten stammen und wie sie geschützt werden, obligatorisch. Das DFD liefert die Karte für Sicherheitsüberprüfungen. Analysten können identifizieren, wo sensible Daten fließen, und sicherstellen, dass entsprechende Kontrollen auf Prozessebene angewendet werden.
Best Practices für strukturiertes Modellieren ✅
Um eine hohe Qualität in Ihren Diagrammen zu gewährleisten, halten Sie sich an die folgenden Best Practices. Diese Richtlinien fördern Konsistenz und erleichtern die Wartung.
- Grenze die Verzweigungsanzahl:Vermeiden Sie die Verbindung eines einzelnen Prozesses mit mehr als neun Datenflüssen. Wenn ein Prozess so komplex ist, muss er wahrscheinlich weiter aufgeteilt werden.
- Konsistente Benennung:Verwenden Sie für Datenflüsse auf allen Ebenen die gleiche Terminologie. Wenn „Bestelldaten“ auf Ebene 0 verwendet wird, nennen Sie es auf Ebene 1 nicht „Kundenanfrage“.
- Logische Gruppierung:Gruppieren Sie verwandte Prozesse zusammen. Wenn eine Gruppe von Prozessen immer Finanzdaten verarbeitet, halten Sie sie visuell zusammengefasst, um die Verständlichkeit zu fördern.
- Regelmäßige Überprüfung:Geschäftsprozesse ändern sich. Ein DFD ist ein lebendiges Dokument. Planen Sie regelmäßige Überprüfungen, um sicherzustellen, dass das Diagramm die aktuellen Abläufe widerspiegelt.
- Nutzen Sie Leerraum:Drängen Sie keine Elemente zusammen. Ausreichender Abstand verringert die kognitive Belastung und macht das Diagramm leichter lesbar.
Die Rolle der Dekomposition im Systemdesign 🏗️
Abgesehen von der Dokumentation beeinflusst die Dekomposition von DFDs, wie Systeme gebaut werden. Wenn Prozesse klar definiert sind, können Entwicklungsteams Module bestimmten Entwicklern oder Teams zuweisen. Diese Modularität verringert die Abhängigkeiten zwischen Teams. Wenn Prozess A und Prozess B unabhängig sind, können sie parallel entwickelt werden.
Darüber hinaus hilft die Dekomposition bei der Identifizierung von Leistungsengpässen. Wenn ein bestimmter Unterverfahren excessive Ressourcen verbraucht oder erhebliche Verzögerungen verursacht, wird er zu einem Ziel für die Optimierung. Ohne die Dekomposition bleibt der Engpass in der monolithischen Sichtweise des Systems verborgen.
Es unterstützt auch Teststrategien. Testfälle können direkt aus den Datenflüssen abgeleitet werden. Wenn ein Prozess „Eingabe A“ in „Ausgabe B“ umwandelt, muss ein Testfall diese spezifische Transformation überprüfen. Diese Abstimmung zwischen Design und Test sorgt für eine höhere Qualität der Lieferung.
Umgang mit gleichzeitigen Prozessen und Schleifen 🔄
Realitätsnahe Geschäftsprozesse beinhalten oft Schleifen und gleichzeitige Aktionen. Ein standardmäßiger DFD stellt die Logik linear dar, doch Geschäftsregeln können iterativ sein. Zum Beispiel kann eine Bestellung mehrere Überprüfungsstufen erfordern, bevor sie genehmigt wird. In der Darstellung wird dies durch Datenflüsse dargestellt, die sich zurück zu vorherigen Prozessen schließen.
Beim Modellieren von Schleifen ist Klarheit entscheidend. Stellen Sie sicher, dass die Schleifenbedingung in der Prozessbeschreibung dokumentiert ist, nicht nur durch den Pfeil angedeutet. Ein Datenfluss, der zu einem Prozess zurückkehrt, deutet auf einen Nacharbeitungszyklus oder einen erneuten Validierungsversuch hin. Die explizite Angabe der Bedingung für diese Rückkehr vermeidet Unklarheiten für das Entwicklungsteam.
Gleichzeitige Prozesse werden durch parallele Flüsse dargestellt. Wenn zwei Prozesse gleichzeitig stattfinden, zeichnen Sie sie auf getrennten Zweigen. Denken Sie jedoch daran, dass DFDs keine Zeitpunkte oder Synchronisationsstellen zeigen. Diese Detailgenauigkeit gehört zu anderen Modellierungssprachen. Der DFD konzentriert sich auf das Vorhandensein des Flusses, nicht auf dessen zeitliche Abfolge.
Abschließende Überlegungen für Analysten 🤔
Die Beherrschung der Kunst der Dekomposition erfordert Übung und Geduld. Es ist eine Fähigkeit, die sich im Laufe der Zeit entwickelt, wenn Analysten unterschiedliche Arten von Geschäftslogik kennenlernen. Das Ziel ist nicht, das detaillierteste Diagramm zu erstellen, sondern das nützlichste.
Denken Sie daran, dass das Diagramm ein Kommunikationsinstrument ist. Sein primärer Publikum sind oft nicht-technische Stakeholder, die die Informationsflüsse verstehen müssen. Wenn das Diagramm zu technisch ist, verfehlt es seine Aufgabe. Passen Sie das Abstraktionsniveau an das Fachwissen der Zielgruppe an.
Die Dokumentation sollte immer die Entscheidungsfindung unterstützen. Wenn ein Geschäftsführer fragt, wo ein bestimmter Datenpunkt herkommt, sollte der DFD die Antwort schnell liefern. Diese Zuverlässigkeit stärkt das Vertrauen in die Analysefunktion. Im Laufe der Zeit wird die Sammlung von Diagrammen zu einem wertvollen Gut für die Organisation und dient als Referenz für zukünftige Systemänderungen.
Wenn Systeme sich weiterentwickeln, müssen auch die Diagramme mit ihnen fortschreiten. Veraltete Diagramme sind schlimmer als gar keine, weil sie irreführen. Verpflichten Sie sich, die Integrität der Datenflussmodelle aufrechtzuerhalten. Behandeln Sie sie mit derselben Sorgfalt wie den Code, der letztendlich geschrieben wird, um sie zu unterstützen. Diese Disziplin stellt sicher, dass die Geschäftslogik transparent und zugänglich bleibt.
Letztendlich liegt der Wert in der gewonnenen Klarheit. Indem Analysten das Komplexe in Verständliches zerlegen, befähigen sie ihre Organisationen, effizienter zu arbeiten. Der strukturierte Ansatz von Datenflussdiagrammen bietet die Grundlage für diese Klarheit und verwandelt Chaos in Ordnung.