











Concevoir des systèmes distribués complexes exige plus que la simple rédaction de code ; cela nécessite un langage visuel clair que les parties prenantes peuvent comprendre. 🏗️ Les diagrammes de flux de données (DFD) servent de ce langage, en cartographiant le déplacement de l’information à travers différents nœuds, services et unités de stockage. Appliqués dans des environnements distribués, les DFD deviennent des outils essentiels pour identifier les goulets d’étranglement, les risques de sécurité et les défis liés à la cohérence avant le début de la mise en œuvre.
Ce guide explore la méthodologie derrière la création de modèles de systèmes distribués efficaces. Nous examinerons les composants fondamentaux, le processus de décomposition, ainsi que les considérations spécifiques nécessaires lorsque les données traversent les frontières réseau. En suivant des pratiques de modélisation établies, les équipes peuvent s’assurer que leur architecture soutient l’évolutivité et la fiabilité.
🌐 Comprendre le contexte des systèmes distribués
Les systèmes distribués se composent de plusieurs ordinateurs autonomes qui apparaissent aux utilisateurs comme un seul système cohérent. Contrairement aux architectures monolithiques, ces environnements introduisent une complexité concernant la communication, la gestion d’état et les modes de défaillance. 🚀 La modélisation de ces systèmes exige un changement de perspective, passant de la logique interne des processus aux chemins de communication externes.
- Frontières réseau :Les données traversent souvent des réseaux physiques ou logiques, introduisant une latence et des points potentiels de défaillance.
- Granularité des services :Les systèmes sont décomposés en services plus petits, chacun gérant des responsabilités spécifiques.
- État sans état versus état présent :Certains composants traitent les requêtes sans conserver d’historique, tandis que d’autres gèrent des données persistantes.
- Communication asynchrone :De nombreuses interactions distribuées reposent sur des files de messages plutôt que sur des appels synchrones directs.
Sans une carte claire, les équipes risquent de créer une « architecture spaghetti » où les flux de données sont flous. Un DFD bien structuré clarifie ces interactions, en assurant que chaque point de données ait une origine et une destination définies.
🔍 Le rôle des diagrammes de flux de données dans la conception des systèmes
Un diagramme de flux de données est une représentation graphique du flux de données à travers un système d’information. Il ne montre pas le moment ou la logique de contrôle, mais se concentre strictement sur la manière dont les données entrent, se transforment, se déplacent et quittent le système. 🧭
