











एक प्रणाली के माध्यम से जानकारी के आवागमन को समझना मजबूत सॉफ्टवेयर और कुशल व्यावसायिक प्रक्रियाओं के निर्माण के लिए महत्वपूर्ण है। डेटा प्रवाह आरेख (DFD) इस आवागमन का दृश्य प्रतिनिधित्व प्रदान करते हैं। वे बाहरी स्रोतों से आंतरिक प्रक्रियाओं तक डेटा के प्रवाह को नक्शा बनाते हैं, यह दिखाते हुए कि डेटा कहाँ संग्रहीत होता है और इसका परिवर्तन कैसे होता है। हालांकि, एक ही आरेख बनाने से आधुनिक प्रणालियों की जटिलता को आमतौर पर नहीं दर्शाया जाता है। यहीं स्तर 0, स्तर 1 और स्तर 2 DFD के पदानुक्रम का महत्व आता है।
सही समय पर सही विवरण स्तर का चयन करने से आवश्यकता एकत्र करने और प्रणाली डिजाइन के दौरान भ्रम को रोका जा सकता है। इस मार्गदर्शिका में प्रत्येक स्तर के विशिष्ट उपयोग, घटक और नियमों का अध्ययन किया जाएगा। हम यह जांचेंगे कि किस समय किसी प्रक्रिया के विभाजन को रोकना चाहिए और अपने दस्तावेजों में संगतता कैसे बनाए रखनी चाहिए।
🔍 डेटा प्रवाह आरेख क्या है?
एक डेटा प्रवाह आरेख एक सूचना प्रणाली के माध्यम से डेटा के प्रवाह का आलेखीय प्रतिनिधित्व है। नियंत्रण प्रवाह और तार्किक निर्णयों पर ध्यान केंद्रित करने वाले फ्लोचार्ट्स के विपरीत, DFD डेटा गति पर ध्यान केंद्रित करते हैं। वे स्टेकहोल्डर्स को इनपुट को आउटपुट में कैसे बदला जाता है, इसका दृश्य रूप से देखने में मदद करते हैं।
- प्रक्रिया: डेटा के परिवर्तन करने वाली क्रिया।
- डेटा भंडार: जहां डेटा बाद में उपयोग के लिए रखा जाता है।
- बाहरी एकाई: प्रणाली की सीमा के बाहर कोई स्रोत या गंतव्य।
- डेटा प्रवाह: इन घटकों के बीच डेटा के आवागमन।
एक प्रणाली को विशिष्ट स्तरों में बांटकर विश्लेषक जटिलता को प्रबंधित कर सकते हैं। पहले आरेख पर प्रत्येक लेनदेन विवरण दिखाने की आवश्यकता नहीं है। बल्कि, आप व्यापक शुरुआत करते हैं और आवश्यकता के अनुसार बेहतर बनाते हैं।
