











In der komplexen Architektur moderner verteilter Systeme ist Zeit nicht lediglich eine zu messende Größe; sie ist eine grundlegende Beschränkung, die das Systemverhalten bestimmt. Die Softwarezuverlässigkeit geht nicht allein darum, Abstürze zu verhindern oder Ausnahmen zu behandeln; es geht vielmehr darum, sicherzustellen, dass Komponenten innerhalb bestimmter zeitlicher Grenzen korrekt miteinander interagieren. Wenn mehrere Threads, Dienste oder Hardwaregeräte versuchen, auf gemeinsame Ressourcen zuzugreifen, werden die Reihenfolge und Dauer dieser Interaktionen entscheidend. Genau hier werden Zeitverlaufsdiagramme unverzichtbar.
Zeitverlaufsdiagramme bieten eine visuelle Darstellung, wie Signale oder Nachrichten im Laufe der Zeit ihren Zustand ändern. Sie ermöglichen es Ingenieuren, die zeitlichen Beziehungen zwischen Ereignissen zu modellieren, noch bevor eine einzige Codezeile ausgeführt wird. Durch die Visualisierung des Zeitverlaufs können Teams potenzielle Engpässe, Rennbedingungen und Synchronisationsfehler erkennen, die in statischen Flussdiagrammen oder Sequenzdiagrammen oft unsichtbar sind. Dieser Leitfaden untersucht die Mechanismen des Einsatzes von Zeitverlaufsdiagrammen zur Verbesserung der Softwarezuverlässigkeit und bietet einen tiefen Einblick in Konkurrenz, Latenzanalyse und Systemvalidierung.
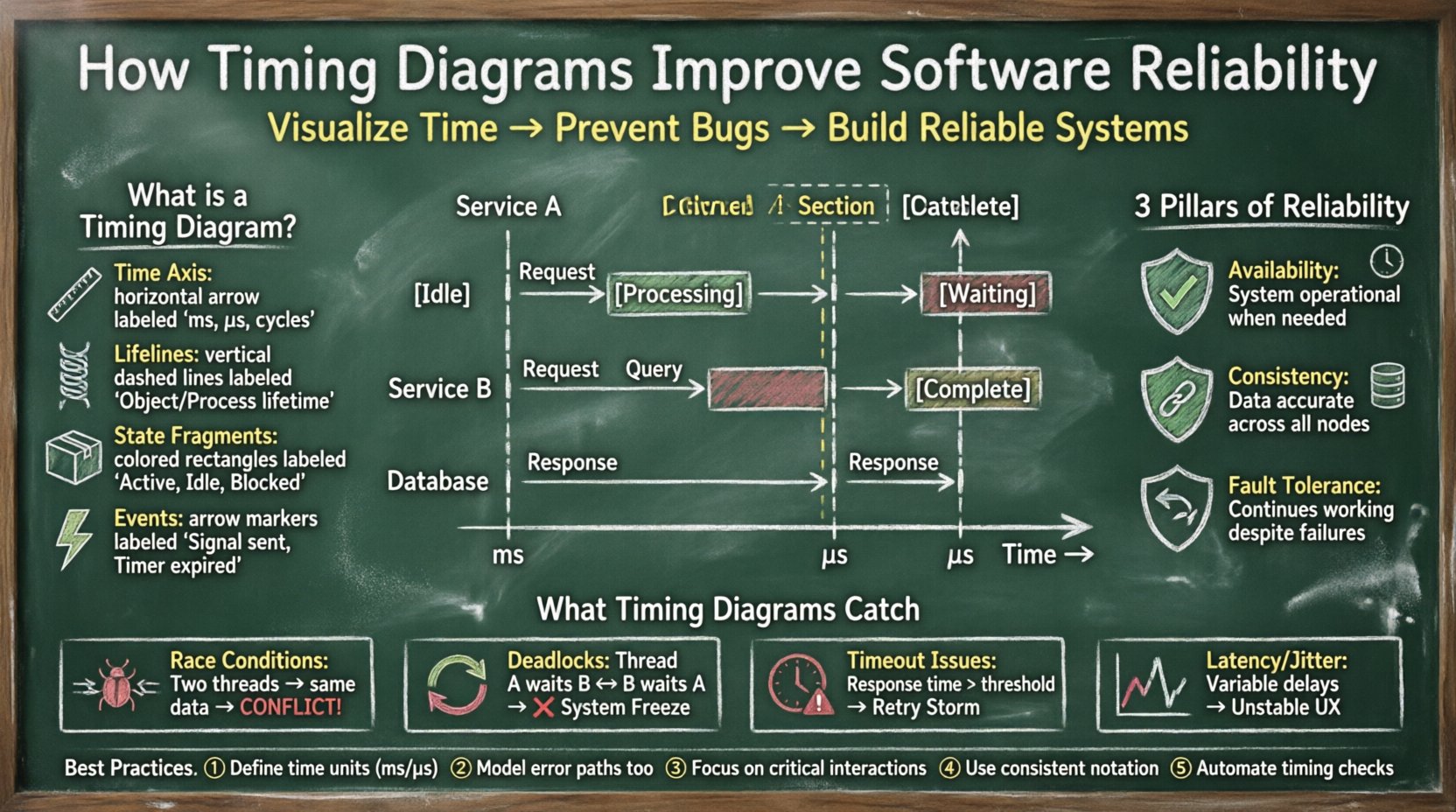
🔍 Definition von Zeitverlaufsdiagrammen in der Ingenieurwissenschaft
Ein Zeitverlaufsdiagramm ist eine Art von Verhaltensdiagramm in der Systemmodellierung, das das Verhalten von Objekten über die Zeit beschreibt. Im Gegensatz zu einem Sequenzdiagramm, das sich hauptsächlich auf die Reihenfolge der Nachrichten konzentriert, legt ein Zeitverlaufsdiagramm den Fokus auf die zeitlichen Beziehungen zwischen Ereignissen. Es zeigt die Zustände von Objekten und die Übergänge zwischen ihnen entlang einer horizontalen Zeitachse.