Dans un contexte distribué, le DFD aide à visualiser :
- D’où proviennent les données (entités externes).
- Comment elles sont traitées (processus).
- Où elles sont stockées temporairement ou de manière permanente (stocks de données).
- Comment elles voyagent entre les composants (flux de données).
L’utilisation des DFD permet aux architectes de valider les exigences par rapport à l’architecture proposée. Elle garantit qu’aucune donnée n’est créée ou détruite sans raison valable, préservant ainsi l’intégrité tout au long du cycle de vie.
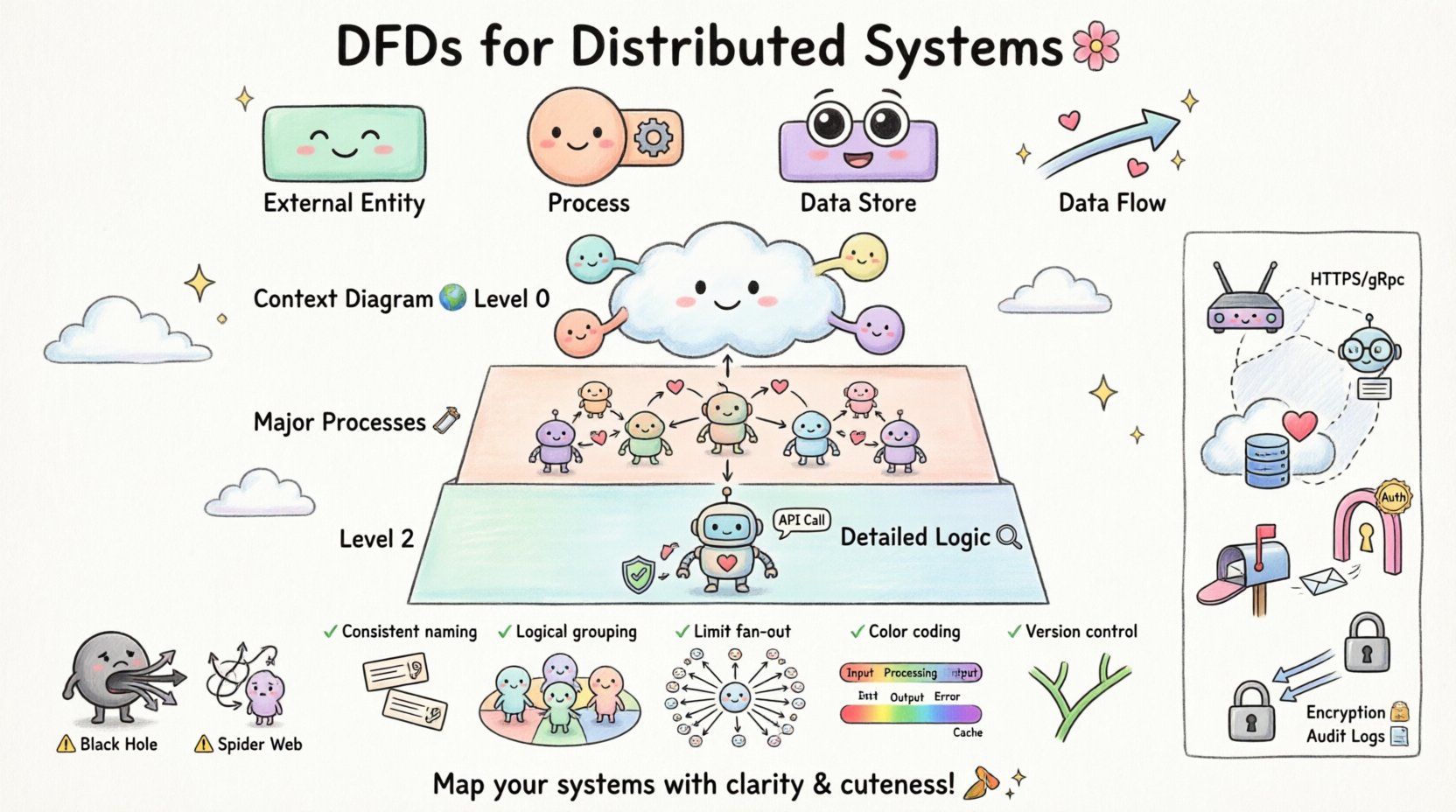
Composants fondamentaux d’un DFD
Pour construire un modèle valide, vous devez comprendre les quatre symboles principaux utilisés dans la notation standard. Chacun remplit un rôle distinct dans la représentation graphique.
| Composant | Fonction | Représentation visuelle |
|---|---|---|
| Entité externe | Source ou destination des données situées en dehors de la frontière du système. | Rectangle |
| Processus | Transformation des données d’entrée en sortie. | Cercle ou rectangle arrondi |
| Stockage de données | Emplacement où les données sont stockées pour une utilisation ultérieure. | Rectangle ouvert ou lignes parallèles |
| Flux de données | Le déplacement des données entre les composants. | Flèche |
Lors de la modélisation des systèmes distribués, il est crucial de nommer chaque flèche par une expression nominale décrivant le contenu des données, et non un verbe. Par exemple, utiliser « Identifiants utilisateur » au lieu de « Envoi des identifiants ».
📉 Niveaux de décomposition des diagrammes en flux de données
Les systèmes complexes ne peuvent pas être représentés dans une seule vue. La décomposition permet de descendre d’un aperçu de haut niveau vers des détails précis. Cette approche évite la surcharge cognitive pour le lecteur.
Niveau 0 : Le diagramme de contexte
Le diagramme de contexte fournit le niveau d’abstraction le plus élevé. Il représente l’ensemble du système comme un seul processus et identifie toutes les entités externes interagissant avec lui. 🌍
- Portée : Définit la frontière du système.
- Interactions : Montre toutes les entrées et sorties provenant du monde extérieur.
- Clarté : Aide les parties prenantes à comprendre le but du système sans détails techniques.
Niveau 1 : Les principaux processus
Le niveau 1 étend le processus unique du diagramme de contexte en sous-processus majeurs. Ce niveau divise le système en morceaux logiques basés sur la fonction. 🛠️
- Décomposition : Divise le système en 5 à 9 processus majeurs.
- Flux : Montre comment les données circulent entre ces principaux processus.
- Stockages : Présente les stockages de données qui soutiennent ces processus.