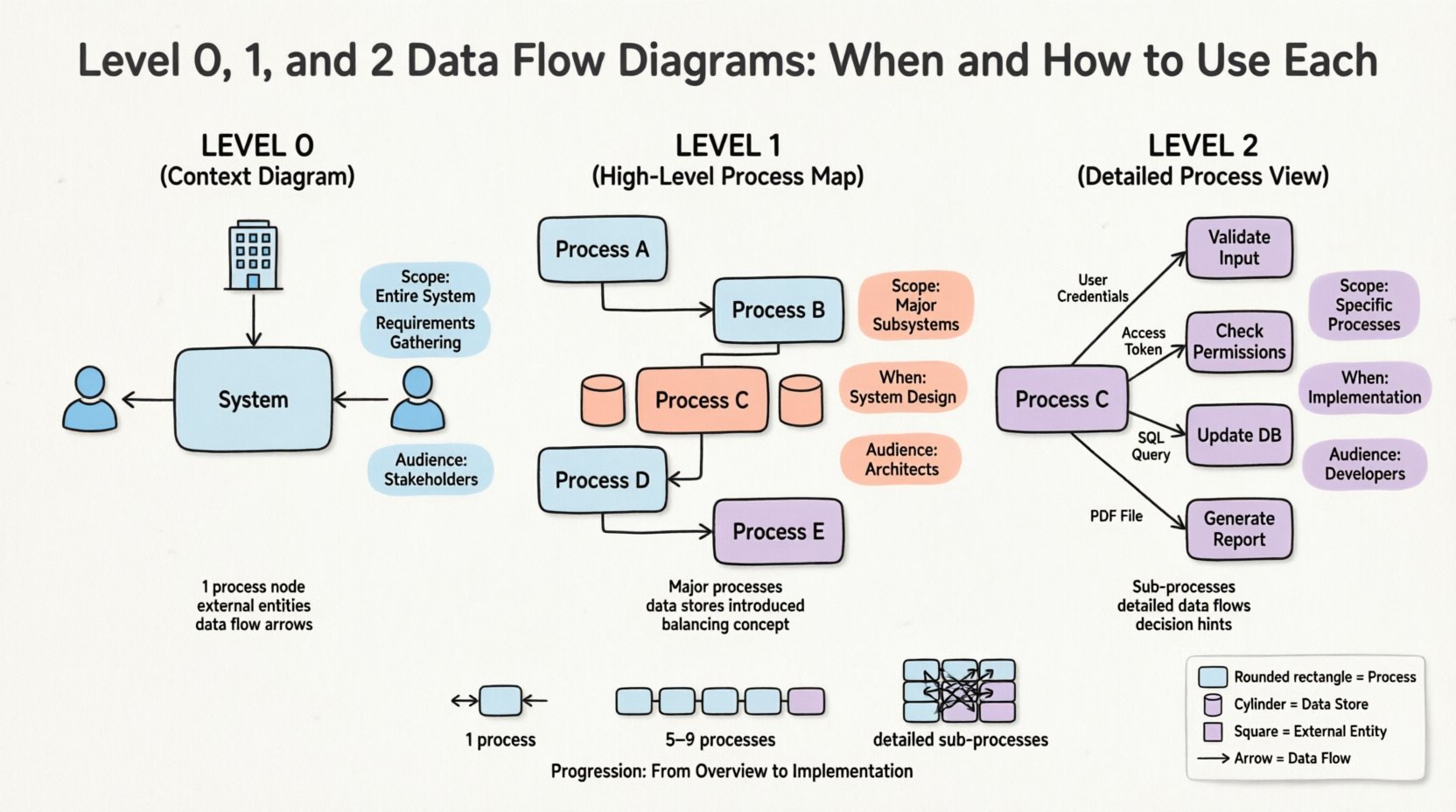
🌍 स्तर 0: संदर्भ आरेख 🌍
स्तर 0 DFD को अक्सर संदर्भ आरेख कहा जाता है। इसमें पूरी प्रणाली को एकल प्रक्रिया के रूप में दर्शाया जाता है। इस उच्च स्तर के दृश्य ने प्रणाली और उसके वातावरण के बीच सीमा को स्थापित करता है।
🎯 स्तर 0 का उपयोग कब करें
- आवश्यकता एकत्र करना: शुरुआत में इसका उपयोग करें ताकि स्टेकहोल्डर्स के साथ सीमा की पुष्टि की जा सके।
- प्रोजेक्ट शुरू करना: नए सदस्यों के लिए एक त्वरित समीक्षा प्रदान करता है।
- प्रणाली सीमा परिभाषा: स्पष्ट रूप से यह परिभाषित करता है कि क्या प्रणाली के अंदर है और क्या बाहर है।
⚙️ मुख्य घटक
- एक प्रक्रिया नोड: पूरी प्रणाली को एकल वृत्त या गोल कोने वाले आयत द्वारा दर्शाया जाता है। इसे आमतौर पर प्रणाली के नाम (उदाहरण के लिए, “आदेश प्रोसेसिंग प्रणाली”) के साथ लेबल किया जाता है।
- बाहरी एकाई: ये व्यक्ति, संगठन या अन्य प्रणालियाँ हैं जो आपकी प्रणाली के साथ बातचीत करती हैं। उदाहरणों में “ग्राहक”, “भुगतान गेटवे” या “गोदाम प्रबंधन प्रणाली” शामिल हैं।
- नोट: यदि आंतरिक विभाग एक ही प्रणाली के दायरे का हिस्सा हैं, तो उन्हें बाहरी एकाई के रूप में शामिल न करें।
- डेटा प्रवाह: एंटिटीज और केंद्रीय प्रक्रिया के बीच इनपुट और आउटपुट को दर्शाने वाले तीर।
📝 उदाहरण परिदृश्य
एक पुस्तकालय प्रबंधन प्रणाली के बारे में सोचें। स्तर 0 आरेख में केंद्रीय “पुस्तकालय प्रणाली” प्रक्रिया को दिखाया जाएगा। बाहरी एंटिटीज में “पुस्तकालय अधिकारी,” “सदस्य,” और “पुस्तक आपूर्तिकर्ता” शामिल होंगे। डेटा प्रवाह में “नई पुस्तक अनुरोध” आपूर्तिकर्ता से और “पुस्तक चेकआउट” सदस्य से शामिल होंगे।
यह स्तर प्रश्न का उत्तर देता है: “प्रणाली क्या है, और इससे कौन बात करता है?”
