











In der komplexen Landschaft der Softwareentwicklung ist Klarheit Währung. Architekten und technische Schreiber stehen oft vor der Herausforderung, wie Daten durch ein System fließen, ohne die Stakeholder in Code- oder Konfigurationsdateien zu ertränken. Hier kommt das Datenflussdiagramm (DFD) als unverzichtbares Werkzeug ins Spiel. Die Integration von DFDs in die Architekturdokumentation schließt die Lücke zwischen abstrakter Logik und konkreter Implementierung und bietet eine visuelle Sprache, die Entwickler, Produktmanager und Prüfer alle verstehen können.
Dieser Leitfaden untersucht die Mechanismen der Einbindung von Datenflussdiagrammen in Ihre architektonischen Aufzeichnungen. Er behandelt die grundlegenden Konzepte, den Integrationsprozess, Wartungsstrategien und bewährte Praktiken, um sicherzustellen, dass Ihre Dokumentation eine zuverlässige Quelle der Wahrheit bleibt. Durch die Anwendung dieser Methoden erstellen Sie ein lebendiges Dokument, das der Systementwicklung dient, anstatt zu einer statischen Reliquie zu werden.
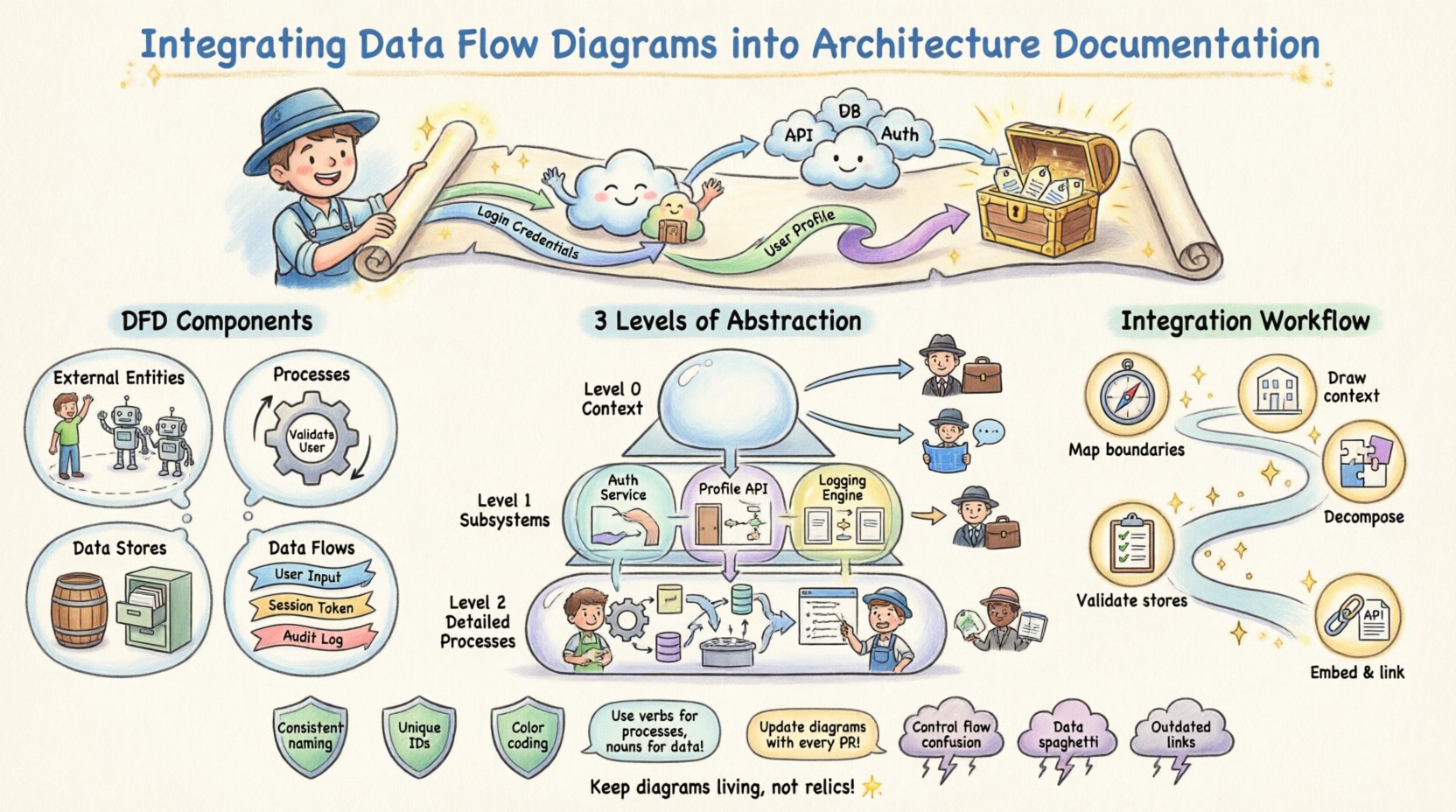
🤔 Verständnis von Datenflussdiagrammen in der Systemgestaltung
Ein Datenflussdiagramm stellt den Fluss von Informationen durch ein System dar. Im Gegensatz zu Flussdiagrammen, die den Steuerfluss und die Entscheidungslogik betonen, konzentrieren sich DFDs ausschließlich auf die Datenbewegung. Sie zeigen, wo Daten entstehen, wie sie sich verändern, wo sie gespeichert werden und wo sie schließlich verlassen werden. Diese Unterscheidung ist für die Architekturdokumentation von entscheidender Bedeutung, da sie die informationsbasierte Grundstruktur der Anwendung von der prozeduralen Logik trennt, die sie ausführt.
Wenn Sie DFDs in Ihr Architekturpaket aufnehmen, liefern Sie eine Karte der kognitiven Belastung des Systems. Stakeholder können einen Datenbestand von der Aufnahme bis zur Speicherung und Abruf verfolgen, ohne die zugrundeliegende Code-Logik verstehen zu müssen. Diese Abstraktion ist für die Entscheidungsfindung auf höherer Ebene und die Compliance-Prüfung unerlässlich.