- Zeitachse: Läuft typischerweise horizontal von links nach rechts und stellt die Fortschreitung der Zeit in Millisekunden, Mikrosekunden oder Taktzyklen dar.
- Lebenslinien:Vertikale Balken, die die Existenz eines Objekts oder Prozesses über die Zeit darstellen.
- Zustandsfragmente:Rechteckige Bereiche auf der Lebenslinie, die den Zustand des Objekts anzeigen (z. B. Aktiv, Leerlauf, Blockiert, Verarbeitung).
- Ereignisse:Pfeile oder Markierungen, die anzeigen, wann eine bestimmte Aktion erfolgt, beispielsweise das Senden eines Signals oder das Ablaufen eines Timers.
Durch die Abbildung dieser Elemente erstellen Entwickler eine Zeitachse der Systemoperationen. Dieser visuelle Kontext ist entscheidend, um zu verstehen, wie lange ein Prozess zur Vollendung benötigt und wie er auf andere Prozesse wartet. Er wandelt abstraktes Logik in eine greifbare Zeitachse um, die auf Fehler analysiert werden kann.
🏗️ Die zentralen Säulen der Softwarezuverlässigkeit
Zuverlässigkeit in der Softwaretechnik bezieht sich auf die Wahrscheinlichkeit, dass ein System seine erforderlichen Funktionen unter genannten Bedingungen für einen festgelegten Zeitraum erfüllt. Um dies zu erreichen, müssen drei zentrale Säulen berücksichtigt werden:
- Verfügbarkeit:Das System muss jederzeit einsatzbereit sein, wenn es benötigt wird. Zeitverlaufsdiagramme helfen dabei, zu überprüfen, ob Wiederherstellungsprozesse innerhalb akzeptabler Zeiträume abgeschlossen werden.
- Konsistenz:Daten müssen über verteilte Knoten hinweg genau bleiben. Die Visualisierung von Schreib- und Leseoperationen hilft sicherzustellen, dass die Datenintegrität durch Latenz nicht beeinträchtigt wird.
- Fehlertoleranz:Das System muss auch bei Ausfällen weiterarbeiten. Zeitverlaufsdiagramme zeigen, wie lange ein Fallback-Mechanismus benötigt, um einzuschalten, und stellen sicher, dass der Benutzer keine Dienstunterbrechung wahrnimmt.