Niveau 2 et au-delà : Logique détaillée
Une décomposition supplémentaire a lieu au niveau 2, où des sous-processus spécifiques sont détaillés. C’est souvent à ce stade que les détails d’implémentation commencent à apparaître, tels que des règles de validation spécifiques ou des appels d’API. 🔍
Dans la modélisation distribuée, les diagrammes de niveau 2 sont particulièrement utiles pour définir les limites des services. Ils aident à identifier quel processus doit résider dans quel nœud de service.
⚡ Modélisation des environnements distribués
Les DFD standards supposent souvent un environnement monolithique. Lorsqu’on les adapte aux systèmes distribués, des notations et des considérations spécifiques doivent être appliquées pour refléter les réalités du réseau. 🌐
Voici une comparaison des éléments de modélisation standard versus distribuée :
| Élément | Modélisation standard | Modélisation distribuée |
|---|---|---|
| Flux de données | Flux logique direct. | Transmission réseau, latence, protocole. |
| Processus | Unité de calcul unique. | Microservice, conteneur ou fonction sans serveur. |
| Stockage de données | Base de données locale. | Stockage en nuage, cache distribué ou base de données fractionnée. |
| Frontière | Frontière du système. | Frontière réseau, zone de confiance ou passerelle API. |
Lors du dessin des flux de données entre des processus situés sur des nœuds différents, il est utile d’annoter le flux avec le mécanisme de transport (par exemple, HTTPS, gRPC, file d’attente de messages). Cela ajoute un contexte concernant les exigences de performance et de sécurité.
🛡️ Gestion de la concurrence et de l’état
Les systèmes distribués traitent fréquemment des requêtes concurrentes. Un DFD statique ne montre pas nécessairement le timing de manière explicite, mais doit suggérer la manière dont l’état est géré lors de ces interactions. ⏳
- Processus sans état : Si un processus ne conserve pas d’état, le DFD doit montrer les données passant à travers et sortant sans revenir vers un stockage pour cette transaction spécifique.
- Processus avec état : Si un processus conserve un état, il doit y avoir un flux de données clair vers un stockage de données qui persiste ces informations.
- Consistance : Les flux de données représentant des mises à jour doivent indiquer comment la consistance est maintenue entre les nœuds.
Par exemple, lors de la modélisation d’un panier d’achat, le DFD doit montrer le flux des « données du panier » provenant de l’entité Utilisateur vers un service Panier, puis vers un stockage de base de données. Si le service Panier est distribué, le flux doit indiquer quel nœud détient la copie autoritaire des données.
🚫 Pièges courants dans la modélisation distribuée
Même les architectes expérimentés peuvent commettre des erreurs lors de la visualisation des flux de données distribués. Être conscient de ces erreurs courantes aide à améliorer la qualité du modèle. 🚧
| Piège | Impact | Correction |
|---|---|---|
| Processus trou noir | Les données entrent dans un processus mais n’en sortent jamais. | Assurez-vous que chaque entrée a une sortie correspondante ou un stockage. |
| Processus trou gris | Les sorties existent, mais aucune entrée ne les explique. | Vérifiez toutes les sources de données pour chaque flux de sortie. |
| Toile d’araignée | Trop de lignes qui se croisent, ce qui cause de la confusion. | Utilisez des sous-processus pour regrouper les flux liés. |
| Ignorance du réseau | Ignorer les délais de latence ou les points de défaillance. | Annotez les flux avec des notes sur le protocole et la fiabilité. |
Évitez de dessiner des connexions directes entre les magasins de données sans processus intermédiaire. Les magasins de données ne doivent interagir qu’à travers des processus qui valident et transforment les données. Cela empêche les accès directs non autorisés et garantit l’application de la logique métier.
📝 Meilleures pratiques pour la clarté
Créer un diagramme à la fois précis et lisible exige de suivre des principes de conception spécifiques. 🎨
- Nommage cohérent :Utilisez la même terminologie pour les mêmes données dans tous les diagrammes. Si « User ID » est utilisé au niveau 0, ne l’appeler pas « Customer Key » au niveau 1.
- Regroupement logique :Regroupez visuellement les processus liés. Cela aide à identifier les frontières des services.
- Limitez le fan-out :Évitez d’avoir un seul processus connecté à plus de dix flux de données. Si cela se produit, décomposez le processus.
- Codage par couleur :Utilisez des couleurs pour distinguer les processus internes, les entités externes et les magasins de données. Cela facilite le balayage rapide.