- Externe Entitäten: Stellen Benutzer, Systeme oder Organisationen dar, die mit dem System interagieren, aber außerhalb seiner Grenzen liegen.
- Prozesse: Transformationen oder Berechnungen, die an den Daten durchgeführt werden. Es handelt sich nicht um Code-Funktionen, sondern um logische Operationen.
- Datenbanken: Speicherorte, an denen Daten ruhen, wie Datenbanken, Dateisysteme oder Protokolle.
- Datenflüsse: Die Bewegung von Daten zwischen Entitäten, Prozessen und Speichern, typischerweise beschriftet mit dem Namen des übertragenen Datenbestands.
Durch die klare Definition dieser Komponenten schaffen Sie eine einheitliche Fachsprache. Dies verringert die Mehrdeutigkeit bei Diskussionen über das Systemverhalten durch Ingenieure und stellt sicher, dass „die Benutzerprofil-Daten“ in Backend, Frontend und Dokumentation dasselbe Entität bezeichnen.
📈 Warum DFDs für die Architekturdokumentation entscheidend sind
Die Integration von DFDs geht nicht nur darum, Bilder zu zeichnen; es geht darum, die Nutzbarkeit der Dokumentation selbst zu verbessern. Ein gut strukturiertes DFD bringt in mehreren Schlüsselbereichen spezifischen Wert für die Architekturdokumentation.
🔍 Verbesserte Kommunikation
Visuelle Modelle reduzieren die kognitive Belastung, die zum Verständnis von Systemwechselwirkungen erforderlich ist. Textliche Beschreibungen können oft die bidirektionale Natur von Datenwechseln nicht erfassen. Ein Diagramm zeigt die Richtung sofort. Wenn ein neuer Entwickler ein Projekt beitritt, kann er sich das DFD ansehen, um die grobe Datenarchitektur zu verstehen, bevor er in das Repository eintaucht.
🛡️ Sicherheits- und Compliance-Prüfung
Für regulierte Branchen ist die Verfolgung der Datenherkunft eine Voraussetzung. DFDs zeigen explizit, wo sensible Daten gespeichert werden und wie sie zwischen Prozessen fließen. Dadurch wird es einfacher, potenzielle Sicherheitslücken wie unverschlüsselte Datenübertragungen oder unbefugten Zugriffspunkte auf Datenspeicher zu identifizieren.