Ohne ein klares Verständnis der zeitlichen Beschränkungen könnte ein System logisch korrekt sein, aber praktisch unzuverlässig. Beispielsweise könnte eine Datenbankabfrage die richtigen Daten zurückgeben, aber wenn sie 10 Sekunden zum Verarbeiten benötigt, verstößt sie gegen die Zuverlässigkeitsanforderung einer reaktionsfreudigen Benutzeroberfläche. Zeitverlaufsdiagramme bringen solche zeitlichen Verstöße ans Licht.
🐞 Erkennen von Rennbedingungen durch visuelle Analyse
Eine Rennbedingung tritt auf, wenn zwei oder mehr Prozesse gleichzeitig auf gemeinsame Daten zugreifen, und das Endergebnis von der relativen Ausführungsreihenfolge abhängt. Diese sind berüchtigt dafür, schwer zu debuggen zu sein, da sie nicht-deterministisch sind und oft verschwinden, wenn Debugger angehängt werden.
Zeitverlaufsdiagramme mindern dieses Risiko, indem sie eine strenge visuelle Reihenfolge der Ereignisse erzwingen. Beim Modellieren einer potenziellen Rennbedingung kann ein Ingenieur die Lebenslinien der konkurrierenden Threads zeichnen. Wenn das Diagramm zeigt, dass beide Threads gleichzeitig versuchen, an die gleiche Speicherstelle zu schreiben, ohne dass eine Synchronisationssperre vorhanden ist, ist der Fehler sofort sichtbar.
- Visualisierung kritischer Abschnitte:Hervorheben der Dauer, in der eine Ressource gesperrt ist. Wenn ein anderer Prozess während dieses Zeitfensters auf den Zugriff versucht, zeigt das Diagramm einen Konflikt an.
- Erkennen von Störungen:Bei Hardware-Software-Schnittstellen können Signalstörungen auftreten, wenn Setup- und Hold-Zeiten nicht eingehalten werden. Zeitverlaufsdiagramme zeigen diese Fenster explizit an.
- Abhängigkeiten der Reihenfolge: Stellen Sie sicher, dass die Initialisierung A abgeschlossen ist, bevor die Initialisierung B beginnt. Das Diagramm erzwingt eine zeitliche Überprüfung dieser Abhängigkeit.
Durch die Behebung dieser Probleme in der Entwurfsphase sinkt die Wahrscheinlichkeit von Produktionsfehlern erheblich. Es verlagert die Erkennung von Konkurrenzfehlern von Laufzeitprotokollen zu Entwurfsüberprüfungen.
🧵 Verwaltung von Konkurrenz und Thread-Synchronisation
Moderne Anwendungen verlassen sich stark auf asynchrone Verarbeitung, um hohe Lasten zu bewältigen. Threads, Coroutinen und Worker-Pools ermöglichen die parallele Ausführung mehrerer Aufgaben. Allerdings führen Synchronisationsprimitive wie Mutexes, Semaphoren und Sperren eigene zeitliche Komplexitäten ein.
Zeitdiagramme unterstützen bei der Modellierung dieser Synchronisationspunkte. Sie helfen dabei, Fragen wie folgende zu beantworten:
- Wie lange wartet ein Thread auf eine Sperre, bevor ein Zeitüberschreitung eintritt?
- Variiert die Zeit zur Erhaltung einer Sperre je nach Systemlast?
- Gibt es Deadlocks, bei denen zwei Threads sich gegenseitig unendlich lange warten?
Beim Entwurf einer mehrthreadigen Anwendung können Ingenieure den Zustand jedes Threads skizzieren. Wenn Thread A Ressource 1 hält und auf Ressource 2 wartet, während Thread B Ressource 2 hält und auf Ressource 1 wartet, kann ein Zeitdiagramm die zirkuläre Wartezustandsbedingung aufzeigen. Dieser visuelle Beweis ermöglicht die Umstrukturierung der Ressourcenbeschaffungslogik, bevor die Implementierung beginnt.
Darüber hinaus klären Zeitdiagramme das Verhalten der Prioritätsinversion. In Echtzeitsystemen könnte eine hochpriorisierte Aufgabe durch eine niedrigpriorisierte Aufgabe blockiert werden, die eine Sperre hält. Ein Zeitdiagramm macht diese Prioritätsinversion offensichtlich und ermöglicht es Architekten, Protokolle zur Prioritätsvererbung zu implementieren.