🔄 स्तर 1: उच्च स्तरीय प्रक्रिया नक्शा 🔄
स्तर 1 DFD स्तर 0 से एकल प्रक्रिया को उसके मुख्य उप-प्रक्रियाओं में विस्तारित करता है। यह छोटे-छोटे विवरणों में फंसे बिना प्रणाली के आंतरिक कार्यों को उजागर करता है। यह अक्सर उच्च स्तरीय आर्किटेक्चर चर्चाओं के लिए सबसे महत्वपूर्ण आरेख होता है।
🎯 स्तर 1 का उपयोग कब करें
- प्रणाली डिजाइन चरण: डेवलपर्स को मुख्य मॉड्यूल्स के बारे में जानकारी की आवश्यकता होती है।
- फीचर योजना: उत्पाद प्रबंधक इसका उपयोग अलग-अलग कार्यात्मक क्षेत्रों की पहचान करने के लिए करते हैं।
- इंटरफेस परिभाषा: डेटा के प्रणाली में प्रवेश और बाहर निकलने वाले स्थानों की पहचान करने में मदद करता है ताकि API को परिभाषित किया जा सके।
⚙️ मुख्य घटक
- मुख्य प्रक्रियाएँ: एकल स्तर 0 प्रक्रिया को 5 से 9 अलग-अलग प्रक्रियाओं में विभाजित करें। यदि आपके पास अधिक हैं, तो उन्हें और अधिक समूहित करने के बारे में सोचें।
- डेटा स्टोरेज: स्तर 1 वह स्थान है जहां आप आमतौर पर डेटा स्टोर (डेटाबेस, फाइलें, तालिकाएं) का परिचय देते हैं। यह दिखाता है कि जानकारी कहां स्थायी रूप से रहती है।
- संगतता: स्तर 0 में प्रणाली में प्रवेश करने या बाहर जाने वाला प्रत्येक डेटा प्रवाह स्तर 1 में दिखाई देना चाहिए। इसे कहा जाता है संतुलन.
📝 उदाहरण परिदृश्य
पुस्तकालय प्रणाली के साथ आगे बढ़ते हुए, स्तर 1 आरेख “पुस्तकालय प्रणाली” को “सदस्य का पंजीकरण,” “पुस्तक चेकआउट,” “जुर्माना प्रक्रिया,” और “इन्वेंटरी प्रबंधन” में बांटता है। डेटा स्टोर में “सदस्य डेटाबेस” और “पुस्तक प्रकाशन सूची” शामिल हो सकते हैं। स्तर 0 से “पुस्तक चेकआउट” का प्रवाह स्तर 1 में “सदस्य डेटाबेस” और “पुस्तक प्रकाशन सूची” के साथ बातचीत करने वाले प्रवाह में विभाजित हो जाता है।
यह स्तर प्रश्न का उत्तर देता है: “मुख्य कार्य क्या हैं, और डेटा कहां संग्रहीत है?”