🔄 System-Onboarding
Die Onboarding-Zeit wird verkürzt, wenn visuelle Hilfsmittel zur Verfügung stehen. Anstatt Hunderte von Seiten an API-Spezifikationen zu lesen, kann ein neues Teammitglied den Ablauf des Systems innerhalb einer Stunde verstehen. Dies beschleunigt die Zeit bis zur Produktivität für technische Ressourcen.
📂 Abstraktionsstufen: Kontext, Ebene 0 und Ebene 1
Effektive Architekturdokumentation verlässt sich nicht auf ein einziges Diagramm. Stattdessen nutzt sie eine Hierarchie von DFDs, um die richtige Detailtiefe für unterschiedliche Zielgruppen bereitzustellen. Dieser schichtweise Ansatz verhindert Informationsüberlastung, während die notwendige Detaillierung erhalten bleibt.
| Diagrammebene | Schwerpunkt | Zielgruppe | Anwendungsfall |
|---|---|---|---|
| Kontextdiagramm (Ebene 0) | System als einzelner Prozess, der mit externen Entitäten interagiert. | Führungsebene, Produktmanager | Definition des Hochniveaus und Identifizierung der Grenzen. |
| Diagramm der Ebene 1 | Hauptuntersysteme und primäre Datenbanken. | Systemarchitekten, Hauptentwickler | Verständnis der Hauptfunktionsblöcke und Datenspeicherung. |
| Diagramm der Ebene 2 | Tiefgang in spezifische komplexe Prozesse. | Backend-Entwickler, QA-Spezialisten | Implementierungsdetails und spezifische Datenumwandlungen. |
Beim Einbinden dieser Diagramme in Ihre Dokumentation stellen Sie sicher, dass jeder Level eindeutig gekennzeichnet ist. Mischen Sie keine detaillierten Informationen in eine Übersicht auf hoher Ebene. Das Kontextdiagramm sollte niemals interne Prozesse zeigen, sondern nur die Systemgrenze. Diese Disziplin bewahrt die Integrität der Abstraktion.
🔄 Schritt-für-Schritt-Integrationsworkflow
Die Integration von DFDs ist kein einmaliger Vorgang. Es handelt sich um einen Workflow, der parallel zum Entwicklungslebenszyklus läuft. Nachfolgend finden Sie einen strukturierten Ansatz zur effektiven Einbindung dieser Diagramme.
1. Identifizieren der Daten-Grenzen
Bevor Sie zeichnen, definieren Sie den Umfang. Was ist im System enthalten? Was ist extern? Listen Sie alle externen Entitäten (Benutzer, Drittanbieter-APIs) und internen Datenbanken auf. Diese Liste wird zur Bestandsaufnahme für Ihr Diagramm.
2. Abbildung der Hochniveau-Flüsse
Erstellen Sie zunächst das Kontextdiagramm. Zeichnen Sie das System als zentralen Kreis oder Kasten. Verbinden Sie alle externen Entitäten mit diesem Zentrum mittels Pfeilen. Beschriften Sie jeden Pfeil mit dem spezifischen Datenaustausch (z. B. „Anmeldeinformationen“, „Rechnungsdaten“, „Benutzerprofilaktualisierung“).
3. Prozesse zerlegen
Nehmen Sie den zentralen Prozess aus dem Kontextdiagramm und zerlegen Sie ihn in Unterverfahren. Dies wird das Diagramm der Ebene 1. Stellen Sie sicher, dass jeder Datenfluss aus der höheren Ebene in der unteren Ebene berücksichtigt wird. Führen Sie keine neuen externen Entitäten ein, es sei denn, sie wurden zuvor vergessen.
4. Validierung der Datenbanken
Überprüfen Sie jede Datenbank. Ist sie schreibgeschützt? Ist sie schreib-only? Bleibt die Daten dauerhaft erhalten? Dokumentieren Sie diese Attribute zusammen mit dem Diagramm in Ihren Architekturnotizen. Dies verhindert Annahmen über die Dauerhaftigkeit der Daten.