🌐 Netzwerkprotokolle und Handshake-Überprüfung
In verteilten Systemen ist die Netzwerklatenz eine Variable, die nicht ignoriert werden kann. Protokolle wie TCP/IP, HTTP/2 und gRPC setzen auf Handshakes, um Verbindungen herzustellen. Zeitdiagramme sind entscheidend für die Validierung dieser Interaktionen.
Betrachten Sie einen Standard-Handshake mit drei Schritten (SYN, SYN-ACK, ACK). Ein Zeitdiagramm ermöglicht es Ingenieuren, eine maximal zulässige Dauer für diesen Vorgang festzulegen. Wenn das Diagramm zeigt, dass der ACK länger dauert als der konfigurierte Timeout-Schwellwert, ist die Verbindung unter Belastung wahrscheinlich fehlgeschlagen.
- Timeout-Konfiguration: Definieren Sie die genaue Millisekunden-Dauer für eine Anfrage, bevor ein Neustart ausgelöst wird.
- Wiederholungslogik:Visualisieren Sie die Lücke zwischen einem fehlgeschlagenen Paket und seiner Wiederholung, um sicherzustellen, dass das Netzwerk nicht überflutet wird.
- Keep-Alive-Intervalle:Stellen Sie sicher, dass das Intervall zwischen Keep-Alive-Nachrichten kürzer ist als der Netzwerk-Idle-Timeout, um eine vorzeitige Trennung zu verhindern.
Durch die Modellierung dieser Netzwerkinteraktionen können Teams sicherstellen, dass ihre Software Netzwerkjitter reibungslos bewältigt. Dies verhindert kaskadenartige Ausfälle, bei denen eine langsame Antwort von einem Mikrodienst die gesamte Frontend-Verarbeitung blockiert.
⚙️ Hardware-Software-Schnittstellen-Zeitgestaltung
Die Zuverlässigkeit von Software hängt oft davon ab, wie gut sie mit der Hardware interagiert. Eingebettete Systeme, IoT-Geräte und Hochfrequenz-Handelsplattformen erfordern präzise Zeitgestaltung. Eine Verzögerung von einigen Mikrosekunden kann zu Datenkorruption oder finanziellen Verlusten führen.
Interrupt-Service-Routinen (ISRs) sind ein Paradebeispiel. Wenn ein Hardware-Interrupt eintritt, muss die CPU aktuelle Aufgaben pausieren, um ihn zu bearbeiten. Ein Zeitdiagramm zeigt die Interrupt-Latenz (Zeit von der Interrupt-Anforderung bis zum ISR-Eintritt) und die Interrupt-Antwortzeit auf.
- Interrupt-Latenz:Die Zeit, die benötigt wird, um den Interrupt zu bestätigen.
- Overhead beim Kontextwechsel:Die Zeit, die beim ISR gespeichert und wiederhergestellt wird.
- Register-Schutz:Sicherstellen, dass der Zustand gespeichert wird, bevor der ISR ihn modifiziert.
Wenn das Zeitdiagramm zeigt, dass der ISR zu lange dauert, kann er andere kritische Interrupts blockieren. Diese visuelle Analyse ermöglicht es Entwicklern, den ISR-Code zu optimieren oder die Verarbeitung auf einen Hintergrundthread auszulagern, um sicherzustellen, dass die Echtzeitanforderungen erfüllt werden.
📉 Identifizieren von Latenz- und Jitterproblemen
Latenz ist die Verzögerung, die vor Beginn einer Datenübertragung auftritt, nachdem eine Anweisung zur Übertragung erteilt wurde. Jitter ist die Schwankung der Latenz über die Zeit. Beides ist nachteilig für die Benutzererfahrung und die Systemstabilität. Zeitdiagramme sind das primäre Werkzeug zur Analyse dieser Metriken.
Beim Modellieren eines Anfrage-Antwort-Zyklus können Ingenieure die genauen Punkte markieren, an denen die Verarbeitung stattfindet. Zum Beispiel:
- Wartezeit in der Warteschlange: Wie lange befindet sich eine Anfrage im Puffer, bevor sie verarbeitet wird?
- Verarbeitungszeit: Wie lange dauert die Ausführung der Logik tatsächlich?
- Netzwerkübertragung: Wie lange dauert es, bis die Daten über das Kabel reisen?