🔬 स्तर 2: विस्तृत प्रक्रिया दृश्य 🔬
स्तर 2 DFD स्तर 1 में पहचाने गए विशिष्ट प्रक्रियाओं में गहराई से उतरते हैं। एकल स्तर 1 प्रक्रिया पूरी तरह समझने के लिए बहुत जटिल हो सकती है, इसलिए इसे आगे विभाजित किया जाता है। प्रत्येक प्रक्रिया के लिए स्तर 2 आरेख की आवश्यकता नहीं होती है; केवल उन्हीं के लिए जिन्हें विस्तृत विवरण की आवश्यकता होती है।
🎯 स्तर 2 का उपयोग कब करें
- विस्तृत विवरण: डेवलपर्स के लिए तकनीकी आवश्यकताएं लिखते समय उपयोग किया जाता है।
- जटिल तर्क: बहुत सारे निर्णय बिंदु या गणनाओं वाली प्रक्रियाएं।
- पुराने आधार को आधुनिक बनाना: मौजूदा जटिल वर्कफ्लो को नए सिस्टम में मैप करना।
⚙️ मुख्य घटक
- उप-प्रक्रियाएं: लेवल 1 प्रक्रियाओं का विभाजन। उदाहरण के लिए, “पुस्तक निकालें” को “सदस्य की पुष्टि करें,” “इन्वेंटरी अपडेट करें,” और “रसीद जनरेट करें” में बदल दिया जाता है।
- भारी बनावट से बचने के लिए उप-प्रक्रियाओं की संख्या को सीमित रखें।
- इनपुट/आउटपुट विवरण: इन उप-प्रक्रियाओं के बीच कौन से डेटा तत्व पारित होते हैं, इसका सटीक विवरण दिखाएं।
- नियंत्रण तर्क: जबकि DFDs कोड की तरह तर्क नहीं दिखाते, लेवल 2 अक्सर निर्णय बिंदुओं की ओर इशारा करता है (उदाहरण के लिए, “यदि सदस्य वैध है, तो आगे बढ़ें”)।
📝 उदाहरण परिदृश्य
पुस्तकालय के उदाहरण में, लेवल 1 से “जुर्माना प्रक्रिया” प्रक्रिया को विभाजित किया गया है। इसमें “लेट दिनों की गणना करें,” “शुल्क दर लागू करें,” और “खाता शेष अपडेट करें” शामिल हो सकते हैं। इस स्तर के माध्यम से यह सुनिश्चित किया जाता है कि जुर्माना की गणना के लिए तर्क स्पष्ट और व्यावसायिक नियमों के अनुरूप है।
यह स्तर प्रश्न का उत्तर देता है: “इस विशिष्ट कार्य कैसे काम करता है?”
📊 DFD स्तरों की तुलना
| विशेषता | लेवल 0 (संदर्भ) | लेवल 1 (उच्च स्तर) | लेवल 2 (विस्तृत) |
|---|---|---|---|
| परिधि | पूरा सिस्टम | मुख्य उप-प्रणालियां | विशिष्ट प्रक्रियाएं |
| प्रक्रिया गिनती | 1 | 5 से 9 | चर (गहन गहराई से) |
| डेटा स्टोर | कोई नहीं | प्रमुख स्टोर | विस्तृत भंडारण |
| दर्शक | हितधारक, निदेशक | वास्तुकार, प्रबंधक | विकासकर्ता, विश्लेषक |
| समय | आवश्यकता चरण | डिज़ाइन चरण | कार्यान्वयन चरण |
| फोकस | सीमाएँ | कार्यक्षमता | तर्क और डेटा |
🛠️ डीएफडी मॉडलिंग के लिए सर्वोत्तम प्रथाएँ
सटीक आरेख बनाने के लिए अनुशासन की आवश्यकता होती है। विशिष्ट नियमों का पालन करने से यह सुनिश्चित होता है कि आपका दस्तावेज़ प्रोजेक्ट चक्र के दौरान उपयोगी बना रहे।
1. संतुलन बनाए रखें