- Contrôle de version :Traitez les diagrammes comme du code. Stockez-les dans un système de contrôle de version pour suivre les modifications au fil du temps.
Lors de la modélisation des systèmes distribués, envisagez d’utiliser des nageoires pour représenter différentes zones de confiance ou segments de réseau. Cela rend immédiatement évident quels composants sont accessibles au public par rapport aux composants internes.
🔒 Intégration des considérations de sécurité
La sécurité n’est pas une réflexion tardive ; elle doit être modélisée en parallèle de la fonctionnalité. 🔐 Les diagrammes de flux de données offrent une opportunité unique d’identifier les risques de sécurité dès la phase de conception.
- Points d’authentification :Indiquez où les identifiants utilisateur sont validés. Cela se produit généralement à la frontière entre une entité externe et le premier processus.
- Chiffrement des données :Indiquez où les flux de données sensibles sont chiffrés. Utilisez des étiquettes telles que « Canal chiffré » sur la flèche.
- Contrôle d’accès :Montrez quels processus ont la permission d’accéder à des magasins de données spécifiques.
- Journalisation :Incluez les flux qui envoient des journaux d’audit vers un magasin de journalisation distinct. Cela garantit la traçabilité.
En modélisant explicitement ces flux de sécurité, les équipes peuvent s’assurer que le chiffrement et l’authentification ne sont pas oubliés lors de l’implémentation. Cela impose une discussion sur la confidentialité des données et les exigences de conformité.
🔄 Maintenance et évolution
Les systèmes évoluent. Les exigences changent, et de nouveaux services sont ajoutés. Un DFD est un document vivant qui doit être maintenu pour rester utile. 🔄
- Revue régulière :Programmez des revues périodiques des DFD avec l’équipe de développement pour vous assurer qu’ils correspondent à la base de code actuelle.
- Gestion des changements :Lorsqu’une nouvelle fonctionnalité est ajoutée, mettez à jour le diagramme immédiatement. Ne patientez pas jusqu’à la prochaine itération de documentation.
- Suivi des dépendances :Utilisez le diagramme pour suivre les dépendances. Si un magasin de données est supprimé, le DFD mettra en évidence quels processus seront impactés.
Une documentation qui ne reflète pas la réalité crée une dette technique. Garder les DFD à jour réduit le temps d’intégration des nouveaux ingénieurs et prévient le décalage architectural.
🛠️ Stratégie d’implémentation
Comment commencez-vous réellement à modéliser un système complexe ? Suivez une approche structurée pour garantir une exhaustivité.
- Identifier les entités :Listez tous les utilisateurs, systèmes externes et appareils interagissant avec le système.
- Définir les frontières :Tracez clairement la ligne de frontière du système. Tout ce qui est à l’intérieur fait partie du système ; tout ce qui est à l’extérieur est externe.
- Cartographier les flux de haut niveau :Dessinez d’abord le diagramme de contexte. Assurez-vous que tous les entrées et sorties sont prises en compte.
- Décomposer les processus :Décomposez le processus principal en sous-processus. Étiquetez-les avec des verbes.
- Ajouter des magasins de données : Identifiez où les données doivent être persistées. Liez-les aux processus pertinents.
- Valider : Vérifiez les trous noirs et les trous gris. Assurez-vous que chaque flux a une source et une destination.
- Affiner : Ajoutez des détails sur les protocoles, le chiffrement et les limites réseau dans les contextes distribués.
Ce processus itératif garantit que le modèle est robuste avant l’écriture du code. Il permet de gagner du temps en détectant les erreurs logiques tôt.
🚀 Conclusion
Les diagrammes de flux de données sont un outil fondamental pour concevoir des systèmes distribués. Ils offrent la clarté nécessaire pour comprendre comment les données circulent à travers des réseaux complexes. En suivant les bonnes pratiques, en évitant les pièges courants et en maintenant les diagrammes au fil du temps, les équipes peuvent construire des systèmes évolutifs, sécurisés et fiables. 🌟
L’effort investi dans la modélisation rapporte des dividendes pendant le développement et la maintenance. Des diagrammes clairs facilitent une meilleure communication entre les développeurs, les parties prenantes et les équipes opérationnelles. Ils servent de source unique de vérité pour l’architecture du système.
Commencez à cartographier vos systèmes distribués dès aujourd’hui. Concentrez-vous sur la clarté, la cohérence et l’exactitude. Votre futur vous remerciera lorsque l’architecture devra évoluer ou lors de l’intégration de nouveaux membres à l’équipe. 🏁