5. Einbetten und Verknüpfen
Platzieren Sie die Diagramme im Dokumentations-Repository. Verwenden Sie Hyperlinks, um das Diagramm mit relevanten API-Spezifikationen oder Datenbank-Schemata zu verknüpfen. Wenn sich ein Prozess ändert, aktualisieren Sie das Diagramm und die verknüpfte Dokumentation gleichzeitig.
🛡️ Best Practices für Klarheit und Konsistenz
Um sicherzustellen, dass die DFDs über die Zeit nutzbar bleiben, ist die strikte Einhaltung von Notation und Namenskonventionen erforderlich. Inkonsequenzen führen zu Verwirrung, was dem Zweck des Diagramms widerspricht.
- Konsistente Namenskonventionen:Verwenden Sie ein standardisiertes Format für Beschriftungen. Verwenden Sie beispielsweise immer Verben für Prozesse (z. B. „Benutzer validieren“) und Nomen für Datenflüsse (z. B. „Benutzereingabe“). Mischen Sie niemals Verben und Nomen innerhalb desselben Diagramms.
- Eindeutige Prozessidentifikation:Nummerieren Sie Ihre Prozesse sequenziell. Dies erleichtert die Referenzierung spezifischer Transformationen während Code-Reviews (z. B. „Prozess 3.1 überprüfen“).
- Kreuzungen minimieren: Versuchen Sie, die Elemente so anzuordnen, dass sich Linien möglichst wenig kreuzen. Wenn Linien notwendigerweise kreuzen müssen, verwenden Sie eine Brückennotation, um anzugeben, dass sie nicht verbunden sind. Dies verbessert die Lesbarkeit erheblich.
- Logische Gruppierung: Gruppieren Sie verwandte Prozesse visuell zusammen. Wenn drei Prozesse Zahlungen verarbeiten, platzieren Sie sie in einer Gruppe. Dies hilft dem Leser, funktionale Bereiche auf einen Blick zu verstehen.
- Farbcodierung: Verwenden Sie subtile Farbvariationen, um verschiedene Datentypen oder Sicherheitsstufen zu unterscheiden. Zum Beispiel rote Rahmen für sensible Datenströme und grüne für öffentliche Daten.
Die Dokumentation sollte niemals darauf verlassen, dass der Leser vorherige Kenntnisse besitzt. Jeder Pfeil, jedes Feld und jedes Label muss selbstverständlich verständlich sein oder mit einem Glossar innerhalb der Dokumentation verknüpft sein.
🧹 Wartungs- und Versionskontrollstrategien
Ein Diagramm, das nicht mit dem Code übereinstimmt, ist schlimmer als gar kein Diagramm. Es erzeugt ein falsches Gefühl der Sicherheit und täuscht Ingenieure. Daher ist die Wartung die kritischste Phase der DFD-Integration.
📝 Versionsverwaltung
Fügen Sie Versionsnummern in die Fußzeile jedes Diagramms ein. Verknüpfen Sie die Diagrammversion mit der Release-Version der Software. Wenn eine Funktion veraltet ist, archivieren Sie das alte Diagramm stattdessen, dass Sie es löschen. Dadurch wird die Historie der Datenflussänderungen für zukünftige Fehlersuche erhalten.
🔄 Änderungsmanagement
Integrieren Sie DFD-Updates in den Pull-Request-Workflow. Wenn ein Entwickler ein Datenspeicher-Element ändert oder einen neuen API-Endpunkt hinzufügt, muss er das entsprechende DFD aktualisieren. Dadurch wird sichergestellt, dass die Dokumentation Teil der „Fertigstellung“ ist.
📅 Regelmäßige Audits
Planen Sie vierteljährliche Überprüfungen der Architekturdokumentation. Ein zugewiesener Architekt sollte die Diagramme gemeinsam mit dem aktuellen Codebase durchgehen. Falls Abweichungen festgestellt werden, müssen sie protokolliert und sofort korrigiert werden.