जब आप स्तर 0 से स्तर 1 तक एक प्रक्रिया को विभाजित करते हैं, तो इनपुट और आउटपुट के मिलान की आवश्यकता होती है। यदि स्तर 0 पर “उपयोगकर्ता लॉगिन अनुरोध” प्रणाली में प्रवेश करता है, तो स्तर 1 पर उसी डेटा को “प्रमाणीकरण प्रक्रिया” में प्रवेश करते हुए दिखाना चाहिए। यदि डेटा अचानक गायब हो जाता है या बिना कारण दिखाई देता है, तो आरेख अमान्य है।
2. नामकरण प्रथाएँ
- प्रक्रियाएँ: क्रिया-संज्ञा संरचना का उपयोग करें (उदाहरण के लिए, “आदेश की पुष्टि करें”, “आदेश पुष्टि” नहीं)। इससे क्रिया पर जोर दिया जाता है।
- डेटा प्रवाह: संज्ञा वाक्यांशों का उपयोग करें (उदाहरण के लिए, “ग्राहक डेटा”, “बिल”)।
- संस्थाएँ: एकवचन संज्ञाओं का उपयोग करें (उदाहरण के लिए, “ग्राहक”, “ग्राहकों” नहीं)।
3. डेटा स्पैगेटी से बचें
एक दूसरे को अत्यधिक प्रतिच्छेद करने वाले डेटा प्रवाहों को न बनाएं। यदि आरेख रेखाओं के जाल की तरह बन जाता है, तो यह संभवतः बहुत जटिल है। स्तर 1 की प्रक्रिया को अलग-अलग आरेखों में विभाजित करने की योजना बनाएं।
4. क्रॉस-टॉल्क नहीं
बाहरी एकाइयाँ एक दूसरे से सीधे संचार नहीं करनी चाहिए। सभी संचार को सिस्टम प्रक्रिया के माध्यम से जाना चाहिए। यदि “गोदाम” डेटा को “बिलिंग सिस्टम” को भेजता है, तो इसे “ऑर्डर प्रोसेसिंग” प्रक्रिया के माध्यम से जाना चाहिए।
5. डेटा स्टोर की सीमा निर्धारित करें
बहुत सारे डेटा स्टोर पाठक को भ्रमित करते हैं। केवल उन स्टोर को शामिल करें जो वर्तमान स्तर की विस्तार से आवश्यक हैं। यदि कोई स्टोर केवल स्तर 2 में उपयोग किया जाता है, तो इसे स्तर 1 में दिखाने की आवश्यकता नहीं हो सकती है।
🚫 बचने के लिए सामान्य गलतियाँ
यहाँ तक कि अनुभवी विश्लेषक भी गलतियाँ करते हैं। इन गलतियों को जल्दी पहचानने से समीक्षा के दौरान समय बचता है।
- काले छेद: एक प्रक्रिया जिसका कोई आउटपुट नहीं है। इसका अर्थ है कि डेटा गायब हो रहा है, जो एक कार्यरत प्रणाली में तार्किक रूप से असंभव है।
- चमत्कार: एक प्रक्रिया जिसका कोई इनपुट नहीं है। डेटा को किसी भी चीज से बनाया नहीं जा सकता।
- ग्रे होल्स: एक प्रक्रिया जिसमें इनपुट हैं लेकिन इनपुट के आधार पर अपेक्षित नहीं आउटपुट उत्पन्न करती है। इसका आमतौर पर अभाव तर्क का संकेत होता है।
- बहुत अधिक विवरण बहुत जल्दी: स्तर 1 के अनुमोदन से पहले स्तर 2 के डायग्राम बनाने से पुनर्कार्य होता है। विवरण के श्रेणीबद्ध ढांचे का पालन करें।
- डेटा स्टोर को नजरअंदाज करना: यह दिखाने में विफलता करना कि डेटा कहाँ संग्रहीत किया जाता है, प्रणाली को अस्थायी और अविश्वसनीय बनाता है।
📋 कार्यान्वयन रणनीति
एक नए प्रोजेक्ट के लिए इन डायग्राम को बनाने के लिए आपको कैसे प्रक्रिया अपनानी चाहिए? इस संरचित कार्य प्रवाह का पालन करें।
चरण 1: सीमा परिभाषा