Durch Addition dieser Segmente wird die Gesamtlatenz berechnet. Wenn der Jitter hoch ist, zeigt das Zeitdiagramm unregelmäßige Abstände zwischen Ereignissen über mehrere Durchläufe hinweg. Diese Unregelmäßigkeit signalisiert eine Instabilität in der zugrundeliegenden Infrastruktur und fordert eine weitere Untersuchung auf Ressourcenkonflikte oder Netzwerküberlastung.
📝 Dokumentieren von Systemwechselwirkungen
Dokumentation wird oft bei der Suche nach Funktionalität übersehen, ist aber für die langfristige Zuverlässigkeit entscheidend. Der Code ändert sich häufig, und neue Teammitglieder treten regelmäßig hinzu. Zeitdiagramme dienen als dauerhafte Referenz dafür, wie das System im Laufe der Zeit reagiert.
Ein gut gepflegtes Set an Zeitdiagrammen bietet:
- Onboarding-Material:Neue Entwickler können den zeitlichen Ablauf verstehen, ohne Tausende von Codezeilen lesen zu müssen.
- Hilfe beim Debugging:Wenn ein Fehler auftritt, können Ingenieure das tatsächliche Verhalten mit dem dokumentierten Zeitdiagramm vergleichen, um Abweichungen zu erkennen.
- Vertragsdefinition: Sie definieren das erwartete Verhalten zwischen Diensten und fungieren als Vertrag für die Integration.
Diese Dokumentation verringert die kognitive Belastung der Ingenieure bei der Reaktion auf Vorfälle. Anstatt die Zeitpunkte von Ereignissen zu raten, haben sie eine visuelle Referenz, der sie folgen können.
⚠️ Häufige Zeitverletzungen
Nicht alle Zeitprobleme sind gleich. Einige sind kritische Ausfälle, während andere eine Leistungsverschlechterung darstellen. Die folgende Tabelle kategorisiert häufige Verstöße, die bei der Systemmodellierung auftreten.
| Verstoßart | Beschreibung | Auswirkung auf die Zuverlässigkeit |
|---|---|---|
| Setup-Zeit-Verstoß | Die Daten sind vor dem Taktrand nicht stabil. | Unvorhersehbare Zustandsänderungen, Hardwareausfall. |
| Hold-Zeit-Verstoß | Daten ändern sich zu früh nach der Taktränder. | Datenkorruption, Metastabilität. |
| Zeitüberschreitung abgelaufen | Die Operation dauert länger als die definierte Grenze. | Dienstunzugänglichkeit, Wiederholungsstürme. |
| Totalsperre | Zwei Prozesse warten unendlich lange aufeinander. | Systemeinfrieren, Ressourcenknappheit. |
| Prioritätsinversion | Aufgabe mit hoher Priorität wartet auf Aufgabe mit niedriger Priorität. | Verpasste Fristen, Echtzeitfehler. |
| Pufferüberlauf | Daten treffen ein, schneller als sie verarbeitet werden können. | Paketverlust, Speicherauslastung. |
Die Überprüfung dieser Kategorien anhand der Zeitdiagramme Ihres Systems hilft dabei, festzulegen, welche Probleme sofort behoben werden müssen. Hardwareverstöße erfordern oft Firmware-Updates, während Software-Timeouts möglicherweise eine Umstrukturierung der Logik erfordern.
🔄 Integration in den Entwicklungslebenszyklus
Um Zeitdiagramme effektiv für die Zuverlässigkeit einzusetzen, müssen sie in den Softwareentwicklungslebenszyklus (SDLC) integriert werden. Sie sollten kein nachträglicher Zusatz nach der Bereitstellung sein.
- Entwurfsphase: Erstellen Sie hochwertige Zeitdiagramme während der Überprüfung der Systemarchitektur. Identifizieren Sie kritische Pfade und zeitliche Beschränkungen.
- Implementierungsphase: Verwenden Sie Zeitdiagramme zur Leitung der Einheitstests. Stellen Sie sicher, dass Einheitstests die zeitlichen Grenzen abdecken, nicht nur die logische Korrektheit.
- Integrationsphase: Führen Sie eine zeitliche Analyse auf integrierten Komponenten durch. Stellen Sie sicher, dass das kombinierte System die globalen zeitlichen Anforderungen erfüllt.