⚠️ Häufige Fallen und wie man sie vermeidet
Selbst erfahrene Architekten machen Fehler beim Modellieren von Datenflüssen. Die Erkennung dieser Fallen frühzeitig kann Wochen an Umstrukturierung und Verwirrung ersparen.
| Falle | Folge | Maßnahme zur Minderung |
|---|---|---|
| Verwirrung bezüglich Steuerungsfluss | Das Diagramm suggeriert Logik, obwohl nur Daten fließen. | Stellen Sie sicher, dass Pfeile Daten darstellen, nicht Ausführungswege. Verwenden Sie Steuerungsflussdiagramme für Logik. |
| Daten-Spaghetti | Zu viele sich kreuzende Linien, wodurch das Diagramm unleserlich wird. | Verwenden Sie Unterprozesse, um die Komplexität zu reduzieren. Gruppieren Sie verwandte Ströme. |
| Fehlende Datenspeicher | Annahme, dass Daten ohne explizite Speicherung erhalten bleiben. | Definieren Sie jeden Datenspeicher explizit. Nehmen Sie nicht an, dass Speicher im Arbeitsspeicher als Speicher zählt. |
| Veraltete Referenzen | Links zu Prozessen, die nicht mehr existieren. | Implementieren Sie einen strengen Überprüfungsprozess während des Mergens von Code. |
Ein weiterer häufiger Fehler ist die Überdekomposition. Die Erstellung eines Diagramms der Stufe 2 für eine einfache CRUD-Operation verschwendet Platz. Dekomponieren Sie einen Prozess nur, wenn er komplexe Logik enthält, die Klärung erfordert. Wenn ein Prozess mit einer einzigen Codezeile verständlich ist, halten Sie ihn auf hoher Ebene.
🔗 Verbinden von DFDs mit anderen architektonischen Artefakten
Ein DFD existiert nicht isoliert. Er interagiert mit anderen Dokumentationstypen, um ein vollständiges architektonisches Bild zu bilden. Die Integration dieser Artefakte schafft eine kohärente Erzählung.
- Entitäts-Beziehungs-Diagramme (ERD): Der DFD zeigt, wie Daten fließen; das ERD zeigt, wie Daten strukturiert sind. Verknüpfen Sie Datenspeicher im DFD mit ihren entsprechenden Tabellen im ERD.
- API-Spezifikationen: Ordnen Sie API-Endpunkte den Datenflüssen zu. Wenn ein Fluss mit „Bestellung absenden“ beschriftet ist, sollte die API-Spezifikation den Endpunkt enthalten, der für diese Abgabe verantwortlich ist.
- Bereitstellungsdigramme: Zeigen Sie, welche Datenspeicher physische Server oder Cloud-Buckets sind. Dies hilft Infrastruktur-Teams, die durch den Datenfluss implizierte Lastverteilung zu verstehen.
- Sicherheitsrichtlinien: Kreuzreferenzieren Sie sensible Datenflüsse mit Verschlüsselungsstandards. Wenn ein Fluss eine Netzwerkgrenze überschreitet, notieren Sie das erforderliche Verschlüsselungsprotokoll.
Indem Sie diese Artefakte miteinander verflechten, schaffen Sie ein Netz aus Wahrheit. Ein Ingenieur, der den DFD liest, kann durch die API-Spezifikation, dann zur Datenbank-Schema und schließlich zur Bereitstellungskonfiguration navigieren. Dies verringert die Reibung beim Wechseln der Kontexte während der Entwicklung.
🚀 Letzte Gedanken zur Dokumentationsintegrität
Das Ziel der Integration von Datenflussdiagrammen besteht nicht darin, am ersten Tag ein perfektes Bild zu schaffen. Es geht darum, einen Standard dafür zu schaffen, wie Daten während des gesamten Projektzyklus wahrgenommen und verwaltet werden. Wenn die Dokumentation sich gemeinsam mit dem Code entwickelt, wird sie zu einem lebendigen Werkzeug statt zu einem historischen Artefakt.
Konzentrieren Sie sich auf Konsistenz statt Perfektion. Ein leicht vereinfachtes Diagramm, das stets aktuell ist, ist wertvoller als ein hyperdetailliertes Diagramm, das veraltet ist. Indem Sie sich an die hier aufgeführten Workflows und Standards halten, stellen Sie sicher, dass Ihre Architekturdokumentation die Teamarbeit effektiv unterstützt, Fehler reduziert und die Lieferung beschleunigt.