स्तर 0 डायग्राम से शुरू करें। प्रणाली का नाम और सभी बाहरी एकाइयों को पहचानें। अभी आंतरिक प्रक्रियाओं के बारे में चिंता न करें। सीमा के बारे में प्रोजेक्ट स्पॉन्सर से सहमति प्राप्त करें।
चरण 2: कार्यात्मक विभाजन
स्तर 1 डायग्राम बनाएं। प्रमुख प्रक्रियाओं को पहचानें। सुनिश्चित करें कि सभी डेटा स्टोर परिभाषित हैं। यह सुनिश्चित करें कि स्तर 0 से डेटा प्रवाह यहाँ उपलब्ध है। यहीं आर्किटेक्चर का आकार बनता है।
चरण 3: विस्तृत तर्क
स्तर 1 से उन जटिल प्रक्रियाओं का चयन करें जिन्हें स्पष्टीकरण की आवश्यकता है। इन विशिष्ट क्षेत्रों के लिए स्तर 2 डायग्राम बनाएं। इसका उपयोग डेवलपर हैंडओवर और यूनिट टेस्टिंग विवरण के लिए करें।
चरण 4: रखरखाव
DFD स्थिर नहीं होते हैं। जब प्रणाली में परिवर्तन होता है, तो डायग्राम को अपडेट करें। अद्यतन नहीं किए गए DFD को कोई DFD होने से भी बदतर होता है। हर रिलीज साइकल के साथ डायग्राम को अपडेट करने का नियम स्थापित करें।
🤝 अन्य तकनीकों के साथ एकीकरण
DFD एक खाली स्थान में नहीं होते हैं। वे तब सबसे अच्छा काम करते हैं जब अन्य मॉडलिंग विधियों के साथ जोड़े जाते हैं।
- एंटिटी-रिलेशनशिप डायग्राम (ERD): DFDs गति दिखाते हैं; ERD संरचना दिखाते हैं। अपने DFD में दिखाए गए डेटा स्टोर को परिभाषित करने के लिए ERD का उपयोग करें।
- उपयोग केस आरेख: उपयोग केस आरेख उपयोगकर्ता बातचीत पर केंद्रित होते हैं। DFDs डेटा पर केंद्रित होते हैं। वे आवश्यकता दस्तावेजीकरण में एक दूसरे के पूरक होते हैं।
- अनुक्रम आरेख: अनुक्रम आरेख समय को दिखाते हैं। DFDs संरचना दिखाते हैं। स्तर 2 की प्रक्रियाओं में डेटा प्रवाह के समय को स्पष्ट करने के लिए अनुक्रम आरेखों का उपयोग करें।
📝 उपयोग का सारांश
सही DFD स्तर का चयन दर्शक और दस्तावेजीकरण के लक्ष्य पर निर्भर करता है।
- स्तर 0 का उपयोग करें सीमाओं और दायरे को परिभाषित करने के लिए।
- स्तर 1 का उपयोग करें संरचना और मुख्य कार्यों को परिभाषित करने के लिए।
- स्तर 2 का उपयोग करें तर्क और कार्यान्वयन विवरण को परिभाषित करने के लिए।
विभाजन और संतुलन के नियमों का कठोरता से पालन करके, आप प्रणाली विकास के लिए एक स्पष्ट मार्गदर्शिका बनाते हैं। इस स्पष्टता से व्यापार स्टेकहोल्डर्स और तकनीकी टीमों के बीच गलत संचार कम होता है। याद रखें कि लक्ष्य केवल चित्र बनाना नहीं है, बल्कि यह सुनिश्चित करना है कि डेटा व्यापार को कैसे सेवा करता है, इसके बारे में साझा समझ हो।
विश्राम के लिए संरचना सही करने में समय निवेश करें। किसी भी सॉफ्टवेयर परियोजना के विकास और रखरखाव चरणों में एक अच्छी तरह से संरचित डेटा प्रवाह आरेखों के सेट का लाभ मिलता है।