- Testphase: Verwenden Sie Lasttestwerkzeuge, um zeitliche Daten zu generieren. Vergleichen Sie die tatsächlichen Zeitprotokolle mit den ursprünglichen Diagrammen.
- Wartungsphase: Aktualisieren Sie die Diagramme, wenn Codeänderungen die Zeitplanung beeinflussen. Stellen Sie sicher, dass die Dokumentation mit dem Codebestand synchronisiert bleibt.
Diese Integration stellt sicher, dass zeitliche Überlegungen in jeder Phase der Entwicklung berücksichtigt werden, wodurch die Kosten für die Behebung von Zuverlässigkeitsproblemen später im Prozess reduziert werden.
📊 Messung der Zuverlässigkeitsverbesserungen
Wie quantifizieren Sie den Nutzen der Verwendung von Zeitdiagrammen? Während die Zuverlässigkeit oft in Prozenten der Betriebszeit gemessen wird, tragen Zeitdiagramme zu spezifischen Metriken bei:
- Durchschnittliche Zeit zwischen Ausfällen (MTBF): Durch die Verhinderung von Race Conditions und Deadlocks verringert sich die Häufigkeit von Ausfällen.
- Durchschnittliche Reparaturzeit (MTTR): Bessere Dokumentation und visuelle Protokolle reduzieren die Zeit, die zur Diagnose von Problemen benötigt wird.
- Latenz-Perzentile: Die Latenzwerte P99 und P999 werden stabiler, wenn zeitliche Engpässe früh erkannt werden.
- Ressourcennutzung: Die Optimierung von Wartezeiten reduziert die Leerlaufzeit des CPUs und verbessert die Gesamt throughput.
Die Verfolgung dieser Metriken über die Zeit ermöglicht es Teams, die direkte Korrelation zwischen sorgfältiger Zeitmodellierung und Systemstabilität zu erkennen. Es verlagert die Zuverlässigkeit von einem qualitativen Ziel hin zu einer quantitativen Realität.
💡 Zusammenfassung der Best Practices
Um die Wirkung von Zeitdiagrammen auf die Softwarezuverlässigkeit zu maximieren, sollten folgende Praktiken befolgt werden:
- Definieren Sie klare Zeiteinheiten: Geben Sie immer die Zeiteinheit (ms, s, Zyklen) an, um Unklarheiten zu vermeiden.
- Fügen Sie Fehlerzustände hinzu: Modellieren Sie nicht nur den glücklichen Pfad, sondern auch Timeout-Pfade und Fehlerbehandlungswege.
- Konzentrieren Sie sich auf kritische Pfade: Zeichnen Sie nicht jede einzelne Operation auf. Konzentrieren Sie sich auf die Interaktionen, die die Systemstabilität beeinflussen.
- Verwenden Sie eine konsistente Notation: Übernehmen Sie eine standardisierte Notation für Lebenslinien und Ereignisse, um ein einheitliches Verständnis im Team zu gewährleisten.
- Automatisieren Sie, wo möglich: Integrieren Sie Werkzeuge zur Zeitanalyse in die CI/CD-Pipeline, um Regressionen automatisch zu erkennen.
Die Softwarezuverlässigkeit ist eine kontinuierliche Anstrengung. Sie erfordert Aufmerksamkeit, präzises Modellieren und ein tiefes Verständnis dafür, wie Zeit das Systemverhalten beeinflusst. Zeitdiagramme bieten die visuelle Klarheit, die benötigt wird, um diese Komplexität zu meistern. Durch die Umsetzung dieser Praktiken können Ingenieurteams Systeme entwickeln, die nicht nur funktional, sondern auch robust, vorhersehbar und widerstandsfähig gegenüber der unvorhersehbaren Natur der Zeit sind.
Wenn Sie die Zeit visualisieren, gewinnen Sie die Kontrolle darüber. Diese Kontrolle übersetzt sich direkt in Zuverlässigkeit. Je verteilter und komplexer die Systeme werden, desto mehr wird die Fähigkeit, zeitliche Beziehungen zu modellieren, zu einem Wettbewerbsvorteil. Sie unterscheidet Systeme, die lediglich funktionieren, von solchen, die unter Druck konsistent funktionieren.